 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerformance Evaluation of Large Language Models in Statistical Programming
Feb 18, 2025The programming capabilities of large language models (LLMs) have revolutionized automatic code generation and opened new avenues for automatic statistical analysis. However, the validity and quality of these generated codes need to be systematically evaluated before they can be widely adopted. Despite their growing prominence, a comprehensive evaluation of statistical code generated by LLMs remains scarce in the literature. In this paper, we assess the performance of LLMs, including two versions of ChatGPT and one version of Llama, in the domain of SAS programming for statistical analysis. Our study utilizes a set of statistical analysis tasks encompassing diverse statistical topics and datasets. Each task includes a problem description, dataset information, and human-verified SAS code. We conduct a comprehensive assessment of the quality of SAS code generated by LLMs through human expert evaluation based on correctness, effectiveness, readability, executability, and the accuracy of output results. The analysis of rating scores reveals that while LLMs demonstrate usefulness in generating syntactically correct code, they struggle with tasks requiring deep domain understanding and may produce redundant or incorrect results. This study offers valuable insights into the capabilities and limitations of LLMs in statistical programming, providing guidance for future advancements in AI-assisted coding systems for statistical analysis.
Bridging the Data Gap in AI Reliability Research and Establishing DR-AIR, a Comprehensive Data Repository for AI Reliability
Feb 17, 2025



Artificial intelligence (AI) technology and systems have been advancing rapidly. However, ensuring the reliability of these systems is crucial for fostering public confidence in their use. This necessitates the modeling and analysis of reliability data specific to AI systems. A major challenge in AI reliability research, particularly for those in academia, is the lack of readily available AI reliability data. To address this gap, this paper focuses on conducting a comprehensive review of available AI reliability data and establishing DR-AIR: a data repository for AI reliability. Specifically, we introduce key measurements and data types for assessing AI reliability, along with the methodologies used to collect these data. We also provide a detailed description of the currently available datasets with illustrative examples. Furthermore, we outline the setup of the DR-AIR repository and demonstrate its practical applications. This repository provides easy access to datasets specifically curated for AI reliability research. We believe these efforts will significantly benefit the AI research community by facilitating access to valuable reliability data and promoting collaboration across various academic domains within AI. We conclude our paper with a call to action, encouraging the research community to contribute and share AI reliability data to further advance this critical field of study.
VISTA: Enhancing Long-Duration and High-Resolution Video Understanding by Video Spatiotemporal Augmentation
Dec 01, 2024



Current large multimodal models (LMMs) face significant challenges in processing and comprehending long-duration or high-resolution videos, which is mainly due to the lack of high-quality datasets. To address this issue from a data-centric perspective, we propose VISTA, a simple yet effective Video Spatiotemporal Augmentation framework that synthesizes long-duration and high-resolution video instruction-following pairs from existing video-caption datasets. VISTA spatially and temporally combines videos to create new synthetic videos with extended durations and enhanced resolutions, and subsequently produces question-answer pairs pertaining to these newly synthesized videos. Based on this paradigm, we develop seven video augmentation methods and curate VISTA-400K, a video instruction-following dataset aimed at enhancing long-duration and high-resolution video understanding. Finetuning various video LMMs on our data resulted in an average improvement of 3.3% across four challenging benchmarks for long-video understanding. Furthermore, we introduce the first comprehensive high-resolution video understanding benchmark HRVideoBench, on which our finetuned models achieve a 6.5% performance gain. These results highlight the effectiveness of our framework.
GeoDiffuser: Geometry-Based Image Editing with Diffusion Models
Apr 22, 2024



The success of image generative models has enabled us to build methods that can edit images based on text or other user input. However, these methods are bespoke, imprecise, require additional information, or are limited to only 2D image edits. We present GeoDiffuser, a zero-shot optimization-based method that unifies common 2D and 3D image-based object editing capabilities into a single method. Our key insight is to view image editing operations as geometric transformations. We show that these transformations can be directly incorporated into the attention layers in diffusion models to implicitly perform editing operations. Our training-free optimization method uses an objective function that seeks to preserve object style but generate plausible images, for instance with accurate lighting and shadows. It also inpaints disoccluded parts of the image where the object was originally located. Given a natural image and user input, we segment the foreground object using SAM and estimate a corresponding transform which is used by our optimization approach for editing. GeoDiffuser can perform common 2D and 3D edits like object translation, 3D rotation, and removal. We present quantitative results, including a perceptual study, that shows how our approach is better than existing methods. Visit https://ivl.cs.brown.edu/research/geodiffuser.html for more information.
