 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting Decoder-Based Language Models for Diverse Encoder Downstream Tasks
Mar 04, 2025



Decoder-based transformers, while revolutionizing language modeling and scaling to immense sizes, have not completely overtaken encoder-heavy architectures in natural language processing. Specifically, encoder-only models remain dominant in tasks like classification, regression, and ranking. This is primarily due to the inherent structure of decoder-based models, which limits their direct applicability to these tasks. In this paper, we introduce Gemma Encoder, adapting the powerful Gemma decoder model to an encoder architecture, thereby unlocking its potential for a wider range of non-generative applications. To optimize the adaptation from decoder to encoder, we systematically analyze various pooling strategies, attention mechanisms, and hyperparameters (e.g., dropout rate). Furthermore, we benchmark Gemma Encoder against established approaches on the GLUE benchmarks, and MS MARCO ranking benchmark, demonstrating its effectiveness and versatility.
SamToNe: Improving Contrastive Loss for Dual Encoder Retrieval Models with Same Tower Negatives
Jun 05, 2023



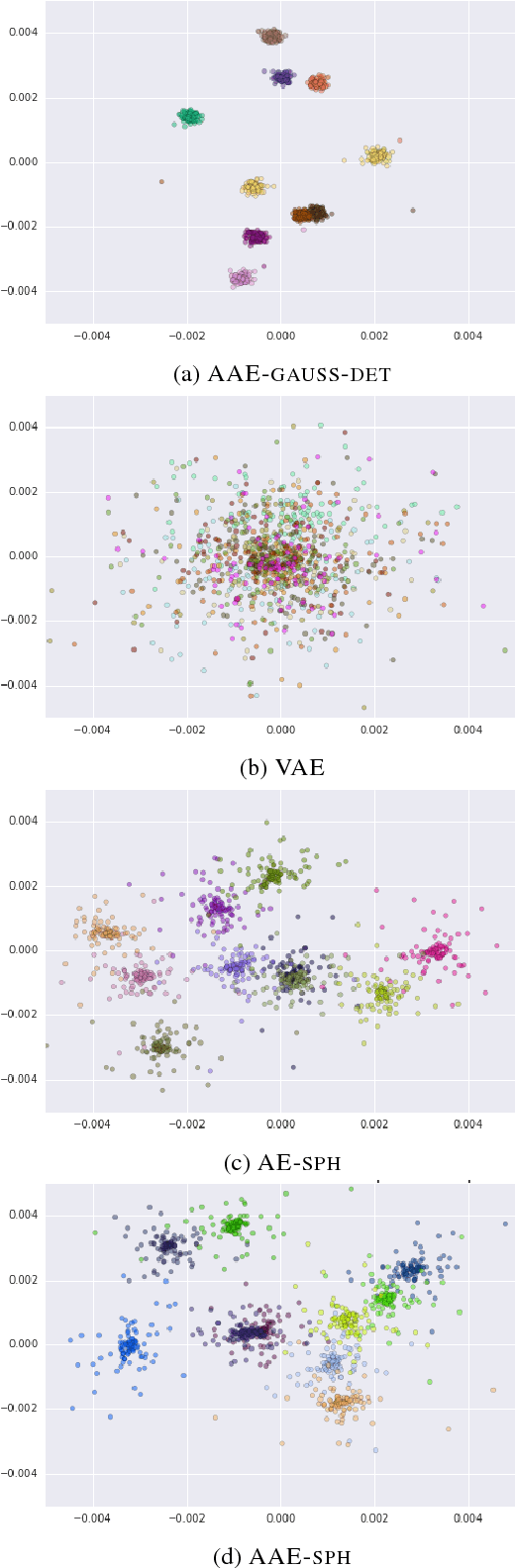
Dual encoders have been used for retrieval tasks and representation learning with good results. A standard way to train dual encoders is using a contrastive loss with in-batch negatives. In this work, we propose an improved contrastive learning objective by adding queries or documents from the same encoder towers to the negatives, for which we name it as "contrastive loss with SAMe TOwer NEgatives" (SamToNe). By evaluating on question answering retrieval benchmarks from MS MARCO and MultiReQA, and heterogenous zero-shot information retrieval benchmarks (BEIR), we demonstrate that SamToNe can effectively improve the retrieval quality for both symmetric and asymmetric dual encoders. By directly probing the embedding spaces of the two encoding towers via the t-SNE algorithm (van der Maaten and Hinton, 2008), we observe that SamToNe ensures the alignment between the embedding spaces from the two encoder towers. Based on the analysis of the embedding distance distributions of the top-$1$ retrieved results, we further explain the efficacy of the method from the perspective of regularisation.
