 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBody Meshes as Points
May 06, 2021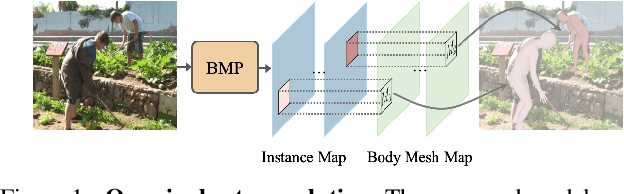

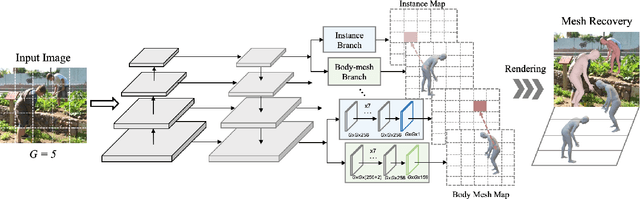

We consider the challenging multi-person 3D body mesh estimation task in this work. Existing methods are mostly two-stage based--one stage for person localization and the other stage for individual body mesh estimation, leading to redundant pipelines with high computation cost and degraded performance for complex scenes (e.g., occluded person instances). In this work, we present a single-stage model, Body Meshes as Points (BMP), to simplify the pipeline and lift both efficiency and performance. In particular, BMP adopts a new method that represents multiple person instances as points in the spatial-depth space where each point is associated with one body mesh. Hinging on such representations, BMP can directly predict body meshes for multiple persons in a single stage by concurrently localizing person instance points and estimating the corresponding body meshes. To better reason about depth ordering of all the persons within the same scene, BMP designs a simple yet effective inter-instance ordinal depth loss to obtain depth-coherent body mesh estimation. BMP also introduces a novel keypoint-aware augmentation to enhance model robustness to occluded person instances. Comprehensive experiments on benchmarks Panoptic, MuPoTS-3D and 3DPW clearly demonstrate the state-of-the-art efficiency of BMP for multi-person body mesh estimation, together with outstanding accuracy. Code can be found at: https://github.com/jfzhang95/BMP.
PoseAug: A Differentiable Pose Augmentation Framework for 3D Human Pose Estimation
May 06, 2021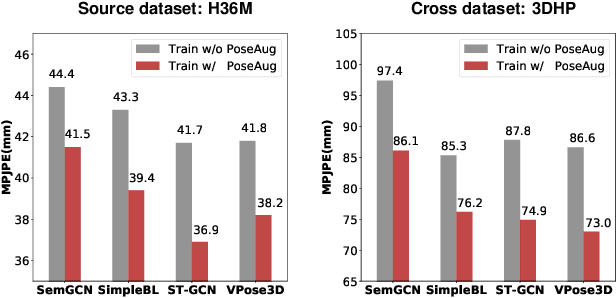
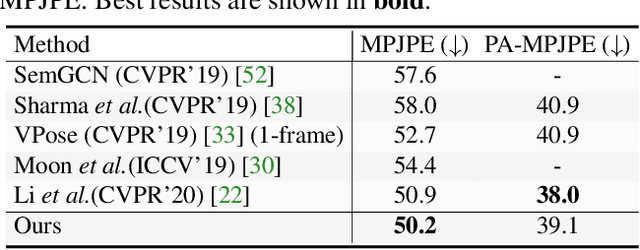
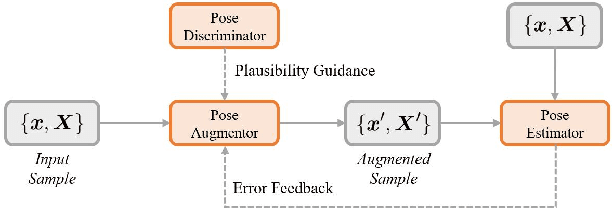
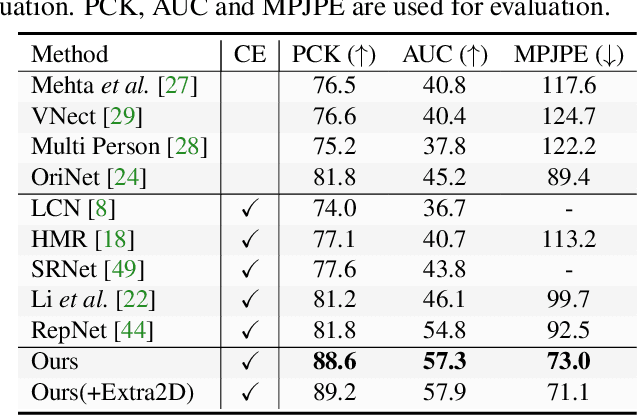
