 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenoised Non-Local Neural Network for Semantic Segmentation
Oct 27, 2021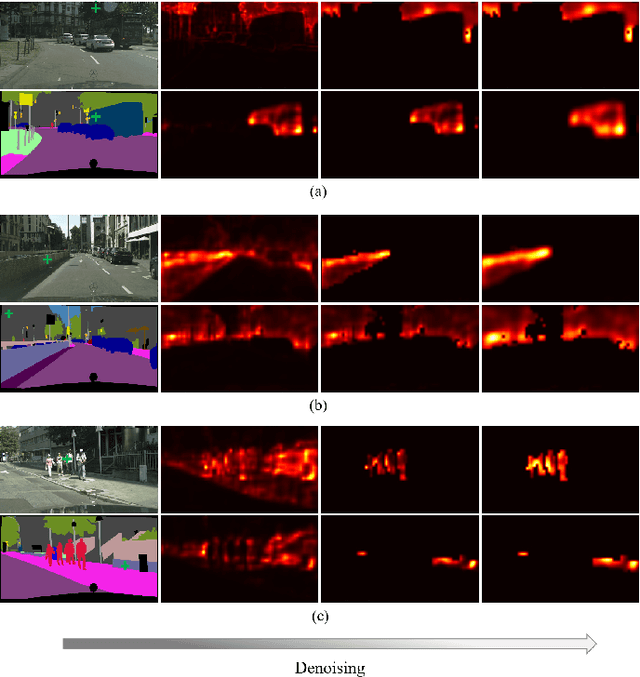


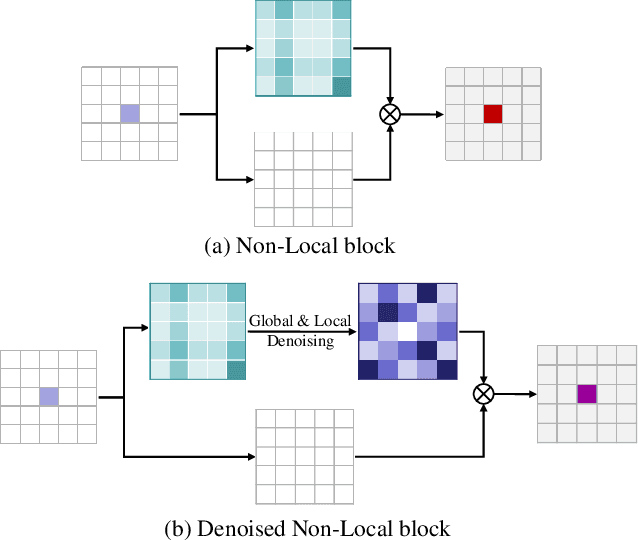
The non-local network has become a widely used technique for semantic segmentation, which computes an attention map to measure the relationships of each pixel pair. However, most of the current popular non-local models tend to ignore the phenomenon that the calculated attention map appears to be very noisy, containing inter-class and intra-class inconsistencies, which lowers the accuracy and reliability of the non-local methods. In this paper, we figuratively denote these inconsistencies as attention noises and explore the solutions to denoise them. Specifically, we inventively propose a Denoised Non-Local Network (Denoised NL), which consists of two primary modules, i.e., the Global Rectifying (GR) block and the Local Retention (LR) block, to eliminate the inter-class and intra-class noises respectively. First, GR adopts the class-level predictions to capture a binary map to distinguish whether the selected two pixels belong to the same category. Second, LR captures the ignored local dependencies and further uses them to rectify the unwanted hollows in the attention map. The experimental results on two challenging semantic segmentation datasets demonstrate the superior performance of our model. Without any external training data, our proposed Denoised NL can achieve the state-of-the-art performance of 83.5\% and 46.69\% mIoU on Cityscapes and ADE20K, respectively.
