 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Policy Hashing Network with Listwise Supervision
Paper and Code
Apr 03, 2019
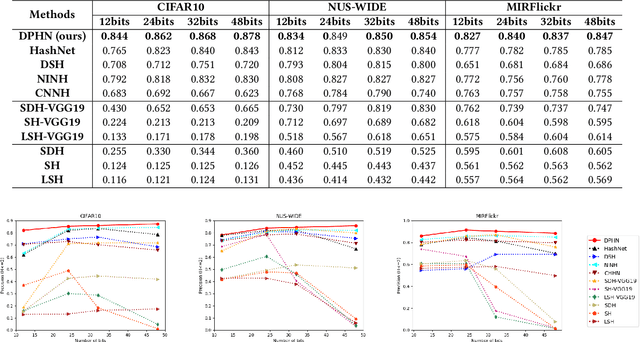
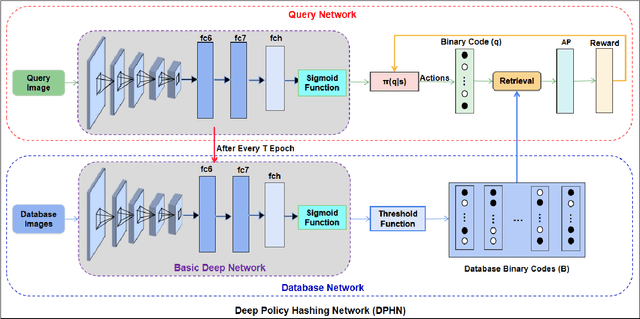
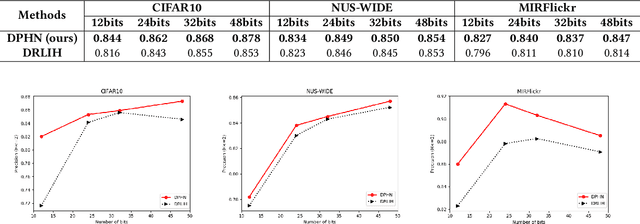
Deep-networks-based hashing has become a leading approach for large-scale image retrieval, which learns a similarity-preserving network to map similar images to nearby hash codes. The pairwise and triplet losses are two widely used similarity preserving manners for deep hashing. These manners ignore the fact that hashing is a prediction task on the list of binary codes. However, learning deep hashing with listwise supervision is challenging in 1) how to obtain the rank list of whole training set when the batch size of the deep network is always small and 2) how to utilize the listwise supervision. In this paper, we present a novel deep policy hashing architecture with two systems are learned in parallel: a query network and a shared and slowly changing database network. The following three steps are repeated until convergence: 1) the database network encodes all training samples into binary codes to obtain a whole rank list, 2) the query network is trained based on policy learning to maximize a reward that indicates the performance of the whole ranking list of binary codes, e.g., mean average precision (MAP), and 3) the database network is updated as the query network. Extensive evaluations on several benchmark datasets show that the proposed method brings substantial improvements over state-of-the-art hashing methods.