 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSECap: Speech Emotion Captioning with Large Language Model
Dec 23, 2023



Speech emotions are crucial in human communication and are extensively used in fields like speech synthesis and natural language understanding. Most prior studies, such as speech emotion recognition, have categorized speech emotions into a fixed set of classes. Yet, emotions expressed in human speech are often complex, and categorizing them into predefined groups can be insufficient to adequately represent speech emotions. On the contrary, describing speech emotions directly by means of natural language may be a more effective approach. Regrettably, there are not many studies available that have focused on this direction. Therefore, this paper proposes a speech emotion captioning framework named SECap, aiming at effectively describing speech emotions using natural language. Owing to the impressive capabilities of large language models in language comprehension and text generation, SECap employs LLaMA as the text decoder to allow the production of coherent speech emotion captions. In addition, SECap leverages HuBERT as the audio encoder to extract general speech features and Q-Former as the Bridge-Net to provide LLaMA with emotion-related speech features. To accomplish this, Q-Former utilizes mutual information learning to disentangle emotion-related speech features and speech contents, while implementing contrastive learning to extract more emotion-related speech features. The results of objective and subjective evaluations demonstrate that: 1) the SECap framework outperforms the HTSAT-BART baseline in all objective evaluations; 2) SECap can generate high-quality speech emotion captions that attain performance on par with human annotators in subjective mean opinion score tests.
Typing to Listen at the Cocktail Party: Text-Guided Target Speaker Extraction
Oct 15, 2023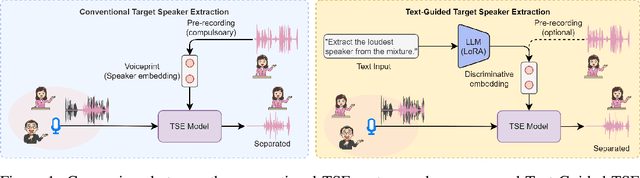
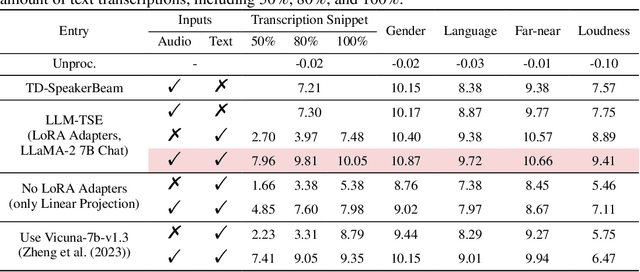
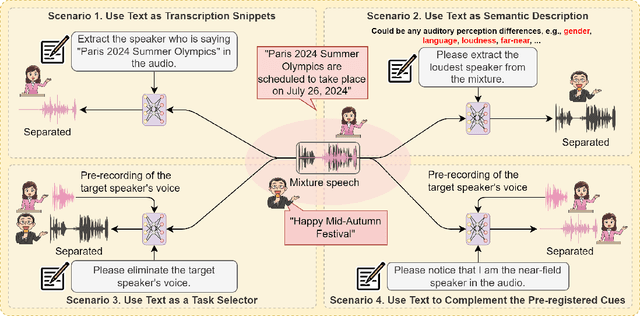
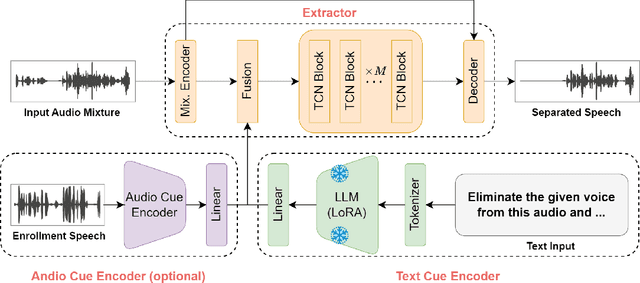
Humans possess an extraordinary ability to selectively focus on the sound source of interest amidst complex acoustic environments, commonly referred to as cocktail party scenarios. In an attempt to replicate this remarkable auditory attention capability in machines, target speaker extraction (TSE) models have been developed. These models leverage the pre-registered cues of the target speaker to extract the sound source of interest. However, the effectiveness of these models is hindered in real-world scenarios due to the unreliable or even absence of pre-registered cues. To address this limitation, this study investigates the integration of natural language description to enhance the feasibility, controllability, and performance of existing TSE models. Specifically, we propose a model named LLM-TSE, wherein a large language model (LLM) extracts useful semantic cues from the user's typed text input. These cues can serve as independent extraction cues, task selectors to control the TSE process or complement the pre-registered cues. Our experimental results demonstrate competitive performance when only text-based cues are presented, the effectiveness of using input text as a task selector, and a new state-of-the-art when combining text-based cues with pre-registered cues. To our knowledge, this is the first study to successfully incorporate LLMs to guide target speaker extraction, which can be a cornerstone for cocktail party problem research.
Leveraging In-the-Wild Data for Effective Self-Supervised Pretraining in Speaker Recognition
