 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniXcoder: Unified Cross-Modal Pre-training for Code Representation
Mar 08, 2022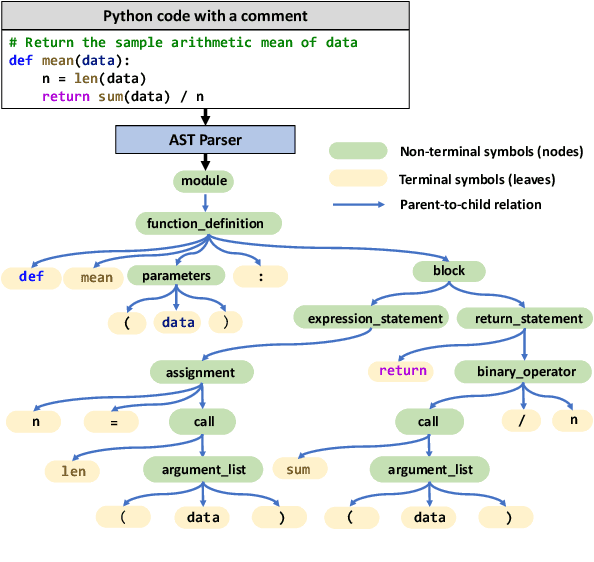
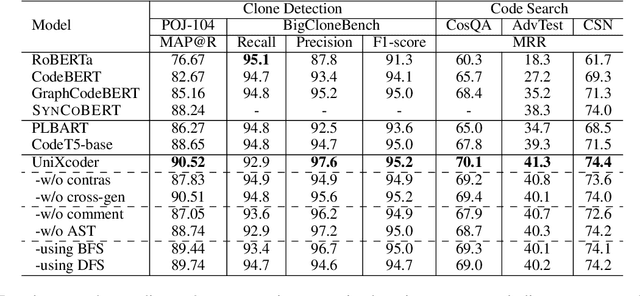
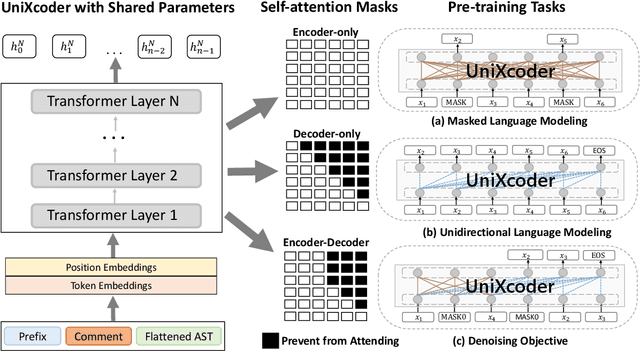
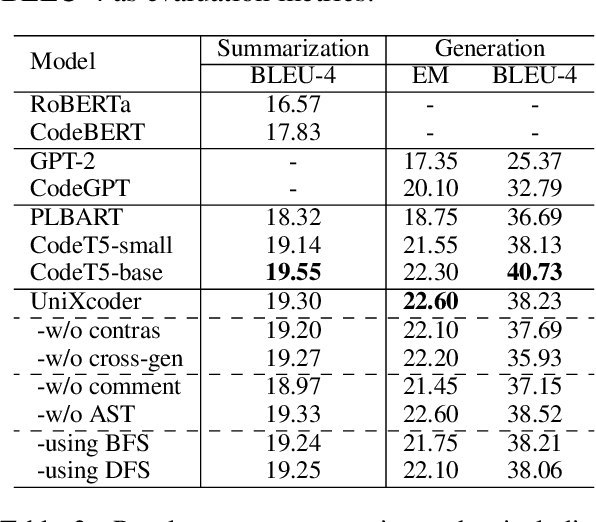
Pre-trained models for programming languages have recently demonstrated great success on code intelligence. To support both code-related understanding and generation tasks, recent works attempt to pre-train unified encoder-decoder models. However, such encoder-decoder framework is sub-optimal for auto-regressive tasks, especially code completion that requires a decoder-only manner for efficient inference. In this paper, we present UniXcoder, a unified cross-modal pre-trained model for programming language. The model utilizes mask attention matrices with prefix adapters to control the behavior of the model and leverages cross-modal contents like AST and code comment to enhance code representation. To encode AST that is represented as a tree in parallel, we propose a one-to-one mapping method to transform AST in a sequence structure that retains all structural information from the tree. Furthermore, we propose to utilize multi-modal contents to learn representation of code fragment with contrastive learning, and then align representations among programming languages using a cross-modal generation task. We evaluate UniXcoder on five code-related tasks over nine datasets. To further evaluate the performance of code fragment representation, we also construct a dataset for a new task, called zero-shot code-to-code search. Results show that our model achieves state-of-the-art performance on most tasks and analysis reveals that comment and AST can both enhance UniXcoder.
