 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA data-physics hybrid generative model for patient-specific post-stroke motor rehabilitation using wearable sensor data
Dec 16, 2025Dynamic prediction of locomotor capacity after stroke is crucial for tailoring rehabilitation, yet current assessments provide only static impairment scores and do not indicate whether patients can safely perform specific tasks such as slope walking or stair climbing. Here, we develop a data-physics hybrid generative framework that reconstructs an individual stroke survivor's neuromuscular control from a single 20 m level-ground walking trial and predicts task-conditioned locomotion across rehabilitation scenarios. The system combines wearable-sensor kinematics, a proportional-derivative physics controller, a population Healthy Motion Atlas, and goal-conditioned deep reinforcement learning with behaviour cloning and generative adversarial imitation learning to generate physically plausible, patient-specific gait simulations for slopes and stairs. In 11 stroke survivors, the personalized controllers preserved idiosyncratic gait patterns while improving joint-angle and endpoint fidelity by 4.73% and 12.10%, respectively, and reducing training time to 25.56% relative to a physics-only baseline. In a multicentre pilot involving 21 inpatients, clinicians who used our locomotion predictions to guide task selection and difficulty obtained larger gains in Fugl-Meyer lower-extremity scores over 28 days of standard rehabilitation than control clinicians (mean change 6.0 versus 3.7 points). These findings indicate that our generative, task-predictive framework can augment clinical decision-making in post-stroke gait rehabilitation and provide a template for dynamically personalized motor recovery strategies.
WonderZoom: Multi-Scale 3D World Generation
Dec 09, 2025We present WonderZoom, a novel approach to generating 3D scenes with contents across multiple spatial scales from a single image. Existing 3D world generation models remain limited to single-scale synthesis and cannot produce coherent scene contents at varying granularities. The fundamental challenge is the lack of a scale-aware 3D representation capable of generating and rendering content with largely different spatial sizes. WonderZoom addresses this through two key innovations: (1) scale-adaptive Gaussian surfels for generating and real-time rendering of multi-scale 3D scenes, and (2) a progressive detail synthesizer that iteratively generates finer-scale 3D contents. Our approach enables users to "zoom into" a 3D region and auto-regressively synthesize previously non-existent fine details from landscapes to microscopic features. Experiments demonstrate that WonderZoom significantly outperforms state-of-the-art video and 3D models in both quality and alignment, enabling multi-scale 3D world creation from a single image. We show video results and an interactive viewer of generated multi-scale 3D worlds in https://wonderzoom.github.io/
UniVerse: Unleashing the Scene Prior of Video Diffusion Models for Robust Radiance Field Reconstruction
Oct 02, 2025
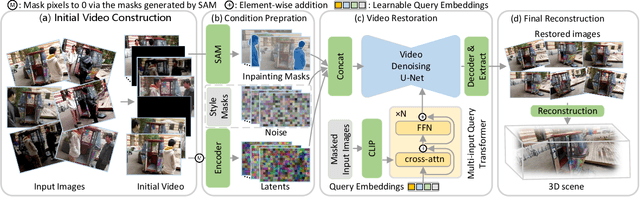
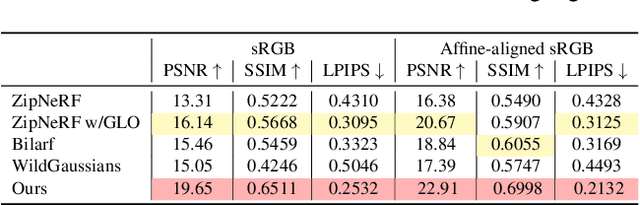

This paper tackles the challenge of robust reconstruction, i.e., the task of reconstructing a 3D scene from a set of inconsistent multi-view images. Some recent works have attempted to simultaneously remove image inconsistencies and perform reconstruction by integrating image degradation modeling into neural 3D scene representations.However, these methods rely heavily on dense observations for robustly optimizing model parameters.To address this issue, we propose to decouple robust reconstruction into two subtasks: restoration and reconstruction, which naturally simplifies the optimization process.To this end, we introduce UniVerse, a unified framework for robust reconstruction based on a video diffusion model. Specifically, UniVerse first converts inconsistent images into initial videos, then uses a specially designed video diffusion model to restore them into consistent images, and finally reconstructs the 3D scenes from these restored images.Compared with case-by-case per-view degradation modeling, the diffusion model learns a general scene prior from large-scale data, making it applicable to diverse image inconsistencies.Extensive experiments on both synthetic and real-world datasets demonstrate the strong generalization capability and superior performance of our method in robust reconstruction. Moreover, UniVerse can control the style of the reconstructed 3D scene. Project page: https://jin-cao-tma.github.io/UniVerse.github.io/
Time Series Language Model for Descriptive Caption Generation
Jan 03, 2025



