 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBinary Latent Diffusion
Apr 10, 2023



In this paper, we show that a binary latent space can be explored for compact yet expressive image representations. We model the bi-directional mappings between an image and the corresponding latent binary representation by training an auto-encoder with a Bernoulli encoding distribution. On the one hand, the binary latent space provides a compact discrete image representation of which the distribution can be modeled more efficiently than pixels or continuous latent representations. On the other hand, we now represent each image patch as a binary vector instead of an index of a learned cookbook as in discrete image representations with vector quantization. In this way, we obtain binary latent representations that allow for better image quality and high-resolution image representations without any multi-stage hierarchy in the latent space. In this binary latent space, images can now be generated effectively using a binary latent diffusion model tailored specifically for modeling the prior over the binary image representations. We present both conditional and unconditional image generation experiments with multiple datasets, and show that the proposed method performs comparably to state-of-the-art methods while dramatically improving the sampling efficiency to as few as 16 steps without using any test-time acceleration. The proposed framework can also be seamlessly scaled to $1024 \times 1024$ high-resolution image generation without resorting to latent hierarchy or multi-stage refinements.
Energy-Inspired Self-Supervised Pretraining for Vision Models
Feb 02, 2023Motivated by the fact that forward and backward passes of a deep network naturally form symmetric mappings between input and output representations, we introduce a simple yet effective self-supervised vision model pretraining framework inspired by energy-based models (EBMs). In the proposed framework, we model energy estimation and data restoration as the forward and backward passes of a single network without any auxiliary components, e.g., an extra decoder. For the forward pass, we fit a network to an energy function that assigns low energy scores to samples that belong to an unlabeled dataset, and high energy otherwise. For the backward pass, we restore data from corrupted versions iteratively using gradient-based optimization along the direction of energy minimization. In this way, we naturally fold