Reasoning over Hybrid Chain for Table-and-Text Open Domain QA
Jan 15, 2022
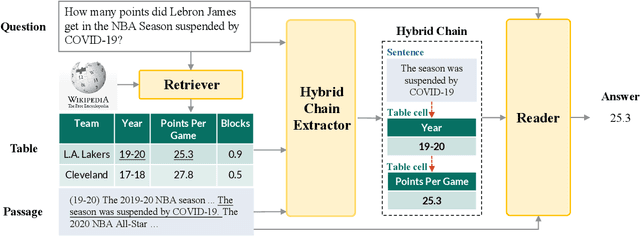
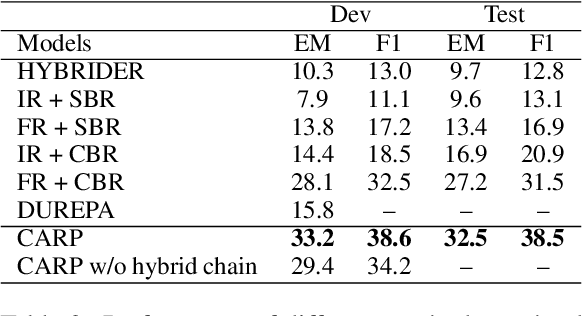
Tabular and textual question answering requires systems to perform reasoning over heterogeneous information, considering table structure, and the connections among table and text. In this paper, we propose a ChAin-centric Reasoning and Pre-training framework (CARP). CARP utilizes hybrid chain to model the explicit intermediate reasoning process across table and text for question answering. We also propose a novel chain-centric pre-training method, to enhance the pre-trained model in identifying the cross-modality reasoning process and alleviating the data sparsity problem. This method constructs the large-scale reasoning corpus by synthesizing pseudo heterogeneous reasoning paths from Wikipedia and generating corresponding questions. We evaluate our system on OTT-QA, a large-scale table-and-text open-domain question answering benchmark, and our system achieves the state-of-the-art performance. Further analyses illustrate that the explicit hybrid chain offers substantial performance improvement and interpretablity of the intermediate reasoning process, and the chain-centric pre-training boosts the performance on the chain extraction.
ViT2Hash: Unsupervised Information-Preserving Hashing
Jan 14, 2022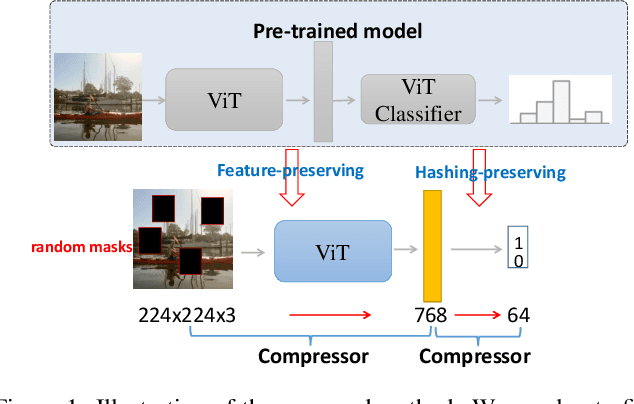
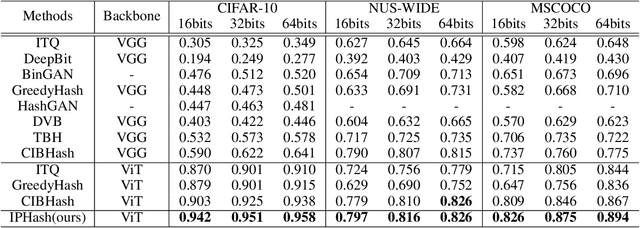
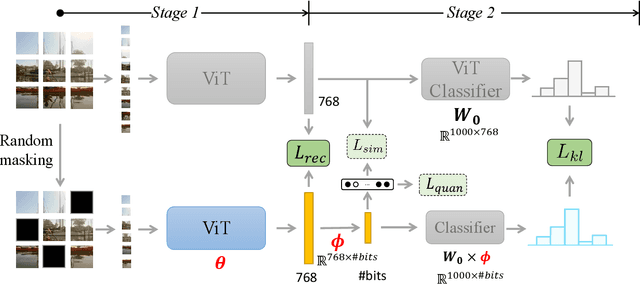
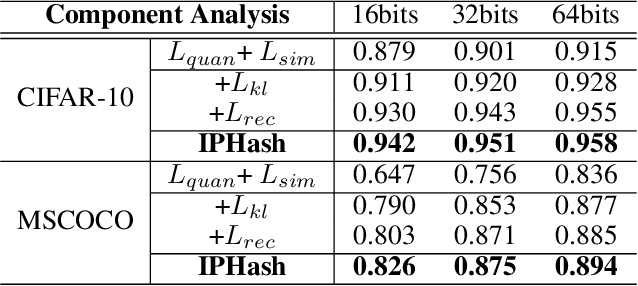
Unsupervised image hashing, which maps images into binary codes without supervision, is a compressor with a high compression rate. Hence, how to preserving meaningful information of the original data is a critical problem. Inspired by the large-scale vision pre-training model, known as ViT, which