 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Heterogeneous Graph with Factual, Temporal and Logical Knowledge for Question Answering Over Dynamic Contexts
Apr 25, 2020
We study question answering over a dynamic textual environment. Although neural network models achieve impressive accuracy via learning from input-output examples, they rarely leverage various types of knowledge and are generally not interpretable. In this work, we propose a graph-based approach, where a heterogeneous graph is automatically built with factual knowledge of the context, temporal knowledge of the past states, and logical knowledge that combines human-curated knowledge bases and rule bases. We develop a graph neural network over the constructed graph, and train the model in an end-to-end manner. Experimental results on a benchmark dataset show that the injection of various types of knowledge improves a strong neural network baseline. An additional benefit of our approach is that the graph itself naturally serves as a rational behind the decision making.
Inferential Text Generation with Multiple Knowledge Sources and Meta-Learning
Apr 15, 2020
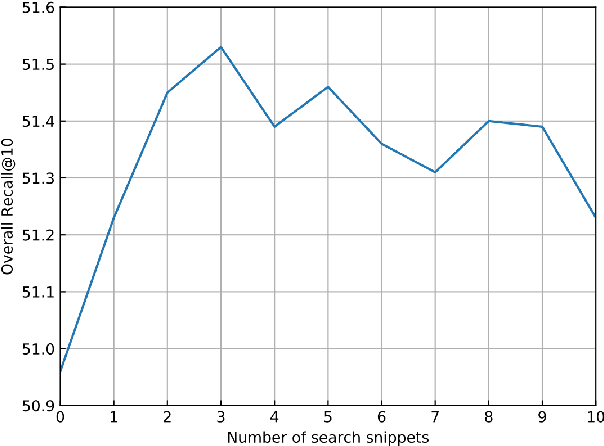
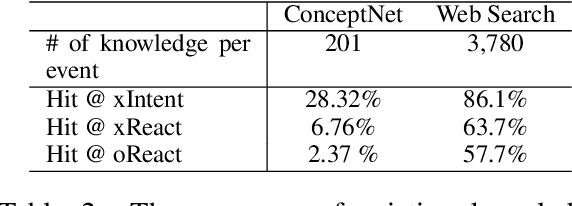
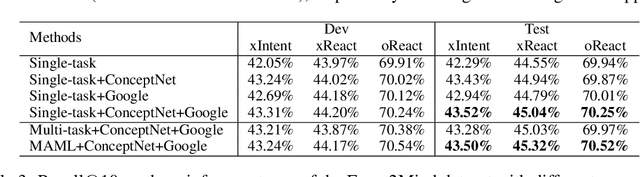
We study the problem of generating inferential texts of events for a variety of commonsense like \textit{if-else} relations. Existing approaches typically use limited evidence from training examples and learn for each relation individually. In this work, we use multiple knowledge sources as fuels for the model. Existing commonsense knowledge bases like ConceptNet are dominated by taxonomic knowledge (e.g., \textit{isA} and \textit{relatedTo} relations), having a limited number of inferential knowledge. We use not only structured commonsense knowledge bases, but also natural language snippets from search-engine results. These sources are incorporated into a generative base model via key-value memory network. In addition, we introduce a meta-learning based multi-task learning algorithm. For each targeted commonsense relation, we regard the learning of examples from other relations as the meta-training process, and the evaluation on examples from the targeted relation as the meta-test process. We conduct experiments on Event2Mind and ATOMIC datasets. Results show that both the integration of multiple knowledge sources and the use of the meta-learning algorithm improve the performance.
