 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteract2Ar: Full-Body Human-Human Interaction Generation via Autoregressive Diffusion Models
Dec 22, 2025



Generating realistic human-human interactions is a challenging task that requires not only high-quality individual body and hand motions, but also coherent coordination among all interactants. Due to limitations in available data and increased learning complexity, previous methods tend to ignore hand motions, limiting the realism and expressivity of the interactions. Additionally, current diffusion-based approaches generate entire motion sequences simultaneously, limiting their ability to capture the reactive and adaptive nature of human interactions. To address these limitations, we introduce Interact2Ar, the first end-to-end text-conditioned autoregressive diffusion model for generating full-body, human-human interactions. Interact2Ar incorporates detailed hand kinematics through dedicated parallel branches, enabling high-fidelity full-body generation. Furthermore, we introduce an autoregressive pipeline coupled with a novel memory technique that facilitates adaptation to the inherent variability of human interactions using efficient large context windows. The adaptability of our model enables a series of downstream applications, including temporal motion composition, real-time adaptation to disturbances, and extension beyond dyadic to multi-person scenarios. To validate the generated motions, we introduce a set of robust evaluators and extended metrics designed specifically for assessing full-body interactions. Through quantitative and qualitative experiments, we demonstrate the state-of-the-art performance of Interact2Ar.
An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
Dec 19, 2025Vision-Language-Action (VLA) models are driving a revolution in robotics, enabling machines to understand instructions and interact with the physical world. This field is exploding with new models and datasets, making it both exciting and challenging to keep pace with. This survey offers a clear and structured guide to the VLA landscape. We design it to follow the natural learning path of a researcher: we start with the basic Modules of any VLA model, trace the history through key Milestones, and then dive deep into the core Challenges that define recent research frontier. Our main contribution is a detailed breakdown of the five biggest challenges in: (1) Representation, (2) Execution, (3) Generalization, (4) Safety, and (5) Dataset and Evaluation. This structure mirrors the developmental roadmap of a generalist agent: establishing the fundamental perception-action loop, scaling capabilities across diverse embodiments and environments, and finally ensuring trustworthy deployment-all supported by the essential data infrastructure. For each of them, we review existing approaches and highlight future opportunities. We position this paper as both a foundational guide for newcomers and a strategic roadmap for experienced researchers, with the dual aim of accelerating learning and inspiring new ideas in embodied intelligence. A live version of this survey, with continuous updates, is maintained on our \href{https://suyuz1.github.io/VLA-Survey-Anatomy/}{project page}.
SATGround: A Spatially-Aware Approach for Visual Grounding in Remote Sensing
Dec 09, 2025Vision-language models (VLMs) are emerging as powerful generalist tools for remote sensing, capable of integrating information across diverse tasks and enabling flexible, instruction-based interactions via a chat interface. In this work, we enhance VLM-based visual grounding in satellite imagery by proposing a novel structured localization mechanism. Our approach involves finetuning a pretrained VLM on a diverse set of instruction-following tasks, while interfacing a dedicated grounding module through specialized control tokens for localization. This method facilitates joint reasoning over both language and spatial information, significantly enhancing the model's ability to precisely localize objects in complex satellite scenes. We evaluate our framework on several remote sensing benchmarks, consistently improving the state-of-the-art, including a 24.8% relative improvement over previous methods on visual grounding. Our results highlight the benefits of integrating structured spatial reasoning into VLMs, paving the way for more reliable real-world satellite data analysis.
Reconstructing 3D Scenes in Native High Dynamic Range
Nov 17, 2025High Dynamic Range (HDR) imaging is essential for professional digital media creation, e.g., filmmaking, virtual production, and photorealistic rendering. However, 3D scene reconstruction has primarily focused on Low Dynamic Range (LDR) data, limiting its applicability to professional workflows. Existing approaches that reconstruct HDR scenes from LDR observations rely on multi-exposure fusion or inverse tone-mapping, which increase capture complexity and depend on synthetic supervision. With the recent emergence of cameras that directly capture native HDR data in a single exposure, we present the first method for 3D scene reconstruction that directly models native HDR observations. We propose {\bf Native High dynamic range 3D Gaussian Splatting (NH-3DGS)}, which preserves the full dynamic range throughout the reconstruction pipeline. Our key technical contribution is a novel luminance-chromaticity decomposition of the color representation that enables direct optimization from native HDR camera data. We demonstrate on both synthetic and real multi-view HDR datasets that NH-3DGS significantly outperforms existing methods in reconstruction quality and dynamic range preservation, enabling professional-grade 3D reconstruction directly from native HDR captures. Code and datasets will be made available.