has shown significant progress for learning visual representations, in this paper, we propose a simple information-preserving compressor to finetune the ViT model for the target unsupervised hashing task. Specifically, from pixels to continuous features, we first propose a feature-preserving module, using the corrupted image as input to reconstruct the original feature from the pre-trained ViT model and the complete image, so that the feature extractor can focus on preserving the meaningful information of original data. Secondly, from continuous features to hash codes, we propose a hashing-preserving module, which aims to keep the semantic information from the pre-trained ViT model by using the proposed Kullback-Leibler divergence loss. Besides, the quantization loss and the similarity loss are added to minimize the quantization error. Our method is very simple and achieves a significantly higher degree of MAP on three benchmark image datasets.
SHGNN: Structure-Aware Heterogeneous Graph Neural Network
Dec 14, 2021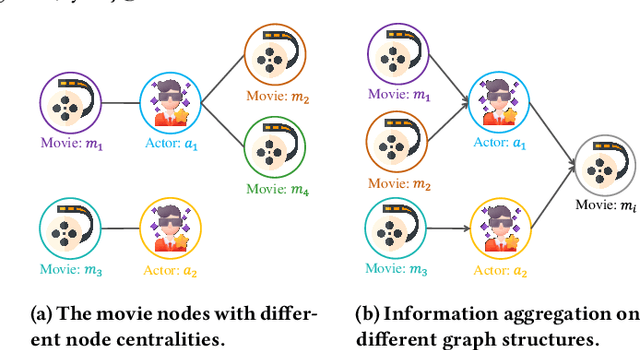
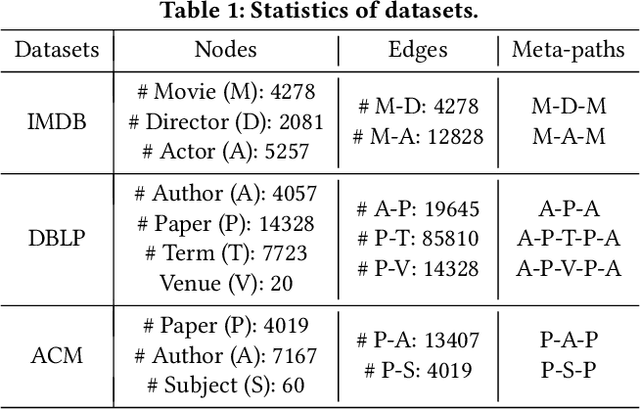
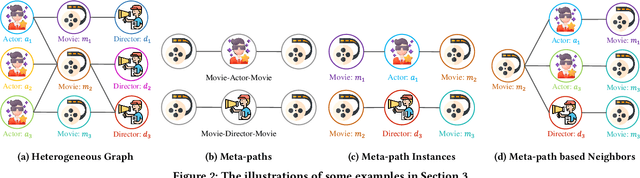
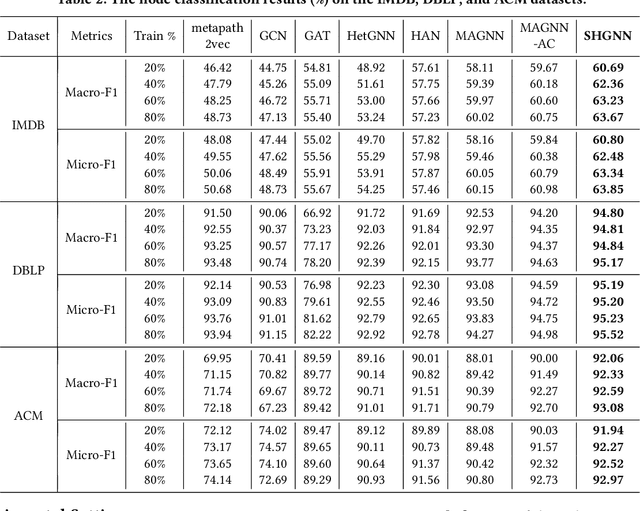
Many real-world graphs (networks) are heterogeneous with different types of nodes and edges. Heterogeneous graph embedding, aiming at learning the low-dimensional node representations of a heterogeneous graph, is vital for various downstream applications. Many meta-path based embedding methods have been proposed to learn the semantic information of heterogeneous graphs in recent years. However, most of the existing techniques overlook the graph structure information when learning the heterogeneous graph embeddings. This paper proposes a novel Structure-Aware Heterogeneous Graph Neural Network (SHGNN) to address the above limitations. In