 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Autonomous Drone Navigation using LLMs Deployed in Edge-Cloud Computing
Apr 01, 2025Autonomous navigation is usually trained offline in diverse scenarios and fine-tuned online subject to real-world experiences. However, the real world is dynamic and changeable, and many environmental encounters/effects are not accounted for in real-time due to difficulties in describing them within offline training data or hard to describe even in online scenarios. However, we know that the human operator can describe these dynamic environmental encounters through natural language, adding semantic context. The research is to deploy Large Language Models (LLMs) to perform real-time contextual code adjustment to autonomous navigation. The challenge not evaluated in literature is what LLMs are appropriate and where should these computationally heavy algorithms sit in the computation-communication edge-cloud computing architectures. In this paper, we evaluate how different LLMs can adjust both the navigation map parameters dynamically (e.g., contour map shaping) and also derive navigation task instruction sets. We then evaluate which LLMs are most suitable and where they should sit in future edge-cloud of 6G telecommunication architectures.
Explainable Interface for Human-Autonomy Teaming: A Survey
May 04, 2024



Nowadays, large-scale foundation models are being increasingly integrated into numerous safety-critical applications, including human-autonomy teaming (HAT) within transportation, medical, and defence domains. Consequently, the inherent 'black-box' nature of these sophisticated deep neural networks heightens the significance of fostering mutual understanding and trust between humans and autonomous systems. To tackle the transparency challenges in HAT, this paper conducts a thoughtful study on the underexplored domain of Explainable Interface (EI) in HAT systems from a human-centric perspective, thereby enriching the existing body of research in Explainable Artificial Intelligence (XAI). We explore the design, development, and evaluation of EI within XAI-enhanced HAT systems. To do so, we first clarify the distinctions between these concepts: EI, explanations and model explainability, aiming to provide researchers and practitioners with a structured understanding. Second, we contribute to a novel framework for EI, addressing the unique challenges in HAT. Last, our summarized evaluation framework for ongoing EI offers a holistic perspective, encompassing model performance, human-centered factors, and group task objectives. Based on extensive surveys across XAI, HAT, psychology, and Human-Computer Interaction (HCI), this review offers multiple novel insights into incorporating XAI into HAT systems and outlines future directions.
Two-Stage Violence Detection Using ViTPose and Classification Models at Smart Airports
Aug 30, 2023



This study introduces an innovative violence detection framework tailored to the unique requirements of smart airports, where prompt responses to violent situations are crucial. The proposed framework harnesses the power of ViTPose for human pose estimation. It employs a CNN - BiLSTM network to analyse spatial and temporal information within keypoints sequences, enabling the accurate classification of violent behaviour in real time. Seamlessly integrated within the SAFE (Situational Awareness for Enhanced Security framework of SAAB, the solution underwent integrated testing to ensure robust performance in real world scenarios. The AIRTLab dataset, characterized by its high video quality and relevance to surveillance scenarios, is utilized in this study to enhance the model's accuracy and mitigate false positives. As airports face increased foot traffic in the post pandemic era, implementing AI driven violence detection systems, such as the one proposed, is paramount for improving security, expediting response times, and promoting data informed decision making. The implementation of this framework not only diminishes the probability of violent events but also assists surveillance teams in effectively addressing potential threats, ultimately fostering a more secure and protected aviation sector. Codes are available at: https://github.com/Asami-1/GDP.
Dynamic deep-reinforcement-learning algorithm in Partially Observed Markov Decision Processes
Jul 29, 2023



Reinforcement learning has been greatly improved in recent studies and an increased interest in real-world implementation has emerged in recent years. In many cases, due to the non-static disturbances, it becomes challenging for the agent to keep the performance. The disturbance results in the environment called Partially Observable Markov Decision Process. In common practice, Partially Observable Markov Decision Process is handled by introducing an additional estimator, or Recurrent Neural Network is utilized in the context of reinforcement learning. Both of the cases require to process sequential information on the trajectory. However, there are only a few studies investigating the effect of information to consider and the network structure to handle them. This study shows the benefit of action sequence inclusion in order to solve Partially Observable Markov Decision Process. Several structures and approaches are proposed to extend one of the latest deep reinforcement learning algorithms with LSTM networks. The developed algorithms showed enhanced robustness of controller performance against different types of external disturbances that are added to observation.