Existing 3D human pose estimators suffer poor generalization performance to new datasets, largely due to the limited diversity of 2D-3D pose pairs in the training data. To address this problem, we present PoseAug, a new auto-augmentation framework that learns to augment the available training poses towards a greater diversity and thus improve generalization of the trained 2D-to-3D pose estimator. Specifically, PoseAug introduces a novel pose augmentor that learns to adjust various geometry factors (e.g., posture, body size, view point and position) of a pose through differentiable operations. With such differentiable capacity, the augmentor can be jointly optimized with the 3D pose estimator and take the estimation error as feedback to generate more diverse and harder poses in an online manner. Moreover, PoseAug introduces a novel part-aware Kinematic Chain Space for evaluating local joint-angle plausibility and develops a discriminative module accordingly to ensure the plausibility of the augmented poses. These elaborate designs enable PoseAug to generate more diverse yet plausible poses than existing offline augmentation methods, and thus yield better generalization of the pose estimator. PoseAug is generic and easy to be applied to various 3D pose estimators. Extensive experiments demonstrate that PoseAug brings clear improvements on both intra-scenario and cross-scenario datasets. Notably, it achieves 88.6% 3D PCK on MPI-INF-3DHP under cross-dataset evaluation setup, improving upon the previous best data augmentation based method by 9.1%. Code can be found at: https://github.com/jfzhang95/PoseAug.
How Well Self-Supervised Pre-Training Performs with Streaming Data?
Apr 25, 2021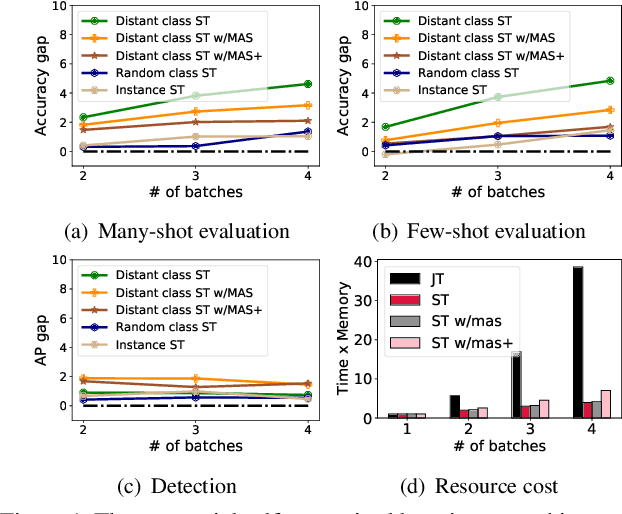
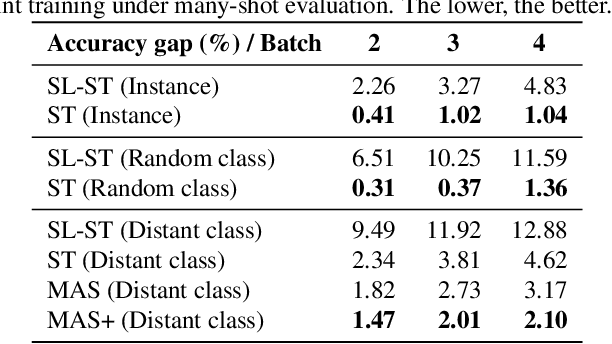
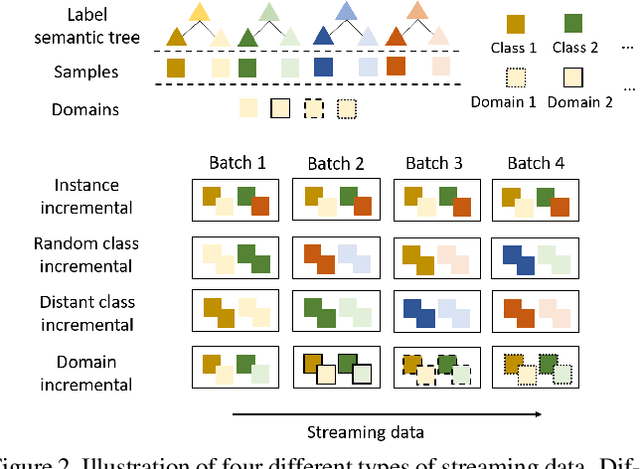
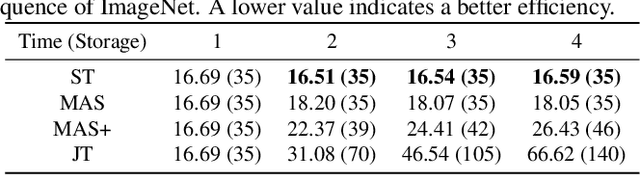
