 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelving into 3D Action Anticipation from Streaming Videos
Jun 15, 2019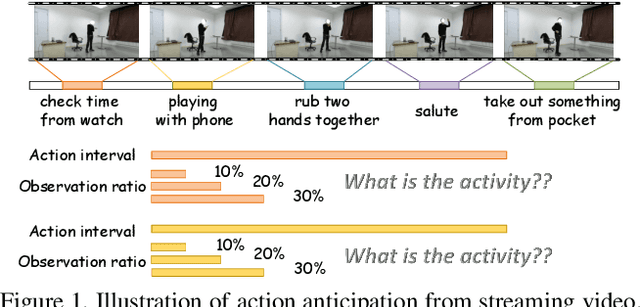
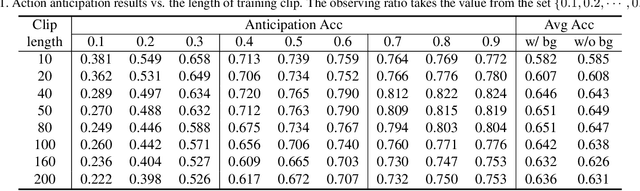
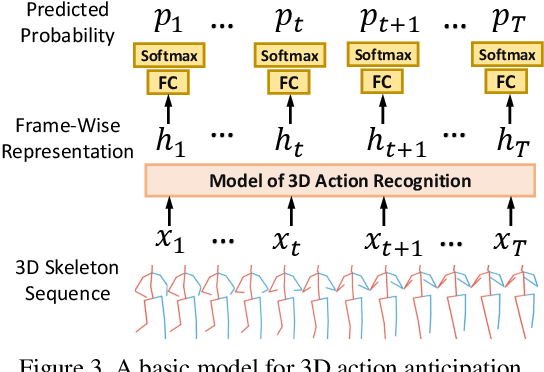
Action anticipation, which aims to recognize the action with a partial observation, becomes increasingly popular due to a wide range of applications. In this paper, we investigate the problem of 3D action anticipation from streaming videos with the target of understanding best practices for solving this problem. We first introduce several complementary evaluation metrics and present a basic model based on frame-wise action classification. To achieve better performance, we then investigate two important factors, i.e., the length of the training clip and clip sampling method. We also explore multi-task learning strategies by incorporating auxiliary information from two aspects: the full action representation and the class-agnostic action label. Our comprehensive experiments uncover the best practices for 3D action anticipation, and accordingly we propose a novel method with a multi-task loss. The proposed method considerably outperforms the recent methods and exhibits the state-of-the-art performance on standard benchmarks.
VRED: A Position-Velocity Recurrent Encoder-Decoder for Human Motion Prediction
Jun 15, 2019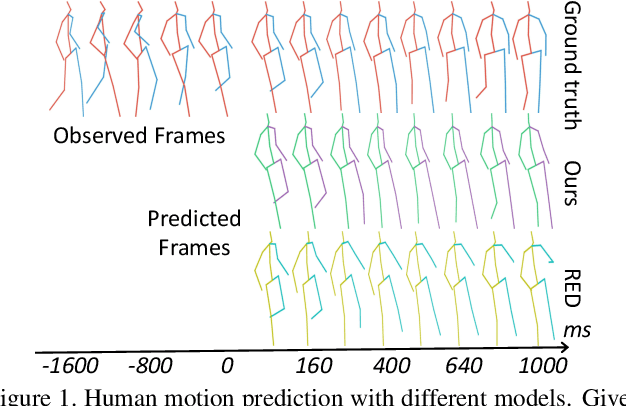
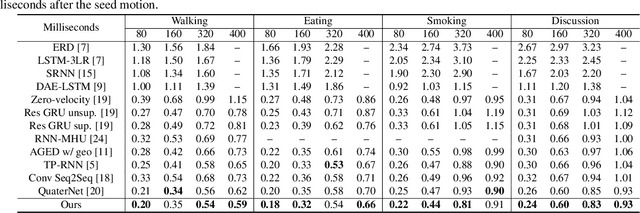
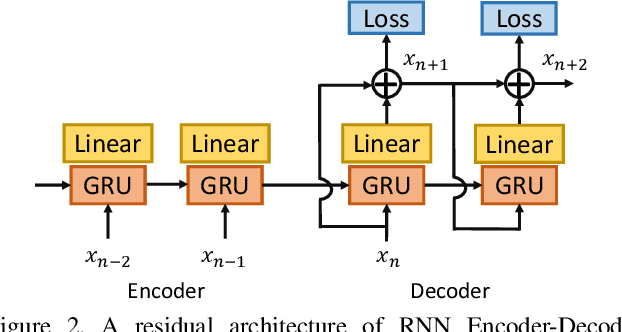
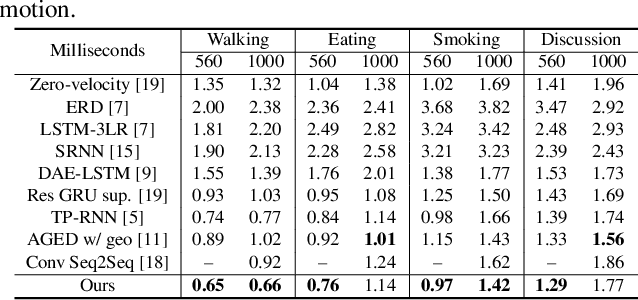
Human motion prediction, which aims to predict future human poses given past poses, has recently seen increased interest. Many recent approaches are based on Recurrent Neural Networks (RNN) which model human poses with exponential maps. These approaches neglect the pose velocity as well as temporal relation of different poses, and tend to converge to the mean pose or fail to generate natural-looking poses. We therefore propose a novel Position-Velocity Recurrent Encoder-Decoder (PVRED) for human motion prediction, which makes full use of pose velocities and temporal positional