Controllable Face Aging
Dec 20, 2019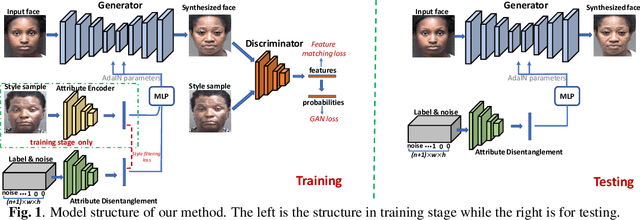
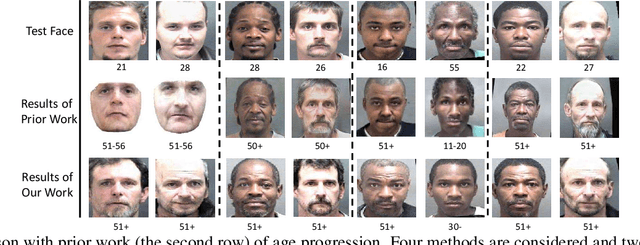
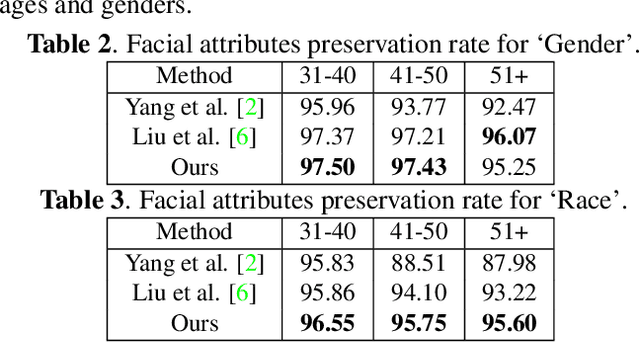
Motivated by the following two observations: 1) people are aging differently under different conditions for changeable facial attributes, e.g., skin color may become darker when working outside, and 2) it needs to keep some unchanged facial attributes during the aging process, e.g., race and gender, we propose a controllable face aging method via attribute disentanglement generative adversarial network. To offer fine control over the synthesized face images, first, an individual embedding of the face is directly learned from an image that contains the desired facial attribute. Second, since the image may contain other unwanted attributes, an attribute disentanglement network is used to separate the individual embedding and learn the common embedding that contains information about the face attribute (e.g., race). With the common embedding, we can manipulate the generated face image with the desired attribute in an explicit manner. Experimental results on two common benchmarks demonstrate that our proposed generator achieves comparable performance on the aging effect with state-of-the-art baselines while gaining more flexibility for attribute control. Code is available at supplementary material.
Gradient Perturbation is Underrated for Differentially Private Convex Optimization
Nov 26, 2019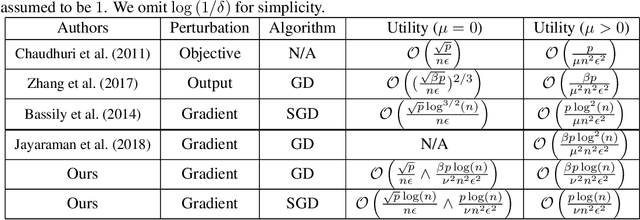
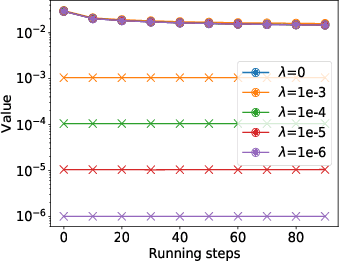
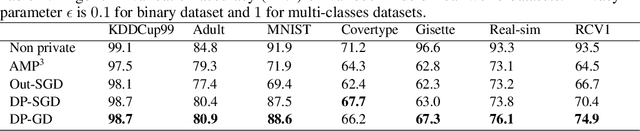
Gradient perturbation, widely used for differentially private optimization, injects noise at every iterative update to guarantee differential privacy. Previous work first determines the noise level that can satisfy the privacy requirement and then analyzes the utility of noisy gradient updates as in non-private case. In this paper, we explore how the privacy noise affects the optimization property. We show that for differentially private convex optimization, the utility guarantee of both DP-GD and DP-SGD is determined by an \emph{expected curvature} rather than the minimum curvature. The \emph{expected curvature} represents the average curvature over the optimization path, which is usually much larger than the minimum curvature and hence can help us achieve a significantly improved utility guarantee. By using the \emph{expected curvature}, our theory justifies the advantage of gradient perturbation over other perturbation methods and closes the gap between theory and practice. Extensive experiments on real world datasets corroborate our theoretical findings.