The automatic generation of representative natural language descriptions for observable patterns in time series data enhances interpretability, simplifies analysis and increases cross-domain utility of temporal data. While pre-trained foundation models have made considerable progress in natural language processing (NLP) and computer vision (CV), their application to time series analysis has been hindered by data scarcity. Although several large language model (LLM)-based methods have been proposed for time series forecasting, time series captioning is under-explored in the context of LLMs. In this paper, we introduce TSLM, a novel time series language model designed specifically for time series captioning. TSLM operates as an encoder-decoder model, leveraging both text prompts and time series data representations to capture subtle temporal patterns across multiple phases and generate precise textual descriptions of time series inputs. TSLM addresses the data scarcity problem in time series captioning by first leveraging an in-context prompting synthetic data generation, and second denoising the generated data via a novel cross-modal dense retrieval scoring applied to time series-caption pairs. Experimental findings on various time series captioning datasets demonstrate that TSLM outperforms existing state-of-the-art approaches from multiple data modalities by a significant margin.
Dynamic Optimization of Storage Systems Using Reinforcement Learning Techniques
Dec 29, 2024



The exponential growth of data-intensive applications has placed unprecedented demands on modern storage systems, necessitating dynamic and efficient optimization strategies. Traditional heuristics employed for storage performance optimization often fail to adapt to the variability and complexity of contemporary workloads, leading to significant performance bottlenecks and resource inefficiencies. To address these challenges, this paper introduces RL-Storage, a novel reinforcement learning (RL)-based framework designed to dynamically optimize storage system configurations. RL-Storage leverages deep Q-learning algorithms to continuously learn from real-time I/O patterns and predict optimal storage parameters, such as cache size, queue depths, and readahead settings[1]. The proposed framework operates within the storage kernel, ensuring minimal latency and low computational overhead. Through an adaptive feedback mechanism, RL-Storage dynamically adjusts critical parameters, achieving efficient resource utilization across a wide range of workloads. Experimental evaluations conducted on a range of benchmarks, including RocksDB and PostgreSQL, demonstrate significant improvements, with throughput gains of up to 2.6x and latency reductions of 43% compared to baseline heuristics. Additionally, RL-Storage achieves these performance enhancements with a negligible CPU overhead of 0.11% and a memory footprint of only 5 KB, making it suitable for seamless deployment in production environments. This work underscores the transformative potential of reinforcement learning techniques in addressing the dynamic nature of modern storage systems. By autonomously adapting to workload variations in real time, RL-Storage provides a robust and scalable solution for optimizing storage performance, paving the way for next-generation intelligent storage infrastructures.
Wearable intelligent throat enables natural speech in stroke patients with dysarthria
Nov 28, 2024



Wearable silent speech systems hold significant potential for restoring communication in patients with speech impairments. However, seamless, coherent speech remains elusive, and clinical efficacy is still unproven. Here, we present an AI-driven intelligent throat (IT) system that integrates throat muscle vibrations and carotid pulse signal sensors with large language model (LLM) processing to enable fluent, emotionally expressive communication. The system utilizes ultrasensitive textile strain sensors to capture high-quality signals from the neck area and supports token-level processing for real-time, continuous speech decoding, enabling seamless, delay-free communication. In tests with five stroke patients with dysarthria, IT's LLM agents intelligently corrected token errors and enriched sentence-level emotional and logical coherence, achieving low error rates (4.2% word error rate, 2.9% sentence error rate) and a 55% increase in user satisfaction. This work establishes a portable, intuitive communication platform for patients with dysarthria with the potential to be applied broadly across different neurological conditions and in multi-language support systems.
Chain-of-Restoration: Multi-Task Image Restoration Models are Zero-Shot Step-by-Step Universal Image Restorers
Oct 11, 2024