Bone Marrow Cell Recognition: Training Deep Object Detection with A New Loss Function
Oct 25, 2021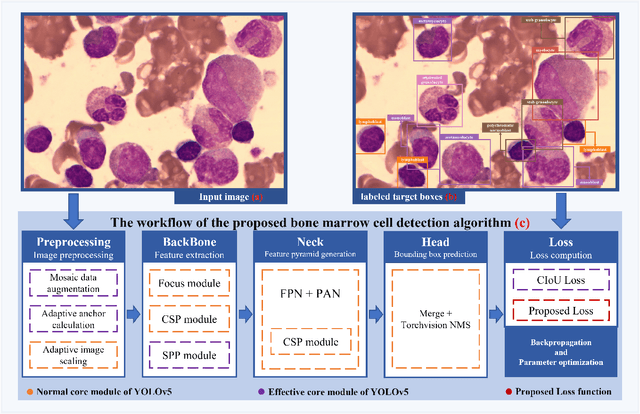
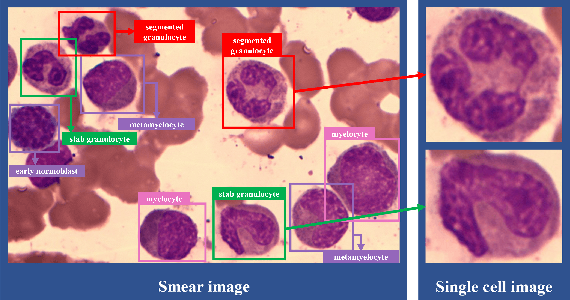
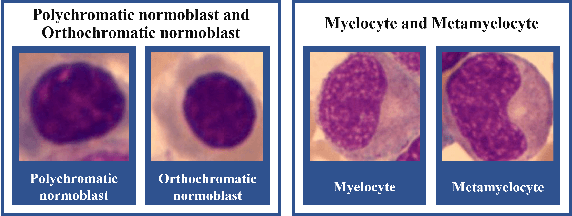
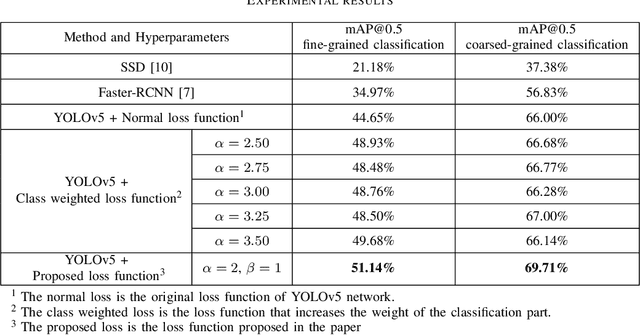
For a long time, bone marrow cell morphology examination has been an essential tool for diagnosing blood diseases. However, it is still mainly dependent on the subjective diagnosis of experienced doctors, and there is no objective quantitative standard. Therefore, it is crucial to study a robust bone marrow cell detection algorithm for a quantitative automatic analysis system. Currently, due to the dense distribution of cells in the bone marrow smear and the diverse cell classes, the detection of bone marrow cells is difficult. The existing bone marrow cell detection algorithms are still insufficient for the automatic analysis system of bone marrow smears. This paper proposes a bone marrow cell detection algorithm based on the YOLOv5 network, trained by minimizing a novel loss function. The classification method of bone marrow cell detection tasks is the basis of the proposed novel loss function. Since bone marrow cells are classified according to series and stages, part of the classes in adjacent stages are similar. The proposed novel loss function considers the similarity between bone marrow cell classes, increases the penalty for prediction errors between dissimilar classes, and reduces the penalty for prediction errors between similar classes. The results show that the proposed loss function effectively improves the algorithm's performance, and the proposed bone marrow cell detection algorithm has achieved better performance than other cell detection algorithms.