The common self-supervised pre-training practice requires collecting massive unlabeled data together and then trains a representation model, dubbed \textbf{joint training}. However, in real-world scenarios where data are collected in a streaming fashion, the joint training scheme is usually storage-heavy and time-consuming. A more efficient alternative is to train a model continually with streaming data, dubbed \textbf{sequential training}. Nevertheless, it is unclear how well sequential self-supervised pre-training performs with streaming data. In this paper, we conduct thorough experiments to investigate self-supervised pre-training with streaming data. Specifically, we evaluate the transfer performance of sequential self-supervised pre-training with four different data sequences on three different downstream tasks and make comparisons with joint self-supervised pre-training. Surprisingly, we find sequential self-supervised learning exhibits almost the same performance as the joint training when the distribution shifts within streaming data are mild. Even for data sequences with large distribution shifts, sequential self-supervised training with simple techniques, e.g., parameter regularization or data replay, still performs comparably to joint training. Based on our findings, we recommend using sequential self-supervised training as a \textbf{more efficient yet performance-competitive} representation learning practice for real-world applications.
Token Labeling: Training a 85.4% Top-1 Accuracy Vision Transformer with 56M Parameters on ImageNet
Apr 23, 2021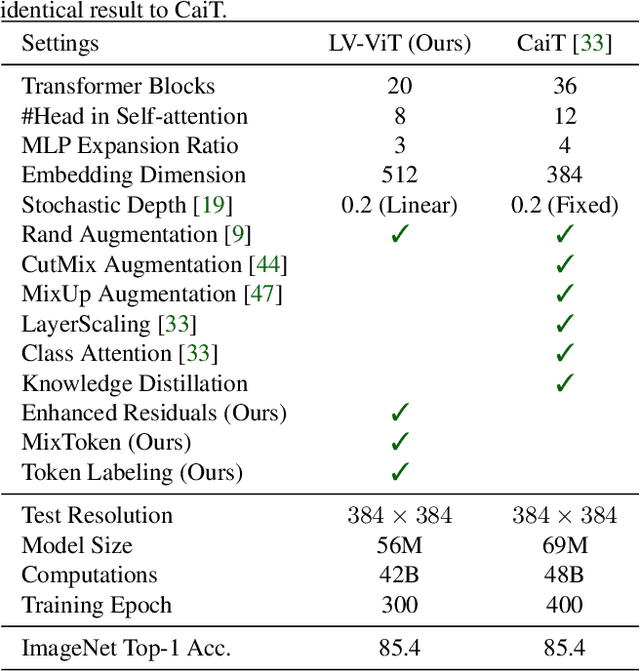
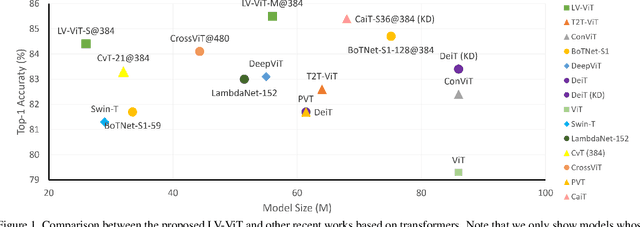
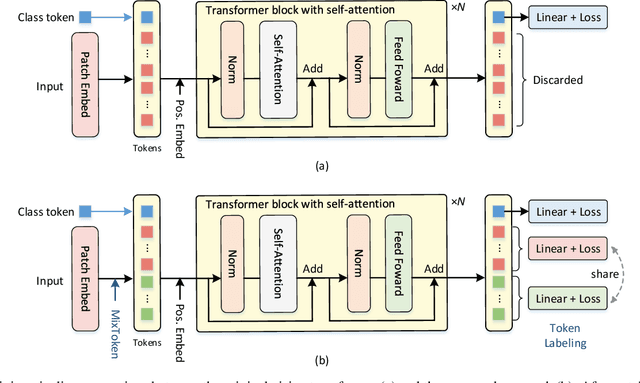
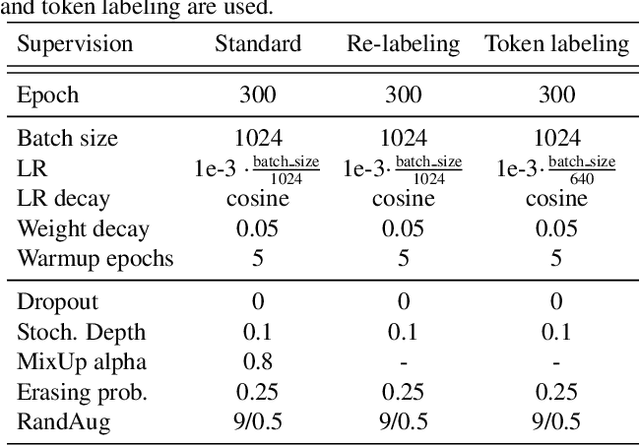
This paper provides a strong baseline for vision transformers on the ImageNet classification task. While recent vision transformers have demonstrated promising results in ImageNet classification, their performance still lags behind powerful convolutional neural networks (CNNs) with approximately the same model size. In this work, instead of describing a novel transformer architecture, we explore the potential of vision transformers in ImageNet classification by developing a bag of training techniques. We show that by