SKILL: Structured Knowledge Infusion for Large Language Models
May 17, 2022
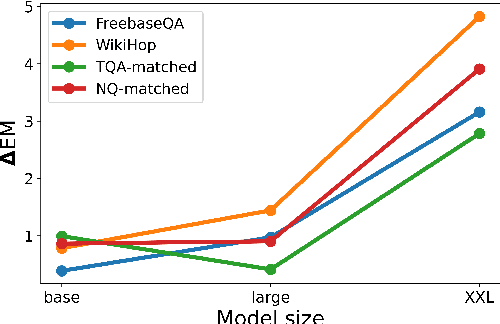
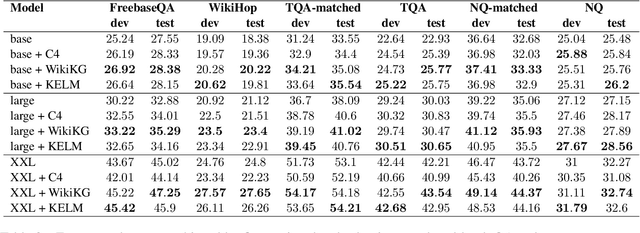
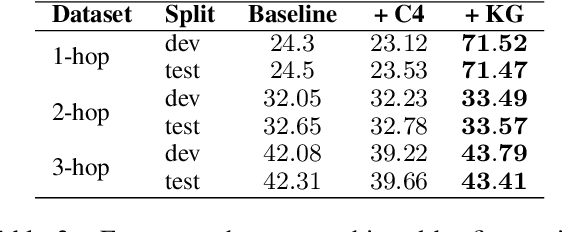
Large language models (LLMs) have demonstrated human-level performance on a vast spectrum of natural language tasks. However, it is largely unexplored whether they can better internalize knowledge from a structured data, such as a knowledge graph, or from text. In this work, we propose a method to infuse structured knowledge into LLMs, by directly training T5 models on factual triples of knowledge graphs (KGs). We show that models pre-trained on Wikidata KG with our method outperform the T5 baselines on FreebaseQA and WikiHop, as well as the Wikidata-answerable subset of TriviaQA and NaturalQuestions. The models pre-trained on factual triples compare competitively with the ones on natural language sentences that contain the same knowledge. Trained on a smaller size KG, WikiMovies, we saw 3x improvement of exact match score on MetaQA task compared to T5 baseline. The proposed method has an advantage that no alignment between the knowledge graph and text corpus is required in curating training data. This makes our method particularly useful when working with industry-scale knowledge graphs.
Exploring Dual Encoder Architectures for Question Answering
Apr 14, 2022
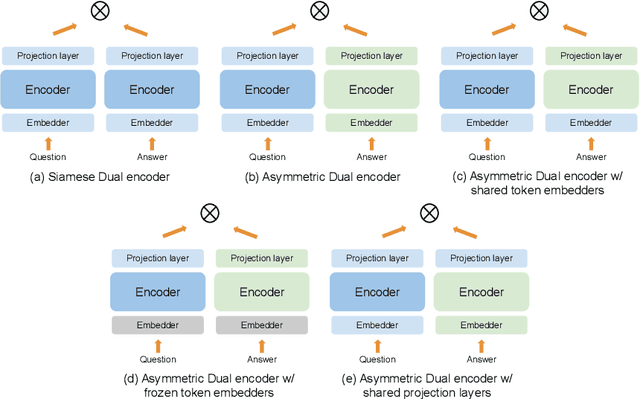
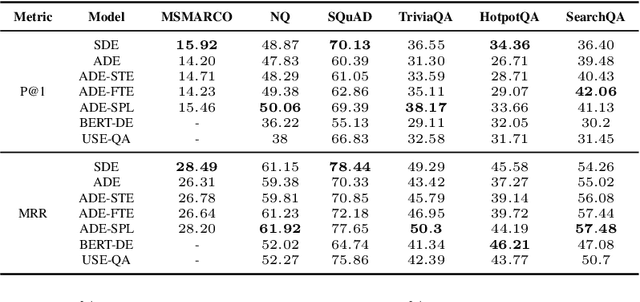

Dual encoders have been used for question-answering (QA) and information retrieval (IR) tasks with good results. There are two major types of dual encoders, Siamese Dual Encoders (SDE), with parameters shared across two encoders, and Asymmetric Dual Encoder (ADE), with two distinctly parameterized encoders. In this work, we explore the dual encoder architectures for QA retrieval tasks. By evaluating on MS MARCO and the MultiReQA benchmark, we show that SDE performs significantly better than ADE. We further propose three different improved versions of ADEs. Based on the evaluation of QA retrieval tasks and direct analysis of the embeddings, we demonstrate that sharing parameters in projection layers would enable ADEs to perform competitively with SDEs.