An Auction-based Coordination Strategy for Task-Constrained Multi-Agent Stochastic Planning with Submodular Rewards
Dec 30, 2022In many domains such as transportation and logistics, search and rescue, or cooperative surveillance, tasks are pending to be allocated with the consideration of possible execution uncertainties. Existing task coordination algorithms either ignore the stochastic process or suffer from the computational intensity. Taking advantage of the weakly coupled feature of the problem and the opportunity for coordination in advance, we propose a decentralized auction-based coordination strategy using a newly formulated score function which is generated by forming the problem into task-constrained Markov decision processes (MDPs). The proposed method guarantees convergence and at least 50% optimality in the premise of a submodular reward function. Furthermore, for the implementation on large-scale applications, an approximate variant of the proposed method, namely Deep Auction, is also suggested with the use of neural networks, which is evasive of the troublesome for constructing MDPs. Inspired by the well-known actor-critic architecture, two Transformers are used to map observations to action probabilities and cumulative rewards respectively. Finally, we demonstrate the performance of the two proposed approaches in the context of drone deliveries, where the stochastic planning for the drone league is cast into a stochastic price-collecting Vehicle Routing Problem (VRP) with time windows. Simulation results are compared with state-of-the-art methods in terms of solution quality, planning efficiency and scalability.
Incremental Correction in Dynamic Systems Modelled with Neural Networks for Constraint Satisfaction
Sep 08, 2022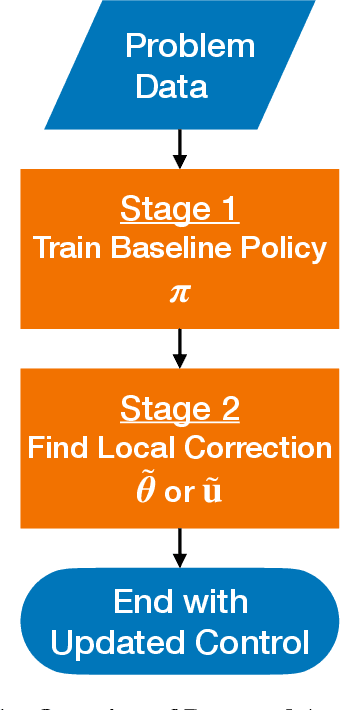

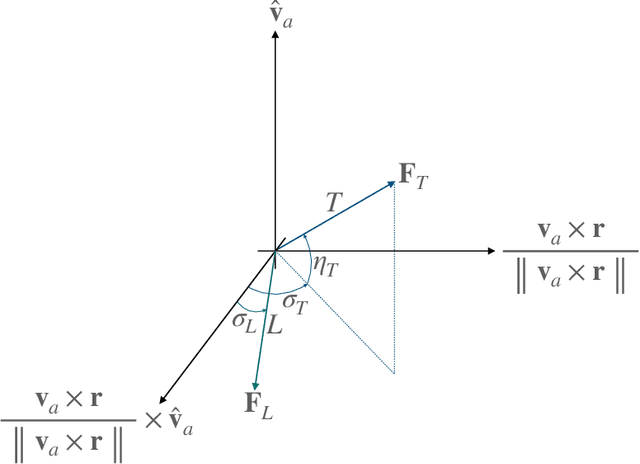
This study presents incremental correction methods for refining neural network parameters or control functions entering into a continuous-time dynamic system to achieve improved solution accuracy in satisfying the interim point constraints placed on the performance output variables. The proposed approach is to linearise the dynamics around the baseline values of its arguments, and then to solve for the corrective input required to transfer the perturbed trajectory to precisely known or desired values at specific time points, i.e., the interim points. Depending on the type of decision variables to adjust, parameter correction and control function correction methods are developed. These incremental correction methods can be utilised as a means to compensate for the prediction errors of pre-trained neural networks in real-time applications where high accuracy of the prediction of dynamical systems at prescribed time points is imperative. In this regard, the online update approach can be useful for enhancing overall targeting accuracy of finite-horizon control subject to point constraints using a neural policy. Numerical example demonstrates the effectiveness of the proposed approach in an application to a powered descent problem at Mars.