the encoder-decoder architecture widely used in masked image modeling into the forward and backward passes of a single vision model. Thus, our framework now accepts a wide range of pretext tasks with different data corruption methods, and permits models to be pretrained from masked image modeling, patch sorting, and image restoration, including super-resolution, denoising, and colorization. We support our findings with extensive experiments, and show the proposed method delivers comparable and even better performance with remarkably fewer epochs of training compared to the state-of-the-art self-supervised vision model pretraining methods. Our findings shed light on further exploring self-supervised vision model pretraining and pretext tasks beyond masked image modeling.
Observability Analysis of Graph SLAM-Based Joint Calibration of Multiple Microphone Arrays and Sound Source Localization
Oct 11, 2022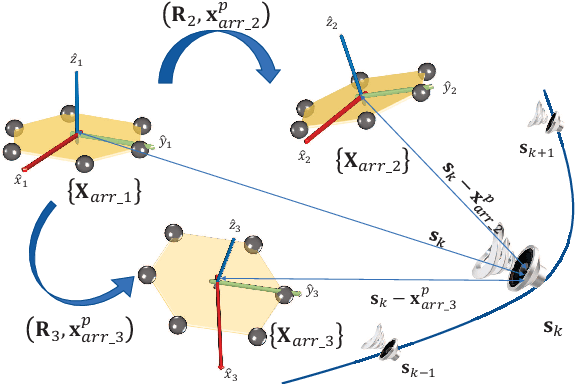
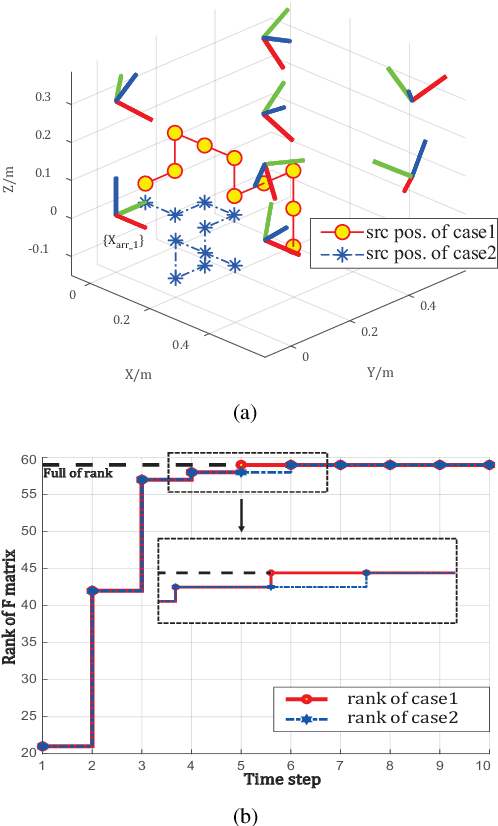
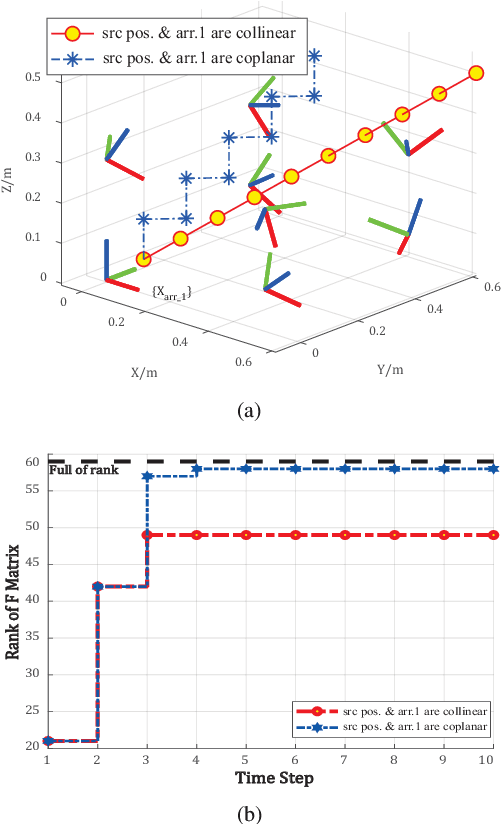
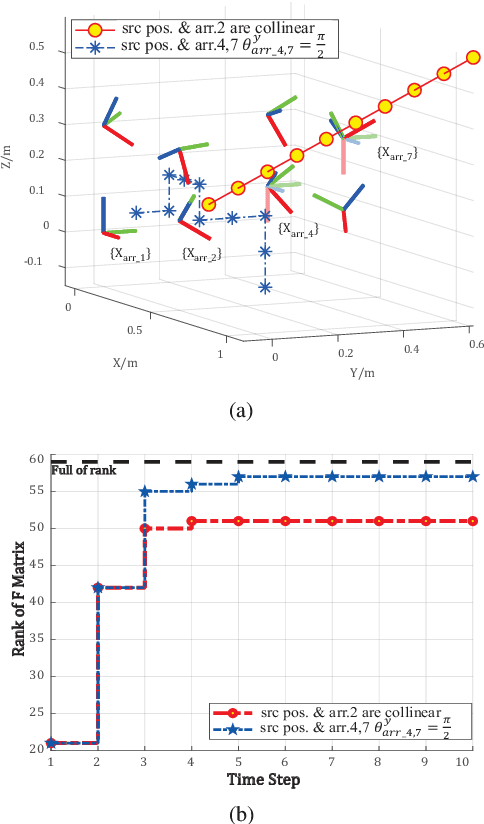
Multiple microphone arrays have many applications in robot audition, including sound source localization, audio scene perception and analysis, etc. However, accurate calibration of multiple microphone arrays remains a challenge because there are many unknown parameters to be identified, including the Euler angles, geometry, asynchronous factors between the microphone arrays. This paper is concerned with joint calibration of multiple microphone arrays and sound source localization using graph simultaneous localization and mapping (SLAM). By using a Fisher information matrix (FIM) approach, we focus on the observability analysis of the graph SLAM framework for the above-mentioned calibration problem. We thoroughly investigate the identifiability of the unknown parameters, including the Euler angles, geometry, asynchronous effects between the microphone arrays, and the sound source locations. We establish necessary/sufficient conditions under which the FIM and the Jacobian matrix have full column rank, which implies the identifiability of the unknown parameters. These conditions are closely related to the variation in the motion of the sound source and the configuration of microphone arrays, and have intuitive and physical interpretations. We also discover several scenarios where the unknown parameters are not uniquely identifiable. All theoretical findings are demonstrated using simulation data.