Despite previous works typically targeting isolated degradation types, recent research has increasingly focused on addressing composite degradations which involve a complex interplay of multiple different isolated degradations. Recognizing the challenges posed by the exponential number of possible degradation combinations, we propose Universal Image Restoration (UIR), a new task setting that requires models to be trained on a set of degradation bases and then remove any degradation that these bases can potentially compose in a zero-shot manner. Inspired by the Chain-of-Thought which prompts LLMs to address problems step-by-step, we propose the Chain-of-Restoration (CoR), which instructs models to step-by-step remove unknown composite degradations. By integrating a simple Degradation Discriminator into pre-trained multi-task models, CoR facilitates the process where models remove one degradation basis per step, continuing this process until the image is fully restored from the unknown composite degradation. Extensive experiments show that CoR significantly improves model performance in removing composite degradations, achieving results comparable to or surpassing those of State-of-The-Art (SoTA) methods trained on all degradations. The code will be released at https://github.com/toummHus/Chain-of-Restoration.
Training Data Attribution: Was Your Model Secretly Trained On Data Created By Mine?
Sep 24, 2024



The emergence of text-to-image models has recently sparked significant interest, but the attendant is a looming shadow of potential infringement by violating the user terms. Specifically, an adversary may exploit data created by a commercial model to train their own without proper authorization. To address such risk, it is crucial to investigate the attribution of a suspicious model's training data by determining whether its training data originates, wholly or partially, from a specific source model. To trace the generated data, existing methods require applying extra watermarks during either the training or inference phases of the source model. However, these methods are impractical for pre-trained models that have been released, especially when model owners lack security expertise. To tackle this challenge, we propose an injection-free training data attribution method for text-to-image models. It can identify whether a suspicious model's training data stems from a source model, without additional modifications on the source model. The crux of our method lies in the inherent memorization characteristic of text-to-image models. Our core insight is that the memorization of the training dataset is passed down through the data generated by the source model to the model trained on that data, making the source model and the infringing model exhibit consistent behaviors on specific samples. Therefore, our approach involves developing algorithms to uncover these distinct samples and using them as inherent watermarks to verify if a suspicious model originates from the source model. Our experiments demonstrate that our method achieves an accuracy of over 80\% in identifying the source of a suspicious model's training data, without interfering the original training or generation process of the source model.
HAIR: Hypernetworks-based All-in-One Image Restoration
Aug 15, 2024



Image restoration involves recovering a high-quality clean image from its degraded version, which is a fundamental task in computer vision. Recent progress in image restoration has demonstrated the effectiveness of learning models capable of addressing various degradations simultaneously, i.e., the All-in-One image restoration models. However, these existing methods typically utilize the same parameters facing images with different degradation types, which causes the model to be forced to trade off between degradation types, therefore impair the total performance. To solve this problem, we propose HAIR, a Hypernetworks-based plug-in-and-play method that dynamically generated parameters for the corresponding networks based on the contents of input images. HAIR consists of 2 main components: Classifier (Cl) and Hyper Selecting Net (HSN). To be more specific, the Classifier is a simple image classification network which is used to generate a Global Information Vector (GIV) that contains the degradation information of the input image; And the HSNs can be seen as a simple Fully-connected Neural Network that receive the GIV and output parameters for the corresponding modules. Extensive experiments shows that incorporating HAIR into the architectures can significantly improve the performance of different models on image restoration tasks at a low cost, \textbf{although HAIR only generate parameters and haven't change these models' logical structures at all.} With incorporating HAIR into the popular architecture Restormer, our method obtains superior or at least comparable performance to current state-of-the-art methods on a range of image restoration tasks. \href{https://github.com/toummHus/HAIR}{\textcolor{blue}{$\underline{\textbf{Code and pre-trained checkpoints are available here.}}$}}
Multi-Scenario Combination Based on Multi-Agent Reinforcement Learning to Optimize the Advertising Recommendation System
Jul 03, 2024



This paper explores multi-scenario optimization on large platforms using multi-agent reinforcement learning (MARL). We address this by treating scenarios like search, recommendation, and advertising as a cooperative, partially observable multi-agent decision problem. We introduce the Multi-Agent Recurrent Deterministic Policy Gradient (MARDPG) algorithm, which aligns different scenarios under a shared objective and allows for strategy communication to boost overall performance. Our results show marked improvements in metrics such as click-through rate (CTR), conversion rate, and total sales, confirming our method's efficacy in practical settings.