 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatrix Completion from Non-Uniformly Sampled Entries
Jun 27, 2018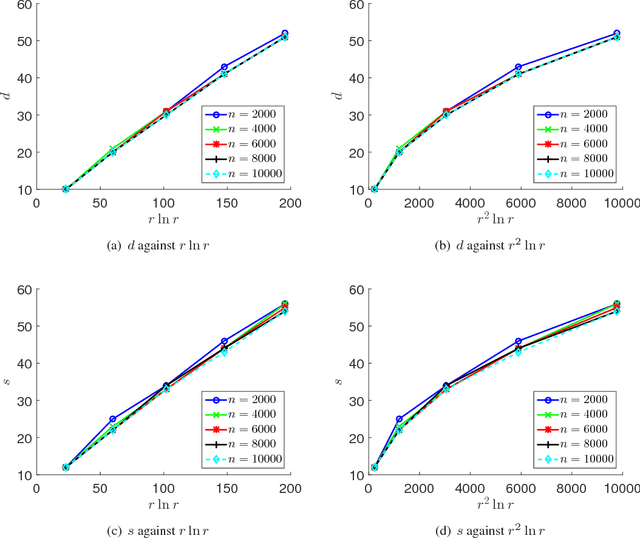
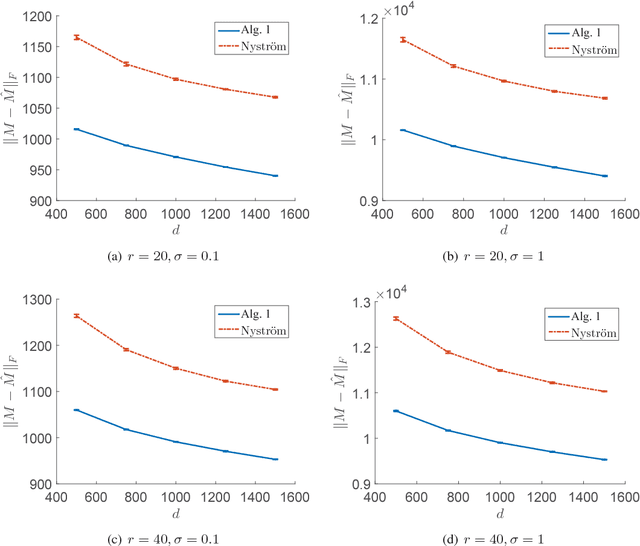
In this paper, we consider matrix completion from non-uniformly sampled entries including fully observed and partially observed columns. Specifically, we assume that a small number of columns are randomly selected and fully observed, and each remaining column is partially observed with uniform sampling. To recover the unknown matrix, we first recover its column space from the fully observed columns. Then, for each partially observed column, we recover it by finding a vector which lies in the recovered column space and consists of the observed entries. When the unknown $m\times n$ matrix is low-rank, we show that our algorithm can exactly recover it from merely $\Omega(rn\ln n)$ entries, where $r$ is the rank of the matrix. Furthermore, for a noisy low-rank matrix, our algorithm computes a low-rank approximation of the unknown matrix and enjoys an additive error bound measured by Frobenius norm. Experimental results on synthetic datasets verify our theoretical claims and demonstrate the effectiveness of our proposed algorithm.
