 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransformation-Grounded Image Generation Network for Novel 3D View Synthesis
Mar 08, 2017
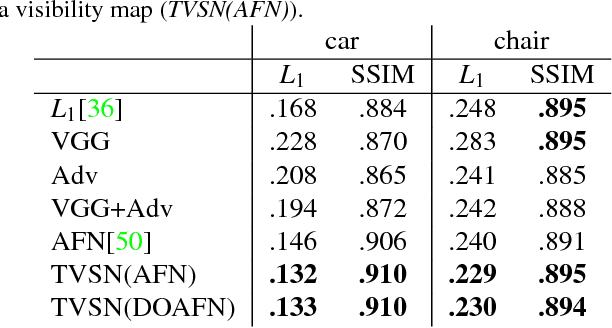


We present a transformation-grounded image generation network for novel 3D view synthesis from a single image. Instead of taking a 'blank slate' approach, we first explicitly infer the parts of the geometry visible both in the input and novel views and then re-cast the remaining synthesis problem as image completion. Specifically, we both predict a flow to move the pixels from the input to the novel view along with a novel visibility map that helps deal with occulsion/disocculsion. Next, conditioned on those intermediate results, we hallucinate (infer) parts of the object invisible in the input image. In addition to the new network structure, training with a combination of adversarial and perceptual loss results in a reduction in common artifacts of novel view synthesis such as distortions and holes, while successfully generating high frequency details and preserving visual aspects of the input image. We evaluate our approach on a wide range of synthetic and real examples. Both qualitative and quantitative results show our method achieves significantly better results compared to existing methods.
Diversified Texture Synthesis with Feed-forward Networks
Mar 05, 2017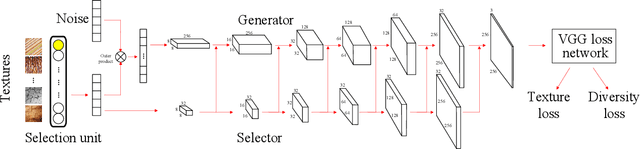


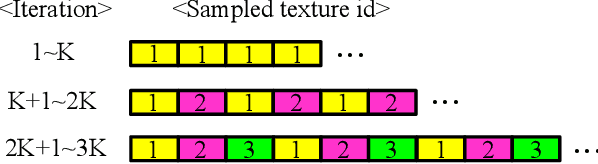
Recent progresses on deep discriminative and generative modeling have shown promising results on texture synthesis. However, existing feed-forward based methods trade off generality for efficiency, which suffer from many issues, such as shortage of generality (i.e., build one network per texture), lack of diversity (i.e., always produce visually identical output) and suboptimality (i.e., generate less satisfying visual effects). In this work, we focus on solving these issues for improved texture synthesis. We propose a deep generative feed-forward network which enables efficient synthesis of multiple textures within one single network and meaningful interpolation between them. Meanwhile, a suite of important techniques are introduced to achieve better convergence and diversity. With extensive experiments, we demonstrate the effectiveness of the proposed model and techniques for synthesizing a large number of textures and show its applications with the stylization.
Video Scene Parsing with Predictive Feature Learning
Dec 13, 2016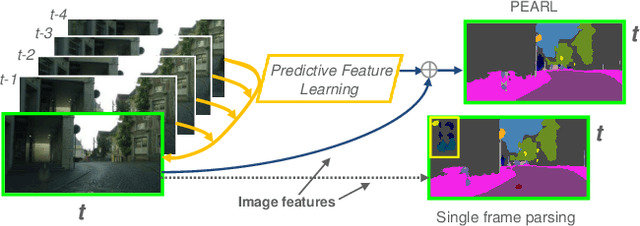
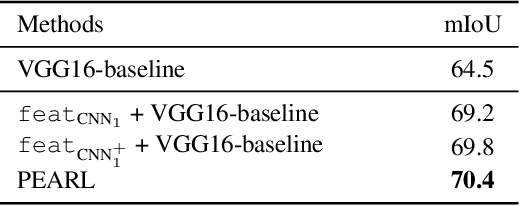