FedIPR: Ownership Verification for Federated Deep Neural Network Models
Sep 27, 2021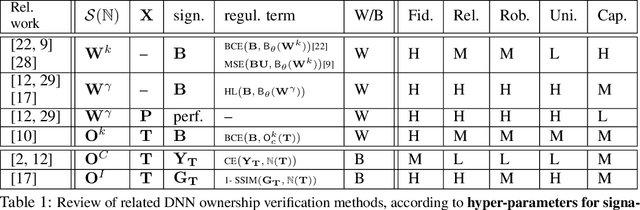
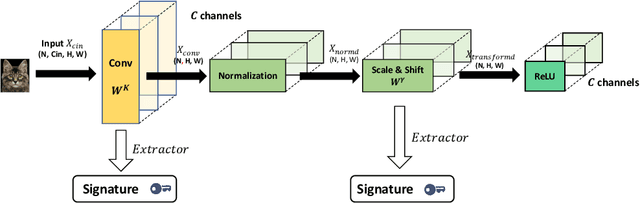
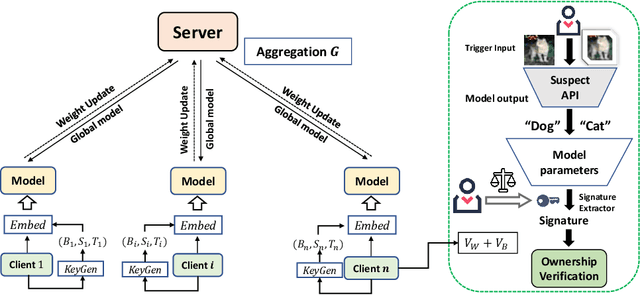
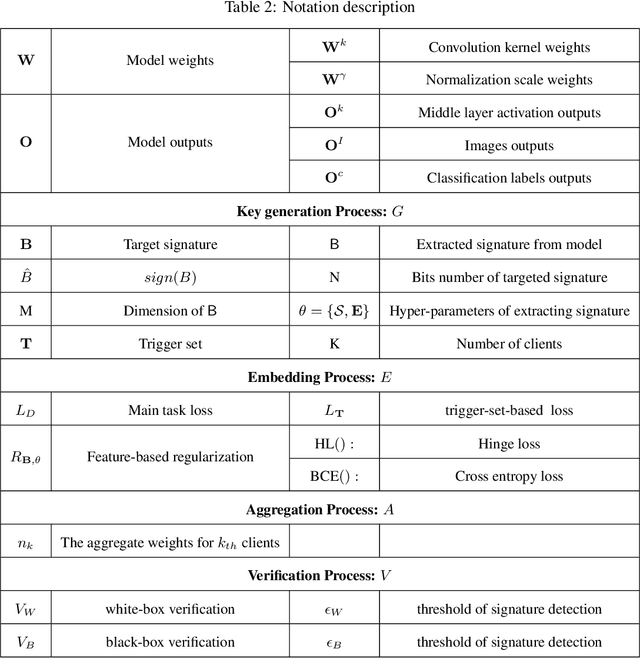
Federated learning models must be protected against plagiarism since these models are built upon valuable training data owned by multiple institutions or people.This paper illustrates a novel federated deep neural network (FedDNN) ownership verification scheme that allows ownership signatures to be embedded and verified to claim legitimate intellectual property rights (IPR) of FedDNN models, in case that models are illegally copied, re-distributed or misused. The effectiveness of embedded ownership signatures is theoretically justified by proved condition sunder which signatures can be embedded and detected by multiple clients with-out disclosing private signatures. Extensive experimental results on CIFAR10,CIFAR100 image datasets demonstrate that varying bit-lengths signatures can be embedded and reliably detected without affecting models classification performances. Signatures are also robust against removal attacks including fine-tuning and pruning.
Geometry-Based Stochastic Line-of-Sight Probability Model for A2G Channels under Urban Scenarios
Sep 06, 2021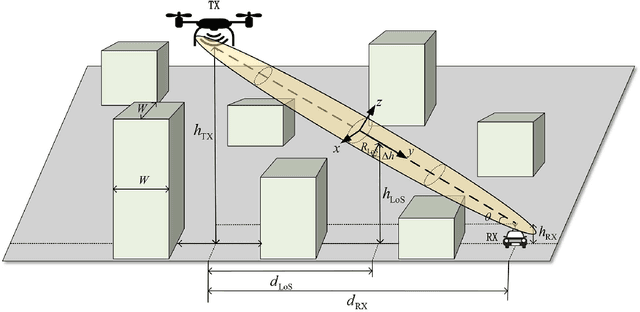