detail, we first utilize a feature propagation module to capture the local structure information of intermediate nodes in the meta-path. Next, we use a tree-attention aggregator to incorporate the graph structure information into the aggregation module on the meta-path. Finally, we leverage a meta-path aggregator to fuse the information aggregated from different meta-paths. We conducted experiments on node classification and clustering tasks and achieved state-of-the-art results on the benchmark datasets, which shows the effectiveness of our proposed method.
KGE-CL: Contrastive Learning of Knowledge Graph Embeddings
Dec 09, 2021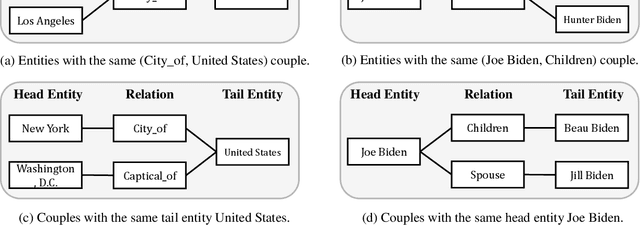

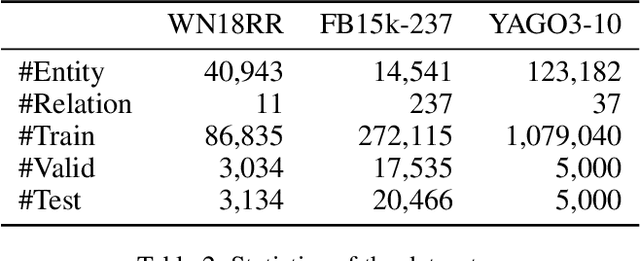
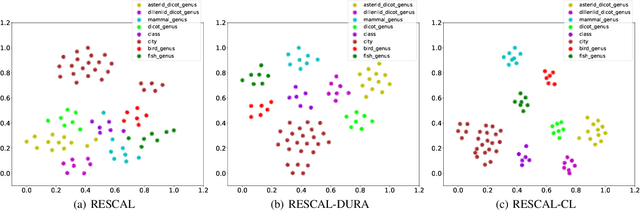
Learning the embeddings of knowledge graphs is vital in artificial intelligence, and can benefit various downstream applications, such as recommendation and question answering. In recent years, many research efforts have been proposed for knowledge graph embedding. However, most previous knowledge graph embedding methods ignore the semantic similarity between the related entities and entity-relation couples in different triples since they separately optimize each triple with the scoring function. To address this problem, we propose a simple yet efficient contrastive learning framework for knowledge graph embeddings, which can shorten the semantic distance of the related entities and entity-relation couples in different triples and thus improve the expressiveness of knowledge graph embeddings. We evaluate our proposed method on three standard knowledge graph benchmarks. It is noteworthy that our method can yield some new state-of-the-art results, achieving 51.2% MRR, 46.8% Hits@1 on the WN18RR dataset, and 59.1% MRR, 51.8% Hits@1 on the YAGO3-10 dataset.
