 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comprehensive Survey on Trustworthiness in Reasoning with Large Language Models
Sep 04, 2025The development of Long-CoT reasoning has advanced LLM performance across various tasks, including language understanding, complex problem solving, and code generation. This paradigm enables models to generate intermediate reasoning steps, thereby improving both accuracy and interpretability. However, despite these advancements, a comprehensive understanding of how CoT-based reasoning affects the trustworthiness of language models remains underdeveloped. In this paper, we survey recent work on reasoning models and CoT techniques, focusing on five core dimensions of trustworthy reasoning: truthfulness, safety, robustness, fairness, and privacy. For each aspect, we provide a clear and structured overview of recent studies in chronological order, along with detailed analyses of their methodologies, findings, and limitations. Future research directions are also appended at the end for reference and discussion. Overall, while reasoning techniques hold promise for enhancing model trustworthiness through hallucination mitigation, harmful content detection, and robustness improvement, cutting-edge reasoning models themselves often suffer from comparable or even greater vulnerabilities in safety, robustness, and privacy. By synthesizing these insights, we hope this work serves as a valuable and timely resource for the AI safety community to stay informed on the latest progress in reasoning trustworthiness. A full list of related papers can be found at \href{https://github.com/ybwang119/Awesome-reasoning-safety}{https://github.com/ybwang119/Awesome-reasoning-safety}.
ReaLM: Reflection-Enhanced Autonomous Reasoning with Small Language Models
Aug 17, 2025Small Language Models (SLMs) are a cost-effective alternative to Large Language Models (LLMs), but often struggle with complex reasoning due to their limited capacity and a tendency to produce mistakes or inconsistent answers during multi-step reasoning. Existing efforts have improved SLM performance, but typically at the cost of one or more of three key aspects: (1) reasoning capability, due to biased supervision that filters out negative reasoning paths and limits learning from errors; (2) autonomy, due to over-reliance on externally generated reasoning signals; and (3) generalization, which suffers when models overfit to teacher-specific patterns. In this paper, we introduce ReaLM, a reinforcement learning framework for robust and self-sufficient reasoning in vertical domains. To enhance reasoning capability, we propose Multi-Route Process Verification (MRPV), which contrasts both positive and negative reasoning paths to extract decisive patterns. To reduce reliance on external guidance and improve autonomy, we introduce Enabling Autonomy via Asymptotic Induction (EAAI), a training strategy that gradually fades external signals. To improve generalization, we apply guided chain-of-thought distillation to encode domain-specific rules and expert knowledge into SLM parameters, making them part of what the model has learned. Extensive experiments on both vertical and general reasoning tasks demonstrate that ReaLM significantly improves SLM performance across aspects (1)-(3) above.
Towards Comprehensible Recommendation with Large Language Model Fine-tuning
Aug 11, 2025Recommender systems have become increasingly ubiquitous in daily life. While traditional recommendation approaches primarily rely on ID-based representations or item-side content features, they often fall short in capturing the underlying semantics aligned with user preferences (e.g., recommendation reasons for items), leading to a semantic-collaborative gap. Recently emerged LLM-based feature extraction approaches also face a key challenge: how to ensure that LLMs possess recommendation-aligned reasoning capabilities and can generate accurate, personalized reasons to mitigate the semantic-collaborative gap. To address these issues, we propose a novel Content Understanding from a Collaborative Perspective framework (CURec), which generates collaborative-aligned content features for more comprehensive recommendations. \method first aligns the LLM with recommendation objectives through pretraining, equipping it with instruction-following and chain-of-thought reasoning capabilities. Next, we design a reward model inspired by traditional recommendation architectures to evaluate the quality of the recommendation reasons generated by the LLM. Finally, using the reward signals, CURec fine-tunes the LLM through RL and corrects the generated reasons to ensure their accuracy. The corrected reasons are then integrated into a downstream recommender model to enhance comprehensibility and recommendation performance. Extensive experiments on public benchmarks demonstrate the superiority of CURec over existing methods.