Consistent Video Instance Segmentation with Inter-Frame Recurrent Attention
Jun 14, 2022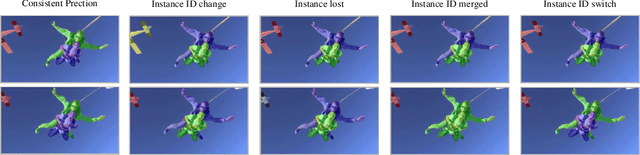
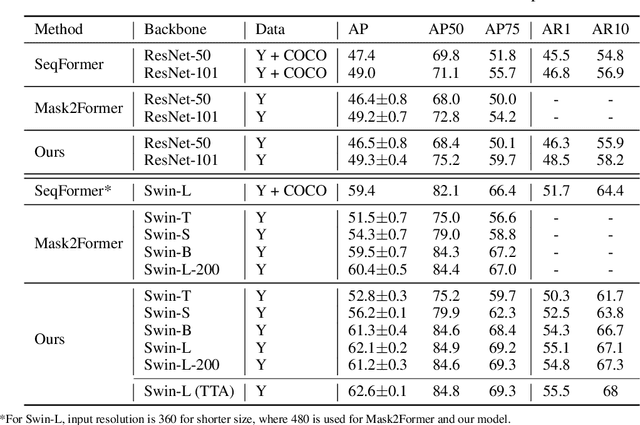
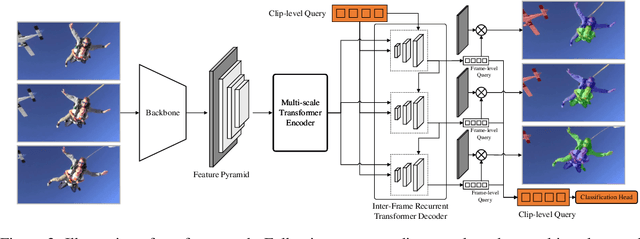
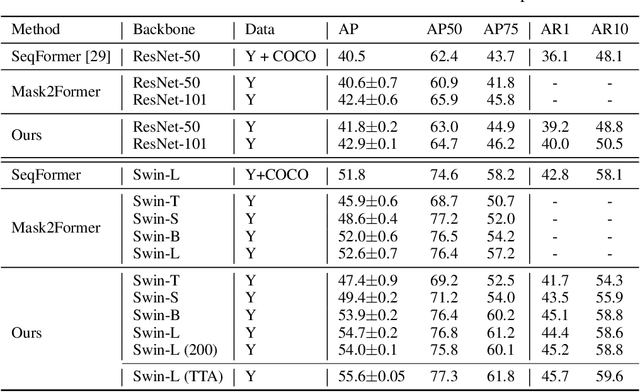
Video instance segmentation aims at predicting object segmentation masks for each frame, as well as associating the instances across multiple frames. Recent end-to-end video instance segmentation methods are capable of performing object segmentation and instance association together in a direct parallel sequence decoding/prediction framework. Although these methods generally predict higher quality object segmentation masks, they can fail to associate instances in challenging cases because they do not explicitly model the temporal instance consistency for adjacent frames. We propose a consistent end-to-end video instance segmentation framework with Inter-Frame Recurrent Attention to model both the temporal instance consistency for adjacent frames and the global temporal context. Our extensive experiments demonstrate that the Inter-Frame Recurrent Attention significantly improves temporal instance consistency while maintaining the quality of the object segmentation masks. Our model achieves state-of-the-art accuracy on both YouTubeVIS-2019 (62.1\%) and YouTubeVIS-2021 (54.7\%) datasets. In addition, quantitative and qualitative results show that the proposed methods predict more temporally consistent instance segmentation masks.