Modal-aware Features for Multimodal Hashing
Nov 19, 2019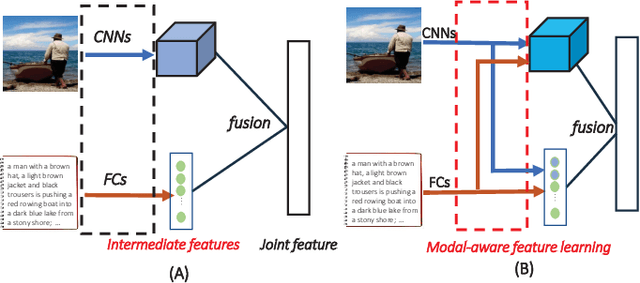
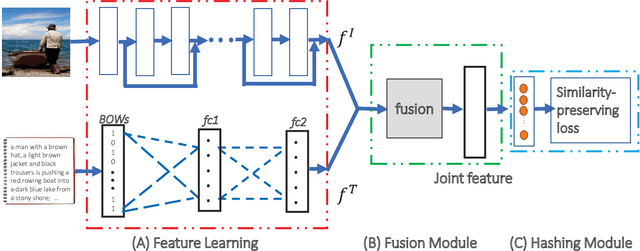
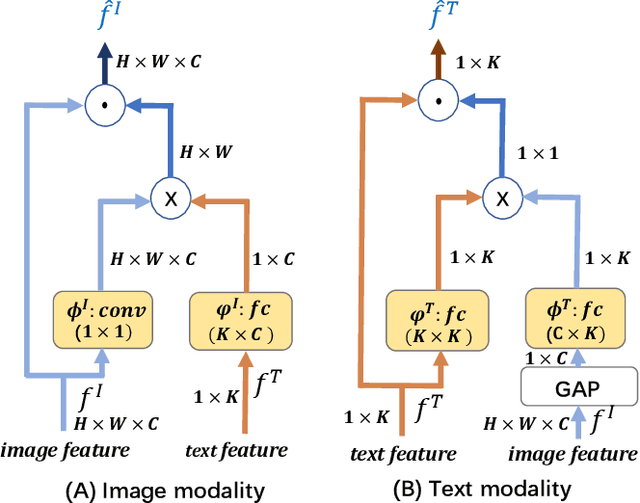
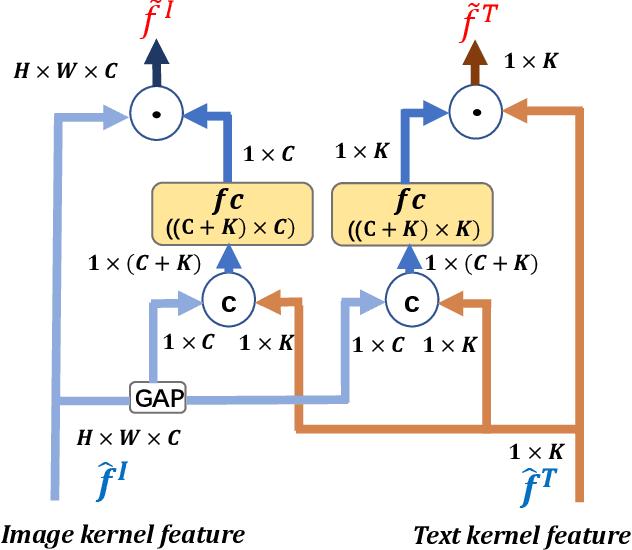
Many retrieval applications can benefit from multiple modalities, e.g., text that contains images on Wikipedia, for which how to represent multimodal data is the critical component. Most deep multimodal learning methods typically involve two steps to construct the joint representations: 1) learning of multiple intermediate features, with each intermediate feature corresponding to a modality, using separate and independent deep models; 2) merging the intermediate features into a joint representation using a fusion strategy. However, in the first step, these intermediate features do not have previous knowledge of each other and cannot fully exploit the information contained in the other modalities. In this paper, we present a modal-aware operation as a generic building block to capture the non-linear dependences among the heterogeneous intermediate features that can learn the underlying correlation structures in other multimodal data as soon as possible. The modal-aware operation consists of a kernel network and an attention network. The kernel network is utilized to learn the non-linear relationships with other modalities. Then, to learn better representations for binary hash codes, we present an attention network that finds the informative regions of these modal-aware features that are favorable for retrieval. Experiments conducted on three public benchmark datasets demonstrate significant improvements in the performance of our method relative to state-of-the-art methods.