Adapting Vision-Language Models Without Labels: A Comprehensive Survey
Aug 07, 2025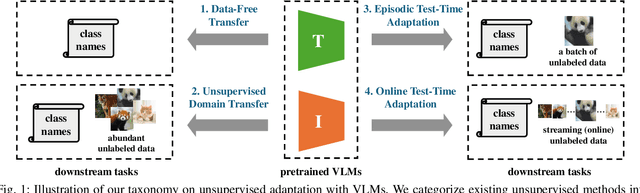
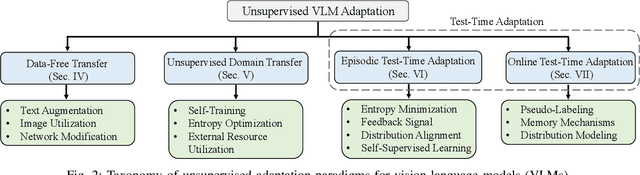
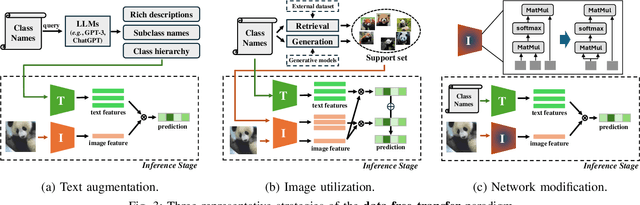
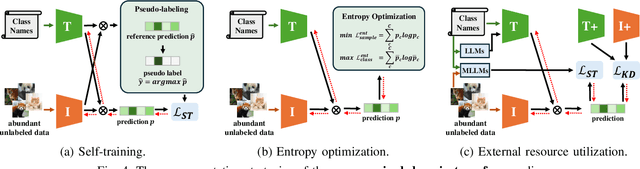
Vision-Language Models (VLMs) have demonstrated remarkable generalization capabilities across a wide range of tasks. However, their performance often remains suboptimal when directly applied to specific downstream scenarios without task-specific adaptation. To enhance their utility while preserving data efficiency, recent research has increasingly focused on unsupervised adaptation methods that do not rely on labeled data. Despite the growing interest in this area, there remains a lack of a unified, task-oriented survey dedicated to unsupervised VLM adaptation. To bridge this gap, we present a comprehensive and structured overview of the field. We propose a taxonomy based on the availability and nature of unlabeled visual data, categorizing existing approaches into four key paradigms: Data-Free Transfer (no data), Unsupervised Domain Transfer (abundant data), Episodic Test-Time Adaptation (batch data), and Online Test-Time Adaptation (streaming data). Within this framework, we analyze core methodologies and adaptation strategies associated with each paradigm, aiming to establish a systematic understanding of the field. Additionally, we review representative benchmarks across diverse applications and highlight open challenges and promising directions for future research. An actively maintained repository of relevant literature is available at https://github.com/tim-learn/Awesome-LabelFree-VLMs.
Harmonizing and Merging Source Models for CLIP-based Domain Generalization
Jun 11, 2025CLIP-based domain generalization aims to improve model generalization to unseen domains by leveraging the powerful zero-shot classification capabilities of CLIP and multiple source datasets. Existing methods typically train a single model across multiple source domains to capture domain-shared information. However, this paradigm inherently suffers from two types of conflicts: 1) sample conflicts, arising from noisy samples and extreme domain shifts among sources; and 2) optimization conflicts, stemming from competition and trade-offs during multi-source training. Both hinder the generalization and lead to suboptimal solutions. Recent studies have shown that model merging can effectively mitigate the competition of multi-objective optimization and improve generalization performance. Inspired by these findings, we propose Harmonizing and Merging (HAM), a novel source model merging framework for CLIP-based domain generalization. During the training process of the source models, HAM enriches the source samples without conflicting samples, and harmonizes the update directions of all models. Then, a redundancy-aware historical model merging method is introduced to effectively integrate knowledge across all source models. HAM comprehensively consolidates source domain information while enabling mutual enhancement among source models, ultimately yielding a final model with optimal generalization capabilities. Extensive experiments on five widely used benchmark datasets demonstrate the effectiveness of our approach, achieving state-of-the-art performance.
To Trust Or Not To Trust Your Vision-Language Model's Prediction
May 29, 2025Vision-Language Models (VLMs) have demonstrated strong capabilities in aligning visual and textual modalities, enabling a wide range of applications in multimodal understanding and generation. While they excel in zero-shot and transfer learning scenarios, VLMs remain susceptible to misclassification, often yielding confident yet incorrect predictions. This limitation poses a significant risk in safety-critical domains, where erroneous predictions can lead to severe consequences. In this work, we introduce TrustVLM, a training-free framework designed to address the critical challenge of estimating when VLM's predictions can be trusted. Motivated by the observed modality gap in VLMs and the insight that certain concepts are more distinctly represented in the image embedding space, we propose a novel confidence-scoring function that leverages this space to improve misclassification detection. We rigorously evaluate our approach across 17 diverse datasets, employing 4 architectures and 2 VLMs, and demonstrate state-of-the-art performance, with improvements of up to 51.87% in AURC, 9.14% in AUROC, and 32.42% in FPR95 compared to existing baselines. By improving the reliability of the model without requiring retraining, TrustVLM paves the way for safer deployment of VLMs in real-world applications. The code will be available at https://github.com/EPFL-IMOS/TrustVLM.