Eval all, trust a few, do wrong to none: Comparing sentence generation models
Oct 30, 2018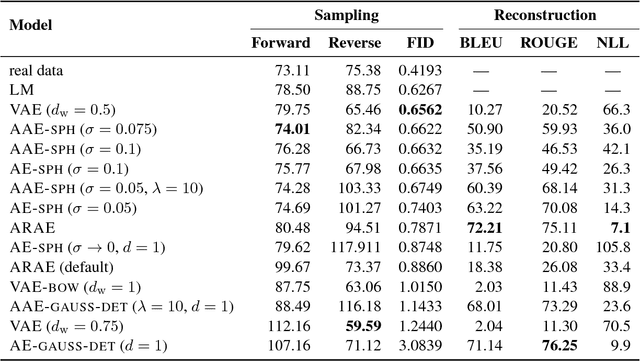


In this paper, we study recent neural generative models for text generation related to variational autoencoders. Previous works have employed various techniques to control the prior distribution of the latent codes in these models, which is important for sampling performance, but little attention has been paid to reconstruction error. In our study, we follow a rigorous evaluation protocol using a large set of previously used and novel automatic and human evaluation metrics, applied to both generated samples and reconstructions. We hope that it will become the new evaluation standard when comparing neural generative models for text.
Prosody Modifications for Question-Answering in Voice-Only Settings
Jun 11, 2018

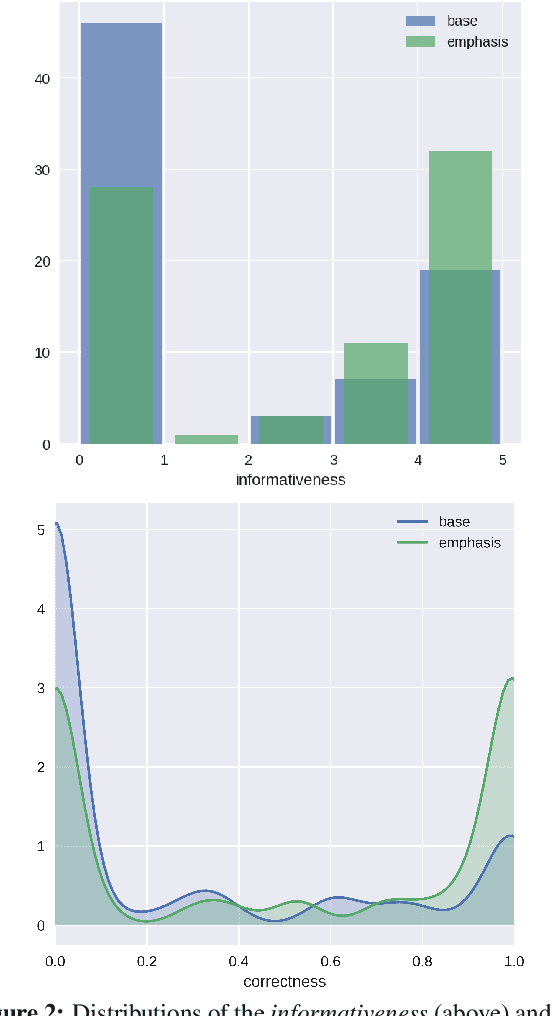

Many popular form factors of digital assistant---such as Amazon Echo, Apple Homepod or Google Home---enable the user to hold a conversation with the assistant based only on the speech modality. The lack of a screen from which the user can read text or watch supporting images or video presents unique challenges. In order to satisfy the information need of a user, we believe that the presentation of the answer needs to be optimized for such voice-only interactions. In this paper we propose a task of evaluating usefulness of prosody modifications for the purpose of voice-only question answering. We describe a crowd-sourcing setup where we evaluate the quality of these modifications along multiple dimensions corresponding to the informativeness, naturalness, and ability of the user to identify the key part of the answer. In addition, we propose a set of simple prosodic modifications that highlight important parts of the answer using various acoustic cues.
