 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improvement for Fast, High-Quality Plan Generation
May 05, 2026Generative models trained on synthetic plan data are a promising approach to generalized planning. Recent work has focused on finding any valid plan, rather than a high-quality solution. We address the challenge of producing high-quality plans, a computationally hard problem, in sub-exponential time. First, we demonstrate that, given optimal data, a decoder-only transformer can generate high-quality plans for unseen problem instances. Second, we show how to self-improve an initial model trained on sub-optimal data. Each round of self-improvement combines multiple model calls with graph search to generate improved plans, used for model fine-tuning. An experimental study on four domains: Blocksworld, Logistics, Labyrinth, and Sokoban, shows on average a 30% reduction in plan length over the source symbolic planner, with over 80% of plans being optimal, where the optimum is known. Plan quality is further improved by inference-time search. The model's latency scales sub-exponentially in contrast to the satisficing and optimal symbolic planners to which we compare. Together, these results suggest that self-improvement with generative models offers a scalable approach for high-quality plan generation.
Knowledge Distillation Transfer Sets and their Impact on Downstream NLU Tasks
Oct 11, 2022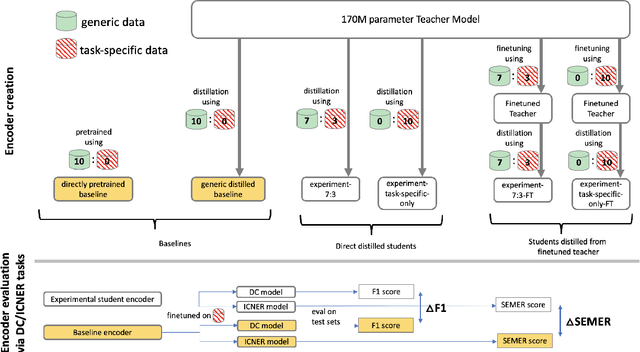
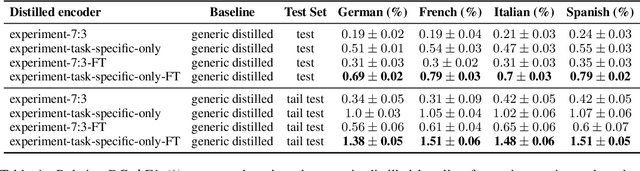
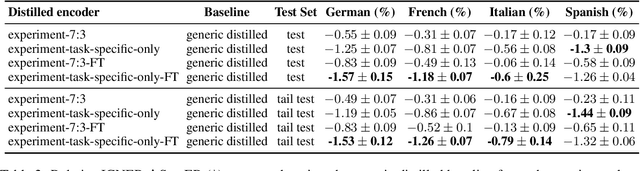
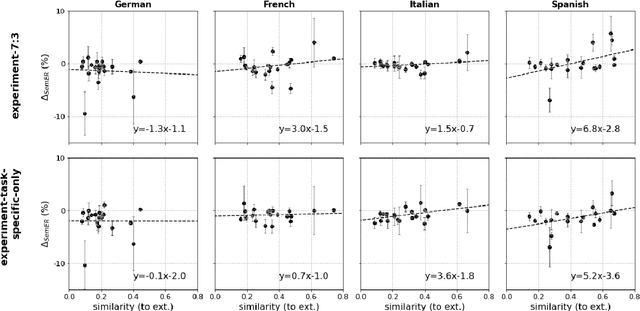
Teacher-student knowledge distillation is a popular technique for compressing today's prevailing large language models into manageable sizes that fit low-latency downstream applications. Both the teacher and the choice of transfer set used for distillation are crucial ingredients in creating a high quality student. Yet, the generic corpora used to pretrain the teacher and the corpora associated with the downstream target domain are often significantly different, which raises a natural question: should the student be distilled over the generic corpora, so as to learn from high-quality teacher predictions, or over the downstream task corpora to align with finetuning? Our study investigates this trade-off using Domain Classification (DC) and Intent Classification/Named Entity Recognition (ICNER) as downstream tasks. We distill several multilingual students from a larger multilingual LM with varying proportions of generic and task-specific datasets, and report their performance after finetuning on DC and ICNER. We observe significant improvements across tasks and test sets when only task-specific corpora is used. We also report on how the impact of adding task-specific data to the transfer set correlates with the similarity between generic and task-specific data. Our results clearly indicate that, while distillation from a generic LM benefits downstream tasks, students learn better using target domain data even if it comes at the price of noisier teacher predictions. In other words, target domain data still trumps teacher knowledge.