Self-weighted Multiple Kernel Learning for Graph-based Clustering and Semi-supervised Classification
Jun 20, 2018
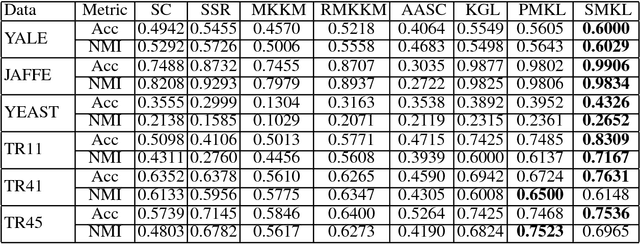
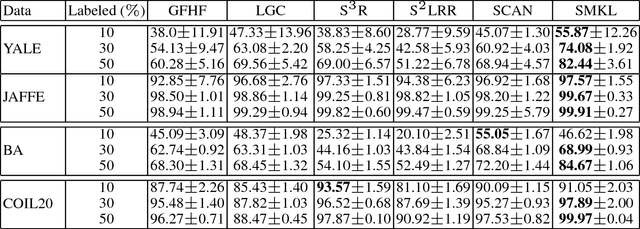
Multiple kernel learning (MKL) method is generally believed to perform better than single kernel method. However, some empirical studies show that this is not always true: the combination of multiple kernels may even yield an even worse performance than using a single kernel. There are two possible reasons for the failure: (i) most existing MKL methods assume that the optimal kernel is a linear combination of base kernels, which may not hold true; and (ii) some kernel weights are inappropriately assigned due to noises and carelessly designed algorithms. In this paper, we propose a novel MKL framework by following two intuitive assumptions: (i) each kernel is a perturbation of the consensus kernel; and (ii) the kernel that is close to the consensus kernel should be assigned a large weight. Impressively, the proposed method can automatically assign an appropriate weight to each kernel without introducing additional parameters, as existing methods do. The proposed framework is integrated into a unified framework for graph-based clustering and semi-supervised classification. We have conducted experiments on multiple benchmark datasets and our empirical results verify the superiority of the proposed framework.
Attacking Visual Language Grounding with Adversarial Examples: A Case Study on Neural Image Captioning
May 22, 2018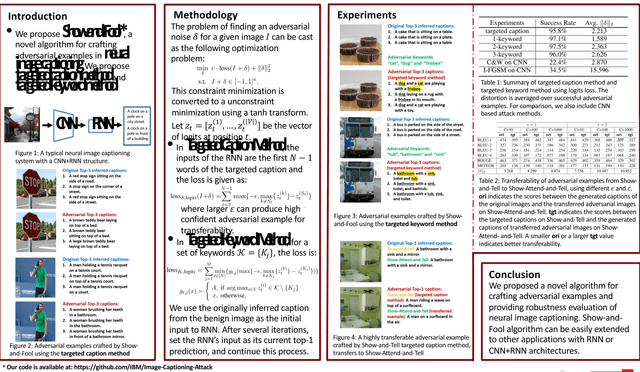
Visual language grounding is widely studied in modern neural image captioning systems, which typically adopts an encoder-decoder framework consisting of two principal components: a convolutional neural network (CNN) for image feature extraction and a recurrent neural network (RNN) for language caption generation. To study the robustness of language grounding to adversarial perturbations in machine vision and perception, we propose Show-and-Fool, a novel algorithm for crafting adversarial examples in neural image captioning. The proposed algorithm provides two evaluation approaches, which check whether neural image captioning systems can be mislead to output some randomly chosen captions or keywords. Our extensive experiments show that our algorithm can successfully craft visually-similar adversarial examples with randomly targeted captions or keywords, and the adversarial examples can be made highly transferable to other image captioning systems. Consequently, our approach leads to new robustness implications of neural image captioning and novel insights in visual language grounding.