Simultaneous Region Localization and Hash Coding for Fine-grained Image Retrieval
Nov 19, 2019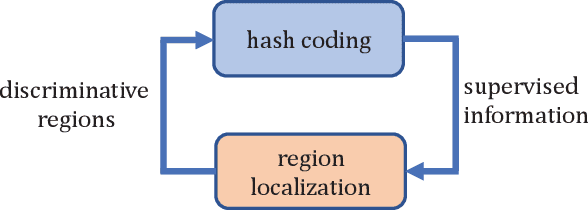
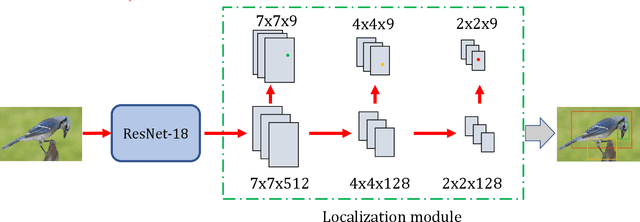
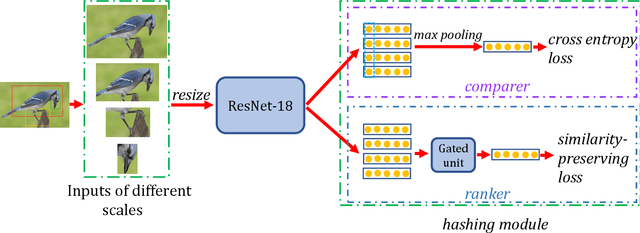
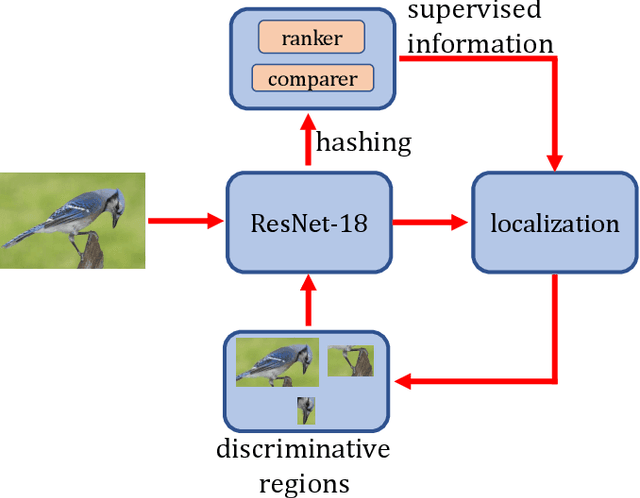
Fine-grained image hashing is a challenging problem due to the difficulties of discriminative region localization and hash code generation. Most existing deep hashing approaches solve the two tasks independently. While these two tasks are correlated and can reinforce each other. In this paper, we propose a deep fine-grained hashing to simultaneously localize the discriminative regions and generate the efficient binary codes. The proposed approach consists of a region localization module and a hash coding module. The region localization module aims to provide informative regions to the hash coding module. The hash coding module aims to generate effective binary codes and give feedback for learning better localizer. Moreover, to better capture subtle differences, multi-scale regions at different layers are learned without the need of bounding-box/part annotations. Extensive experiments are conducted on two public benchmark fine-grained datasets. The results demonstrate significant improvements in the performance of our method relative to other fine-grained hashing algorithms.