Statistical Perspectives on Reliability of Artificial Intelligence Systems
Nov 09, 2021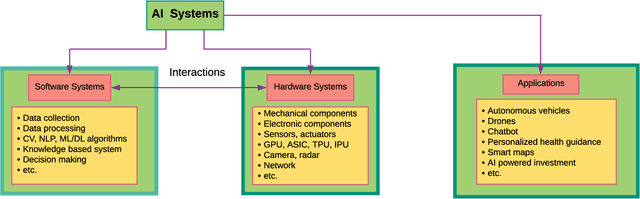
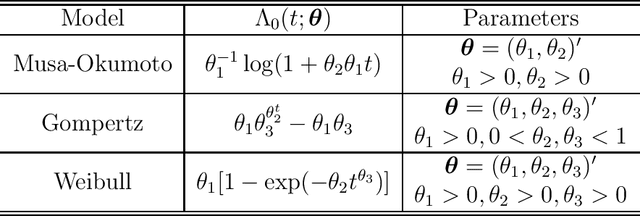
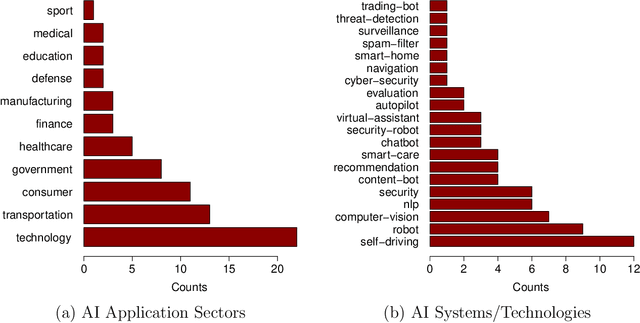
Artificial intelligence (AI) systems have become increasingly popular in many areas. Nevertheless, AI technologies are still in their developing stages, and many issues need to be addressed. Among those, the reliability of AI systems needs to be demonstrated so that the AI systems can be used with confidence by the general public. In this paper, we provide statistical perspectives on the reliability of AI systems. Different from other considerations, the reliability of AI systems focuses on the time dimension. That is, the system can perform its designed functionality for the intended period. We introduce a so-called SMART statistical framework for AI reliability research, which includes five components: Structure of the system, Metrics of reliability, Analysis of failure causes, Reliability assessment, and Test planning. We review traditional methods in reliability data analysis and software reliability, and discuss how those existing methods can be transformed for reliability modeling and assessment of AI systems. We also describe recent developments in modeling and analysis of AI reliability and outline statistical research challenges in this area, including out-of-distribution detection, the effect of the training set, adversarial attacks, model accuracy, and uncertainty quantification, and discuss how those topics can be related to AI reliability, with illustrative examples. Finally, we discuss data collection and test planning for AI reliability assessment and how to improve system designs for higher AI reliability. The paper closes with some concluding remarks.