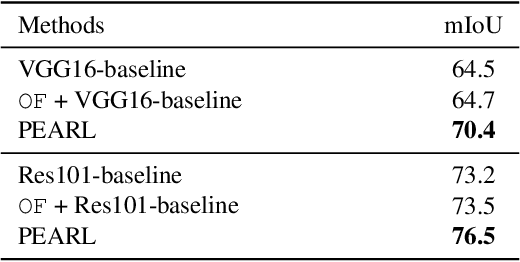
In this work, we address the challenging video scene parsing problem by developing effective representation learning methods given limited parsing annotations. In particular, we contribute two novel methods that constitute a unified parsing framework. (1) \textbf{Predictive feature learning}} from nearly unlimited unlabeled video data. Different from existing methods learning features from single frame parsing, we learn spatiotemporal discriminative features by enforcing a parsing network to predict future frames and their parsing maps (if available) given only historical frames. In this way, the network can effectively learn to capture video dynamics and temporal context, which are critical clues for video scene parsing, without requiring extra manual annotations. (2) \textbf{Prediction steering parsing}} architecture that effectively adapts the learned spatiotemporal features to scene parsing tasks and provides strong guidance for any off-the-shelf parsing model to achieve better video scene parsing performance. Extensive experiments over two challenging datasets, Cityscapes and Camvid, have demonstrated the effectiveness of our methods by showing significant improvement over well-established baselines.
Attribute2Image: Conditional Image Generation from Visual Attributes
Oct 08, 2016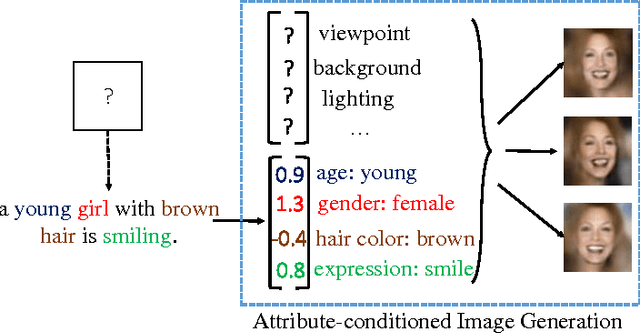
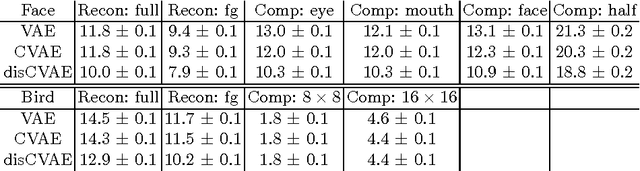
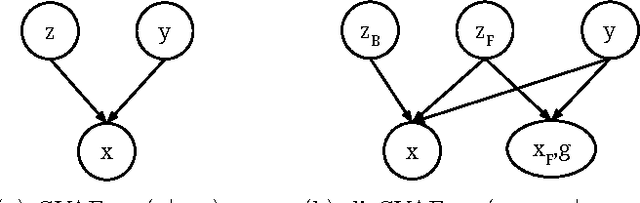
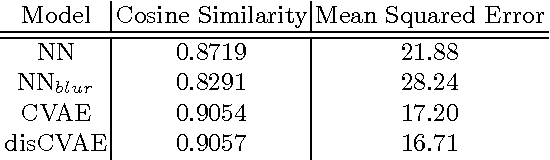
This paper investigates a novel problem of generating images from visual attributes. We model the image as a composite of foreground and background and develop a layered generative model with disentangled latent variables that can be learned end-to-end using a variational auto-encoder. We experiment with natural images of faces and birds and demonstrate that the proposed models are capable of generating realistic and diverse samples with disentangled latent representations. We use a general energy minimization algorithm for posterior inference of latent variables given novel images. Therefore, the learned generative models show excellent quantitative and visual results in the tasks of attribute-conditioned image reconstruction and completion.
Object Contour Detection with a Fully Convolutional Encoder-Decoder Network
Mar 15, 2016

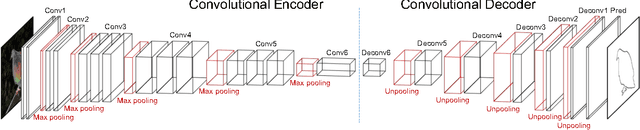

We develop a deep learning algorithm for contour detection with a fully convolutional encoder-decoder network. Different from previous low-level edge detection, our algorithm focuses on detecting higher-level object contours. Our network is trained end-to-end on PASCAL VOC with refined ground truth from inaccurate polygon annotations, yielding much higher precision in object contour detection than previous methods. We find that the learned model generalizes well to unseen object classes from the same super-categories on MS COCO and can match state-of-the-art edge detection on BSDS500 with fine-tuning. By combining with the multiscale combinatorial grouping algorithm, our method can generate high-quality segmented object proposals, which significantly advance the state-of-the-art on PASCAL VOC (improving average recall from 0.62 to 0.67) with a relatively small amount of candidates ($\sim$1660 per image).
Deep Interactive Object Selection
Mar 13, 2016
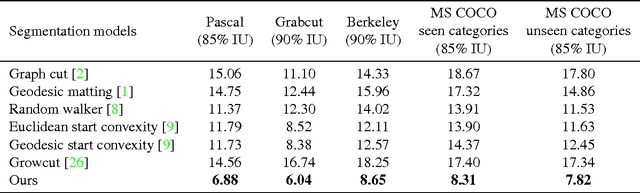