information. A temporal position embedding method is presented and a Position-Velocity RNN (PVRNN) is proposed. We also emphasize the benefits of quaternion parameterization of poses and design a novel trainable Quaternion Transformation (QT) layer, which is combined with a robust loss function during training. Experiments on two human motion prediction benchmarks show that our approach considerably outperforms the state-of-the-art methods for both short-term prediction and long-term prediction. In particular, our proposed approach can predict future human-like and meaningful poses in 4000 milliseconds.
Unsupervised Image Noise Modeling with Self-Consistent GAN
Jun 13, 2019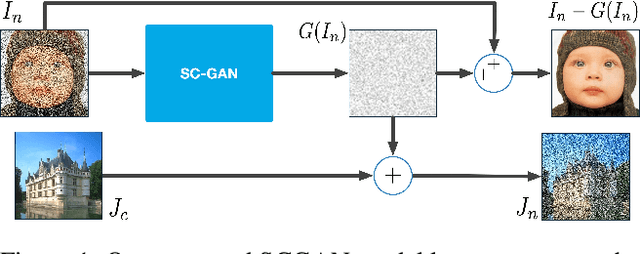

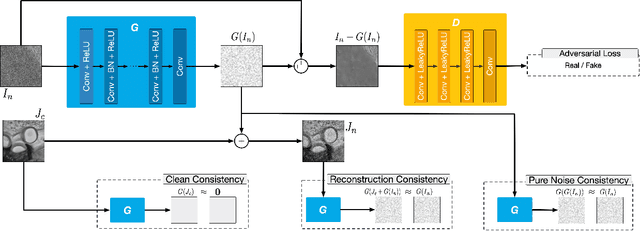

Noise modeling lies in the heart of many image processing tasks. However, existing deep learning methods for noise modeling generally require clean and noisy image pairs for model training; these image pairs are difficult to obtain in many realistic scenarios. To ameliorate this problem, we propose a self-consistent GAN (SCGAN), that can directly extract noise maps from noisy images, thus enabling unsupervised noise modeling. In particular, the SCGAN introduces three novel self-consistent constraints that are complementary to one another, viz.: the noise model should produce a zero response over a clean input; the noise model should return the same output when fed with a specific pure noise input; and the noise model also should re-extract a pure noise map if the map is added to a clean image. These three constraints are simple yet effective. They jointly facilitate unsupervised learning of a noise model for various noise types. To demonstrate its wide applicability, we deploy the SCGAN on three image processing tasks including blind image denoising, rain streak removal, and noisy image super-resolution. The results demonstrate the effectiveness and superiority of our method over the state-of-the-art methods on a variety of benchmark datasets, even though the noise types vary significantly and paired clean images are not available.