Reliability Analysis of Artificial Intelligence Systems Using Recurrent Events Data from Autonomous Vehicles
Feb 02, 2021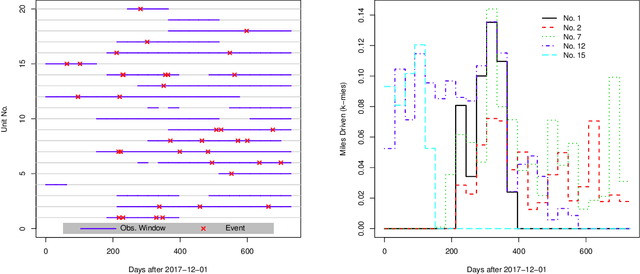


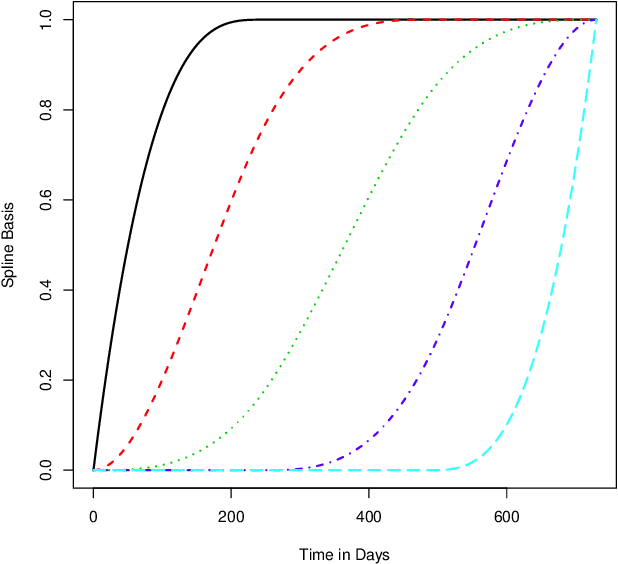
Artificial intelligence (AI) systems have become increasingly common and the trend will continue. Examples of AI systems include autonomous vehicles (AV), computer vision, natural language processing, and AI medical experts. To allow for safe and effective deployment of AI systems, the reliability of such systems needs to be assessed. Traditionally, reliability assessment is based on reliability test data and the subsequent statistical modeling and analysis. The availability of reliability data for AI systems, however, is limited because such data are typically sensitive and proprietary. The California Department of Motor Vehicles (DMV) oversees and regulates an AV testing program, in which many AV manufacturers are conducting AV road tests. Manufacturers participating in the program are required to report recurrent disengagement events to California DMV. This information is being made available to the public. In this paper, we use recurrent disengagement events as a representation of the reliability of the AI system in AV, and propose a statistical framework for modeling and analyzing the recurrent events data from AV driving tests. We use traditional parametric models in software reliability and propose a new nonparametric model based on monotonic splines to describe the event process. We develop inference procedures for selecting the best models, quantifying uncertainty, and testing heterogeneity in the event process. We then analyze the recurrent events data from four AV manufacturers, and make inferences on the reliability of the AI systems in AV. We also describe how the proposed analysis can be applied to assess the reliability of other AI systems.
Nested Scale Editing for Conditional Image Synthesis
Jun 03, 2020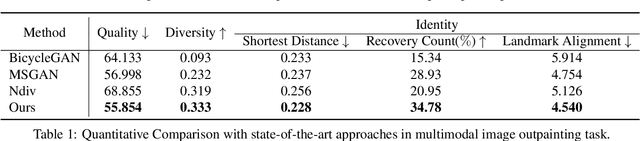
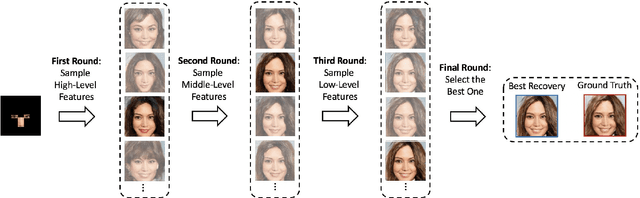
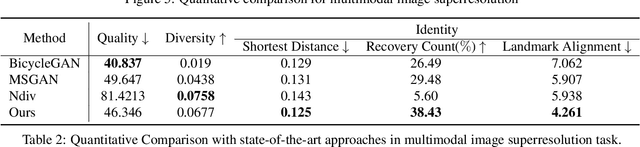
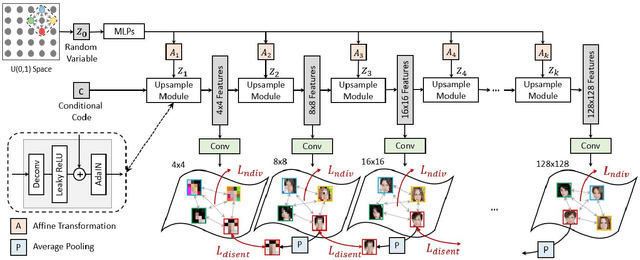
We propose an image synthesis approach that provides stratified navigation in the latent code space. With a tiny amount of partial or very low-resolution image, our approach can consistently out-perform state-of-the-art counterparts in terms of generating the closest sampled image to the ground truth. We achieve this through scale-independent editing while expanding scale-specific diversity. Scale-independence is achieved with a nested scale disentanglement loss. Scale-specific diversity is created by incorporating a progressive diversification constraint. We introduce semantic persistency across the scales by sharing common latent codes. Together they provide better control of the image synthesis process. We evaluate the effectiveness of our proposed approach through various tasks, including image outpainting, image superresolution, and cross-domain image translation.