Indiscriminate Poisoning Attacks Are Shortcuts
Nov 01, 2021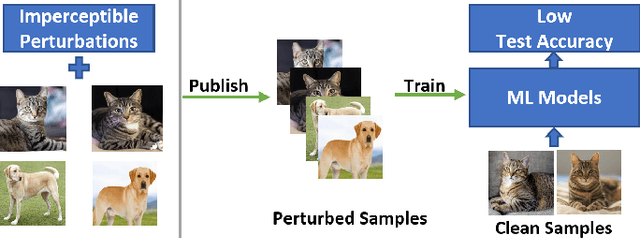
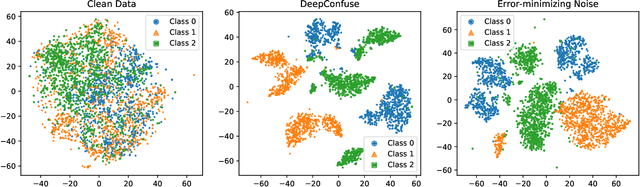
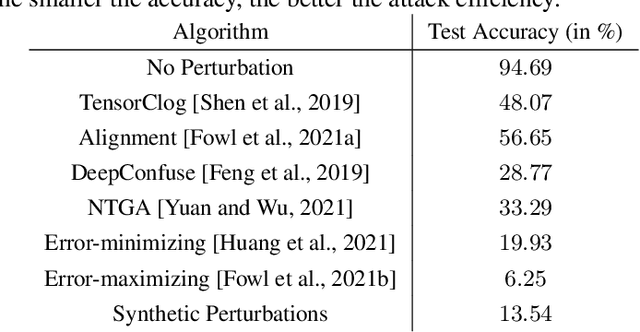

Indiscriminate data poisoning attacks, which add imperceptible perturbations to training data to maximize the test error of trained models, have become a trendy topic because they are thought to be capable of preventing unauthorized use of data. In this work, we investigate why these perturbations work in principle. We find that the perturbations of advanced poisoning attacks are almost \textbf{linear separable} when assigned with the target labels of the corresponding samples, which hence can work as \emph{shortcuts} for the learning objective. This important population property has not been unveiled before. Moreover, we further verify that linear separability is indeed the workhorse for poisoning attacks. We synthesize linear separable data as perturbations and show that such synthetic perturbations are as powerful as the deliberately crafted attacks. Our finding suggests that the \emph{shortcut learning} problem is more serious than previously believed as deep learning heavily relies on shortcuts even if they are of an imperceptible scale and mixed together with the normal features. This finding also suggests that pre-trained feature extractors would disable these poisoning attacks effectively.