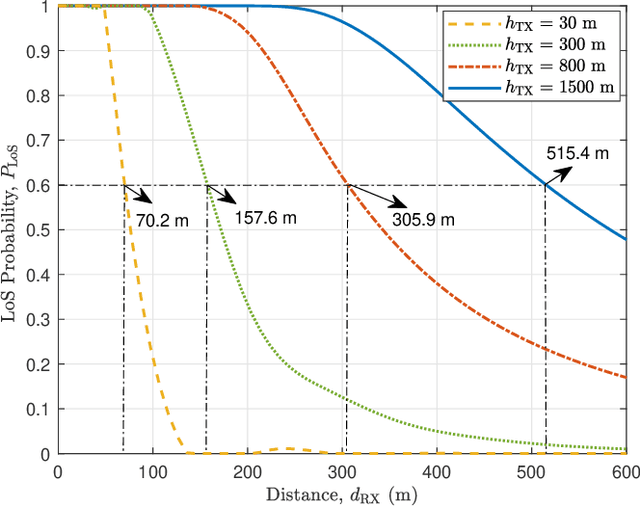
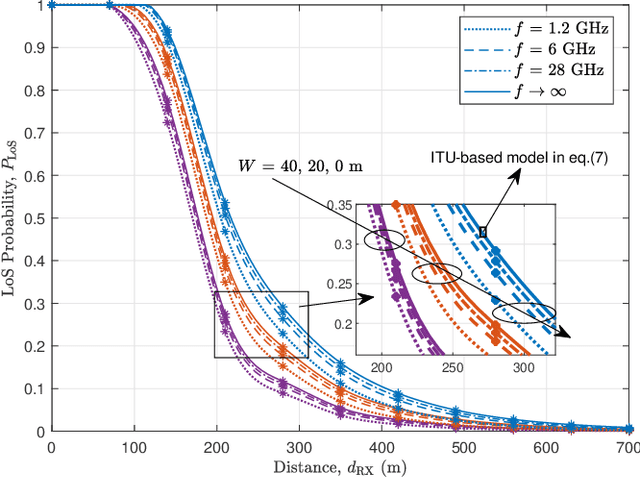
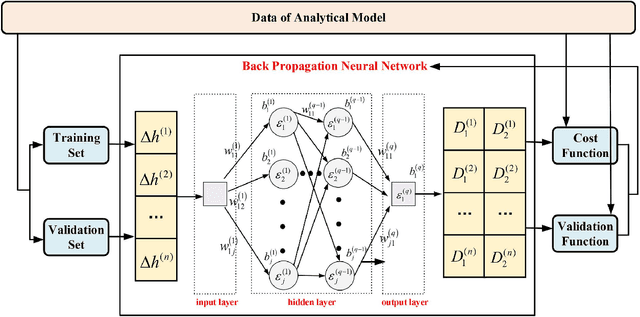
Line-of-sight (LoS) path is essential for the reliability of air-to-ground (A2G) communications, but the existence of LoS path is difficult to predict due to random obstacles on the ground. Based on the statistical geographic information and Fresnel clearance zone, a general stochastic LoS probability model for three-dimensional (3D) A2G channels under urban scenarios is developed. By considering the factors, i.e., building height distribution, building width, building space, carrier frequency, and transceiver's heights, the proposed model is suitable for different frequencies and altitudes. Moreover, in order to get a closed-form expression and reduce the computational complexity, an approximate parametric model is also built with the machine-learning (ML) method to estimate model parameters. The simulation results show that the proposed model has good consistency with existing models at the low altitude. When the altitude increases, it has better performance by comparing with that of the ray-tracing Monte-Carlo simulation data. The analytical results of proposed model are helpful for the channel modeling and performance analysis such as cell coverage, outage probability, and bit error rate in A2G communications.