Edge Attention-based Multi-Relational Graph Convolutional Networks
May 20, 2018
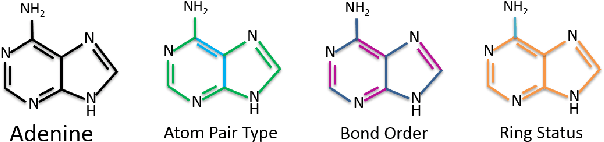
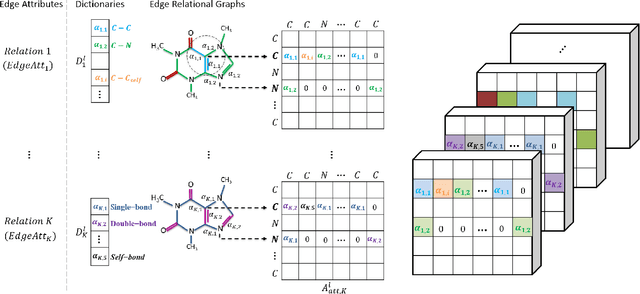
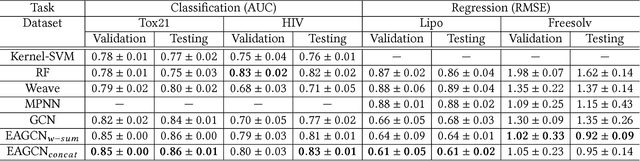
Graph convolutional network (GCN) is generalization of convolutional neural network (CNN) to work with arbitrarily structured graphs. A binary adjacency matrix is commonly used in training a GCN. Recently, the attention mechanism allows the network to learn a dynamic and adaptive aggregation of the neighborhood. We propose a new GCN model on the graphs where edges are characterized in multiple views or precisely in terms of multiple relationships. For instance, in chemical graph theory, compound structures are often represented by the hydrogen-depleted molecular graph where nodes correspond to atoms and edges correspond to chemical bonds. Multiple attributes can be important to characterize chemical bonds, such as atom pair (the types of atoms that a bond connects), aromaticity, and whether a bond is in a ring. The different attributes lead to different graph representations for the same molecule. There is growing interests in both chemistry and machine learning fields to directly learn molecular properties of compounds from the molecular graph, instead of from fingerprints predefined by chemists. The proposed GCN model, which we call edge attention-based multi-relational GCN (EAGCN), jointly learns attention weights and node features in graph convolution. For each bond attribute, a real-valued attention matrix is used to replace the binary adjacency matrix. By designing a dictionary for the edge attention, and forming the attention matrix of each molecule by looking up the dictionary, the EAGCN exploits correspondence between bonds in different molecules. The prediction of compound properties is based on the aggregated node features, which is independent of the varying molecule (graph) size. We demonstrate the efficacy of the EAGCN on multiple chemical datasets: Tox21, HIV, Freesolv, and Lipophilicity, and interpret the resultant attention weights.
Diverse Few-Shot Text Classification with Multiple Metrics
May 19, 2018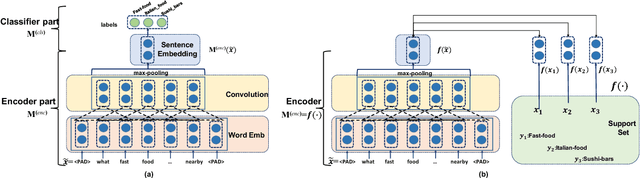
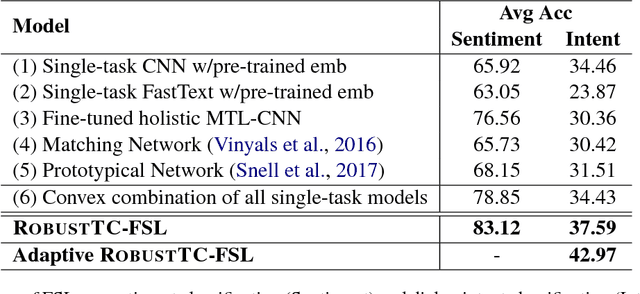
We study few-shot learning in natural language domains. Compared to many existing works that apply either metric-based or optimization-based meta-learning to image domain with low inter-task variance, we consider a more realistic setting, where tasks are diverse. However, it imposes tremendous difficulties to existing state-of-the-art metric-based algorithms since a single metric is insufficient to capture complex task variations in natural language domain. To alleviate the problem, we propose an adaptive metric learning approach that automatically determines the best weighted combination from a set of metrics obtained from meta-training tasks for a newly seen few-shot task. Extensive quantitative evaluations on real-world sentiment analysis and dialog intent classification datasets demonstrate that the proposed method performs favorably against state-of-the-art few shot learning algorithms in terms of predictive accuracy. We make our code and data available for further study.
