 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRISE: Leveraging Retrieval Techniques for Summarization Evaluation
Dec 17, 2022



Evaluating automatically-generated text summaries is a challenging task. While there have been many interesting approaches, they still fall short of human evaluations. We present RISE, a new approach for evaluating summaries by leveraging techniques from information retrieval. RISE is first trained as a retrieval task using a dual-encoder retrieval setup, and can then be subsequently utilized for evaluating a generated summary given an input document, without gold reference summaries. RISE is especially well suited when working on new datasets where one may not have reference summaries available for evaluation. We conduct comprehensive experiments on the SummEval benchmark (Fabbri et al., 2021) and the results show that RISE has higher correlation with human evaluations compared to many past approaches to summarization evaluation. Furthermore, RISE also demonstrates data-efficiency and generalizability across languages.
Attributed Question Answering: Evaluation and Modeling for Attributed Large Language Models
Dec 15, 2022



Large language models (LLMs) have shown impressive results across a variety of tasks while requiring little or no direct supervision. Further, there is mounting evidence that LLMs may have potential in information-seeking scenarios. We believe the ability of an LLM to attribute the text that it generates is likely to be crucial for both system developers and users in this setting. We propose and study Attributed QA as a key first step in the development of attributed LLMs. We develop a reproducable evaluation framework for the task, using human annotations as a gold standard and a correlated automatic metric that we show is suitable for development settings. We describe and benchmark a broad set of architectures for the task. Our contributions give some concrete answers to two key questions (How to measure attribution?, and How well do current state-of-the-art methods perform on attribution?), and give some hints as to how to address a third key question (How to build LLMs with attribution?).
RankT5: Fine-Tuning T5 for Text Ranking with Ranking Losses
Oct 12, 2022



Recently, substantial progress has been made in text ranking based on pretrained language models such as BERT. However, there are limited studies on how to leverage more powerful sequence-to-sequence models such as T5. Existing attempts usually formulate text ranking as classification and rely on postprocessing to obtain a ranked list. In this paper, we propose RankT5 and study two T5-based ranking model structures, an encoder-decoder and an encoder-only one, so that they not only can directly output ranking scores for each query-document pair, but also can be fine-tuned with "pairwise" or "listwise" ranking losses to optimize ranking performances. Our experiments show that the proposed models with ranking losses can achieve substantial ranking performance gains on different public text ranking data sets. Moreover, when fine-tuned with listwise ranking losses, the ranking model appears to have better zero-shot ranking performance on out-of-domain data sets compared to the model fine-tuned with classification losses.
Knowledge Prompts: Injecting World Knowledge into Language Models through Soft Prompts
Oct 10, 2022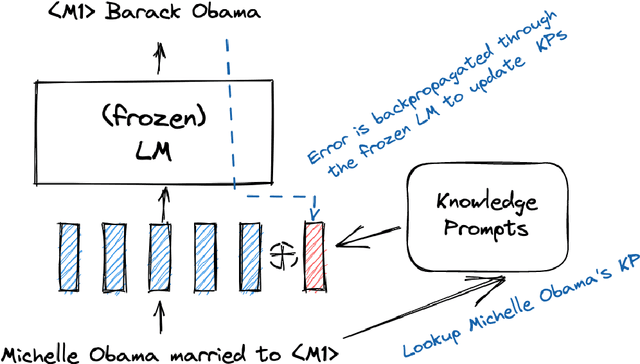
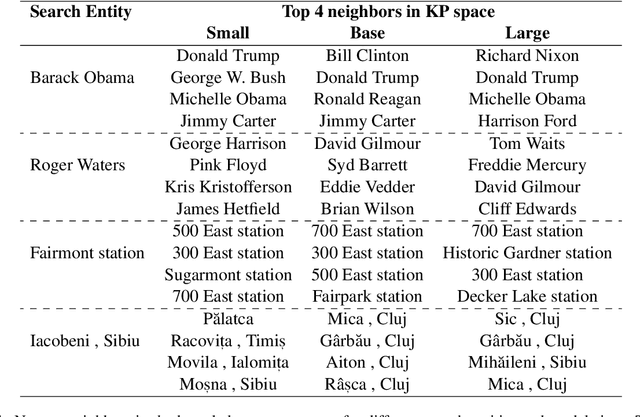
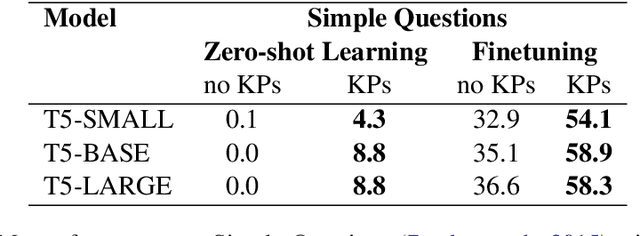
Soft prompts have been recently proposed as a tool for adapting large frozen language models (LMs) to new tasks. In this work, we repurpose soft prompts to the task of injecting world knowledge into LMs. We introduce a method to train soft prompts via self-supervised learning on data from knowledge bases. The resulting soft knowledge prompts (KPs) are task independent and work as an external memory of the LMs. We perform qualitative and quantitative experiments and demonstrate that: (1) KPs can effectively model the structure of the training data; (2) KPs can be used to improve the performance of LMs in different knowledge intensive tasks.