Reasoning Over Semantic-Level Graph for Fact Checking
Sep 13, 2019

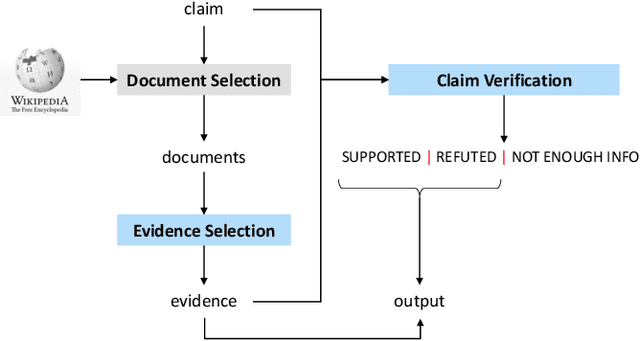
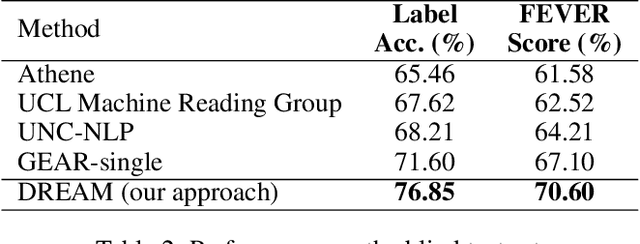
We study fact-checking in this paper, which aims to verify a textual claim given textual evidence (e.g., retrieved sentences from Wikipedia). Existing studies typically either concatenate retrieved sentences as a single string or use feature fusion on the top of features of sentences, while ignoring semantic-level information including participants, location, and temporality of an event occurred in a sentence and relationships among multiple events. Such semantic-level information is crucial for understanding the relational structure of evidence and the deep reasoning procedure over that. In this paper, we address this issue by proposing a graph-based reasoning framework, called the Dynamic REAsoning Machine (DREAM) framework. We first construct a semantic-level graph, where nodes are extracted by semantic role labeling toolkits and are connected by inner- and inter- sentence edges. After having the automatically constructed graph, we use XLNet as the backbone of our approach and propose a graph-based contextual word representation learning module and a graph-based reasoning module to leverage the information of graphs. The first module is designed by considering a claim as a sequence, in which case we use the graph structure to re-define the relative distance of words. On top of this, we propose the second module by considering both the claim and the evidence as graphs and use a graph neural network to capture the semantic relationship at a more abstract level. We conduct experiments on FEVER, a large-scale benchmark dataset for fact-checking. Results show that both of the graph-based modules improve performance. Our system is the state-of-the-art system on the public leaderboard in terms of both accuracy and FEVER score.