HIST: A Graph-based Framework for Stock Trend Forecasting via Mining Concept-Oriented Shared Information
Oct 26, 2021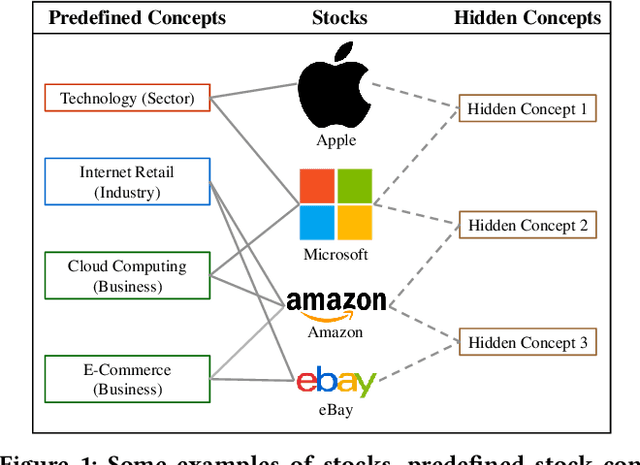
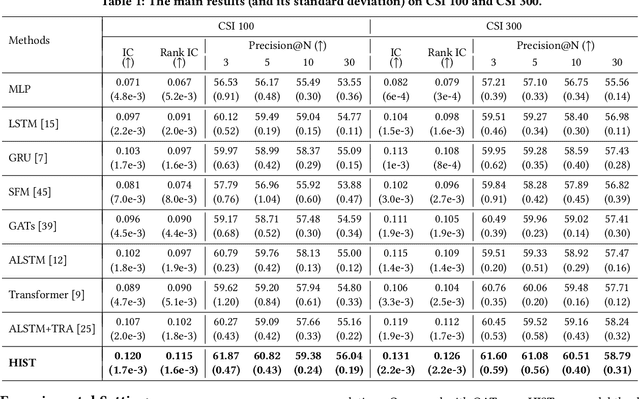
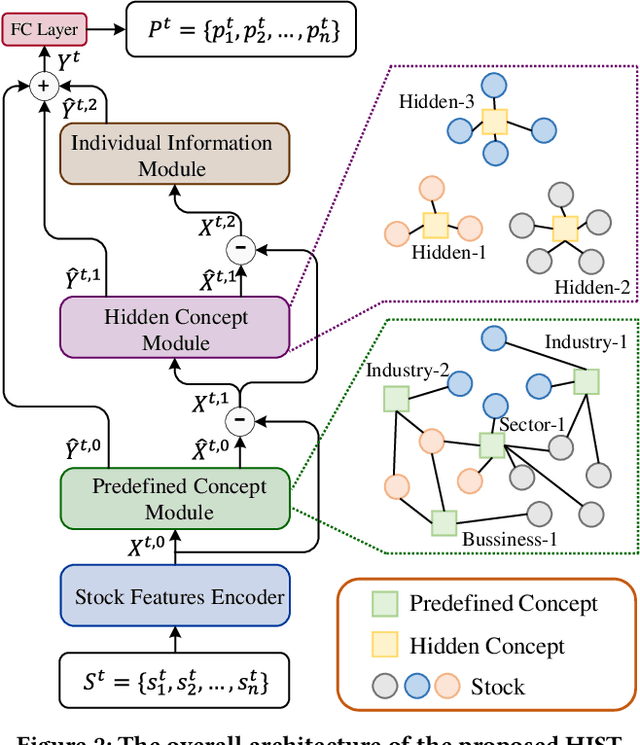
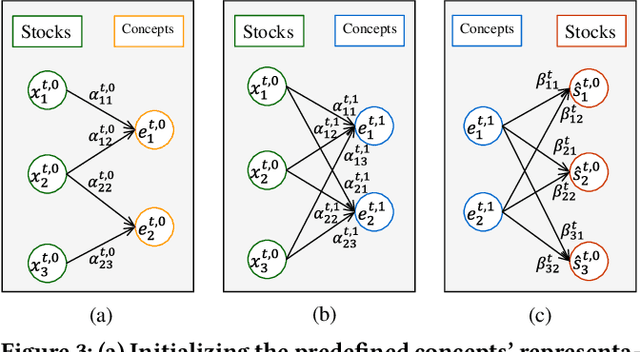
Stock trend forecasting, which forecasts stock prices' future trends, plays an essential role in investment. The stocks in a market can share information so that their stock prices are highly correlated. Several methods were recently proposed to mine the shared information through stock concepts (e.g., technology, Internet Retail) extracted from the Web to improve the forecasting results. However, previous work assumes the connections between stocks and concepts are stationary, and neglects the dynamic relevance between stocks and concepts, limiting the forecasting results. Moreover, existing methods overlook the invaluable shared information carried by hidden concepts, which measure stocks' commonness beyond the manually defined stock concepts. To overcome the shortcomings of previous work, we proposed a novel stock trend forecasting framework that can adequately mine the concept-oriented shared information from predefined concepts and hidden concepts. The proposed framework simultaneously utilize the stock's shared information and individual information to improve the stock trend forecasting performance. Experimental results on the real-world tasks demonstrate the efficiency of our framework on stock trend forecasting. The investment simulation shows that our framework can achieve a higher investment return than the baselines.