Alexa Teacher Model: Pretraining and Distilling Multi-Billion-Parameter Encoders for Natural Language Understanding Systems
Jun 15, 2022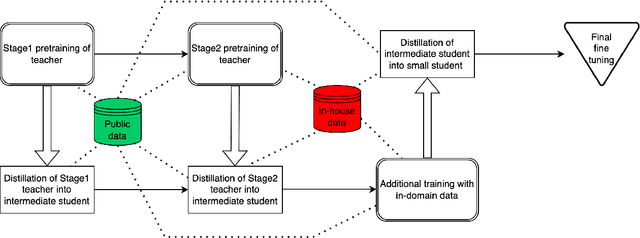
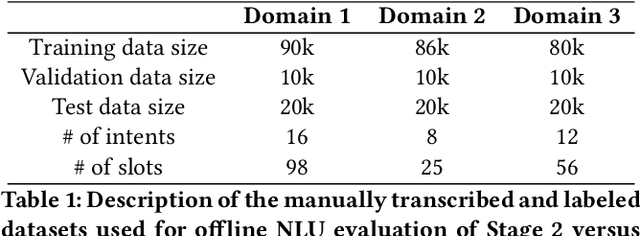
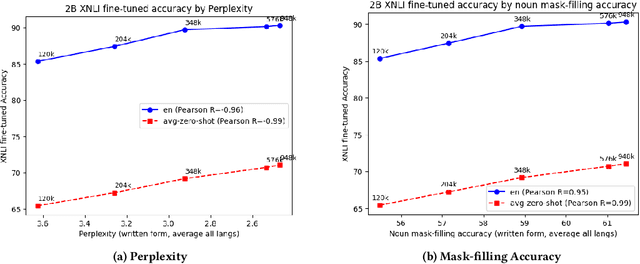
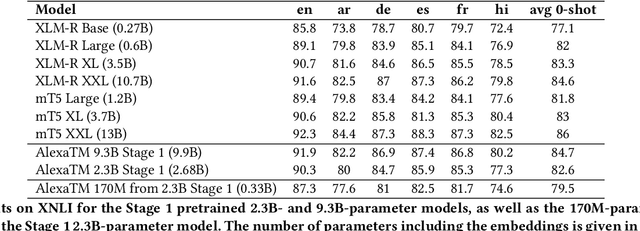
We present results from a large-scale experiment on pretraining encoders with non-embedding parameter counts ranging from 700M to 9.3B, their subsequent distillation into smaller models ranging from 17M-170M parameters, and their application to the Natural Language Understanding (NLU) component of a virtual assistant system. Though we train using 70% spoken-form data, our teacher models perform comparably to XLM-R and mT5 when evaluated on the written-form Cross-lingual Natural Language Inference (XNLI) corpus. We perform a second stage of pretraining on our teacher models using in-domain data from our system, improving error rates by 3.86% relative for intent classification and 7.01% relative for slot filling. We find that even a 170M-parameter model distilled from our Stage 2 teacher model has 2.88% better intent classification and 7.69% better slot filling error rates when compared to the 2.3B-parameter teacher trained only on public data (Stage 1), emphasizing the importance of in-domain data for pretraining. When evaluated offline using labeled NLU data, our 17M-parameter Stage 2 distilled model outperforms both XLM-R Base (85M params) and DistillBERT (42M params) by 4.23% to 6.14%, respectively. Finally, we present results from a full virtual assistant experimentation platform, where we find that models trained using our pretraining and distillation pipeline outperform models distilled from 85M-parameter teachers by 3.74%-4.91% on an automatic measurement of full-system user dissatisfaction.
* KDD 2022