Promptagator: Few-shot Dense Retrieval From 8 Examples
Sep 23, 2022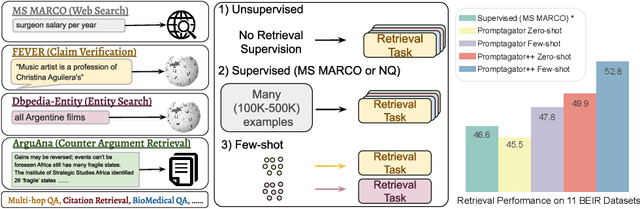
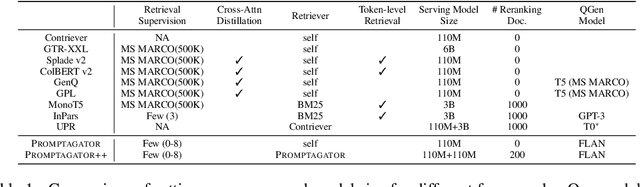
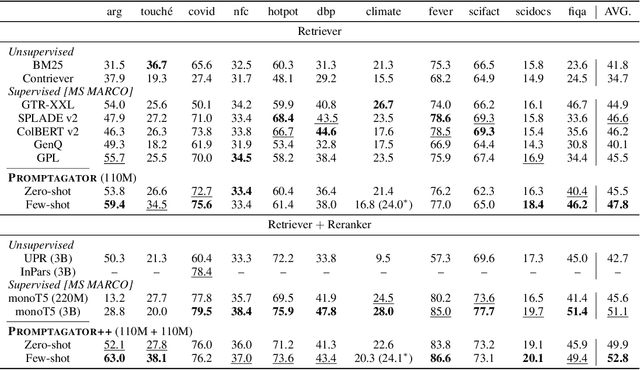
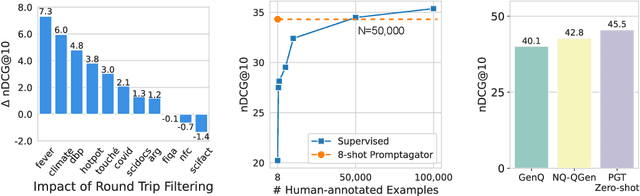
Much recent research on information retrieval has focused on how to transfer from one task (typically with abundant supervised data) to various other tasks where supervision is limited, with the implicit assumption that it is possible to generalize from one task to all the rest. However, this overlooks the fact that there are many diverse and unique retrieval tasks, each targeting different search intents, queries, and search domains. In this paper, we suggest to work on Few-shot Dense Retrieval, a setting where each task comes with a short description and a few examples. To amplify the power of a few examples, we propose Prompt-base Query Generation for Retriever (Promptagator), which leverages large language models (LLM) as a few-shot query generator, and creates task-specific retrievers based on the generated data. Powered by LLM's generalization ability, Promptagator makes it possible to create task-specific end-to-end retrievers solely based on a few examples {without} using Natural Questions or MS MARCO to train %question generators or dual encoders. Surprisingly, LLM prompting with no more than 8 examples allows dual encoders to outperform heavily engineered models trained on MS MARCO like ColBERT v2 by more than 1.2 nDCG on average on 11 retrieval sets. Further training standard-size re-rankers using the same generated data yields another 5.0 point nDCG improvement. Our studies determine that query generation can be far more effective than previously observed, especially when a small amount of task-specific knowledge is given.