Augmenting Knowledge Graphs for Better Link Prediction
Mar 26, 2022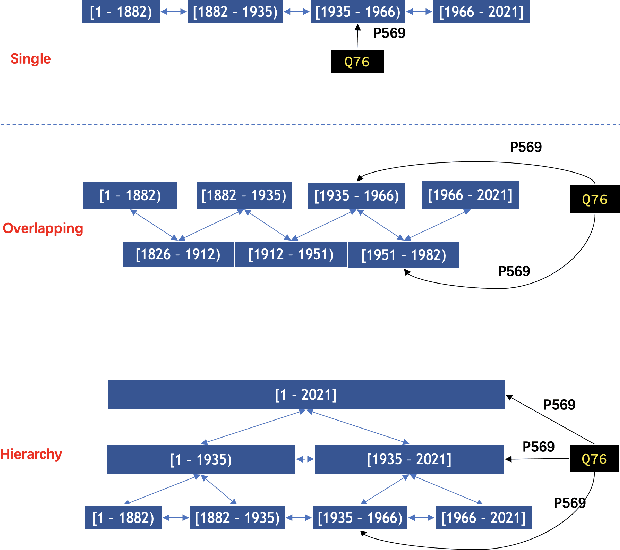

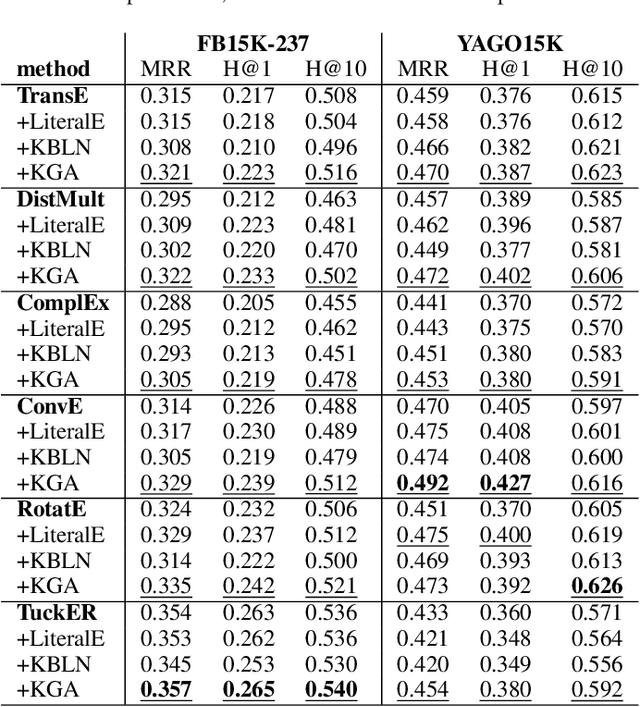
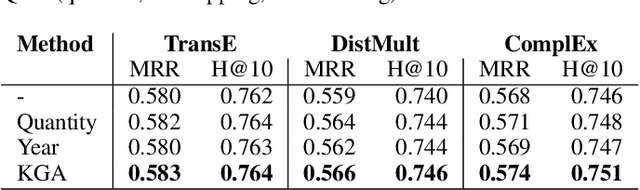
Embedding methods have demonstrated robust performance on the task of link prediction in knowledge graphs, by mostly encoding entity relationships. Recent methods propose to enhance the loss function with a literal-aware term. In this paper, we propose KGA: a knowledge graph augmentation method that incorporates literals in an embedding model without modifying its loss function. KGA discretizes quantity and year values into bins, and chains these bins both horizontally, modeling neighboring values, and vertically, modeling multiple levels of granularity. KGA is scalable and can be used as a pre-processing step for any existing knowledge graph embedding model. Experiments on legacy benchmarks and a new large benchmark, DWD, show that augmenting the knowledge graph with quantities and years is beneficial for predicting both entities and numbers, as KGA outperforms the vanilla models and other relevant baselines. Our ablation studies confirm that both quantities and years contribute to KGA's performance, and that its performance depends on the discretization and binning settings. We make the code, models, and the DWD benchmark publicly available to facilitate reproducibility and future research.