Sep 27, 2023Current speaker recognition systems primarily rely on supervised approaches, constrained by the scale of labeled datasets. To boost the system performance, researchers leverage large pretrained models such as WavLM to transfer learned high-level features to the downstream speaker recognition task. However, this approach introduces extra parameters as the pretrained model remains in the inference stage. Another group of researchers directly apply self-supervised methods such as DINO to speaker embedding learning, yet they have not explored its potential on large-scale in-the-wild datasets. In this paper, we present the effectiveness of DINO training on the large-scale WenetSpeech dataset and its transferability in enhancing the supervised system performance on the CNCeleb dataset. Additionally, we introduce a confidence-based data filtering algorithm to remove unreliable data from the pretraining dataset, leading to better performance with less training data. The associated pretrained models, confidence files, pretraining and finetuning scripts will be made available in the Wespeaker toolkit.
AutoPrep: An Automatic Preprocessing Framework for In-the-Wild Speech Data
Sep 25, 2023Recently, the utilization of extensive open-sourced text data has significantly advanced the performance of text-based large language models (LLMs). However, the use of in-the-wild large-scale speech data in the speech technology community remains constrained. One reason for this limitation is that a considerable amount of the publicly available speech data is compromised by background noise, speech overlapping, lack of speech segmentation information, missing speaker labels, and incomplete transcriptions, which can largely hinder their usefulness. On the other hand, human annotation of speech data is both time-consuming and costly. To address this issue, we introduce an automatic in-the-wild speech data preprocessing framework (AutoPrep) in this paper, which is designed to enhance speech quality, generate speaker labels, and produce transcriptions automatically. The proposed AutoPrep framework comprises six components: speech enhancement, speech segmentation, speaker clustering, target speech extraction, quality filtering and automatic speech recognition. Experiments conducted on the open-sourced WenetSpeech and our self-collected AutoPrepWild corpora demonstrate that the proposed AutoPrep framework can generate preprocessed data with similar DNSMOS and PDNSMOS scores compared to several open-sourced TTS datasets. The corresponding TTS system can achieve up to 0.68 in-domain speaker similarity.
Improved Factorized Neural Transducer Model For text-only Domain Adaptation
Sep 18, 2023End-to-end models, such as the neural Transducer, have been successful in integrating acoustic and linguistic information jointly to achieve excellent recognition performance. However, adapting these models with text-only data is challenging. Factorized neural Transducer (FNT) aims to address this issue by introducing a separate vocabulary decoder to predict the vocabulary, which can effectively perform traditional text data adaptation. Nonetheless, this approach has limitations in fusing acoustic and language information seamlessly. Moreover, a degradation in word error rate (WER) on the general test sets was also observed, leading to doubts about its overall performance. In response to this challenge, we present an improved factorized neural Transducer (IFNT) model structure designed to comprehensively integrate acoustic and language information while enabling effective text adaptation. We evaluate the performance of our proposed methods through in-domain experiments on GigaSpeech and out-of-domain experiments adapting to EuroParl, TED-LIUM, and Medical datasets. After text-only adaptation, IFNT yields 7.9% to 28.5% relative WER improvements over the standard neural Transducer with shallow fusion, and relative WER reductions ranging from 1.6% to 8.2% on the three test sets compared to the FNT model.
Complexity Scaling for Speech Denoising
Sep 14, 2023