Knowledge-aware Neural Collective Matrix Factorization for Cross-domain Recommendation
Jun 27, 2022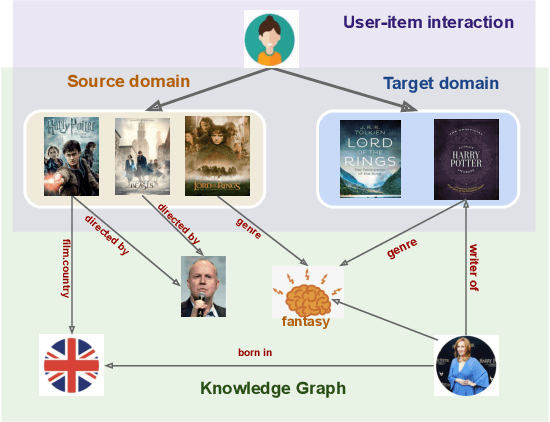
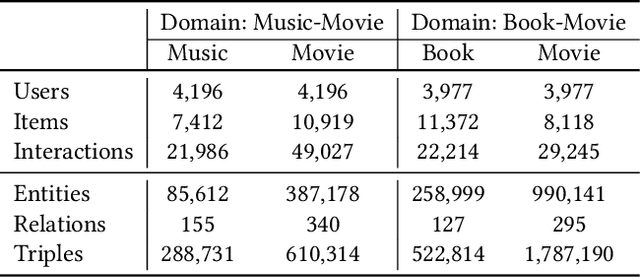
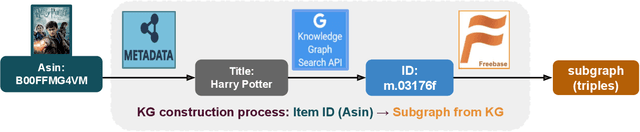
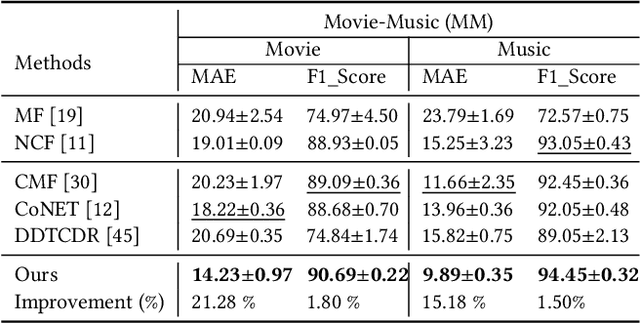
Cross-domain recommendation (CDR) can help customers find more satisfying items in different domains. Existing CDR models mainly use common users or mapping functions as bridges between domains but have very limited exploration in fully utilizing extra knowledge across domains. In this paper, we propose to incorporate the knowledge graph (KG) for CDR, which enables items in different domains to share knowledge. To this end, we first construct a new dataset AmazonKG4CDR from the Freebase KG and a subset (two domain pairs: movies-music, movie-book) of Amazon Review Data. This new dataset facilitates linking knowledge to bridge within- and cross-domain items for CDR. Then we propose a new framework, KG-aware Neural Collective Matrix Factorization (KG-NeuCMF), leveraging KG to enrich item representations. It first learns item embeddings by graph convolutional autoencoder to capture both domain-specific and domain-general knowledge from adjacent and higher-order neighbours in the KG. Then, we maximize the mutual information between item embeddings learned from the KG and user-item matrix to establish cross-domain relationships for better CDR. Finally, we conduct extensive experiments on the newly constructed dataset and demonstrate that our model significantly outperforms the best-performing baselines.
Exploring Dual Encoder Architectures for Question Answering
Apr 14, 2022
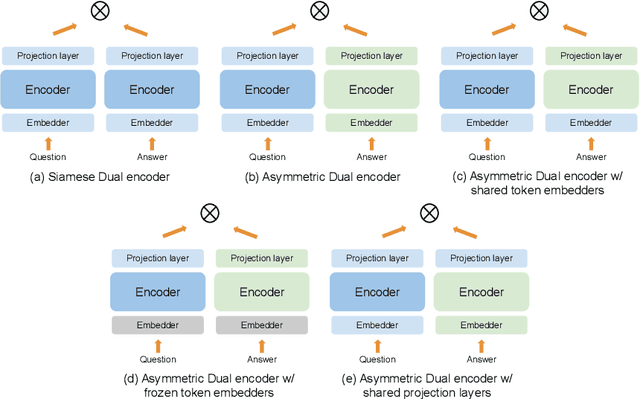
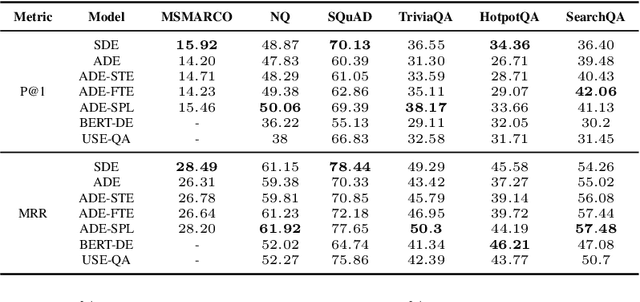

Dual encoders have been used for question-answering (QA) and information retrieval (IR) tasks with good results. There are two major types of dual encoders, Siamese Dual Encoders (SDE), with parameters shared across two encoders, and Asymmetric Dual Encoder (ADE), with two distinctly parameterized encoders. In this work, we explore the dual encoder architectures for QA retrieval tasks. By evaluating on MS MARCO and the MultiReQA benchmark, we show that SDE performs significantly better than ADE. We further propose three different improved versions of ADEs. Based on the evaluation of QA retrieval tasks and direct analysis of the embeddings, we demonstrate that sharing parameters in projection layers would enable ADEs to perform competitively with SDEs.