Deep Frequency Filtering for Domain Generalization
Mar 23, 2022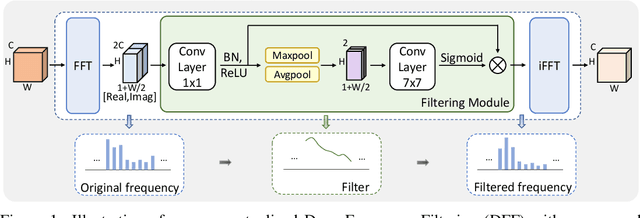
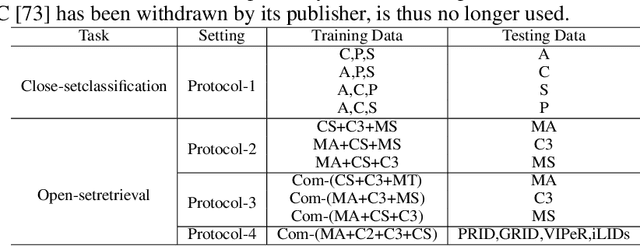
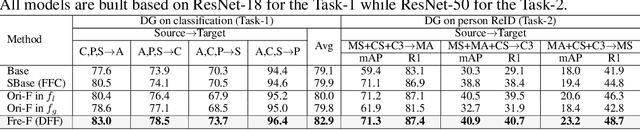

Improving the generalization capability of Deep Neural Networks (DNNs) is critical for their practical uses, which has been a longstanding challenge. Some theoretical studies have revealed that DNNs have preferences to different frequency components in the learning process and indicated that this may affect the robustness of learned features. In this paper, we propose Deep Frequency Filtering (DFF) for learning domain-generalizable features, which is the first endeavour to explicitly modulate frequency components of different transfer difficulties across domains during training. To achieve this, we perform Fast Fourier Transform (FFT) on feature maps at different layers, then adopt a light-weight module to learn the attention masks from frequency representations after FFT to enhance transferable frequency components while suppressing the components not conductive to generalization. Further, we empirically compare different types of attention for implementing our conceptualized DFF. Extensive experiments demonstrate the effectiveness of the proposed DFF and show that applying DFF on a plain baseline outperforms the state-of-the-art methods on different domain generalization tasks, including close-set classification and open-set retrieval.