slightly tuning the structure of vision transformers and introducing token labeling -- a new training objective, our models are able to achieve better results than the CNN counterparts and other transformer-based classification models with similar amount of training parameters and computations. Taking a vision transformer with 26M learnable parameters as an example, we can achieve an 84.4% Top-1 accuracy on ImageNet. When the model size is scaled up to 56M/150M, the result can be further increased to 85.4%/86.2% without extra data. We hope this study could provide researchers with useful techniques to train powerful vision transformers. Our code and all the training details will be made publicly available at https://github.com/zihangJiang/TokenLabeling.
DeepViT: Towards Deeper Vision Transformer
Apr 19, 2021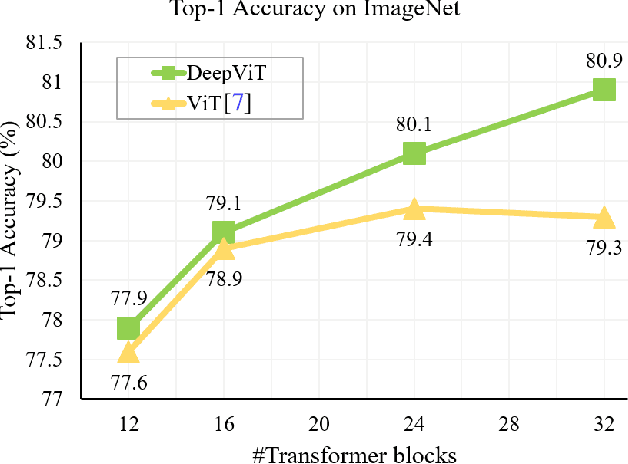
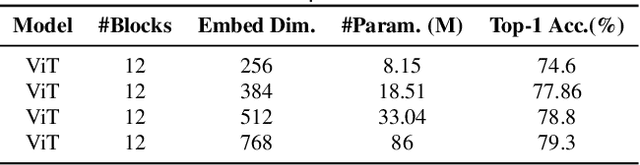
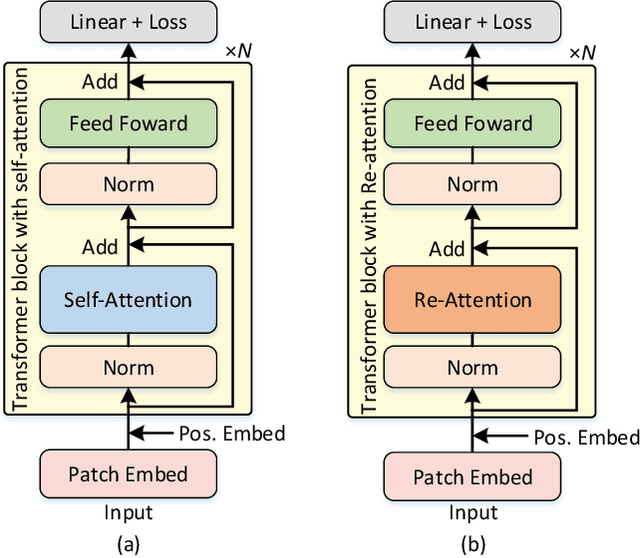

Vision transformers (ViTs) have been successfully applied in image classification tasks recently. In this paper, we show that, unlike convolution neural networks (CNNs)that can be improved by stacking more convolutional layers, the performance of ViTs saturate fast when scaled to be deeper. More specifically, we empirically observe that such scaling difficulty is caused by the attention collapse issue: as the transformer goes deeper, the attention maps gradually become similar and even much the same after certain layers. In other words, the feature maps tend to be identical in the top layers of deep ViT models. This fact demonstrates that in deeper layers of ViTs, the self-attention mechanism fails to learn effective concepts for representation learning and hinders the model from getting expected performance gain. Based on above observation, we propose a simple yet effective method, named Re-attention, to re-generate the attention maps to increase their diversity at different layers with negligible computation and memory cost. The pro-posed method