 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyle Attuned Pre-training and Parameter Efficient Fine-tuning for Spoken Language Understanding
Paper and Code
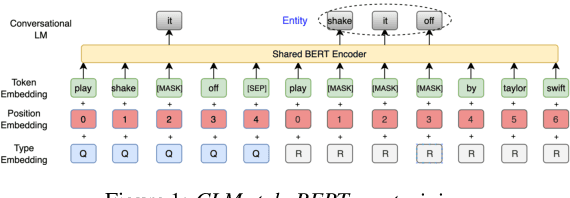
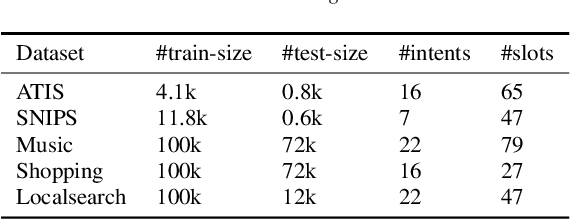
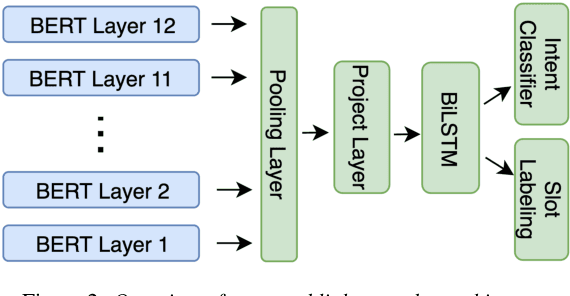

Neural models have yielded state-of-the-art results in deciphering spoken language understanding (SLU) problems; however, these models require a significant amount of domain-specific labeled examples for training, which is prohibitively expensive. While pre-trained language models like BERT have been shown to capture a massive amount of knowledge by learning from unlabeled corpora and solve SLU using fewer labeled examples for adaption, the encoding of knowledge is implicit and agnostic to downstream tasks. Such encoding results in model inefficiencies in parameter usage: an entirely new model is required for every domain. To address these challenges, we introduce a novel SLU framework, comprising a conversational language modeling (CLM) pre-training task and a light encoder architecture. The CLM pre-training enables networks to capture the representation of the language in conversation style with the presence of ASR errors. The light encoder architecture separates the shared pre-trained networks from the mappings of generally encoded knowledge to specific domains of SLU, allowing for the domain adaptation to be performed solely at the light encoder and thus increasing efficiency. With the framework, we match the performance of state-of-the-art SLU results on Alexa internal datasets and on two public ones (ATIS, SNIPS), adding only 4.4% parameters per task.