Lifelong Unsupervised Domain Adaptive Person Re-identification with Coordinated Anti-forgetting and Adaptation
Dec 13, 2021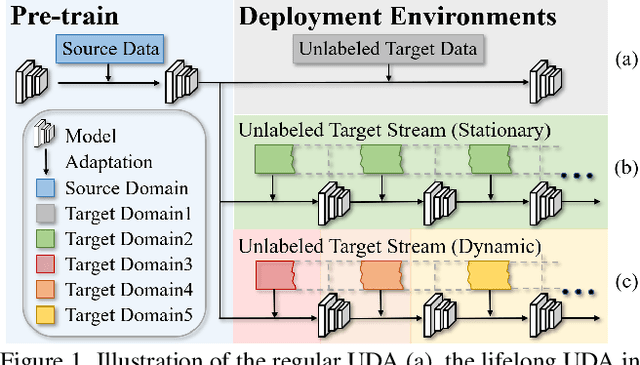

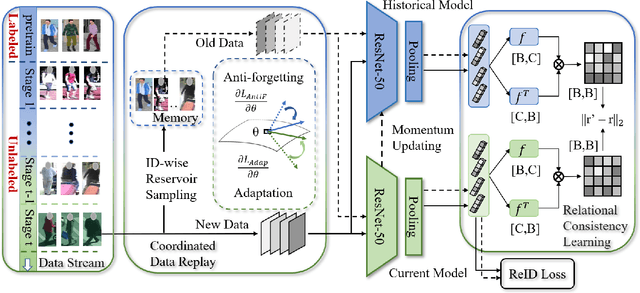
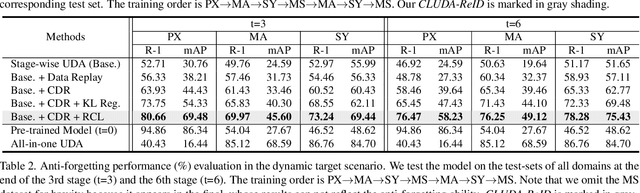
Unsupervised domain adaptive person re-identification (ReID) has been extensively investigated to mitigate the adverse effects of domain gaps. Those works assume the target domain data can be accessible all at once. However, for the real-world streaming data, this hinders the timely adaptation to changing data statistics and sufficient exploitation of increasing samples. In this paper, to address more practical scenarios, we propose a new task, Lifelong Unsupervised Domain Adaptive (LUDA) person ReID. This is challenging because it requires the model to continuously adapt to unlabeled data of the target environments while alleviating catastrophic forgetting for such a fine-grained person retrieval task. We design an effective scheme for this task, dubbed CLUDA-ReID, where the anti-forgetting is harmoniously coordinated with the adaptation. Specifically, a meta-based Coordinated Data Replay strategy is proposed to replay old data and update the network with a coordinated optimization direction for both adaptation and memorization. Moreover, we propose Relational Consistency Learning for old knowledge distillation/inheritance in line with the objective of retrieval-based tasks. We set up two evaluation settings to simulate the practical application scenarios. Extensive experiments demonstrate the effectiveness of our CLUDA-ReID for both scenarios with stationary target streams and scenarios with dynamic target streams.
MMPTRACK: Large-scale Densely Annotated Multi-camera Multiple People Tracking Benchmark
Nov 30, 2021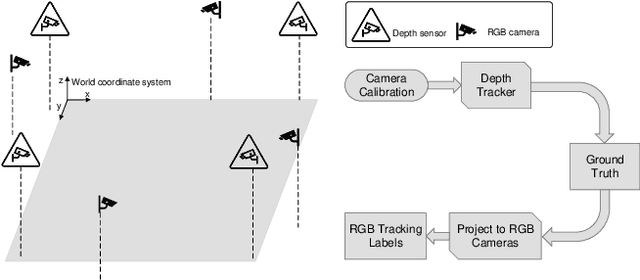
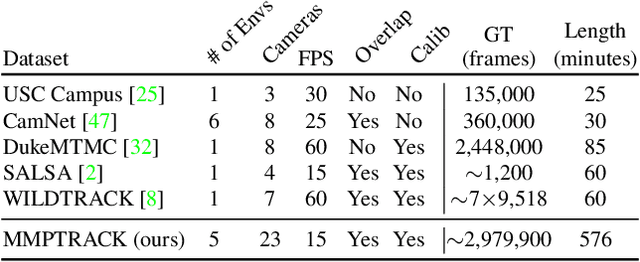

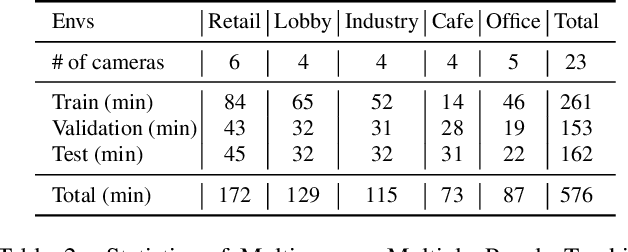
Multi-camera tracking systems are gaining popularity in applications that demand high-quality tracking results, such as frictionless checkout because monocular multi-object tracking (MOT) systems often fail in cluttered and crowded environments due to occlusion. Multiple highly overlapped cameras can significantly alleviate the problem by recovering partial 3D information. However, the cost of creating a high-quality multi-camera tracking dataset with diverse camera settings and backgrounds has limited the dataset scale in this