A Transistor Operations Model for Deep Learning Energy Consumption Scaling
May 30, 2022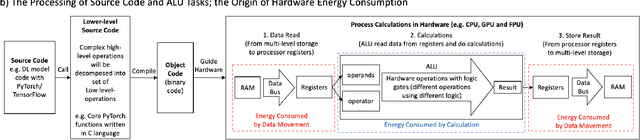
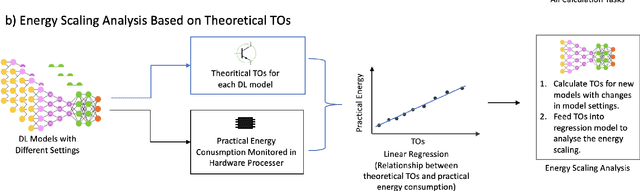
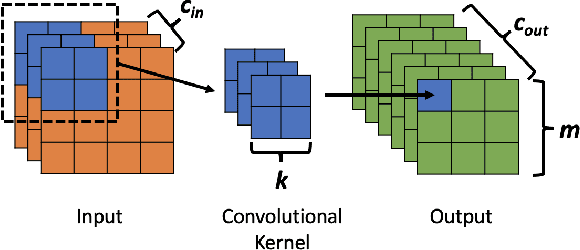
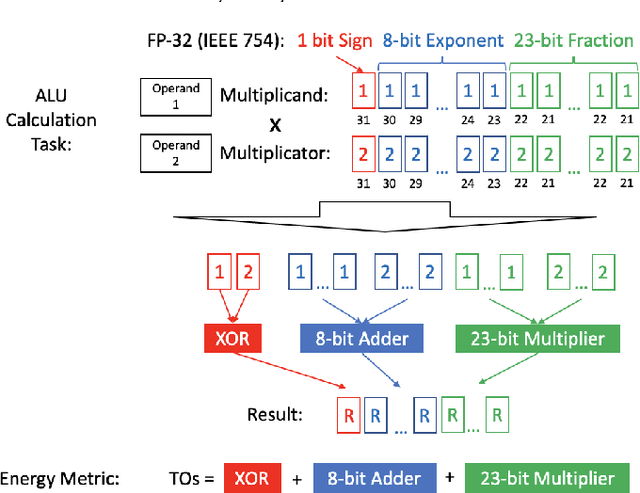
Deep Learning (DL) has transformed the automation of a wide range of industries and finds increasing ubiquity in society. The increasing complexity of DL models and its widespread adoption has led to the energy consumption doubling every 3-4 months. Currently, the relationship between DL model configuration and energy consumption is not well established. Current FLOPs and MACs based methods only consider the linear operations. In this paper, we develop a bottom-level Transistor Operations (TOs) method to expose the role of activation functions and neural network structure in energy consumption scaling with DL model configuration. TOs allows us uncovers the role played by non-linear operations (e.g. division/root operations performed by activation functions and batch normalisation). As such, our proposed TOs model provides developers with a hardware-agnostic index for how energy consumption scales with model settings. To validate our work, we analyse the TOs energy scaling of a feed-forward DNN model set and achieve a 98.2% - 99.97% precision in estimating its energy consumption. We believe this work can be extended to any DL model.