Coupling Retrieval and Meta-Learning for Context-Dependent Semantic Parsing
Jun 17, 2019
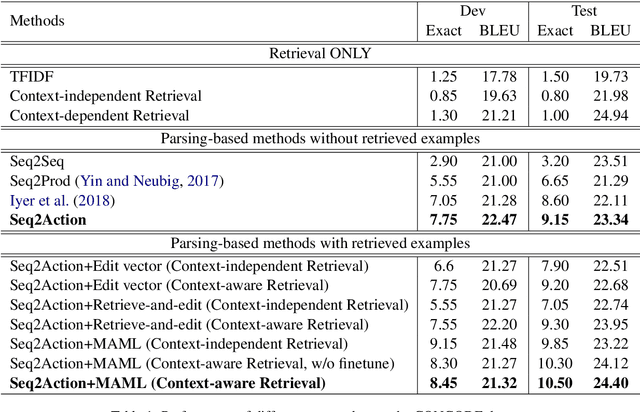
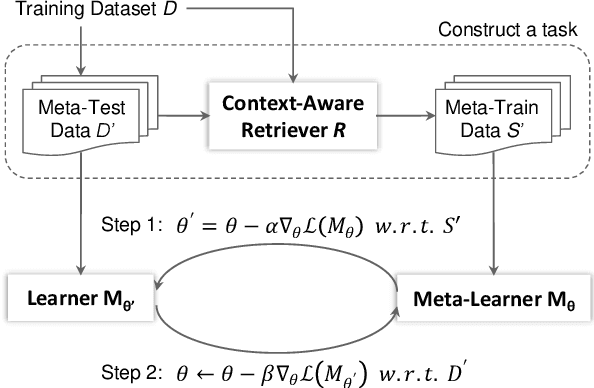
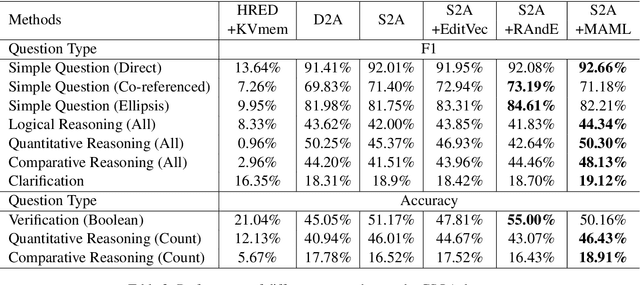
In this paper, we present an approach to incorporate retrieved datapoints as supporting evidence for context-dependent semantic parsing, such as generating source code conditioned on the class environment. Our approach naturally combines a retrieval model and a meta-learner, where the former learns to find similar datapoints from the training data, and the latter considers retrieved datapoints as a pseudo task for fast adaptation. Specifically, our retriever is a context-aware encoder-decoder model with a latent variable which takes context environment into consideration, and our meta-learner learns to utilize retrieved datapoints in a model-agnostic meta-learning paradigm for fast adaptation. We conduct experiments on CONCODE and CSQA datasets, where the context refers to class environment in JAVA codes and conversational history, respectively. We use sequence-to-action model as the base semantic parser, which performs the state-of-the-art accuracy on both datasets. Results show that both the context-aware retriever and the meta-learning strategy improve accuracy, and our approach performs better than retrieve-and-edit baselines.
Fashion Editing with Multi-scale Attention Normalization
Jun 03, 2019
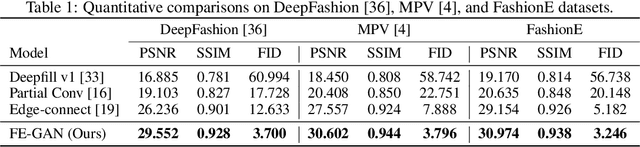
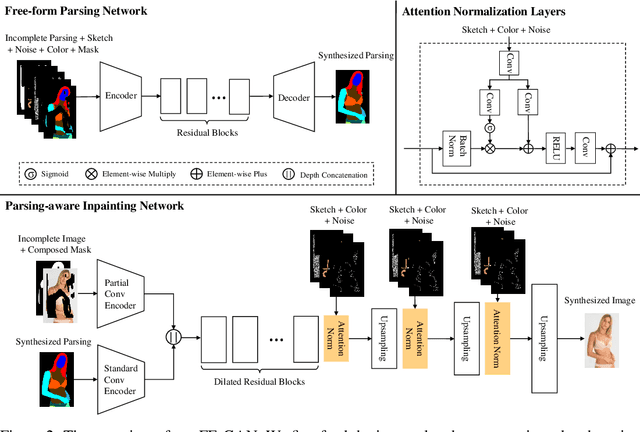

Interactive fashion image manipulation, which enables users to edit images with sketches and color strokes, is an interesting research problem with great application value. Existing works often treat it as a general inpainting task and do not fully leverage the semantic structural information in fashion images. Moreover, they directly utilize conventional convolution and normalization layers to restore the incomplete image, which tends to wash away the sketch and color information. In this paper, we propose a novel Fashion Editing Generative Adversarial Network (FE-GAN), which is capable of manipulating fashion images by free-form sketches and sparse color strokes. FE-GAN consists of two modules: 1) a free-form parsing network that learns to control the human parsing generation by manipulating sketch and color; 2) a parsing-aware inpainting network that renders detailed textures with semantic guidance from the human parsing map. A new attention normalization layer is further applied at multiple scales in the decoder of the inpainting network to enhance the quality of the synthesized image. Extensive experiments on high-resolution fashion image datasets demonstrate that the proposed method significantly outperforms the state-of-the-art methods on image manipulation.