Distilling Object Detectors with Fine-grained Feature Imitation
Jun 09, 2019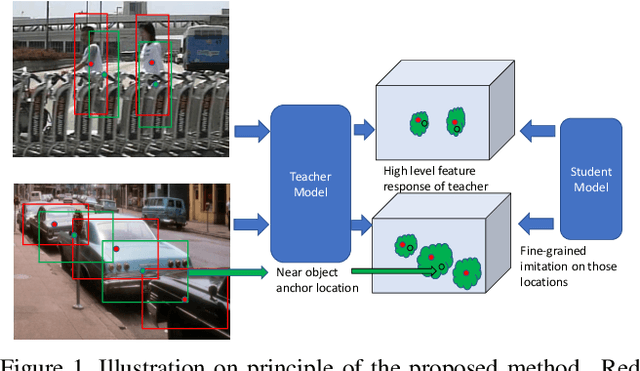
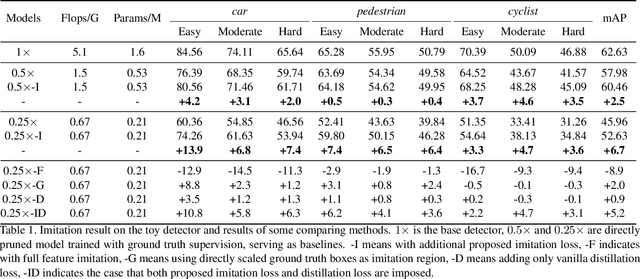
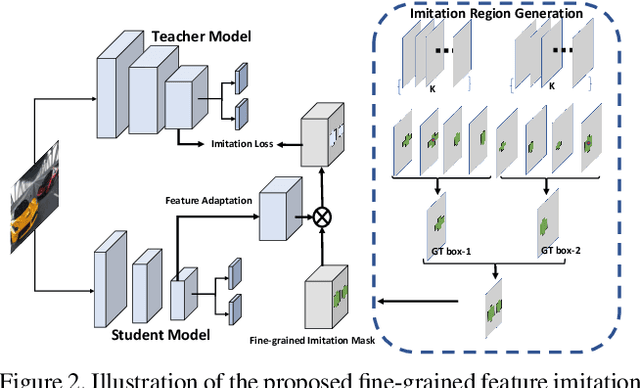

State-of-the-art CNN based recognition models are often computationally prohibitive to deploy on low-end devices. A promising high level approach tackling this limitation is knowledge distillation, which let small student model mimic cumbersome teacher model's output to get improved generalization. However, related methods mainly focus on simple task of classification while do not consider complex tasks like object detection. We show applying the vanilla knowledge distillation to detection model gets minor gain. To address the challenge of distilling knowledge in detection model, we propose a fine-grained feature imitation method exploiting the cross-location discrepancy of feature response. Our intuition is that detectors care more about local near object regions. Thus the discrepancy of feature response on the near object anchor locations reveals important information of how teacher model tends to generalize. We design a novel mechanism to estimate those locations and let student model imitate the teacher on them to get enhanced performance. We first validate the idea on a developed lightweight toy detector which carries simplest notion of current state-of-the-art anchor based detection models on challenging KITTI dataset, our method generates up to 15% boost of mAP for the student model compared to the non-imitated counterpart. We then extensively evaluate the method with Faster R-CNN model under various scenarios with common object detection benchmark of Pascal VOC and COCO, imitation alleviates up to 74% performance drop of student model compared to teacher. Codes released at https://github.com/twangnh/Distilling-Object-Detectors
Understanding Adversarial Behavior of DNNs by Disentangling Non-Robust and Robust Components in Performance Metric
Jun 06, 2019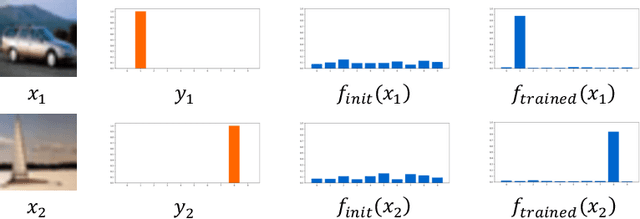
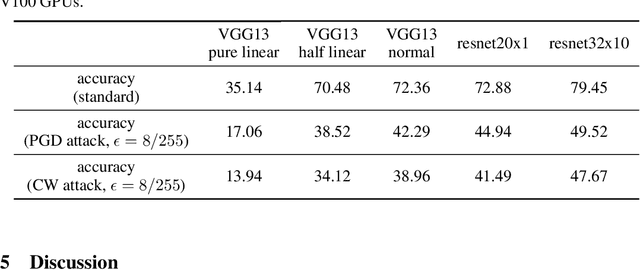
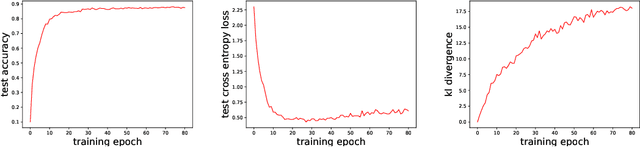
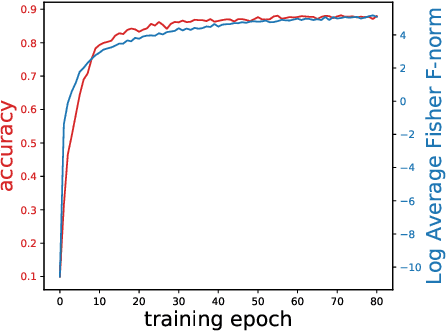