makes it feasible to train deeper ViT models with consistent performance improvements via minor modification to existing ViT models. Notably, when training a deep ViT model with 32 transformer blocks, the Top-1 classification accuracy can be improved by 1.6% on ImageNet. Code is publicly available at https://github.com/zhoudaquan/dvit_repo.
Distill and Fine-tune: Effective Adaptation from a Black-box Source Model
Apr 04, 2021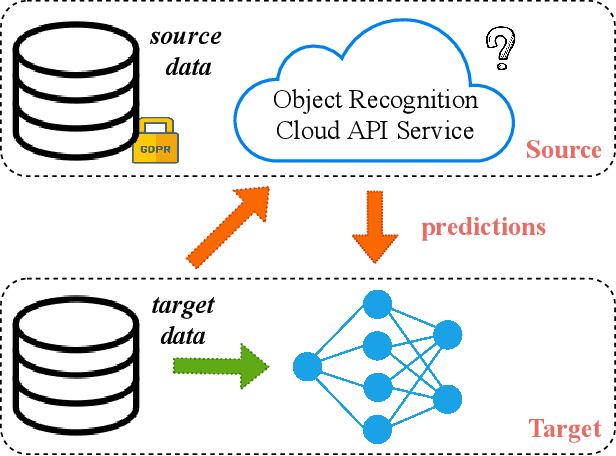
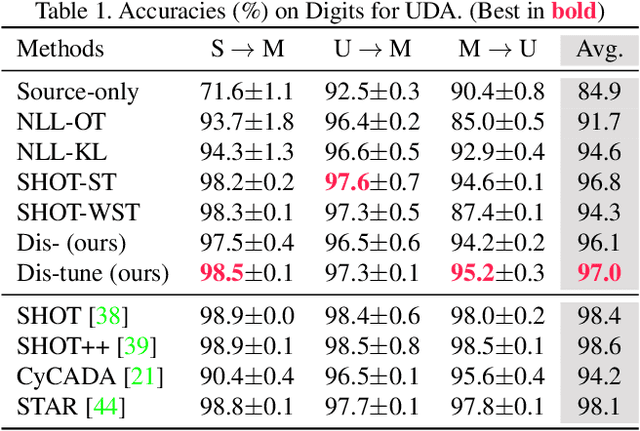
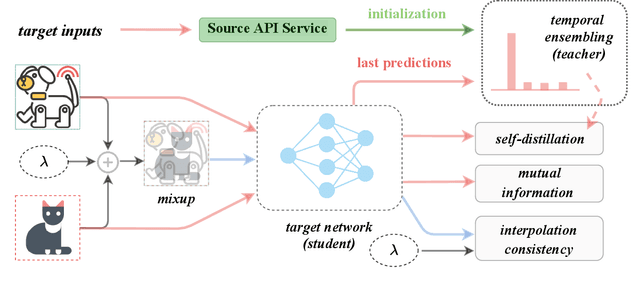

To alleviate the burden of labeling, unsupervised domain adaptation (UDA) aims to transfer knowledge in previous related labeled datasets (source) to a new unlabeled dataset (target). Despite impressive progress, prior methods always need to access the raw source data and develop data-dependent alignment approaches to recognize the target samples in a transductive learning manner, which may raise privacy concerns from source individuals. Several recent studies resort to an alternative solution by exploiting the well-trained white-box model instead of the raw data from the source domain, however, it may leak the raw data through generative adversarial training. This paper studies a practical and interesting setting for UDA, where only a black-box source model (i.e., only network predictions are available) is provided during adaptation in the target domain. Besides, different neural networks are even allowed to be employed for different domains. For this new problem, we propose a novel two-step adaptation framework called Distill and Fine-tune (Dis-tune). Specifically, Dis-tune first structurally distills the knowledge from the source model to a customized target model, then unsupervisedly fine-tunes the distilled model to fit the target domain. To verify the effectiveness, we consider two UDA scenarios (\ie, closed-set and partial-set), and discover that Dis-tune achieves highly competitive performance to state-of-the-art approaches.