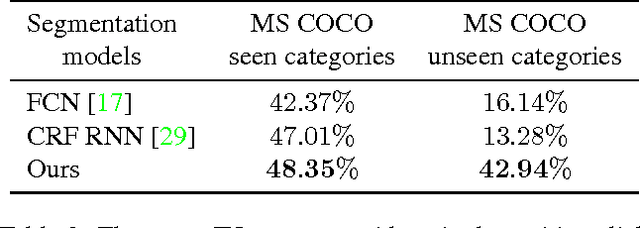
Interactive object selection is a very important research problem and has many applications. Previous algorithms require substantial user interactions to estimate the foreground and background distributions. In this paper, we present a novel deep learning based algorithm which has a much better understanding of objectness and thus can reduce user interactions to just a few clicks. Our algorithm transforms user provided positive and negative clicks into two Euclidean distance maps which are then concatenated with the RGB channels of images to compose (image, user interactions) pairs. We generate many of such pairs by combining several random sampling strategies to model user click patterns and use them to fine tune deep Fully Convolutional Networks (FCNs). Finally the output probability maps of our FCN 8s model is integrated with graph cut optimization to refine the boundary segments. Our model is trained on the PASCAL segmentation dataset and evaluated on other datasets with different object classes. Experimental results on both seen and unseen objects clearly demonstrate that our algorithm has a good generalization ability and is superior to all existing interactive object selection approaches.
Weakly-supervised Disentangling with Recurrent Transformations for 3D View Synthesis
Jan 05, 2016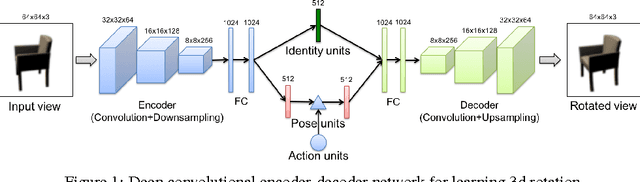
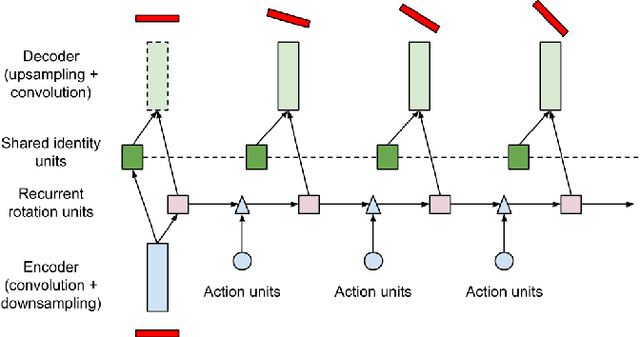
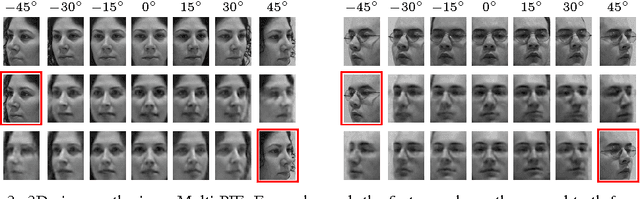
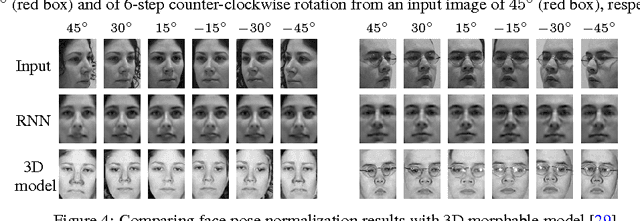
An important problem for both graphics and vision is to synthesize novel views of a 3D object from a single image. This is particularly challenging due to the partial observability inherent in projecting a 3D object onto the image space, and the ill-posedness of inferring object shape and pose. However, we can train a neural network to address the problem if we restrict our attention to specific object categories (in our case faces and chairs) for which we can gather ample training data. In this paper, we propose a novel recurrent convolutional encoder-decoder network that is trained end-to-end on the task of rendering rotated objects starting from a single image. The recurrent structure allows our model to capture long-term dependencies along a sequence of transformations. We demonstrate the quality of its predictions for human faces on the Multi-PIE dataset and for a dataset of 3D chair models, and also show its ability to disentangle latent factors of variation (e.g., identity and pose) without using full supervision.