The vulnerability to slight input perturbations is a worrying yet intriguing property of deep neural networks (DNNs). Despite many previous works studying the reason behind such adversarial behavior, the relationship between the generalization performance and adversarial behavior of DNNs is still little understood. In this work, we reveal such relation by introducing a metric characterizing the generalization performance of a DNN. The metric can be disentangled into an information-theoretic non-robust component, responsible for adversarial behavior, and a robust component. Then, we show by experiments that current DNNs rely heavily on optimizing the non-robust component in achieving decent performance. We also demonstrate that current state-of-the-art adversarial training algorithms indeed try to robustify the DNNs by preventing them from using the non-robust component to distinguish samples from different categories. Also, based on our findings, we take a step forward and point out the possible direction for achieving decent standard performance and adversarial robustness simultaneously. We believe that our theory could further inspire the community to make more interesting discoveries about the relationship between standard generalization and adversarial generalization of deep learning models.
Query-efficient Meta Attack to Deep Neural Networks
Jun 06, 2019
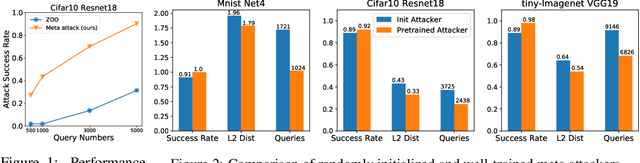
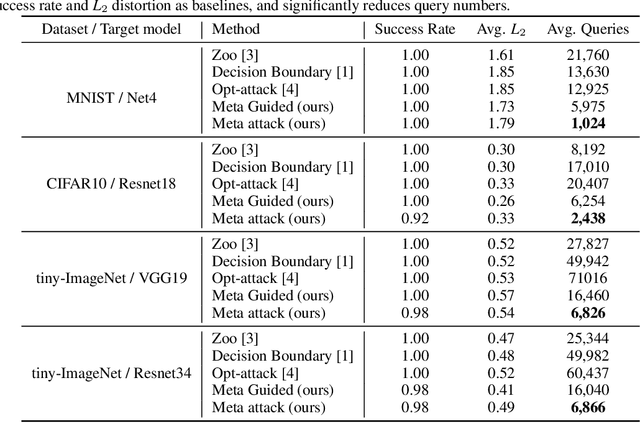
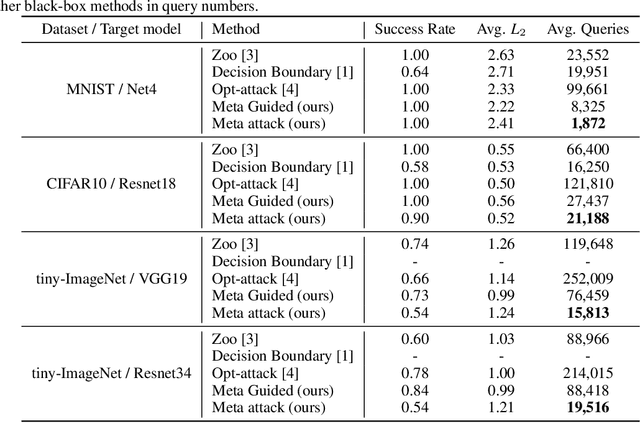
Recently, several adversarial attack methods to black-box deep neural networks have been proposed and they serve as an excellent testing bed for investigating safety issues with DNNs. These methods generally take in the query and corresponding feedback from the targeted DNN model and infer suitable attack patterns accordingly. However, due to lacking prior and inefficiency in leveraging the query information, these methods are mostly query-intensive. In this work, we propose a meta attack strategy which is capable of attacking the target black-box model with much fewer queries. Its high query-efficiency comes from prior abstraction on training a meta attacker which can speed up the search for adversarial examples significantly. Extensive experiments on MNIST, CIFAR10 and tiny-Imagenet demonstrate that, our meta-attack method can remarkably reduce the number of model queries without sacrificing the attack performance. Moreover, the obtained meta attacker is not restricted to a particular model but can be reused easily with fast adaptive ability to attack a variety of models.