Feature Pyramid Hashing
Apr 04, 2019
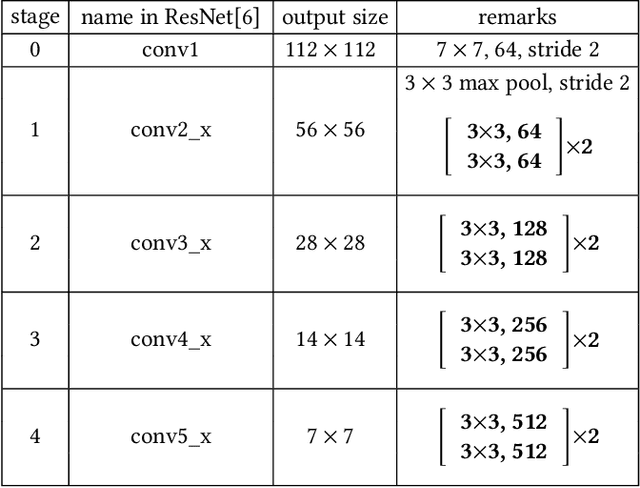
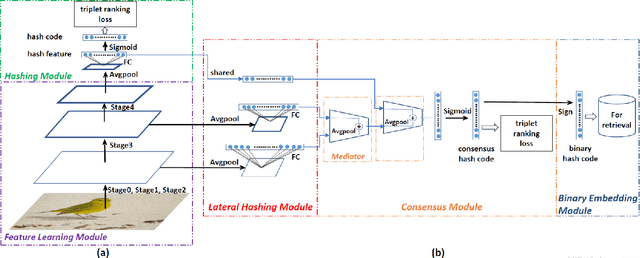
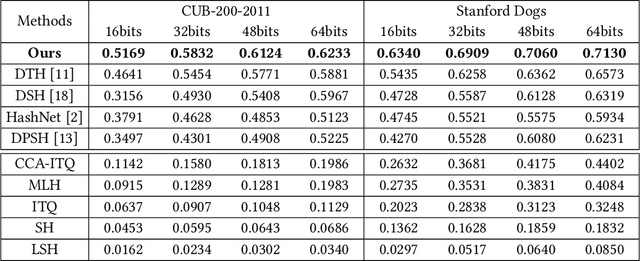
In recent years, deep-networks-based hashing has become a leading approach for large-scale image retrieval. Most deep hashing approaches use the high layer to extract the powerful semantic representations. However, these methods have limited ability for fine-grained image retrieval because the semantic features extracted from the high layer are difficult in capturing the subtle differences. To this end, we propose a novel two-pyramid hashing architecture to learn both the semantic information and the subtle appearance details for fine-grained image search. Inspired by the feature pyramids of convolutional neural network, a vertical pyramid is proposed to capture the high-layer features and a horizontal pyramid combines multiple low-layer features with structural information to capture the subtle differences. To fuse the low-level features, a novel combination strategy, called consensus fusion, is proposed to capture all subtle information from several low-layers for finer retrieval. Extensive evaluation on two fine-grained datasets CUB-200-2011 and Stanford Dogs demonstrate that the proposed method achieves significant performance compared with the state-of-art baselines.