Learning to Attend, Copy, and Generate for Session-Based Query Suggestion
Nov 13, 2017
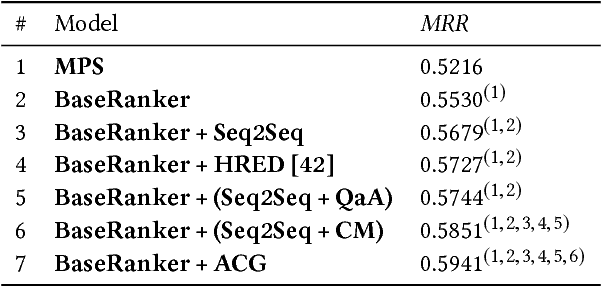
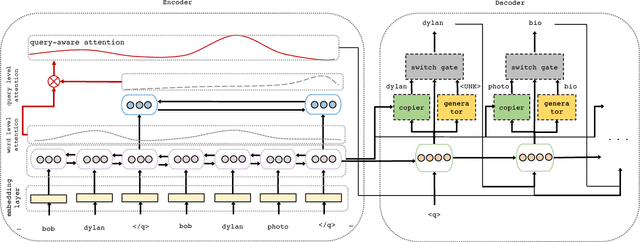
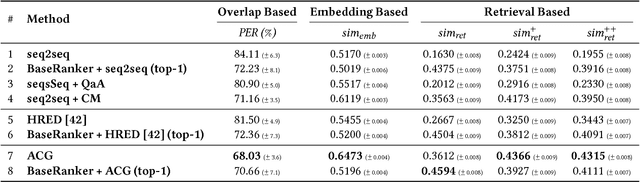
Users try to articulate their complex information needs during search sessions by reformulating their queries. To make this process more effective, search engines provide related queries to help users in specifying the information need in their search process. In this paper, we propose a customized sequence-to-sequence model for session-based query suggestion. In our model, we employ a query-aware attention mechanism to capture the structure of the session context. is enables us to control the scope of the session from which we infer the suggested next query, which helps not only handle the noisy data but also automatically detect session boundaries. Furthermore, we observe that, based on the user query reformulation behavior, within a single session a large portion of query terms is retained from the previously submitted queries and consists of mostly infrequent or unseen terms that are usually not included in the vocabulary. We therefore empower the decoder of our model to access the source words from the session context during decoding by incorporating a copy mechanism. Moreover, we propose evaluation metrics to assess the quality of the generative models for query suggestion. We conduct an extensive set of experiments and analysis. e results suggest that our model outperforms the baselines both in terms of the generating queries and scoring candidate queries for the task of query suggestion.
Fast k-best Sentence Compression
Oct 28, 2015
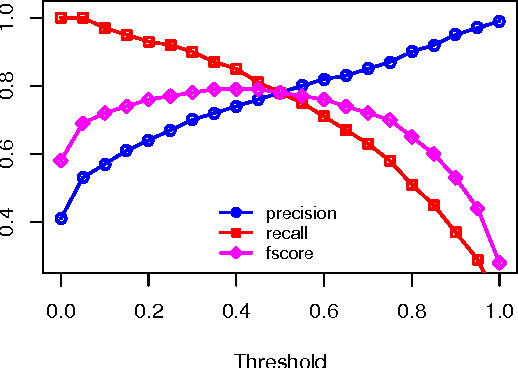
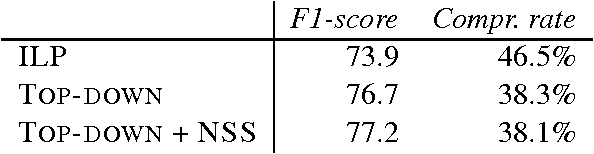
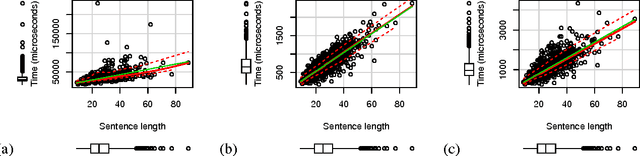
A popular approach to sentence compression is to formulate the task as a constrained optimization problem and solve it with integer linear programming (ILP) tools. Unfortunately, dependence on ILP may make the compressor prohibitively slow, and thus approximation techniques have been proposed which are often complex and offer a moderate gain in speed. As an alternative solution, we introduce a novel compression algorithm which generates k-best compressions relying on local deletion decisions. Our algorithm is two orders of magnitude faster than a recent ILP-based method while producing better compressions. Moreover, an extensive evaluation demonstrates that the quality of compressions does not degrade much as we move from single best to top-five results.