domain. In this paper, we provide a large-scale densely-labeled multi-camera tracking dataset in five different environments with the help of an auto-annotation system. The system uses overlapped and calibrated depth and RGB cameras to build a high-performance 3D tracker that automatically generates the 3D tracking results. The 3D tracking results are projected to each RGB camera view using camera parameters to create 2D tracking results. Then, we manually check and correct the 3D tracking results to ensure the label quality, which is much cheaper than fully manual annotation. We have conducted extensive experiments using two real-time multi-camera trackers and a person re-identification (ReID) model with different settings. This dataset provides a more reliable benchmark of multi-camera, multi-object tracking systems in cluttered and crowded environments. Also, our results demonstrate that adapting the trackers and ReID models on this dataset significantly improves their performance. Our dataset will be publicly released upon the acceptance of this work.
TransMOT: Spatial-Temporal Graph Transformer for Multiple Object Tracking
Apr 03, 2021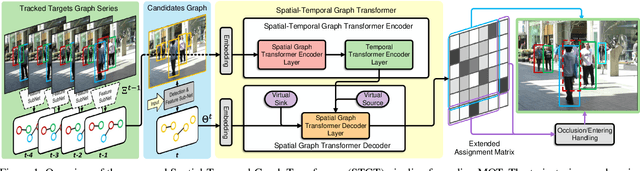
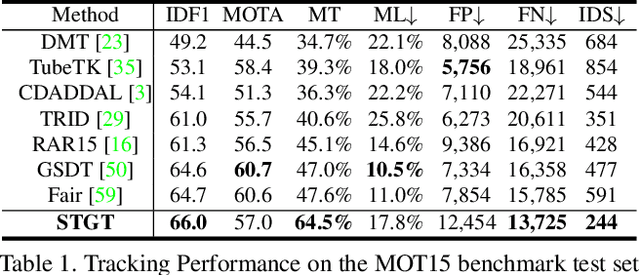
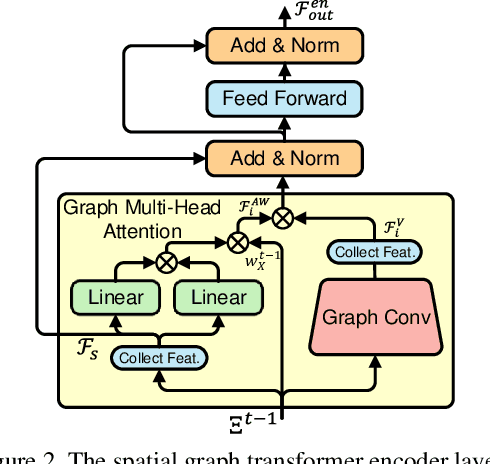
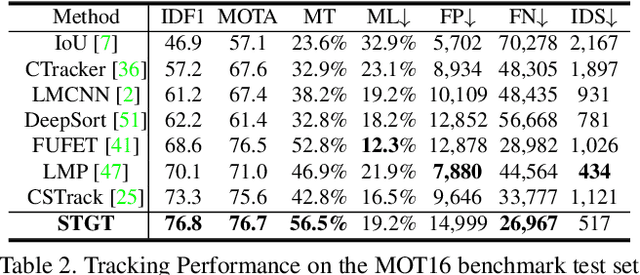
Tracking multiple objects in videos relies on modeling the spatial-temporal interactions of the objects. In this paper, we propose a solution named TransMOT, which leverages powerful graph transformers to efficiently model the spatial and temporal interactions among the objects. TransMOT effectively models the interactions of a large number of objects by arranging the trajectories of the tracked objects as a set of sparse weighted graphs, and constructing a spatial graph transformer encoder layer, a temporal transformer encoder layer, and a spatial graph transformer decoder layer based on the graphs. TransMOT is not only more computationally efficient than the traditional Transformer, but it also achieves better tracking accuracy. To further improve the tracking speed and accuracy, we propose a cascade association framework to handle low-score detections and long-term occlusions that require large computational resources to model in TransMOT. The proposed method is evaluated on multiple benchmark datasets including MOT15, MOT16, MOT17, and MOT20, and it achieves state-of-the-art performance on all the datasets.