Two-timescale Resource Allocation for Automated Networks in IIoT
Mar 24, 2022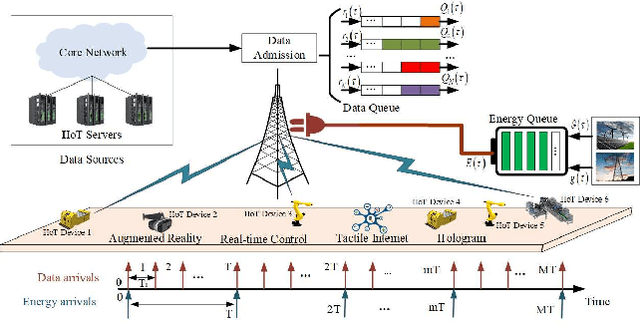
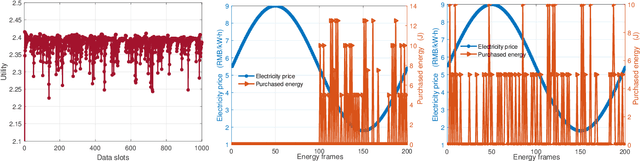
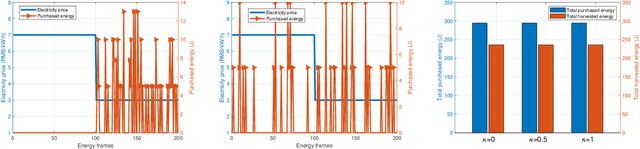
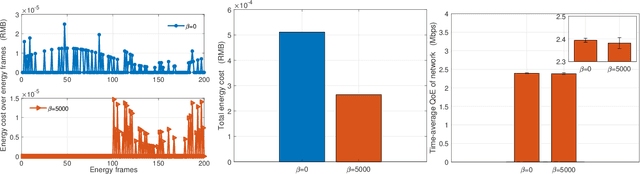
The rapid technological advances of cellular technologies will revolutionize network automation in industrial internet of things (IIoT). In this paper, we investigate the two-timescale resource allocation problem in IIoT networks with hybrid energy supply, where temporal variations of energy harvesting (EH), electricity price, channel state, and data arrival exhibit different granularity. The formulated problem consists of energy management at a large timescale, as well as rate control, channel selection, and power allocation at a small timescale. To address this challenge, we develop an online solution to guarantee bounded performance deviation with only causal information. Specifically, Lyapunov optimization is leveraged to transform the long-term stochastic optimization problem into a series of short-term deterministic optimization problems. Then, a low-complexity rate control algorithm is developed based on alternating direction method of multipliers (ADMM), which accelerates the convergence speed via the decomposition-coordination approach. Next, the joint channel selection and power allocation problem is transformed into a one-to-many matching problem, and solved by the proposed price-based matching with quota restriction. Finally, the proposed algorithm is verified through simulations under various system configurations.
Bayesian Learning Approach to Model Predictive Control
Mar 11, 2022This study presents a Bayesian learning perspective towards model predictive control algorithms. High-level frameworks have been developed separately in the earlier studies on Bayesian learning and sampling-based model predictive control. On one hand, the Bayesian learning rule provides a general framework capable of generating various machine learning algorithms as special instances. On the other hand, the dynamic mirror descent model predictive control framework is capable of diversifying sample-rollout-based control algorithms. However, connections between the two frameworks have still not been fully appreciated in the context of stochastic optimal control. This study combines the Bayesian learning rule point of view into the model predictive control setting by taking inspirations from the view of understanding model predictive controller as an online learner. The selection of posterior class and natural gradient approximation for the variational formulation governs diversification of model predictive control algorithms in the Bayesian learning approach to model predictive control. This alternative viewpoint complements the dynamic mirror descent framework through streamlining the explanation of design choices.
