 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConsistent Video Instance Segmentation with Inter-Frame Recurrent Attention
Paper and Code
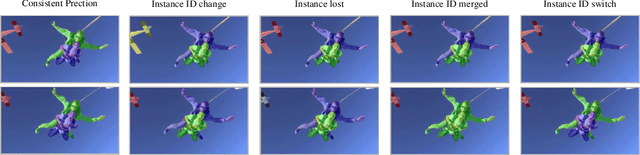
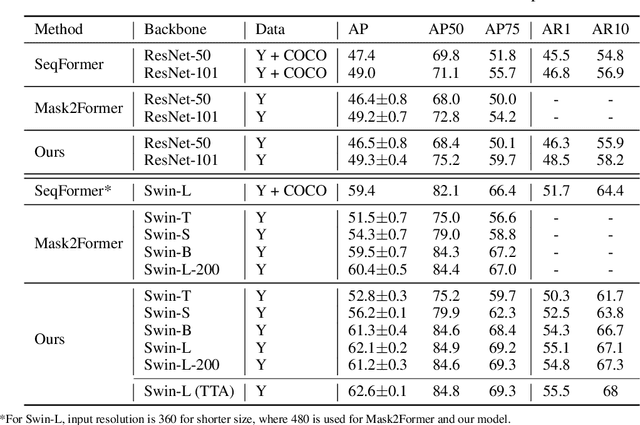
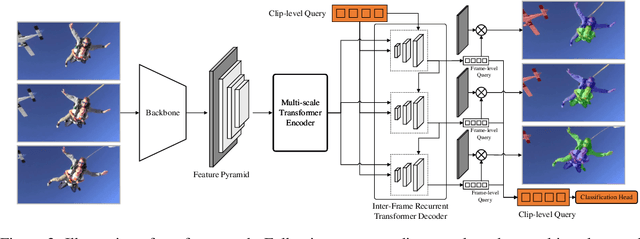
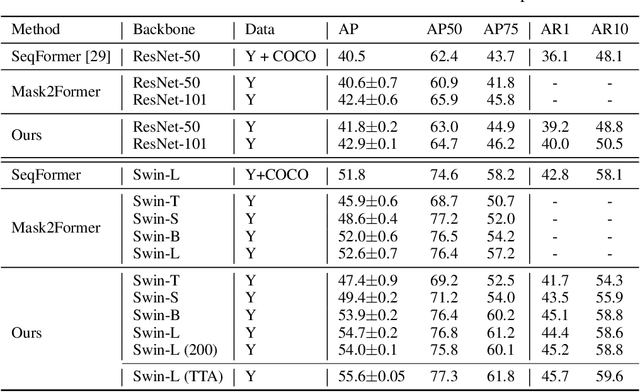
Video instance segmentation aims at predicting object segmentation masks for each frame, as well as associating the instances across multiple frames. Recent end-to-end video instance segmentation methods are capable of performing object segmentation and instance association together in a direct parallel sequence decoding/prediction framework. Although these methods generally predict higher quality object segmentation masks, they can fail to associate instances in challenging cases because they do not explicitly model the temporal instance consistency for adjacent frames. We propose a consistent end-to-end video instance segmentation framework with Inter-Frame Recurrent Attention to model both the temporal instance consistency for adjacent frames and the global temporal context. Our extensive experiments demonstrate that the Inter-Frame Recurrent Attention significantly improves temporal instance consistency while maintaining the quality of the object segmentation masks. Our model achieves state-of-the-art accuracy on both YouTubeVIS-2019 (62.1\%) and YouTubeVIS-2021 (54.7\%) datasets. In addition, quantitative and qualitative results show that the proposed methods predict more temporally consistent instance segmentation masks.