Plug-and-Play Clarifier: A Zero-Shot Multimodal Framework for Egocentric Intent Disambiguation
Nov 12, 2025



The performance of egocentric AI agents is fundamentally limited by multimodal intent ambiguity. This challenge arises from a combination of underspecified language, imperfect visual data, and deictic gestures, which frequently leads to task failure. Existing monolithic Vision-Language Models (VLMs) struggle to resolve these multimodal ambiguous inputs, often failing silently or hallucinating responses. To address these ambiguities, we introduce the Plug-and-Play Clarifier, a zero-shot and modular framework that decomposes the problem into discrete, solvable sub-tasks. Specifically, our framework consists of three synergistic modules: (1) a text clarifier that uses dialogue-driven reasoning to interactively disambiguate linguistic intent, (2) a vision clarifier that delivers real-time guidance feedback, instructing users to adjust their positioning for improved capture quality, and (3) a cross-modal clarifier with grounding mechanism that robustly interprets 3D pointing gestures and identifies the specific objects users are pointing to. Extensive experiments demonstrate that our framework improves the intent clarification performance of small language models (4--8B) by approximately 30%, making them competitive with significantly larger counterparts. We also observe consistent gains when applying our framework to these larger models. Furthermore, our vision clarifier increases corrective guidance accuracy by over 20%, and our cross-modal clarifier improves semantic answer accuracy for referential grounding by 5%. Overall, our method provides a plug-and-play framework that effectively resolves multimodal ambiguity and significantly enhances user experience in egocentric interaction.
RetouchLLM: Training-free White-box Image Retouching
Oct 09, 2025Image retouching not only enhances visual quality but also serves as a means of expressing personal preferences and emotions. However, existing learning-based approaches require large-scale paired data and operate as black boxes, making the retouching process opaque and limiting their adaptability to handle diverse, user- or image-specific adjustments. In this work, we propose RetouchLLM, a training-free white-box image retouching system, which requires no training data and performs interpretable, code-based retouching directly on high-resolution images. Our framework progressively enhances the image in a manner similar to how humans perform multi-step retouching, allowing exploration of diverse adjustment paths. It comprises of two main modules: a visual critic that identifies differences between the input and reference images, and a code generator that produces executable codes. Experiments demonstrate that our approach generalizes well across diverse retouching styles, while natural language-based user interaction enables interpretable and controllable adjustments tailored to user intent.
Embodied Arena: A Comprehensive, Unified, and Evolving Evaluation Platform for Embodied AI
Sep 18, 2025Embodied AI development significantly lags behind large foundation models due to three critical challenges: (1) lack of systematic understanding of core capabilities needed for Embodied AI, making research lack clear objectives; (2) absence of unified and standardized evaluation systems, rendering cross-benchmark evaluation infeasible; and (3) underdeveloped automated and scalable acquisition methods for embodied data, creating critical bottlenecks for model scaling. To address these obstacles, we present Embodied Arena, a comprehensive, unified, and evolving evaluation platform for Embodied AI. Our platform establishes a systematic embodied capability taxonomy spanning three levels (perception, reasoning, task execution), seven core capabilities, and 25 fine-grained dimensions, enabling unified evaluation with systematic research objectives. We introduce a standardized evaluation system built upon unified infrastructure supporting flexible integration of 22 diverse benchmarks across three domains (2D/3D Embodied Q&A, Navigation, Task Planning) and 30+ advanced models from 20+ worldwide institutes. Additionally, we develop a novel LLM-driven automated generation pipeline ensuring scalable embodied evaluation data with continuous evolution for diversity and comprehensiveness. Embodied Arena publishes three real-time leaderboards (Embodied Q&A, Navigation, Task Planning) with dual perspectives (benchmark view and capability view), providing comprehensive overviews of advanced model capabilities. Especially, we present nine findings summarized from the evaluation results on the leaderboards of Embodied Arena. This helps to establish clear research veins and pinpoint critical research problems, thereby driving forward progress in the field of Embodied AI.