Robust Task Clustering for Deep Many-Task Learning
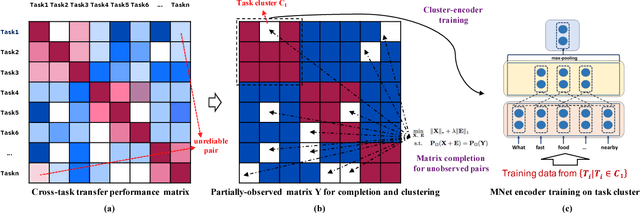
May 18, 2018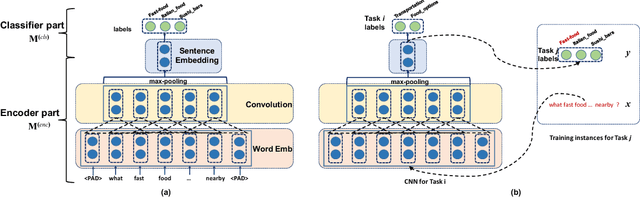
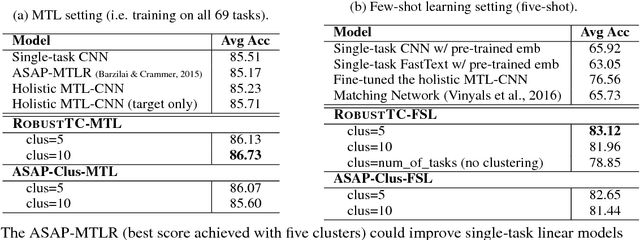
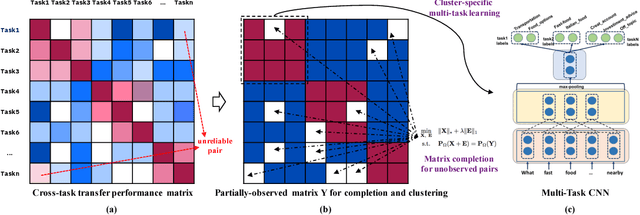
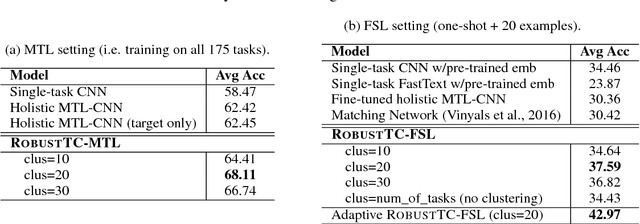
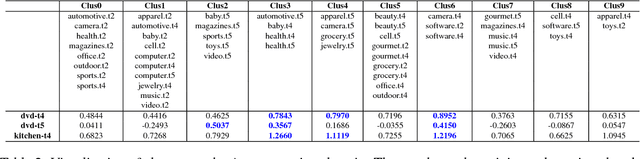
We investigate task clustering for deep-learning based multi-task and few-shot learning in a many-task setting. We propose a new method to measure task similarities with cross-task transfer performance matrix for the deep learning scenario. Although this matrix provides us critical information regarding similarity between tasks, its asymmetric property and unreliable performance scores can affect conventional clustering methods adversely. Additionally, the uncertain task-pairs, i.e., the ones with extremely asymmetric transfer scores, may collectively mislead clustering algorithms to output an inaccurate task-partition. To overcome these limitations, we propose a novel task-clustering algorithm by using the matrix completion technique. The proposed algorithm constructs a partially-observed similarity matrix based on the certainty of cluster membership of the task-pairs. We then use a matrix completion algorithm to complete the similarity matrix. Our theoretical analysis shows that under mild constraints, the proposed algorithm will perfectly recover the underlying "true" similarity matrix with a high probability. Our results show that the new task clustering method can discover task clusters for training flexible and superior neural network models in a multi-task learning setup for sentiment classification and dialog intent classification tasks. Our task clustering approach also extends metric-based few-shot learning methods to adapt multiple metrics, which demonstrates empirical advantages when the tasks are diverse.