Computational Impact Time Guidance: A Learning-Based Prediction-Correction Approach
Mar 09, 2021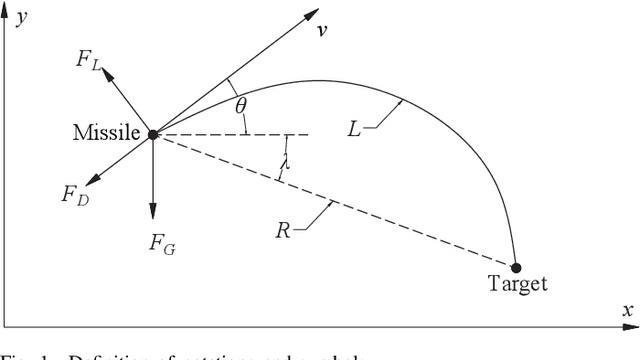
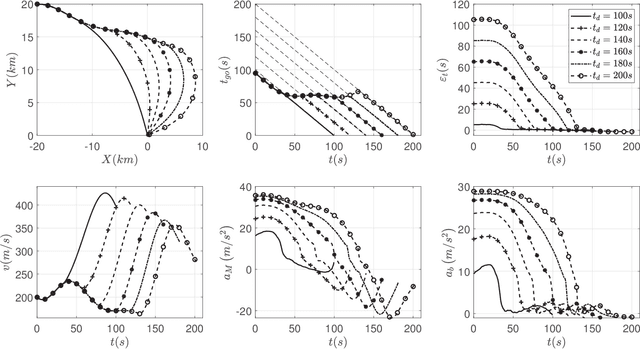
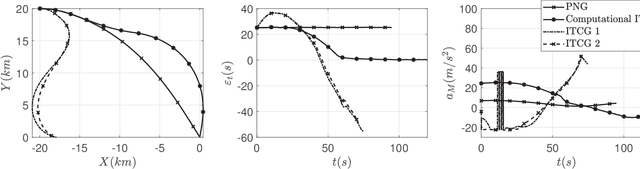
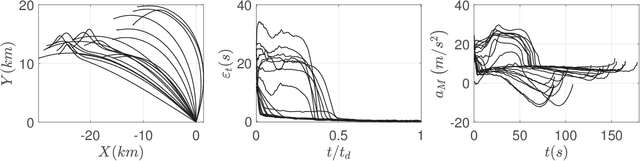
This paper investigates the problem of impact-time-control and proposes a learning-based computational guidance algorithm to solve this problem. The proposed guidance algorithm is developed based on a general prediction-correction concept: the exact time-to-go under proportional navigation guidance with realistic aerodynamic characteristics is estimated by a deep neural network and a biased command to nullify the impact time error is developed by utilizing the emerging reinforcement learning techniques. The deep neural network is augmented into the reinforcement learning block to resolve the issue of sparse reward that has been observed in typical reinforcement learning formulation. Extensive numerical simulations are conducted to support the proposed algorithm.