LMAD: Integrated End-to-End Vision-Language Model for Explainable Autonomous Driving
Aug 17, 2025
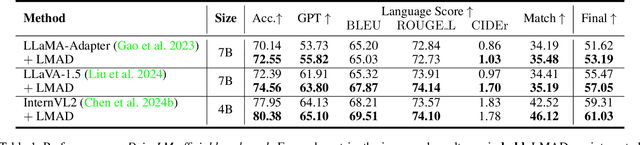

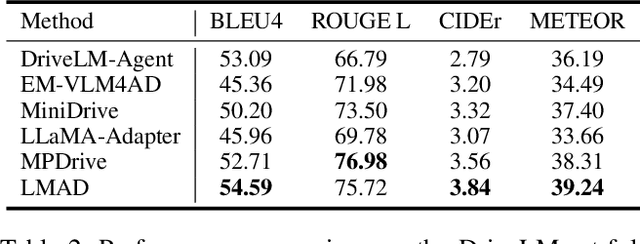
Large vision-language models (VLMs) have shown promising capabilities in scene understanding, enhancing the explainability of driving behaviors and interactivity with users. Existing methods primarily fine-tune VLMs on on-board multi-view images and scene reasoning text, but this approach often lacks the holistic and nuanced scene recognition and powerful spatial awareness required for autonomous driving, especially in complex situations. To address this gap, we propose a novel vision-language framework tailored for autonomous driving, called LMAD. Our framework emulates modern end-to-end driving paradigms by incorporating comprehensive scene understanding and a task-specialized structure with VLMs. In particular, we introduce preliminary scene interaction and specialized expert adapters within the same driving task structure, which better align VLMs with autonomous driving scenarios. Furthermore, our approach is designed to be fully compatible with existing VLMs while seamlessly integrating with planning-oriented driving systems. Extensive experiments on the DriveLM and nuScenes-QA datasets demonstrate that LMAD significantly boosts the performance of existing VLMs on driving reasoning tasks,setting a new standard in explainable autonomous driving.
Unlocking the Potential of Diffusion Priors in Blind Face Restoration
Aug 12, 2025



Although diffusion prior is rising as a powerful solution for blind face restoration (BFR), the inherent gap between the vanilla diffusion model and BFR settings hinders its seamless adaptation. The gap mainly stems from the discrepancy between 1) high-quality (HQ) and low-quality (LQ) images and 2) synthesized and real-world images. The vanilla diffusion model is trained on images with no or less degradations, whereas BFR handles moderately to severely degraded images. Additionally, LQ images used for training are synthesized by a naive degradation model with limited degradation patterns, which fails to simulate complex and unknown degradations in real-world scenarios. In this work, we use a unified network FLIPNET that switches between two modes to resolve specific gaps. In Restoration mode, the model gradually integrates BFR-oriented features and face embeddings from LQ images to achieve authentic and faithful face restoration. In Degradation mode, the model synthesizes real-world like degraded images based on the knowledge learned from real-world degradation datasets. Extensive evaluations on benchmark datasets show that our model 1) outperforms previous diffusion prior based BFR methods in terms of authenticity and fidelity, and 2) outperforms the naive degradation model in modeling the real-world degradations.
Region-based Cluster Discrimination for Visual Representation Learning
Jul 26, 2025Learning visual representations is foundational for a broad spectrum of downstream tasks. Although recent vision-language contrastive models, such as CLIP and SigLIP, have achieved impressive zero-shot performance via large-scale vision-language alignment, their reliance on global representations constrains their effectiveness for dense prediction tasks, such as grounding, OCR, and segmentation. To address this gap, we introduce Region-Aware Cluster Discrimination (RICE), a novel method that enhances region-level visual and OCR capabilities. We first construct a billion-scale candidate region dataset and propose a Region Transformer layer to extract rich regional semantics. We further design a unified region cluster discrimination loss that jointly supports object and OCR learning within a single classification framework, enabling efficient and scalable distributed training on large-scale data. Extensive experiments show that RICE consistently outperforms previous methods on tasks, including segmentation, dense detection, and visual perception for Multimodal Large Language Models (MLLMs). The pre-trained models have been released at https://github.com/deepglint/MVT.