Seq2Sick: Evaluating the Robustness of Sequence-to-Sequence Models with Adversarial Examples
Mar 03, 2018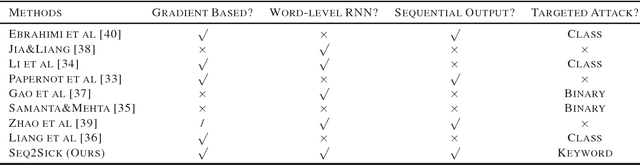
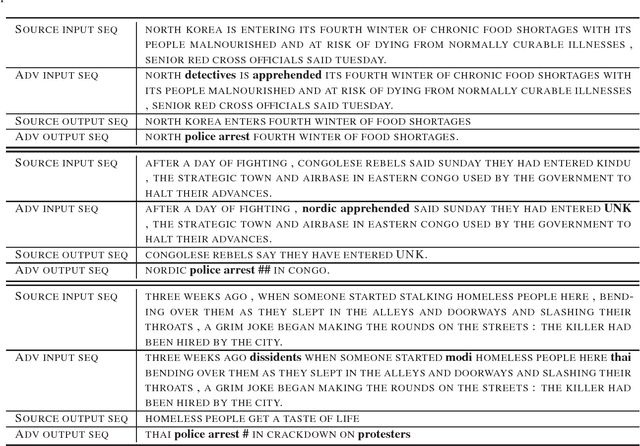
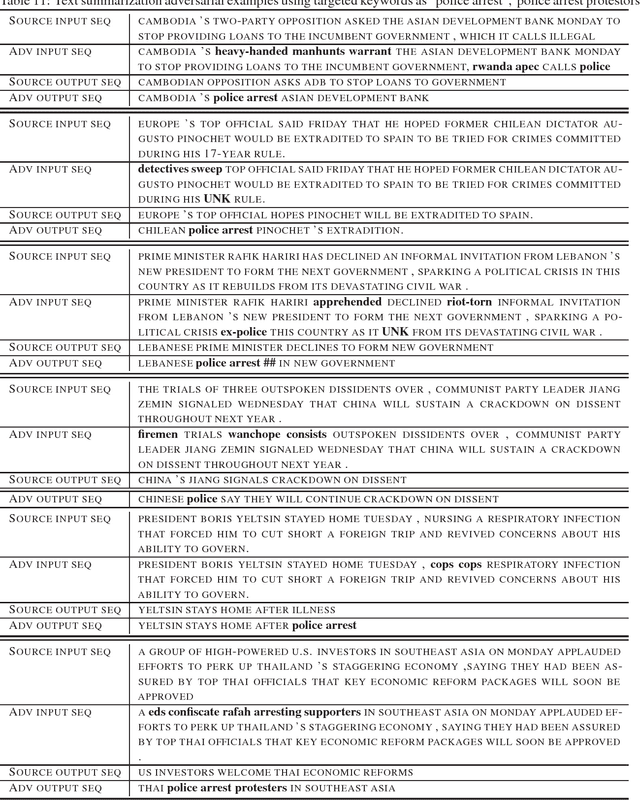
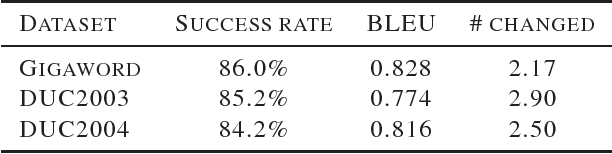
Crafting adversarial examples has become an important technique to evaluate the robustness of deep neural networks (DNNs). However, most existing works focus on attacking the image classification problem since its input space is continuous and output space is finite. In this paper, we study the much more challenging problem of crafting adversarial examples for sequence-to-sequence (seq2seq) models, whose inputs are discrete text strings and outputs have an almost infinite number of possibilities. To address the challenges caused by the discrete input space, we propose a projected gradient method combined with group lasso and gradient regularization. To handle the almost infinite output space, we design some novel loss functions to conduct non-overlapping attack and targeted keyword attack. We apply our algorithm to machine translation and text summarization tasks, and verify the effectiveness of the proposed algorithm: by changing less than 3 words, we can make seq2seq model to produce desired outputs with high success rates. On the other hand, we recognize that, compared with the well-evaluated CNN-based classifiers, seq2seq models are intrinsically more robust to adversarial attacks.