Stimuli-Aware Visual Emotion Analysis
Sep 04, 2021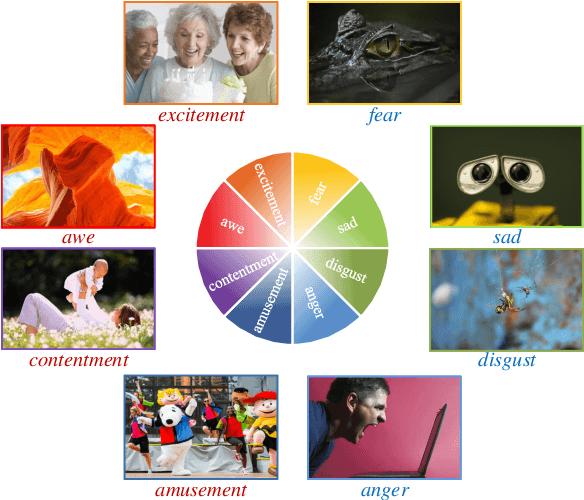

Visual emotion analysis (VEA) has attracted great attention recently, due to the increasing tendency of expressing and understanding emotions through images on social networks. Different from traditional vision tasks, VEA is inherently more challenging since it involves a much higher level of complexity and ambiguity in human cognitive process. Most of the existing methods adopt deep learning techniques to extract general features from the whole image, disregarding the specific features evoked by various emotional stimuli. Inspired by the \textit{Stimuli-Organism-Response (S-O-R)} emotion model in psychological theory, we proposed a stimuli-aware VEA method consisting of three stages, namely stimuli selection (S), feature extraction (O) and emotion prediction (R). First, specific emotional stimuli (i.e., color, object, face) are selected from images by employing the off-the-shelf tools. To the best of our knowledge, it is the first time to introduce stimuli selection process into VEA in an end-to-end network. Then, we design three specific networks, i.e., Global-Net, Semantic-Net and Expression-Net, to extract distinct emotional features from different stimuli simultaneously. Finally, benefiting from the inherent structure of Mikel's wheel, we design a novel hierarchical cross-entropy loss to distinguish hard false examples from easy ones in an emotion-specific manner. Experiments demonstrate that the proposed method consistently outperforms the state-of-the-art approaches on four public visual emotion datasets. Ablation study and visualizations further prove the validity and interpretability of our method.
* Accepted by TIP
An Integrated Framework for the Heterogeneous Spatio-Spectral-Temporal Fusion of Remote Sensing Images
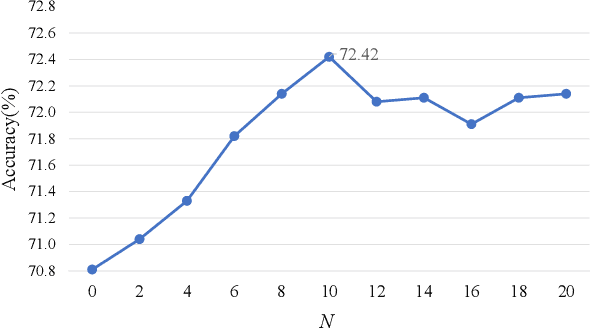
Sep 01, 2021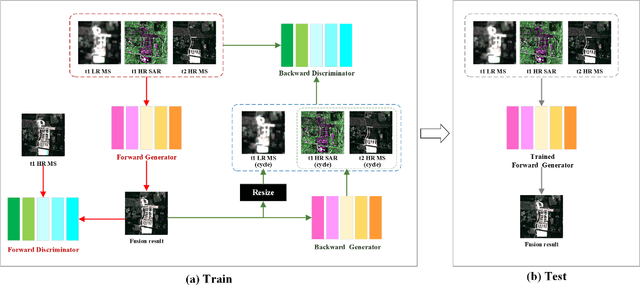
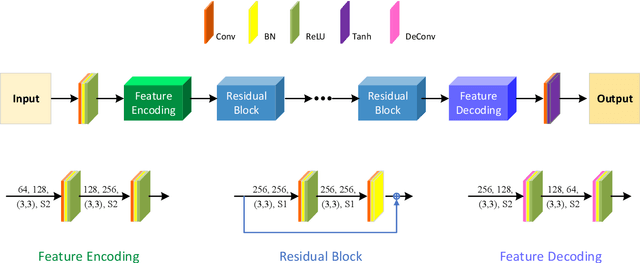
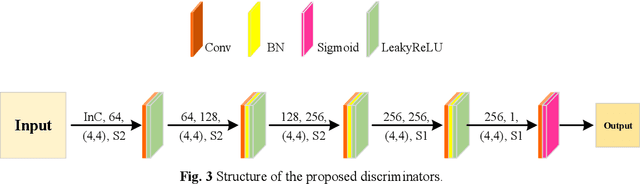
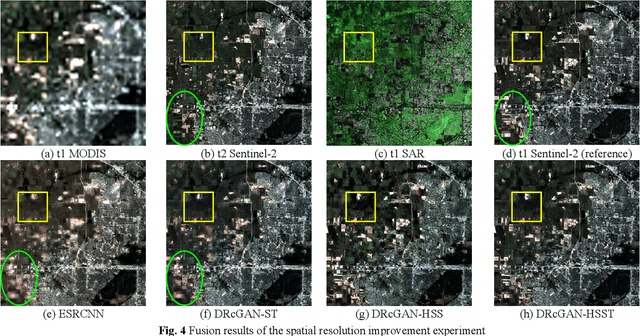
Image fusion technology is widely used to fuse the complementary information between multi-source remote sensing images. Inspired by the frontier of deep learning, this paper first proposes a heterogeneous-integrated framework based on a novel deep residual cycle GAN. The proposed network consists of a forward fusion part and a backward degeneration feedback part. The forward part generates the desired fusion result from the various observations; the backward degeneration feedback part considers the imaging degradation process and regenerates the observations inversely from the fusion result. The proposed network can effectively fuse not only the homogeneous but also the heterogeneous information. In addition, for the first time, a heterogeneous-integrated fusion framework is proposed to simultaneously merge the complementary heterogeneous spatial, spectral and temporal information of multi-source heterogeneous observations. The proposed heterogeneous-integrated framework also provides a uniform mode that can complete various fusion tasks, including heterogeneous spatio-spectral fusion, spatio-temporal fusion, and heterogeneous spatio-spectral-temporal fusion. Experiments are conducted for two challenging scenarios of land cover changes and thick cloud coverage. Images from many remote sensing satellites, including MODIS, Landsat-8, Sentinel-1, and Sentinel-2, are utilized in the experiments. Both qualitative and quantitative evaluations confirm the effectiveness of the proposed method.
