 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnleashing the Potential of Mamba: Boosting a LiDAR 3D Sparse Detector by Using Cross-Model Knowledge Distillation
Sep 17, 2024



The LiDAR-based 3D object detector that strikes a balance between accuracy and speed is crucial for achieving real-time perception in autonomous driving and robotic navigation systems. To enhance the accuracy of point cloud detection, integrating global context for visual understanding improves the point clouds ability to grasp overall spatial information. However, many existing LiDAR detection models depend on intricate feature transformation and extraction processes, leading to poor real-time performance and high resource consumption, which limits their practical effectiveness. In this work, we propose a Faster LiDAR 3D object detection framework, called FASD, which implements heterogeneous model distillation by adaptively uniform cross-model voxel features. We aim to distill the transformer's capacity for high-performance sequence modeling into Mamba models with low FLOPs, achieving a significant improvement in accuracy through knowledge transfer. Specifically, Dynamic Voxel Group and Adaptive Attention strategies are integrated into the sparse backbone, creating a robust teacher model with scale-adaptive attention for effective global visual context modeling. Following feature alignment with the Adapter, we transfer knowledge from the Transformer to the Mamba through latent space feature supervision and span-head distillation, resulting in improved performance and an efficient student model. We evaluated the framework on the Waymo and nuScenes datasets, achieving a 4x reduction in resource consumption and a 1-2\% performance improvement over the current SoTA methods.
Short Range Correlation Transformer for Occluded Person Re-Identification
Jan 04, 2022
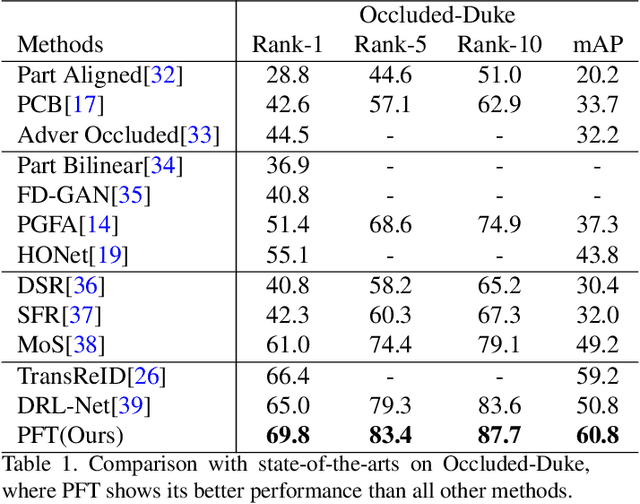
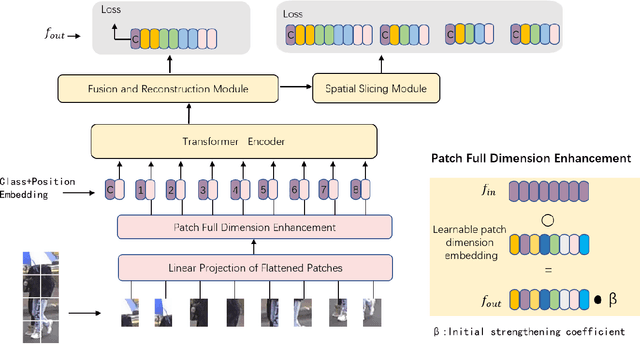
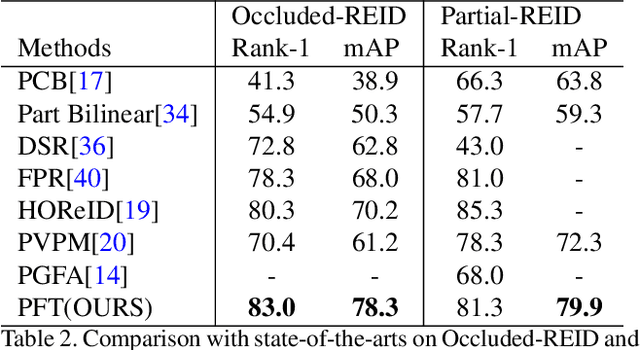
Occluded person re-identification is one of the challenging areas of computer vision, which faces problems such as inefficient feature representation and low recognition accuracy. Convolutional neural network pays more attention to the extraction of local features, therefore it is difficult to extract features of occluded pedestrians and the effect is not so satisfied. Recently, vision transformer is introduced into the field of re-identification and achieves the most advanced results by constructing the relationship of global features between patch sequences. However, the performance of vision transformer in extracting local features is inferior to that of convolutional neural network. Therefore, we design a partial feature transformer-based person re-identification framework named PFT. The proposed PFT utilizes three modules to enhance the efficiency of vision transformer. (1) Patch full dimension enhancement module. We design a learnable tensor with the same size as patch sequences, which is full-dimensional and deeply embedded in patch sequences to enrich the diversity of training samples. (2) Fusion and reconstruction module. We extract the less important part of obtained patch sequences, and fuse them with original patch sequence to reconstruct the original patch sequences. (3) Spatial Slicing Module. We slice and group patch sequences from spatial direction, which can effectively improve the short-range correlation of patch sequences. Experimental results over occluded and holistic re-identification datasets demonstrate that the proposed PFT network achieves superior performance consistently and outperforms the state-of-the-art methods.