Identify Susceptible Locations in Medical Records via Adversarial Attacks on Deep Predictive Models
Feb 13, 2018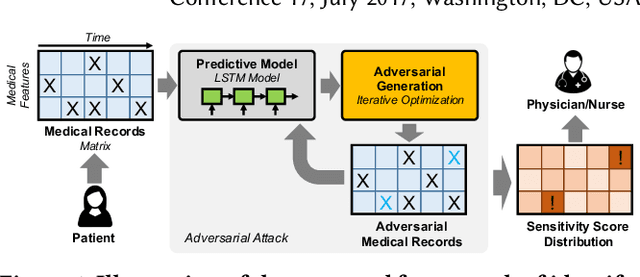
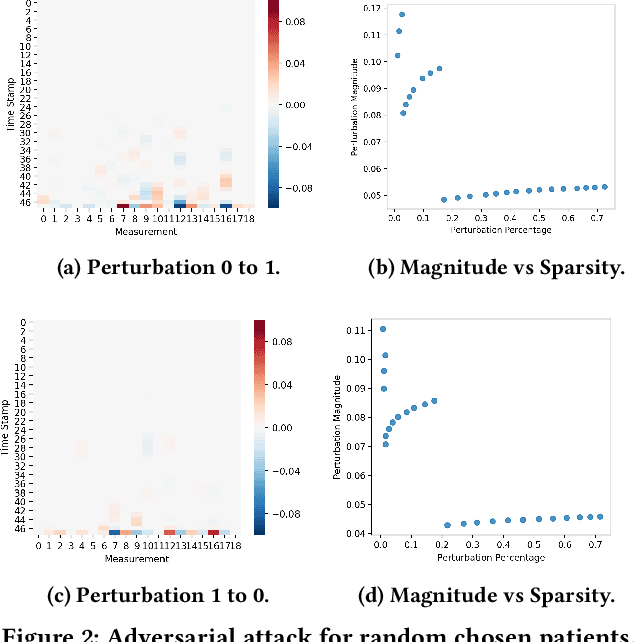
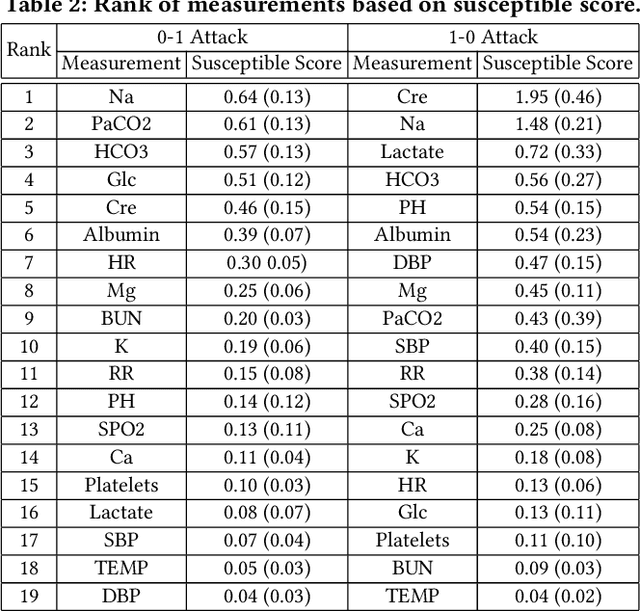
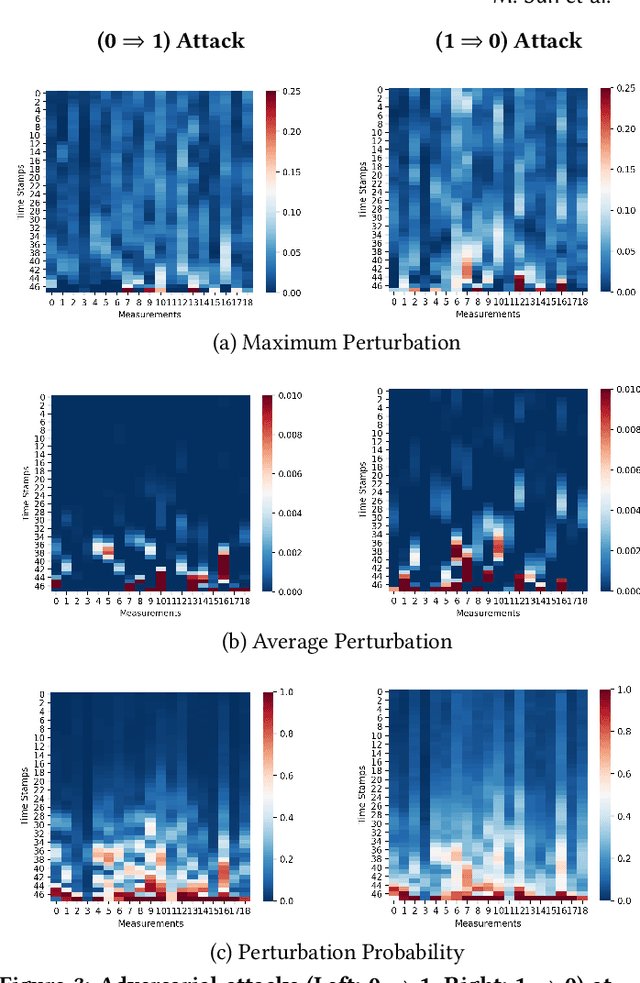
The surging availability of electronic medical records (EHR) leads to increased research interests in medical predictive modeling. Recently many deep learning based predicted models are also developed for EHR data and demonstrated impressive performance. However, a series of recent studies showed that these deep models are not safe: they suffer from certain vulnerabilities. In short, a well-trained deep network can be extremely sensitive to inputs with negligible changes. These inputs are referred to as adversarial examples. In the context of medical informatics, such attacks could alter the result of a high performance deep predictive model by slightly perturbing a patient's medical records. Such instability not only reflects the weakness of deep architectures, more importantly, it offers guide on detecting susceptible parts on the inputs. In this paper, we propose an efficient and effective framework that learns a time-preferential minimum attack targeting the LSTM model with EHR inputs, and we leverage this attack strategy to screen medical records of patients and identify susceptible events and measurements. The efficient screening procedure can assist decision makers to pay extra attentions to the locations that can cause severe consequence if not measured correctly. We conduct extensive empirical studies on a real-world urgent care cohort and demonstrate the effectiveness of the proposed screening approach.