Deep Face Recognition Model Compression via Knowledge Transfer and Distillation
Jun 03, 2019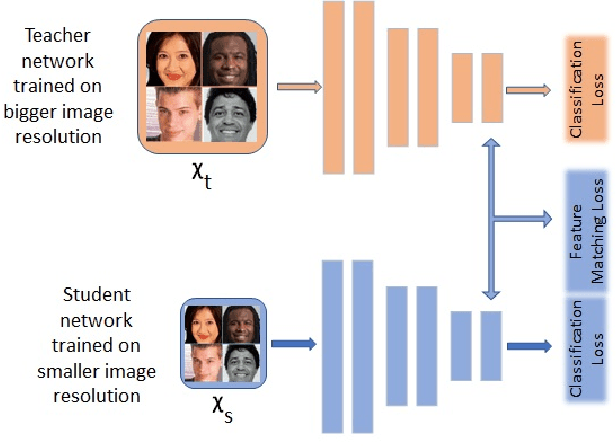
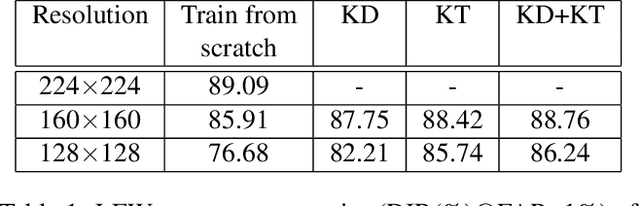
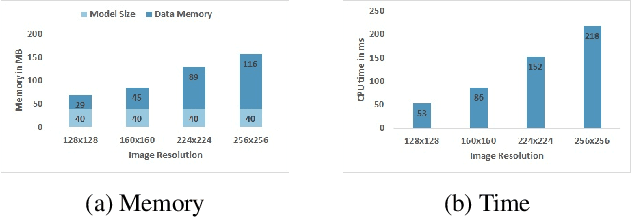
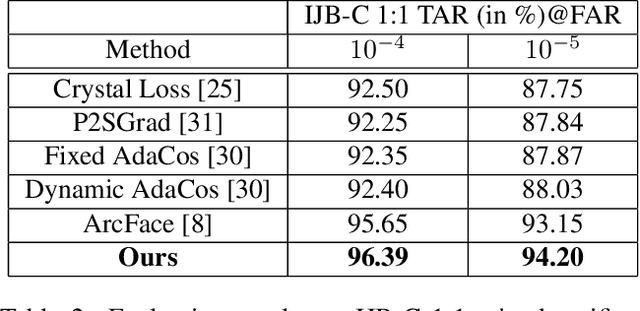
Fully convolutional networks (FCNs) have become de facto tool to achieve very high-level performance for many vision and non-vision tasks in general and face recognition in particular. Such high-level accuracies are normally obtained by very deep networks or their ensemble. However, deploying such high performing models to resource constraint devices or real-time applications is challenging. In this paper, we present a novel model compression approach based on student-teacher paradigm for face recognition applications. The proposed approach consists of training teacher FCN at bigger image resolution while student FCNs are trained at lower image resolutions than that of teacher FCN. We explored three different approaches to train student FCNs: knowledge transfer (KT), knowledge distillation (KD) and their combination. Experimental evaluation on LFW and IJB-C datasets demonstrate comparable improvements in accuracies with these approaches. Training low-resolution student FCNs from higher resolution teacher offer fourfold advantage of accelerated training, accelerated inference, reduced memory requirements and improved accuracies. We evaluated all models on IJB-C dataset and achieved state-of-the-art results on this benchmark. The teacher network and some student networks even achieved Top-1 performance on IJB-C dataset. The proposed approach is simple and hardware friendly, thus enables the deployment of high performing face recognition deep models to resource constraint devices.