Improved Drug-target Interaction Prediction with Intermolecular Graph Transformer
Oct 15, 2021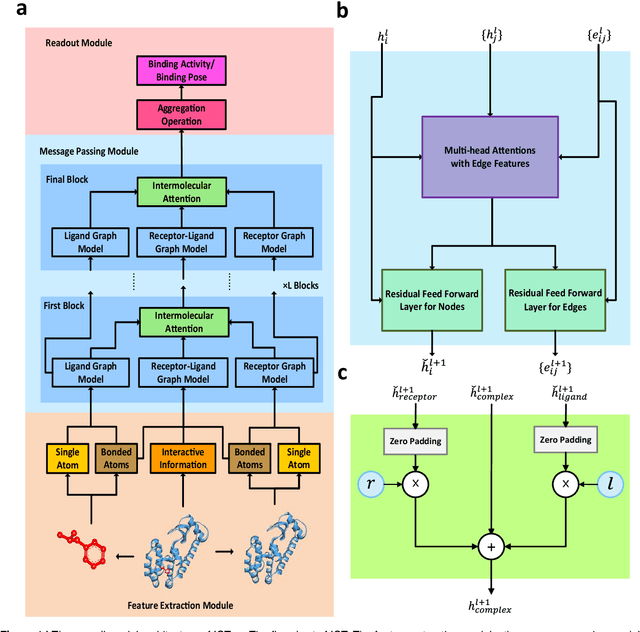
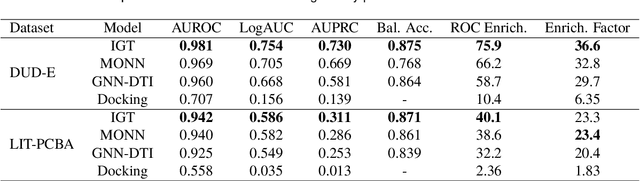
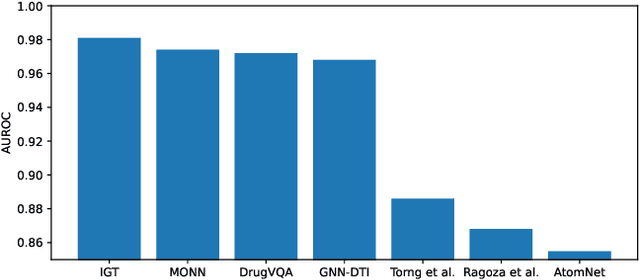

The identification of active binding drugs for target proteins (termed as drug-target interaction prediction) is the key challenge in virtual screening, which plays an essential role in drug discovery. Although recent deep learning-based approaches achieved better performance than molecular docking, existing models often neglect certain aspects of the intermolecular information, hindering the performance of prediction. We recognize this problem and propose a novel approach named Intermolecular Graph Transformer (IGT) that employs a dedicated attention mechanism to model intermolecular information with a three-way Transformer-based architecture. IGT outperforms state-of-the-art approaches by 9.1% and 20.5% over the second best for binding activity and binding pose prediction respectively, and shows superior generalization ability to unseen receptor proteins. Furthermore, IGT exhibits promising drug screening ability against SARS-CoV-2 by identifying 83.1% active drugs that have been validated by wet-lab experiments with near-native predicted binding poses.