LocTex: Learning Data-Efficient Visual Representations from Localized Textual Supervision
Aug 26, 2021



Computer vision tasks such as object detection and semantic/instance segmentation rely on the painstaking annotation of large training datasets. In this paper, we propose LocTex that takes advantage of the low-cost localized textual annotations (i.e., captions and synchronized mouse-over gestures) to reduce the annotation effort. We introduce a contrastive pre-training framework between images and captions and propose to supervise the cross-modal attention map with rendered mouse traces to provide coarse localization signals. Our learned visual features capture rich semantics (from free-form captions) and accurate localization (from mouse traces), which are very effective when transferred to various downstream vision tasks. Compared with ImageNet supervised pre-training, LocTex can reduce the size of the pre-training dataset by 10x or the target dataset by 2x while achieving comparable or even improved performance on COCO instance segmentation. When provided with the same amount of annotations, LocTex achieves around 4% higher accuracy than the previous state-of-the-art "vision+language" pre-training approach on the task of PASCAL VOC image classification.
A Dynamic 3D Spontaneous Micro-expression Database: Establishment and Evaluation
Aug 22, 2021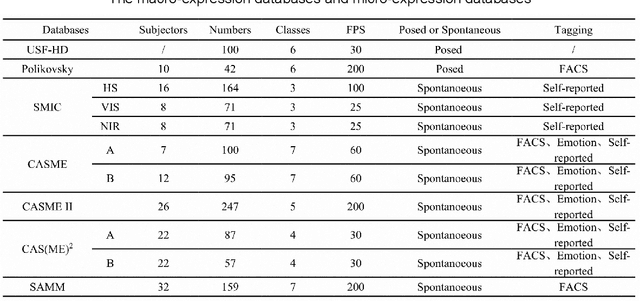
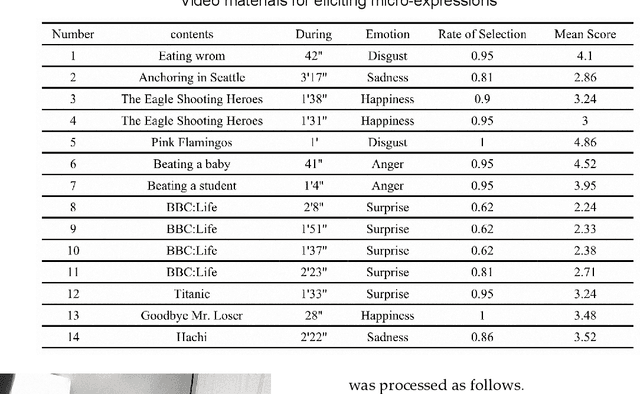


Micro-expressions are spontaneous, unconscious facial movements that show people's true inner emotions and have great potential in related fields of psychological testing. Since the face is a 3D deformation object, the occurrence of an expression can arouse spatial deformation of the face, but limited by the available databases are 2D videos, lacking the description of 3D spatial information of micro-expressions. Therefore, we proposed a new micro-expression database containing 2D video sequences and 3D point clouds sequences. The database includes 259 micro-expressions sequences, and these samples were classified using the objective method based on facial action coding system, as well as the non-objective method that combines video contents and participants' self-reports. We extracted 2D and 3D features using the local binary patterns on three orthogonal planes (LBP-TOP) and curvature algorithms, respectively, and evaluated the classification accuracies of these two features and their fusion results with leave-one-subject-out (LOSO) and 10-fold cross-validation. Further, we performed various neural network algorithms for database classification, the results show that classification accuracies are improved by fusing 3D features than using only 2D features. The database offers original and cropped micro-expression samples, which will facilitate the exploration and research on 3D Spatio-temporal features of micro-expressions.