Augmented Transformer with Adaptive Graph for Temporal Action Proposal Generation
Mar 30, 2021



Temporal action proposal generation (TAPG) is a fundamental and challenging task in video understanding, especially in temporal action detection. Most previous works focus on capturing the local temporal context and can well locate simple action instances with clean frames and clear boundaries. However, they generally fail in complicated scenarios where interested actions involve irrelevant frames and background clutters, and the local temporal context becomes less effective. To deal with these problems, we present an augmented transformer with adaptive graph network (ATAG) to exploit both long-range and local temporal contexts for TAPG. Specifically, we enhance the vanilla transformer by equipping a snippet actionness loss and a front block, dubbed augmented transformer, and it improves the abilities of capturing long-range dependencies and learning robust feature for noisy action instances.Moreover, an adaptive graph convolutional network (GCN) is proposed to build local temporal context by mining the position information and difference between adjacent features. The features from the two modules carry rich semantic information of the video, and are fused for effective sequential proposal generation. Extensive experiments are conducted on two challenging datasets, THUMOS14 and ActivityNet1.3, and the results demonstrate that our method outperforms state-of-the-art TAPG methods. Our code will be released soon.
AutoSpace: Neural Architecture Search with Less Human Interference
Mar 22, 2021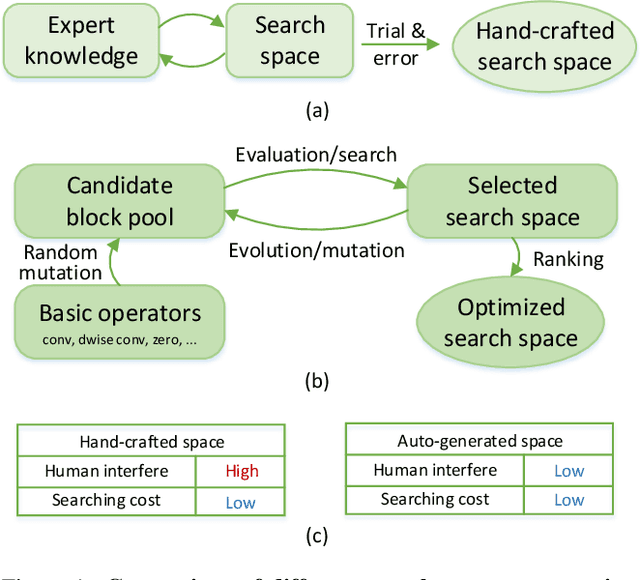
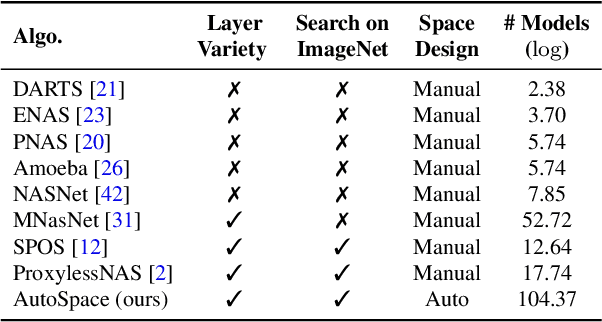
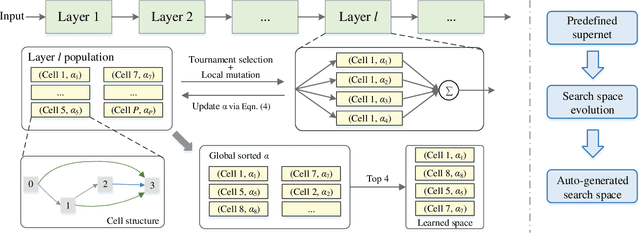
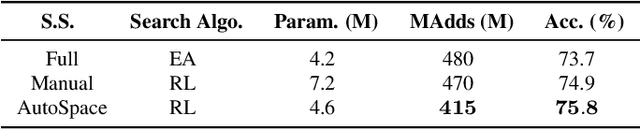
Current neural architecture search (NAS) algorithms still require expert knowledge and effort to design a search space for network construction. In this paper, we consider automating the search space design to minimize human interference, which however faces two challenges: the explosive complexity of the exploration space and the expensive computation cost to evaluate the quality of different search spaces. To solve them, we propose a novel differentiable