EAD: Elastic-Net Attacks to Deep Neural Networks via Adversarial Examples
Feb 10, 2018
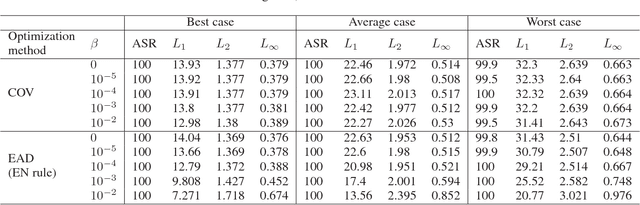

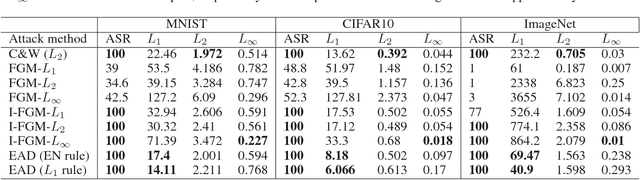
Recent studies have highlighted the vulnerability of deep neural networks (DNNs) to adversarial examples - a visually indistinguishable adversarial image can easily be crafted to cause a well-trained model to misclassify. Existing methods for crafting adversarial examples are based on $L_2$ and $L_\infty$ distortion metrics. However, despite the fact that $L_1$ distortion accounts for the total variation and encourages sparsity in the perturbation, little has been developed for crafting $L_1$-based adversarial examples. In this paper, we formulate the process of attacking DNNs via adversarial examples as an elastic-net regularized optimization problem. Our elastic-net attacks to DNNs (EAD) feature $L_1$-oriented adversarial examples and include the state-of-the-art $L_2$ attack as a special case. Experimental results on MNIST, CIFAR10 and ImageNet show that EAD can yield a distinct set of adversarial examples with small $L_1$ distortion and attains similar attack performance to the state-of-the-art methods in different attack scenarios. More importantly, EAD leads to improved attack transferability and complements adversarial training for DNNs, suggesting novel insights on leveraging $L_1$ distortion in adversarial machine learning and security implications of DNNs.