Is Pseudo-Lidar needed for Monocular 3D Object detection?
Aug 13, 2021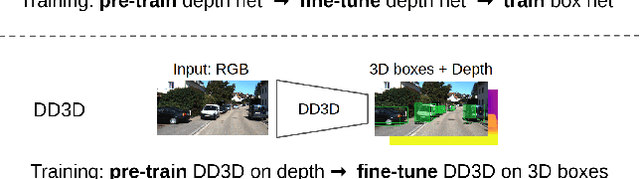
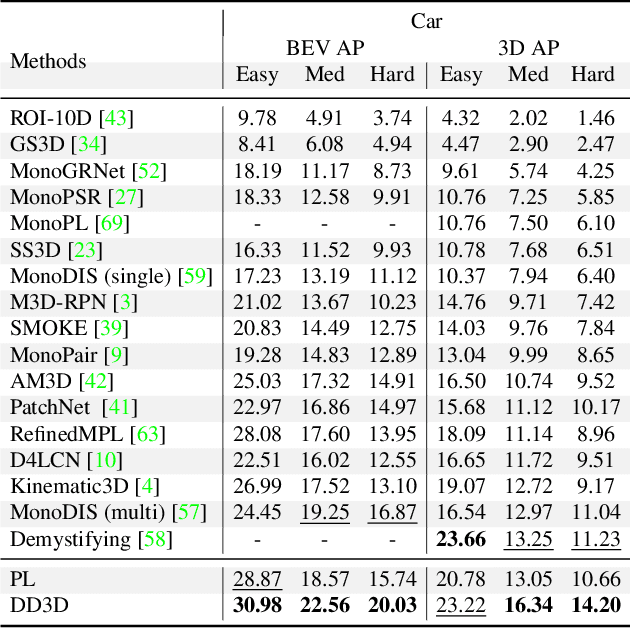
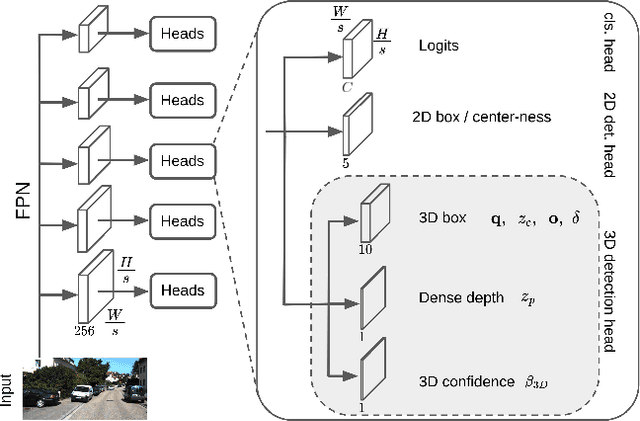
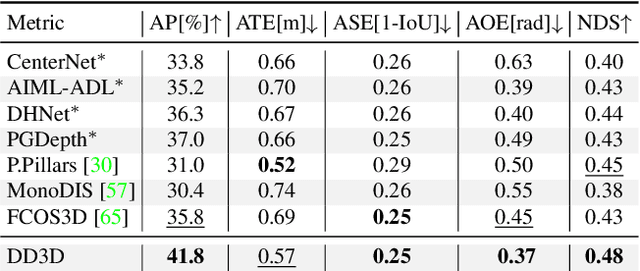
Recent progress in 3D object detection from single images leverages monocular depth estimation as a way to produce 3D pointclouds, turning cameras into pseudo-lidar sensors. These two-stage detectors improve with the accuracy of the intermediate depth estimation network, which can itself be improved without manual labels via large-scale self-supervised learning. However, they tend to suffer from overfitting more than end-to-end methods, are more complex, and the gap with similar lidar-based detectors remains significant. In this work, we propose an end-to-end, single stage, monocular 3D object detector, DD3D, that can benefit from depth pre-training like pseudo-lidar methods, but without their limitations. Our architecture is designed for effective information transfer between depth estimation and 3D detection, allowing us to scale with the amount of unlabeled pre-training data. Our method achieves state-of-the-art results on two challenging benchmarks, with 16.34% and 9.28% AP for Cars and Pedestrians (respectively) on the KITTI-3D benchmark, and 41.5% mAP on NuScenes.