Instance-wise Graph-based Framework for Multivariate Time Series Forecasting
Sep 14, 2021
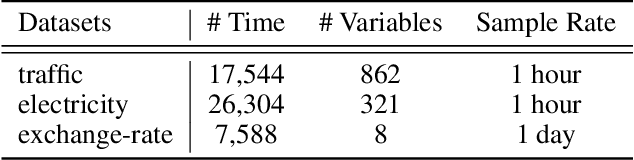
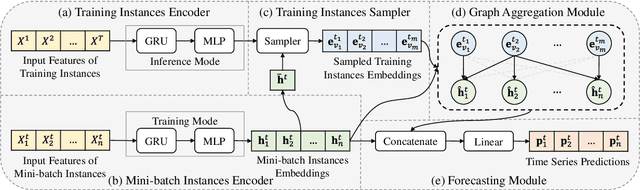
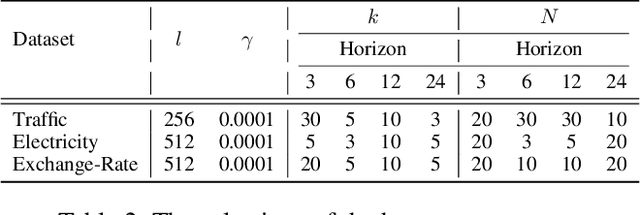
The multivariate time series forecasting has attracted more and more attention because of its vital role in different fields in the real world, such as finance, traffic, and weather. In recent years, many research efforts have been proposed for forecasting multivariate time series. Although some previous work considers the interdependencies among different variables in the same timestamp, existing work overlooks the inter-connections between different variables at different time stamps. In this paper, we propose a simple yet efficient instance-wise graph-based framework to utilize the inter-dependencies of different variables at different time stamps for multivariate time series forecasting. The key idea of our framework is aggregating information from the historical time series of different variables to the current time series that we need to forecast. We conduct experiments on the Traffic, Electricity, and Exchange-Rate multivariate time series datasets. The results show that our proposed model outperforms the state-of-the-art baseline methods.
Large Scale Private Learning via Low-rank Reparametrization
Jun 28, 2021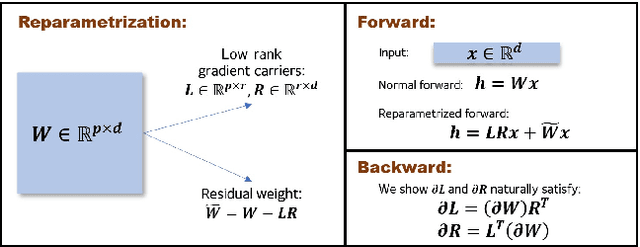

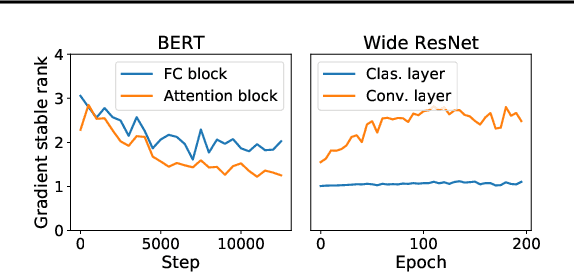
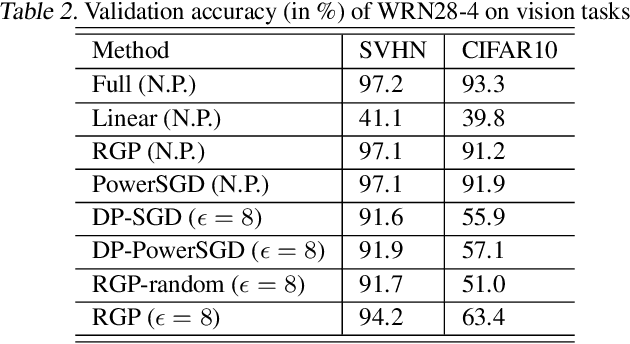
We propose a reparametrization scheme to address the challenges of applying differentially private SGD on large neural networks, which are 1) the huge memory cost of storing individual gradients, 2) the added noise suffering notorious dimensional dependence. Specifically, we reparametrize each weight matrix with two \emph{gradient-carrier} matrices of small dimension and a \emph{residual weight} matrix. We argue that such reparametrization keeps the forward/backward process unchanged while enabling us to compute the projected gradient without computing the gradient itself. To learn with differential privacy, we design \emph{reparametrized gradient perturbation (RGP)} that perturbs the gradients on gradient-carrier matrices and reconstructs an update for the original weight from the noisy gradients. Importantly, we use historical updates to find the gradient-carrier matrices, whose optimality is rigorously justified under linear regression and empirically verified with deep learning tasks. RGP significantly reduces the memory cost and improves the utility. For example, we are the first able to apply differential privacy on the BERT model and achieve an average accuracy of $83.9\%$ on four downstream tasks with $\epsilon=8$, which is within $5\%$ loss compared to the non-private baseline but enjoys much lower privacy leakage risk.