Computational complexity is critical when deploying deep learning-based speech denoising models for on-device applications. Most prior research focused on optimizing model architectures to meet specific computational cost constraints, often creating distinct neural network architectures for different complexity limitations. This study conducts complexity scaling for speech denoising tasks, aiming to consolidate models with various complexities into a unified architecture. We present a Multi-Path Transform-based (MPT) architecture to handle both low- and high-complexity scenarios. A series of MPT networks present high performance covering a wide range of computational complexities on the DNS challenge dataset. Moreover, inspired by the scaling experiments in natural language processing, we explore the empirical relationship between model performance and computational cost on the denoising task. As the complexity number of multiply-accumulate operations (MACs) is scaled from 50M/s to 15G/s on MPT networks, we observe a linear increase in the values of PESQ-WB and SI-SNR, proportional to the logarithm of MACs, which might contribute to the understanding and application of complexity scaling in speech denoising tasks.
Ultra Dual-Path Compression For Joint Echo Cancellation And Noise Suppression
Aug 21, 2023



Echo cancellation and noise reduction are essential for full-duplex communication, yet most existing neural networks have high computational costs and are inflexible in tuning model complexity. In this paper, we introduce time-frequency dual-path compression to achieve a wide range of compression ratios on computational cost. Specifically, for frequency compression, trainable filters are used to replace manually designed filters for dimension reduction. For time compression, only using frame skipped prediction causes large performance degradation, which can be alleviated by a post-processing network with full sequence modeling. We have found that under fixed compression ratios, dual-path compression combining both the time and frequency methods will give further performance improvement, covering compression ratios from 4x to 32x with little model size change. Moreover, the proposed models show competitive performance compared with fast FullSubNet and DeepFilterNet. A demo page can be found at hangtingchen.github.io/ultra_dual_path_compression.github.io/.
Bayes Risk Transducer: Transducer with Controllable Alignment Prediction
Aug 19, 2023Automatic speech recognition (ASR) based on transducers is widely used. In training, a transducer maximizes the summed posteriors of all paths. The path with the highest posterior is commonly defined as the predicted alignment between the speech and the transcription. While the vanilla transducer does not have a prior preference for any of the valid paths, this work intends to enforce the preferred paths and achieve controllable alignment prediction. Specifically, this work proposes Bayes Risk Transducer (BRT), which uses a Bayes risk function to set lower risk values to the preferred paths so that the predicted alignment is more likely to satisfy specific desired properties. We further demonstrate that these predicted alignments with intentionally designed properties can provide practical advantages over the vanilla transducer. Experimentally, the proposed BRT saves inference cost by up to 46% for non-streaming ASR and reduces overall system latency by 41% for streaming ASR.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Music Demixing Track
Aug 14, 2023



This paper summarizes the music demixing (MDX) track of the Sound Demixing Challenge (SDX'23). We provide a summary of the challenge setup and introduce the task of robust music source separation (MSS), i.e., training MSS models in the presence of errors in the training data. We propose a formalization of the errors that can occur in the design of a training dataset for MSS systems and introduce two new datasets that simulate such errors: SDXDB23_LabelNoise and SDXDB23_Bleeding1. We describe the methods that achieved the highest scores in the competition. Moreover, we present a direct comparison with the previous edition of the challenge (the Music Demixing Challenge 2021): the best performing system under the standard MSS formulation achieved an improvement of over 1.6dB in signal-to-distortion ratio over the winner of the previous competition, when evaluated on MDXDB21. Besides relying on the signal-to-distortion ratio as objective metric, we also performed a listening test with renowned producers/musicians to study the perceptual quality of the systems and report here the results. Finally, we provide our insights into the organization of the competition and our prospects for future editions.
The Sound Demixing Challenge 2023 $\unicode{x2013}$ Cinematic Demixing Track
Aug 14, 2023



This paper summarizes the cinematic demixing (CDX) track of the Sound Demixing Challenge 2023 (SDX'23). We provide a comprehensive summary of the challenge setup, detailing the structure of the competition and the datasets used. Especially, we detail CDXDB23, a new hidden dataset constructed from real movies that was used to rank the submissions. The paper also offers insights into the most successful approaches employed by participants. Compared to the cocktail-fork baseline, the best-performing system trained exclusively on the simulated Divide and Remaster (DnR) dataset achieved an improvement of 1.8dB in SDR whereas the top performing system on the open leaderboard, where any data could be used for training, saw a significant improvement of 5.7dB.