Coupling Model-Driven and Data-Driven Methods for Remote Sensing Image Restoration and Fusion
Aug 13, 2021
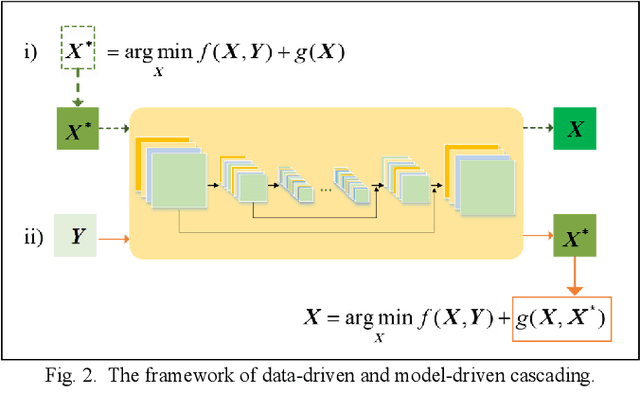
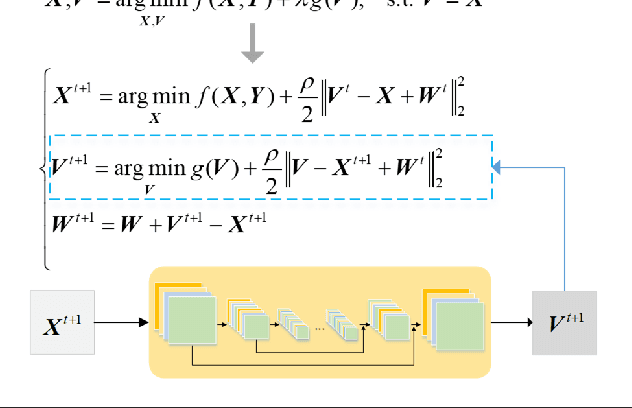
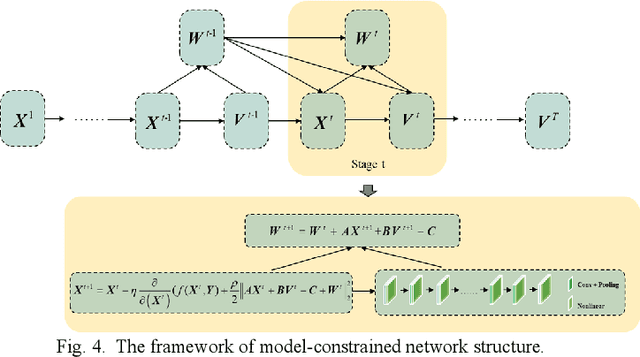
In the fields of image restoration and image fusion, model-driven methods and data-driven methods are the two representative frameworks. However, both approaches have their respective advantages and disadvantages. The model-driven methods consider the imaging mechanism, which is deterministic and theoretically reasonable; however, they cannot easily model complicated nonlinear problems. The data-driven methods have a stronger prior knowledge learning capability for huge data, especially for nonlinear statistical features; however, the interpretability of the networks is poor, and they are over-dependent on training data. In this paper, we systematically investigate the coupling of model-driven and data-driven methods, which has rarely been considered in the remote sensing image restoration and fusion communities. We are the first to summarize the coupling approaches into the following three categories: 1) data-driven and model-driven cascading methods; 2) variational models with embedded learning; and 3) model-constrained network learning methods. The typical existing and potential coupling methods for remote sensing image restoration and fusion are introduced with application examples. This paper also gives some new insights into the potential future directions, in terms of both methods and applications.