Evaluating the Robustness of Neural Networks: An Extreme Value Theory Approach
Jan 31, 2018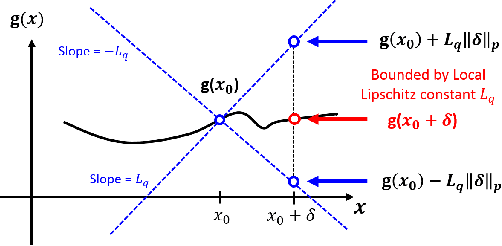
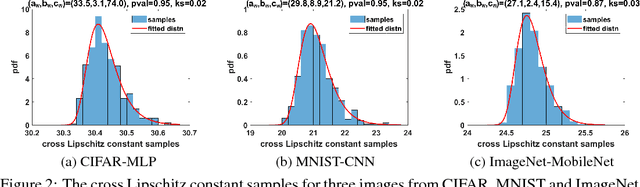
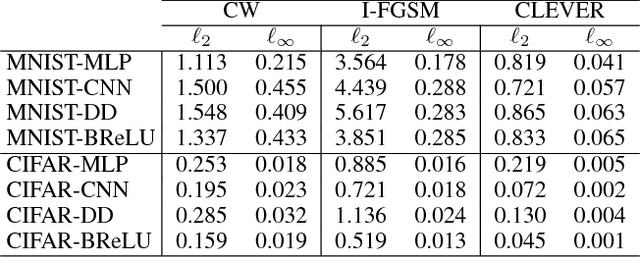
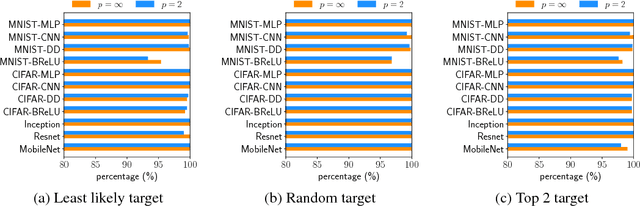
The robustness of neural networks to adversarial examples has received great attention due to security implications. Despite various attack approaches to crafting visually imperceptible adversarial examples, little has been developed towards a comprehensive measure of robustness. In this paper, we provide a theoretical justification for converting robustness analysis into a local Lipschitz constant estimation problem, and propose to use the Extreme Value Theory for efficient evaluation. Our analysis yields a novel robustness metric called CLEVER, which is short for Cross Lipschitz Extreme Value for nEtwork Robustness. The proposed CLEVER score is attack-agnostic and computationally feasible for large neural networks. Experimental results on various networks, including ResNet, Inception-v3 and MobileNet, show that (i) CLEVER is aligned with the robustness indication measured by the $\ell_2$ and $\ell_\infty$ norms of adversarial examples from powerful attacks, and (ii) defended networks using defensive distillation or bounded ReLU indeed achieve better CLEVER scores. To the best of our knowledge, CLEVER is the first attack-independent robustness metric that can be applied to any neural network classifier.