Scaling Up Models and Data with $\texttt{t5x}$ and $\texttt{seqio}$
Mar 31, 2022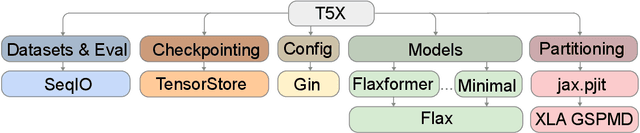
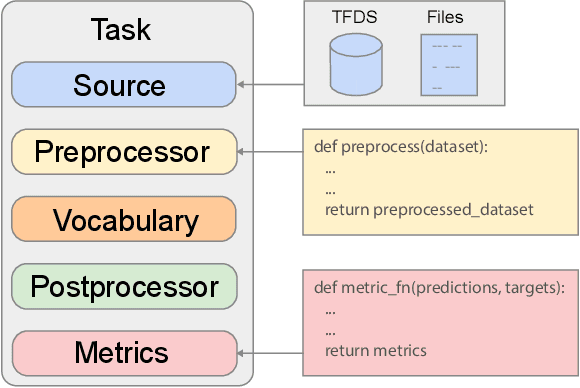
Recent neural network-based language models have benefited greatly from scaling up the size of training datasets and the number of parameters in the models themselves. Scaling can be complicated due to various factors including the need to distribute computation on supercomputer clusters (e.g., TPUs), prevent bottlenecks when infeeding data, and ensure reproducible results. In this work, we present two software libraries that ease these issues: $\texttt{t5x}$ simplifies the process of building and training large language models at scale while maintaining ease of use, and $\texttt{seqio}$ provides a task-based API for simple creation of fast and reproducible training data and evaluation pipelines. These open-source libraries have been used to train models with hundreds of billions of parameters on datasets with multiple terabytes of training data. Along with the libraries, we release configurations and instructions for T5-like encoder-decoder models as well as GPT-like decoder-only architectures. $\texttt{t5x}$ and $\texttt{seqio}$ are open source and available at https://github.com/google-research/t5x and https://github.com/google/seqio, respectively.
Transformer Memory as a Differentiable Search Index
Feb 16, 2022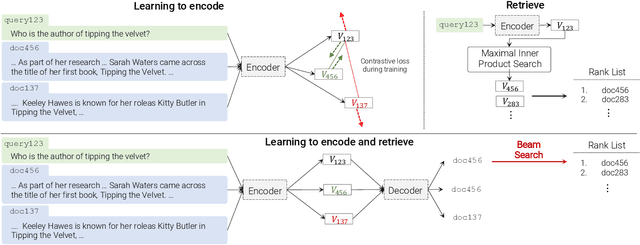
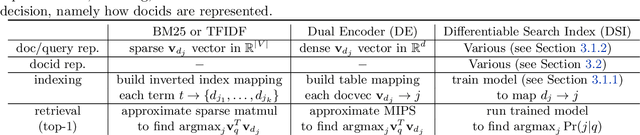
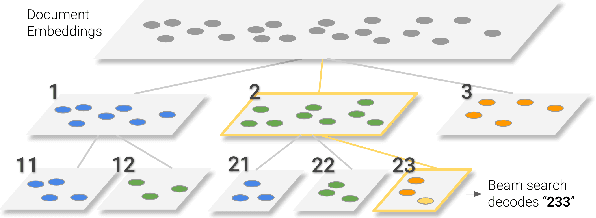
In this paper, we demonstrate that information retrieval can be accomplished with a single Transformer, in which all information about the corpus is encoded in the parameters of the model. To this end, we introduce the Differentiable Search Index (DSI), a new paradigm that learns a text-to-text model that maps string queries directly to relevant docids; in other words, a DSI model answers queries directly using only its parameters, dramatically simplifying the whole retrieval process. We study variations in how documents and their identifiers are represented, variations in training procedures, and the interplay between models and corpus sizes. Experiments demonstrate that given appropriate design choices, DSI significantly outperforms strong baselines such as dual encoder models. Moreover, DSI demonstrates strong generalization capabilities, outperforming a BM25 baseline in a zero-shot setup.