evolutionary framework named AutoSpace, which evolves the search space to an optimal one with following novel techniques: a differentiable fitness scoring function to efficiently evaluate the performance of cells and a reference architecture to speedup the evolution procedure and avoid falling into sub-optimal solutions. The framework is generic and compatible with additional computational constraints, making it feasible to learn specialized search spaces that fit different computational budgets. With the learned search space, the performance of recent NAS algorithms can be improved significantly compared with using previously manually designed spaces. Remarkably, the models generated from the new search space achieve 77.8% top-1 accuracy on ImageNet under the mobile setting (MAdds < 500M), out-performing previous SOTA EfficientNet-B0 by 0.7%. All codes will be made public.
Coordinate Attention for Efficient Mobile Network Design
Mar 04, 2021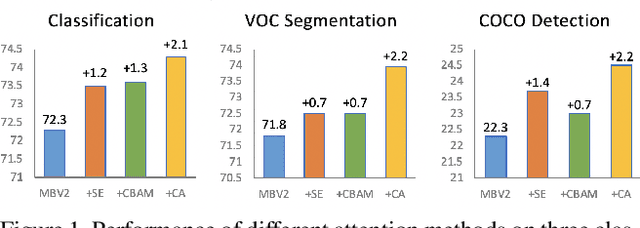
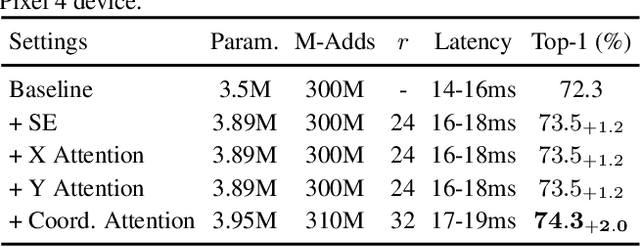
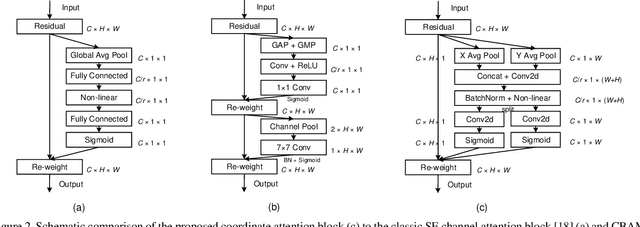
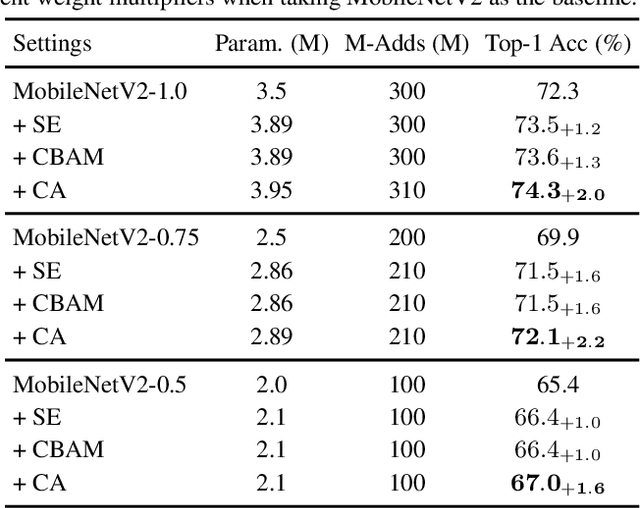
Recent studies on mobile network design have demonstrated the remarkable effectiveness of channel attention (e.g., the Squeeze-and-Excitation attention) for lifting model performance, but they generally neglect the positional information, which is important for generating spatially selective attention maps. In this paper, we propose a novel attention mechanism for mobile networks by embedding positional information into channel attention, which we call "coordinate attention". Unlike channel attention that transforms a feature tensor to a single feature vector via 2D global pooling, the coordinate attention factorizes channel attention into two 1D feature encoding processes that aggregate features along the two spatial directions, respectively. In this way, long-range dependencies can be captured along one spatial direction and meanwhile precise positional information can be preserved along the other spatial direction. The resulting feature maps are then encoded separately into a pair of direction-aware and position-sensitive attention maps that can be complementarily applied to the input feature