Learning to Amend Facial Expression Representation via De-albino and Affinity
Mar 18, 2021


Facial Expression Recognition (FER) is a classification task that points to face variants. Hence, there are certain intimate relationships between facial expressions. We call them affinity features, which are barely taken into account by current FER algorithms. Besides, to capture the edge information of the image, Convolutional Neural Networks (CNNs) generally utilize a host of edge paddings. Although they are desirable, the feature map is deeply eroded after multi-layer convolution. We name what has formed in this process the albino features, which definitely weaken the representation of the expression. To tackle these challenges, we propose a novel architecture named Amend Representation Module (ARM). ARM is a substitute for the pooling layer. Theoretically, it could be embedded in any CNN with a pooling layer. ARM efficiently enhances facial expression representation from two different directions: 1) reducing the weight of eroded features to offset the side effect of padding, and 2) sharing affinity features over mini-batch to strengthen the representation learning. In terms of data imbalance, we designed a minimal random resampling (MRR) scheme to suppress network overfitting. Experiments on public benchmarks prove that our ARM boosts the performance of FER remarkably. The validation accuracies are respectively 90.55% on RAF-DB, 64.49% on Affect-Net, and 71.38% on FER2013, exceeding current state-of-the-art methods.
Joint Learning of Self-Representation and Indicator for Multi-View Image Clustering
May 11, 2019
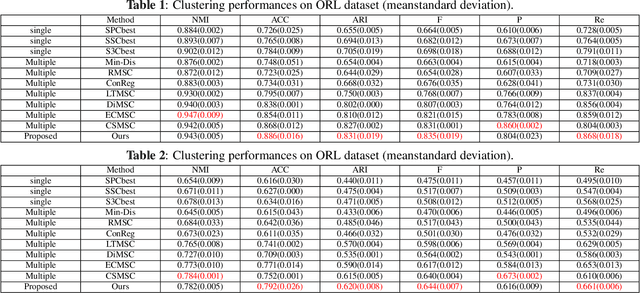
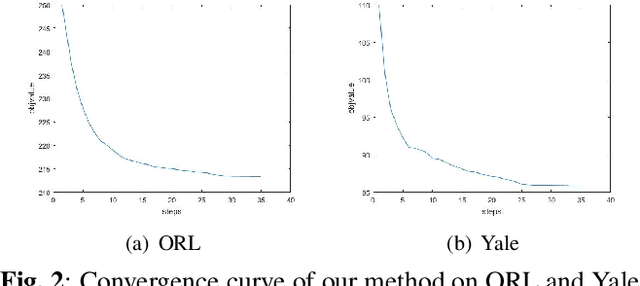
Multi-view subspace clustering aims to divide a set of multisource data into several groups according to their underlying subspace structure. Although the spectral clustering based methods achieve promotion in multi-view clustering, their utility is limited by the separate learning manner in which affinity matrix construction and cluster indicator estimation are isolated. In this paper, we propose to jointly learn the self-representation, continue and discrete cluster indicators in an unified model. Our model can explore the subspace structure of each view and fusion them to facilitate clustering simultaneously. Experimental results on two benchmark datasets demonstrate that our method outperforms other existing competitive multi-view clustering methods.