Liquid Warping GAN: A Unified Framework for Human Motion Imitation, Appearance Transfer and Novel View Synthesis
Oct 01, 2019
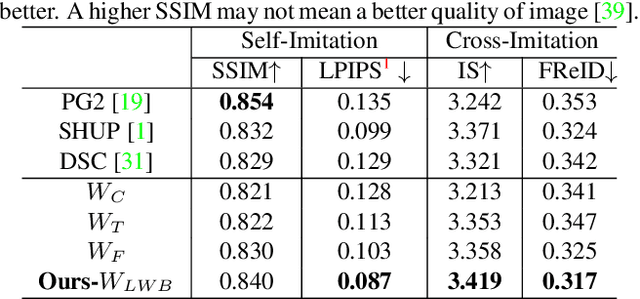
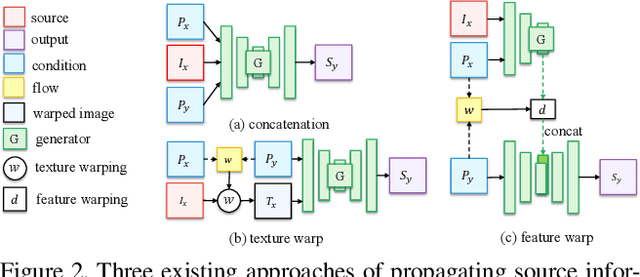
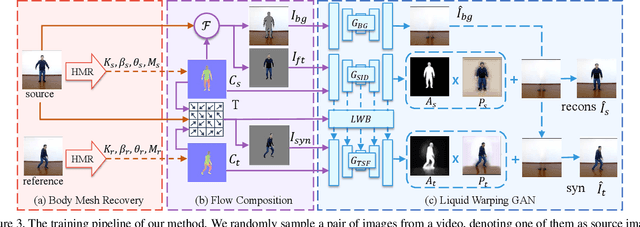
We tackle the human motion imitation, appearance transfer, and novel view synthesis within a unified framework, which means that the model once being trained can be used to handle all these tasks. The existing task-specific methods mainly use 2D keypoints (pose) to estimate the human body structure. However, they only expresses the position information with no abilities to characterize the personalized shape of the individual person and model the limbs rotations. In this paper, we propose to use a 3D body mesh recovery module to disentangle the pose and shape, which can not only model the joint location and rotation but also characterize the personalized body shape. To preserve the source information, such as texture, style, color, and face identity, we propose a Liquid Warping GAN with Liquid Warping Block (LWB) that propagates the source information in both image and feature spaces, and synthesizes an image with respect to the reference. Specifically, the source features are extracted by a denoising convolutional auto-encoder for characterizing the source identity well. Furthermore, our proposed method is able to support a more flexible warping from multiple sources. In addition, we build a new dataset, namely Impersonator (iPER) dataset, for the evaluation of human motion imitation, appearance transfer, and novel view synthesis. Extensive experiments demonstrate the effectiveness of our method in several aspects, such as robustness in occlusion case and preserving face identity, shape consistency and clothes details. All codes and datasets are available on https://svip-lab.github.io/project/impersonator.html