Panoptic Edge Detection
Jun 03, 2019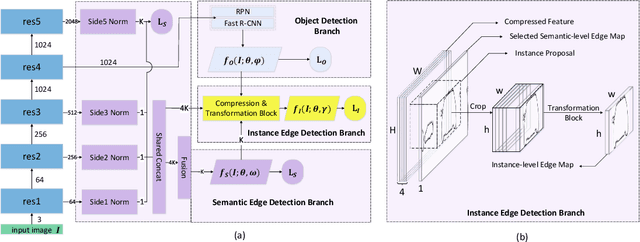
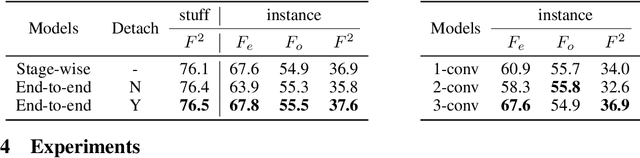

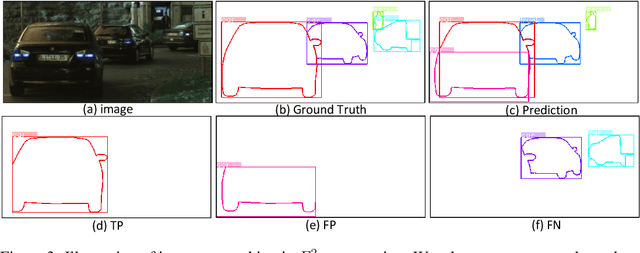
Pursuing more complete and coherent scene understanding towards realistic vision applications drives edge detection from category-agnostic to category-aware semantic level. However, finer delineation of instance-level boundaries still remains unexcavated. In this work, we address a new finer-grained task, termed panoptic edge detection (PED), which aims at predicting semantic-level boundaries for stuff categories and instance-level boundaries for instance categories, in order to provide more comprehensive and unified scene understanding from the perspective of edges.We then propose a versatile framework, Panoptic Edge Network (PEN), which aggregates different tasks of object detection, semantic and instance edge detection into a single holistic network with multiple branches. Based on the same feature representation, the semantic edge branch produces semantic-level boundaries for all categories and the object detection branch generates instance proposals. Conditioned on the prior information from these two branches, the instance edge branch aims at instantiating edge predictions for instance categories. Besides, we also devise a Panoptic Dual F-measure (F2) metric for the new PED task to uniformly measure edge prediction quality for both stuff and instances. By joint end-to-end training, the proposed PEN framework outperforms all competitive baselines on Cityscapes and ADE20K datasets.
Cross-Resolution Face Recognition via Prior-Aided Face Hallucination and Residual Knowledge Distillation
May 26, 2019

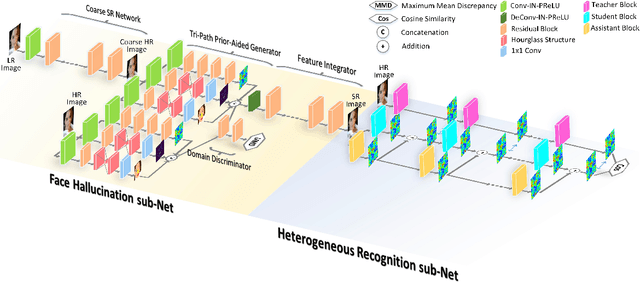
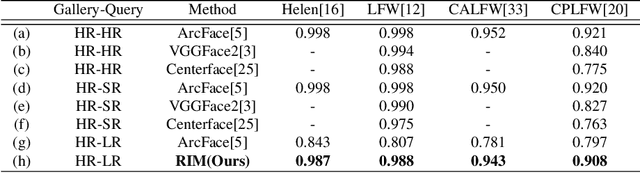
Recent deep learning based face recognition methods have achieved great performance, but it still remains challenging to recognize very low-resolution query face like 28x28 pixels when CCTV camera is far from the captured subject. Such face with very low-resolution is totally out of detail information of the face identity compared to normal resolution in a gallery and hard to find corresponding faces therein. To this end, we propose a Resolution Invariant Model (RIM) for addressing such cross-resolution face recognition problems, with three distinct novelties. First, RIM is a novel and unified deep architecture, containing a Face Hallucination sub-Net (FHN) and a Heterogeneous Recognition sub-Net (HRN), which are jointly learned end to end. Second, FHN is a well-designed tri-path Generative Adversarial Network (GAN) which simultaneously perceives facial structure and geometry prior information, i.e. landmark heatmaps and parsing maps, incorporated with an unsupervised cross-domain adversarial training strategy to super-resolve very low-resolution query image to its 8x larger ones without requiring them to be well aligned. Third, HRN is a generic Convolutional Neural Network (CNN) for heterogeneous face recognition with our proposed residual knowledge distillation strategy for learning discriminative yet generalized feature representation. Quantitative and qualitative experiments on several benchmarks demonstrate the superiority of the proposed model over the state-of-the-arts. Codes and models will be released upon acceptance.
