 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShared and Private Information Learning in Multimodal Sentiment Analysis with Deep Modal Alignment and Self-supervised Multi-Task Learning
May 15, 2023Designing an effective representation learning method for multimodal sentiment analysis tasks is a crucial research direction. The challenge lies in learning both shared and private information in a complete modal representation, which is difficult with uniform multimodal labels and a raw feature fusion approach. In this work, we propose a deep modal shared information learning module based on the covariance matrix to capture the shared information between modalities. Additionally, we use a label generation module based on a self-supervised learning strategy to capture the private information of the modalities. Our module is plug-and-play in multimodal tasks, and by changing the parameterization, it can adjust the information exchange relationship between the modes and learn the private or shared information between the specified modes. We also employ a multi-task learning strategy to help the model focus its attention on the modal differentiation training data. We provide a detailed formulation derivation and feasibility proof for the design of the deep modal shared information learning module. We conduct extensive experiments on three common multimodal sentiment analysis baseline datasets, and the experimental results validate the reliability of our model. Furthermore, we explore more combinatorial techniques for the use of the module. Our approach outperforms current state-of-the-art methods on most of the metrics of the three public datasets.
A Dynamic 3D Spontaneous Micro-expression Database: Establishment and Evaluation
Aug 22, 2021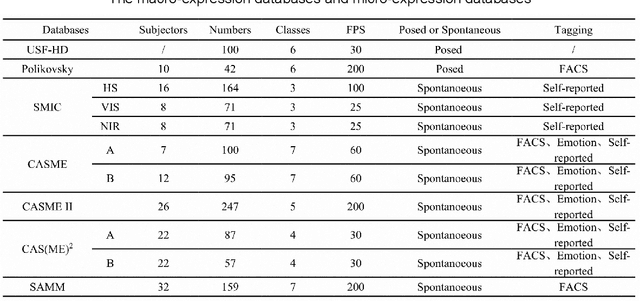
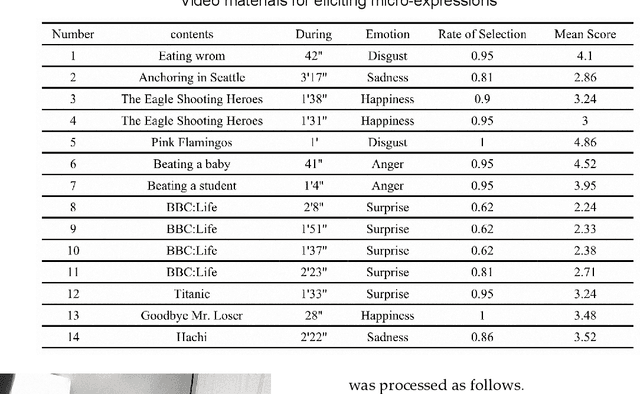


Micro-expressions are spontaneous, unconscious facial movements that show people's true inner emotions and have great potential in related fields of psychological testing. Since the face is a 3D deformation object, the occurrence of an expression can arouse spatial deformation of the face, but limited by the available databases are 2D videos, lacking the description of 3D spatial information of micro-expressions. Therefore, we proposed a new micro-expression database containing 2D video sequences and 3D point clouds sequences. The database includes 259 micro-expressions sequences, and these samples were classified using the objective method based on facial action coding system, as well as the non-objective method that combines video contents and participants' self-reports. We extracted 2D and 3D features using the local binary patterns on three orthogonal planes (LBP-TOP) and curvature algorithms, respectively, and evaluated the classification accuracies of these two features and their fusion results with leave-one-subject-out (LOSO) and 10-fold cross-validation. Further, we performed various neural network algorithms for database classification, the results show that classification accuracies are improved by fusing 3D features than using only 2D features. The database offers original and cropped micro-expression samples, which will facilitate the exploration and research on 3D Spatio-temporal features of micro-expressions.