LongT5: Efficient Text-To-Text Transformer for Long Sequences
Dec 15, 2021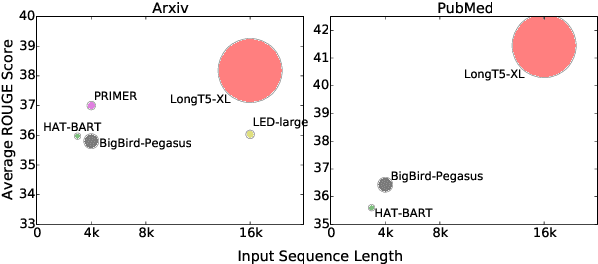
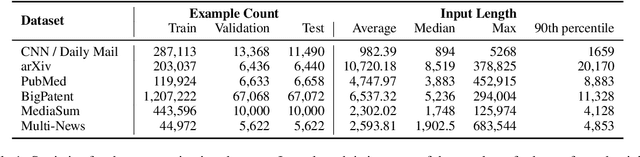
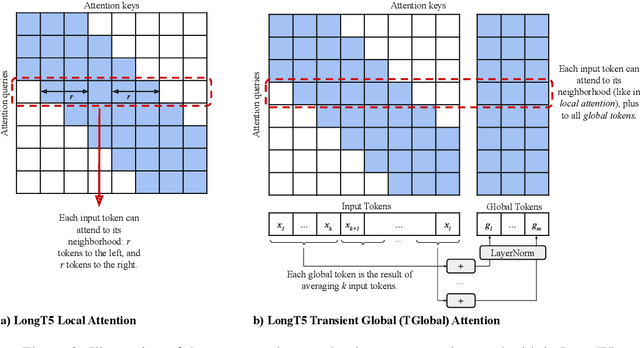
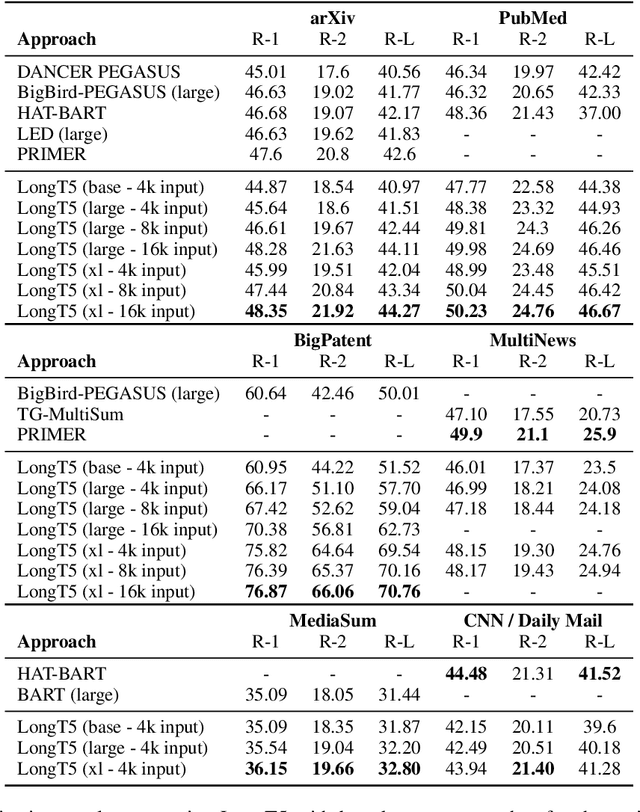
Recent work has shown that either (1) increasing the input length or (2) increasing model size can improve the performance of Transformer-based neural models. In this paper, we present a new model, called LongT5, with which we explore the effects of scaling both the input length and model size at the same time. Specifically, we integrated attention ideas from long-input transformers (ETC), and adopted pre-training strategies from summarization pre-training (PEGASUS) into the scalable T5 architecture. The result is a new attention mechanism we call {\em Transient Global} (TGlobal), which mimics ETC's local/global attention mechanism, but without requiring additional side-inputs. We are able to achieve state-of-the-art results on several summarization tasks and outperform the original T5 models on question answering tasks.