Prototype Reminding for Continual Learning
May 23, 2019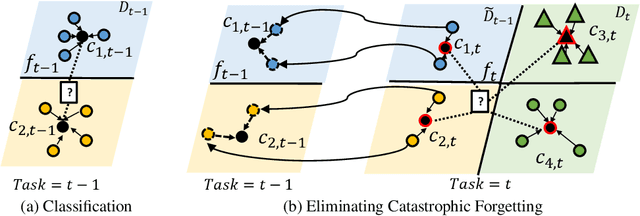
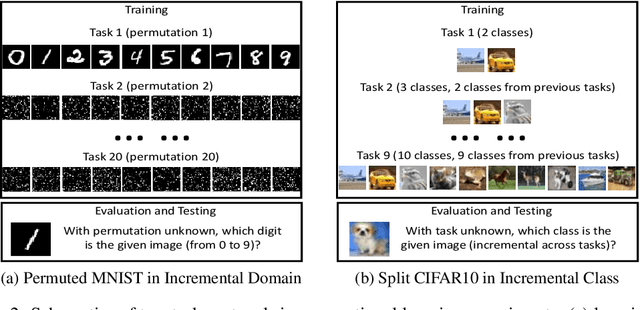
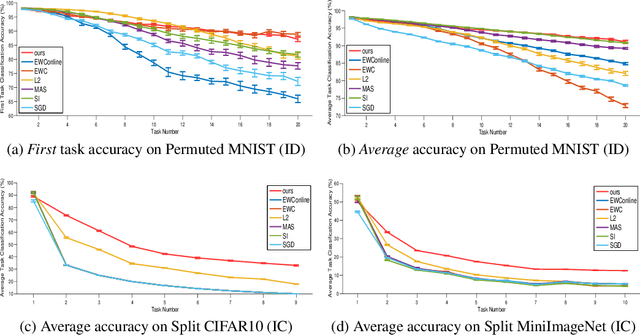
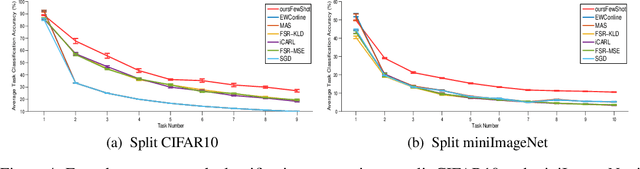
Continual learning is a critical ability of continually acquiring and transferring knowledge without catastrophically forgetting previously learned knowledge. However, enabling continual learning for AI remains a long-standing challenge. In this work, we propose a novel method, Prototype Reminding, that efficiently embeds and recalls previously learnt knowledge to tackle catastrophic forgetting issue. In particular, we consider continual learning in classification tasks. For each classification task, our method learns a metric space containing a set of prototypes where embedding of the samples from the same class cluster around prototypes and class-representative prototypes are separated apart. To alleviate catastrophic forgetting, our method preserves the embedding function from the samples to the previous metric space, through our proposed prototype reminding from previous tasks. Specifically, the reminding process is implemented by replaying a small number of samples from previous tasks and correspondingly matching their embedding to their nearest class-representative prototypes. Compared with recent continual learning methods, our contributions are fourfold: first, our method achieves the best memory retention capability while adapting quickly to new tasks. Second, our method uses metric learning for classification, and does not require adding in new neurons given new object classes. Third, our method is more memory efficient since only class-representative prototypes need to be recalled. Fourth, our method suggests a promising solution for few-shot continual learning. Without tampering with the performance on initial tasks, our method learns novel concepts given a few training examples of each class in new tasks.