map to augment the representations of the objects of interest. Our coordinate attention is simple and can be flexibly plugged into classic mobile networks, such as MobileNetV2, MobileNeXt, and EfficientNet with nearly no computational overhead. Extensive experiments demonstrate that our coordinate attention is not only beneficial to ImageNet classification but more interestingly, behaves better in down-stream tasks, such as object detection and semantic segmentation. Code is available at https://github.com/Andrew-Qibin/CoordAttention.
Unleashing the Power of Contrastive Self-Supervised Visual Models via Contrast-Regularized Fine-Tuning
Feb 12, 2021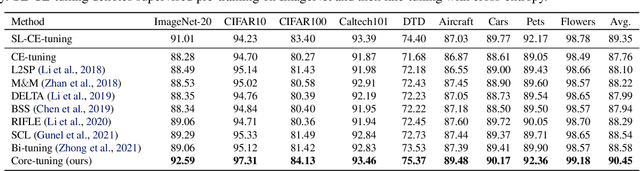
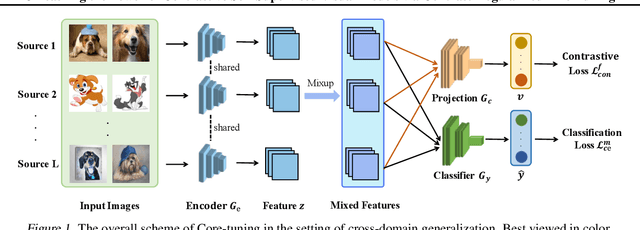
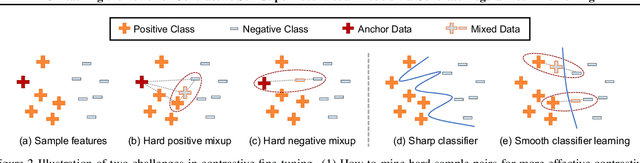

Contrastive self-supervised learning (CSL) leverages unlabeled data to train models that provide instance-discriminative visual representations uniformly scattered in the feature space. In deployment, the common practice is to directly fine-tune models with the cross-entropy loss, which however may not be an optimal strategy. Although cross-entropy tends to separate inter-class features, the resulted models still have limited capability of reducing intra-class feature scattering that inherits from pre-training, and thus may suffer unsatisfactory performance on downstream tasks. In this paper, we investigate whether applying contrastive learning to fine-tuning would bring further benefits, and analytically find that optimizing the supervised contrastive loss benefits both class-discriminative representation learning and model optimization during fine-tuning. Inspired by these findings, we propose Contrast-regularized tuning (Core-tuning), a novel approach for fine-tuning contrastive self-supervised visual models. Instead of simply adding the contrastive loss to the objective of fine-tuning, Core-tuning also generates hard sample pairs for more effective contrastive learning through a novel feature mixup strategy, as well as improves the generalizability of the model by smoothing the decision boundary via mixed samples. Extensive experiments on image classification and semantic segmentation verify the effectiveness of Core-tuning.