Test-Time Immunization: A Universal Defense Framework Against Jailbreaks for (Multimodal) Large Language Models
May 28, 2025While (multimodal) large language models (LLMs) have attracted widespread attention due to their exceptional capabilities, they remain vulnerable to jailbreak attacks. Various defense methods are proposed to defend against jailbreak attacks, however, they are often tailored to specific types of jailbreak attacks, limiting their effectiveness against diverse adversarial strategies. For instance, rephrasing-based defenses are effective against text adversarial jailbreaks but fail to counteract image-based attacks. To overcome these limitations, we propose a universal defense framework, termed Test-time IMmunization (TIM), which can adaptively defend against various jailbreak attacks in a self-evolving way. Specifically, TIM initially trains a gist token for efficient detection, which it subsequently applies to detect jailbreak activities during inference. When jailbreak attempts are identified, TIM implements safety fine-tuning using the detected jailbreak instructions paired with refusal answers. Furthermore, to mitigate potential performance degradation in the detector caused by parameter updates during safety fine-tuning, we decouple the fine-tuning process from the detection module. Extensive experiments on both LLMs and multimodal LLMs demonstrate the efficacy of TIM.
ThanoRA: Task Heterogeneity-Aware Multi-Task Low-Rank Adaptation
May 24, 2025Low-Rank Adaptation (LoRA) is widely adopted for downstream fine-tuning of foundation models due to its efficiency and zero additional inference cost. Many real-world applications require foundation models to specialize in multiple tasks simultaneously, motivating the need for efficient multi-task adaptation. While recent approaches integrate LoRA with mixture-of-experts (MoE) to address this, the use of routers prevents parameter mergeability, which increases inference overhead and hinders unified multi-task adaptation, thereby limiting deployment practicality. In this work, we propose ThanoRA, a Task Heterogeneity-Aware Multi-Task Low-Rank Adaptation framework that enables multi-task adaptation while preserving the inference efficiency of LoRA. ThanoRA jointly models task heterogeneity and mitigates subspace interference throughout training. Specifically, motivated by inherent differences in complexity and heterogeneity across tasks, ThanoRA constructs task-specific LoRA subspaces at initialization, enabling fine-grained knowledge injection aligned with task heterogeneity. Furthermore, to prevent task interference and subspace collapse during multi-task training, ThanoRA introduces a subspace-preserving regularization that maintains the independence of task-specific representations. With the synergy of both components, ThanoRA enables efficient and unified multi-task adaptation. Extensive experiments across multimodal and text-only benchmarks under varying multi-task mixtures demonstrate that ThanoRA consistently achieves robust and superior performance over strong baselines without introducing additional inference overhead. Our code is publicly available at: https://github.com/LiangJian24/ThanoRA.
Backdoor Cleaning without External Guidance in MLLM Fine-tuning
May 22, 2025Multimodal Large Language Models (MLLMs) are increasingly deployed in fine-tuning-as-a-service (FTaaS) settings, where user-submitted datasets adapt general-purpose models to downstream tasks. This flexibility, however, introduces serious security risks, as malicious fine-tuning can implant backdoors into MLLMs with minimal effort. In this paper, we observe that backdoor triggers systematically disrupt cross-modal processing by causing abnormal attention concentration on non-semantic regions--a phenomenon we term attention collapse. Based on this insight, we propose Believe Your Eyes (BYE), a data filtering framework that leverages attention entropy patterns as self-supervised signals to identify and filter backdoor samples. BYE operates via a three-stage pipeline: (1) extracting attention maps using the fine-tuned model, (2) computing entropy scores and profiling sensitive layers via bimodal separation, and (3) performing unsupervised clustering to remove suspicious samples. Unlike prior defenses, BYE equires no clean supervision, auxiliary labels, or model modifications. Extensive experiments across various datasets, models, and diverse trigger types validate BYE's effectiveness: it achieves near-zero attack success rates while maintaining clean-task performance, offering a robust and generalizable solution against backdoor threats in MLLMs.
From Local Details to Global Context: Advancing Vision-Language Models with Attention-Based Selection
May 19, 2025Pretrained vision-language models (VLMs), e.g., CLIP, demonstrate impressive zero-shot capabilities on downstream tasks. Prior research highlights the crucial role of visual augmentation techniques, like random cropping, in alignment with fine-grained class descriptions generated by large language models (LLMs), significantly enhancing zero-shot performance by incorporating multi-view information. However, the inherent randomness of these augmentations can inevitably introduce background artifacts and cause models to overly focus on local details, compromising global semantic understanding. To address these issues, we propose an \textbf{A}ttention-\textbf{B}ased \textbf{S}election (\textbf{ABS}) method from local details to global context, which applies attention-guided cropping in both raw images and feature space, supplement global semantic information through strategic feature selection. Additionally, we introduce a soft matching technique to effectively filter LLM descriptions for better alignment. \textbf{ABS} achieves state-of-the-art performance on out-of-distribution generalization and zero-shot classification tasks. Notably, \textbf{ABS} is training-free and even rivals few-shot and test-time adaptation methods. Our code is available at \href{https://github.com/BIT-DA/ABS}{\textcolor{darkgreen}{https://github.com/BIT-DA/ABS}}.