Variational Probabilistic Multi-Hypothesis Tracking
Oct 25, 2021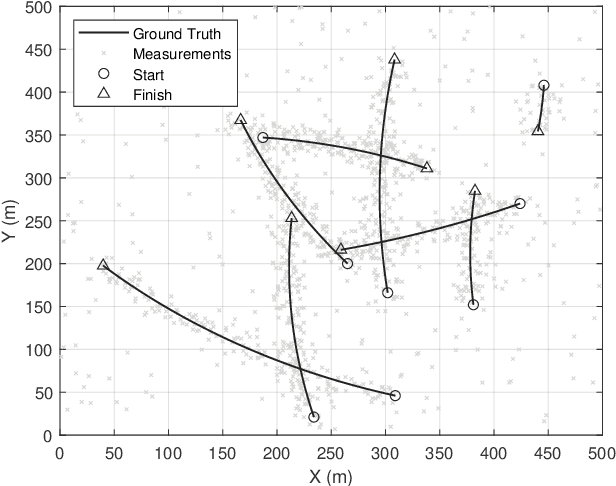

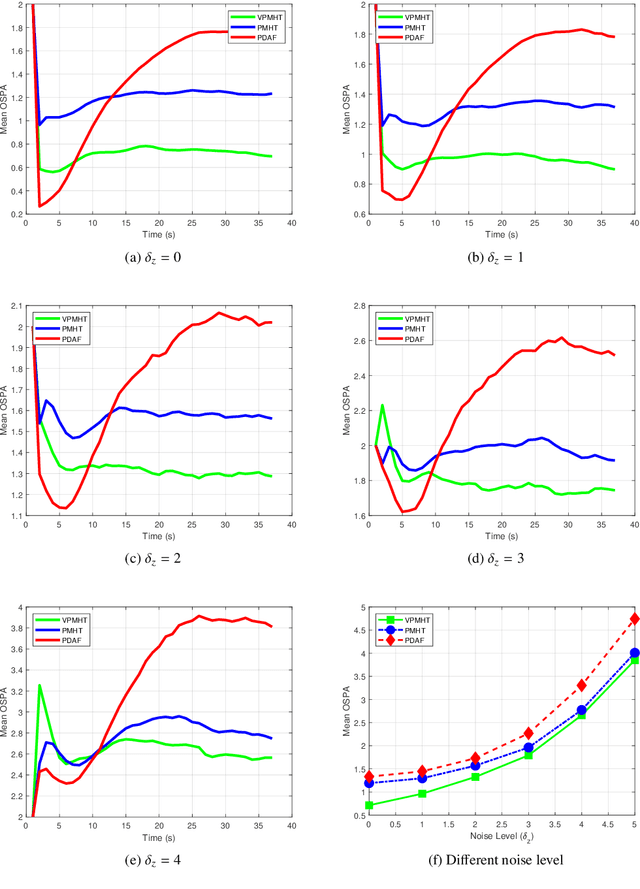
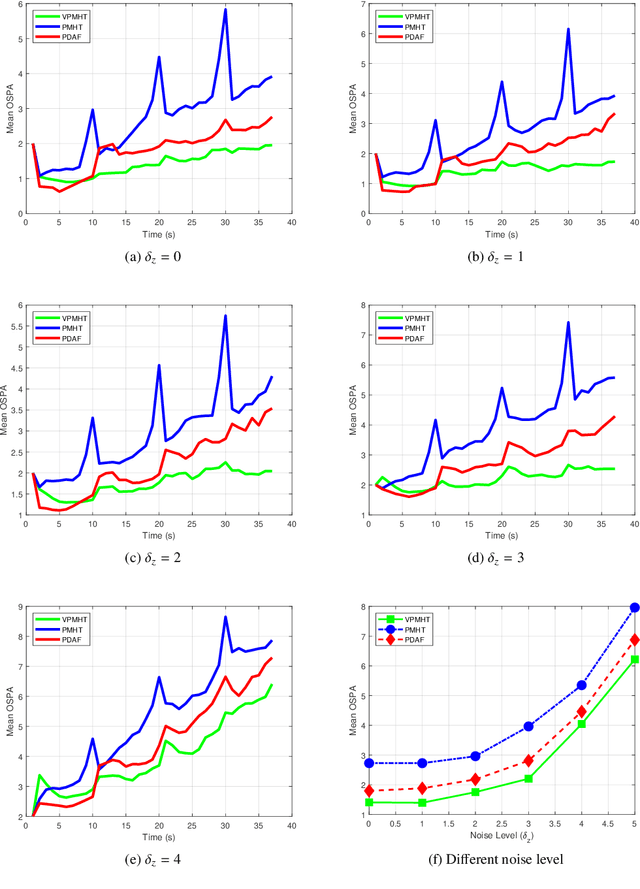
This paper proposes a novel multi-target tracking (MTT) algorithm for scenarios with arbitrary numbers of measurements per target. We propose the variational probabilistic multi-hypothesis tracking (VPMHT) algorithm based on the variational Bayesian expectation-maximisation (VBEM) algorithm to resolve the MTT problem in the classic PMHT algorithm. With the introduction of variational inference, the proposed VPMHT handles track-loss much better than the conventional probabilistic multi-hypothesis tracking (PMHT) while preserving a similar or even better tracking accuracy. Extensive numerical simulations are conducted to demonstrate the effectiveness of the proposed algorithm.