 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTIM: Teaching Large Language Models to Translate with Comparison
Jul 10, 2023



Open-sourced large language models (LLMs) have demonstrated remarkable efficacy in various tasks with instruction tuning. However, these models can sometimes struggle with tasks that require more specialized knowledge such as translation. One possible reason for such deficiency is that instruction tuning aims to generate fluent and coherent text that continues from a given instruction without being constrained by any task-specific requirements. Moreover, it can be more challenging for tuning smaller LLMs with lower-quality training data. To address this issue, we propose a novel framework using examples in comparison to teach LLMs to learn translation. Our approach involves presenting the model with examples of correct and incorrect translations and using a preference loss to guide the model's learning. We evaluate our method on WMT2022 test sets and show that it outperforms existing methods. Our findings offer a new perspective on fine-tuning LLMs for translation tasks and provide a promising solution for generating high-quality translations. Please refer to Github for more details: https://github.com/lemon0830/TIM.
Soft Language Clustering for Multilingual Model Pre-training
Jun 13, 2023



Multilingual pre-trained language models have demonstrated impressive (zero-shot) cross-lingual transfer abilities, however, their performance is hindered when the target language has distant typology from source languages or when pre-training data is limited in size. In this paper, we propose XLM-P, which contextually retrieves prompts as flexible guidance for encoding instances conditionally. Our XLM-P enables (1) lightweight modeling of language-invariant and language-specific knowledge across languages, and (2) easy integration with other multilingual pre-training methods. On the tasks of XTREME including text classification, sequence labeling, question answering, and sentence retrieval, both base- and large-size language models pre-trained with our proposed method exhibit consistent performance improvement. Furthermore, it provides substantial advantages for low-resource languages in unsupervised sentence retrieval and for target languages that differ greatly from the source language in cross-lingual transfer.
DualNER: A Dual-Teaching framework for Zero-shot Cross-lingual Named Entity Recognition
Nov 15, 2022



We present DualNER, a simple and effective framework to make full use of both annotated source language corpus and unlabeled target language text for zero-shot cross-lingual named entity recognition (NER). In particular, we combine two complementary learning paradigms of NER, i.e., sequence labeling and span prediction, into a unified multi-task framework. After obtaining a sufficient NER model trained on the source data, we further train it on the target data in a {\it dual-teaching} manner, in which the pseudo-labels for one task are constructed from the prediction of the other task. Moreover, based on the span prediction, an entity-aware regularization is proposed to enhance the intrinsic cross-lingual alignment between the same entities in different languages. Experiments and analysis demonstrate the effectiveness of our DualNER. Code is available at https://github.com/lemon0830/dualNER.
Contrastive Learning with Prompt-derived Virtual Semantic Prototypes for Unsupervised Sentence Embedding
Nov 07, 2022



Contrastive learning has become a new paradigm for unsupervised sentence embeddings. Previous studies focus on instance-wise contrastive learning, attempting to construct positive pairs with textual data augmentation. In this paper, we propose a novel Contrastive learning method with Prompt-derived Virtual semantic Prototypes (ConPVP). Specifically, with the help of prompts, we construct virtual semantic prototypes to each instance, and derive negative prototypes by using the negative form of the prompts. Using a prototypical contrastive loss, we enforce the anchor sentence embedding to be close to its corresponding semantic prototypes, and far apart from the negative prototypes as well as the prototypes of other sentences. Extensive experimental results on semantic textual similarity, transfer, and clustering tasks demonstrate the effectiveness of our proposed model compared to strong baselines. Code is available at https://github.com/lemon0830/promptCSE.
Modeling Paragraph-Level Vision-Language Semantic Alignment for Multi-Modal Summarization
Aug 24, 2022
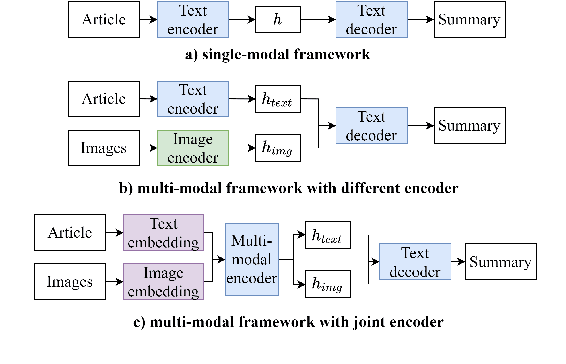
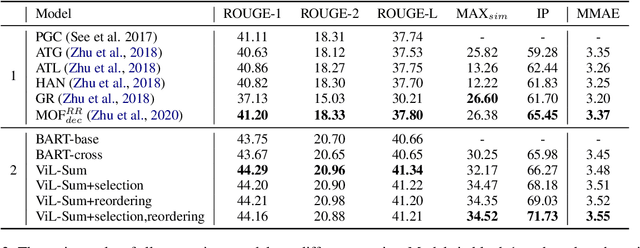
Most current multi-modal summarization methods follow a cascaded manner, where an off-the-shelf object detector is first used to extract visual features, then these features are fused with language representations to generate the summary with an encoder-decoder model. The cascaded way cannot capture the semantic alignments between images and paragraphs, which are crucial to a precise summary. In this paper, we propose ViL-Sum to jointly model paragraph-level \textbf{Vi}sion-\textbf{L}anguage Semantic Alignment and Multi-Modal \textbf{Sum}marization. The core of ViL-Sum is a joint multi-modal encoder with two well-designed tasks, image reordering and image selection. The joint multi-modal encoder captures the interactions between modalities, where the reordering task guides the model to learn paragraph-level semantic alignment and the selection task guides the model to selected summary-related images in the final summary. Experimental results show that our proposed ViL-Sum significantly outperforms current state-of-the-art methods. In further analysis, we find that two well-designed tasks and joint multi-modal encoder can effectively guide the model to learn reasonable paragraphs-images and summary-images relations.
An Efficient Coarse-to-Fine Facet-Aware Unsupervised Summarization Framework based on Semantic Blocks
Aug 17, 2022
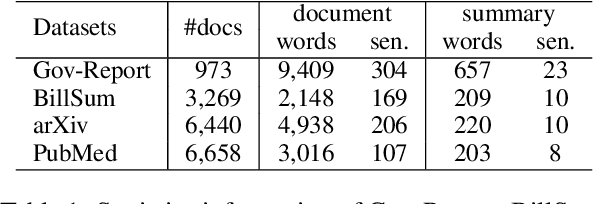
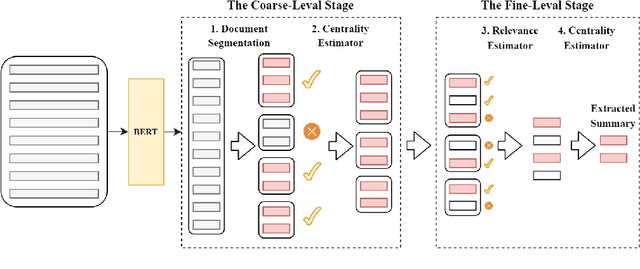
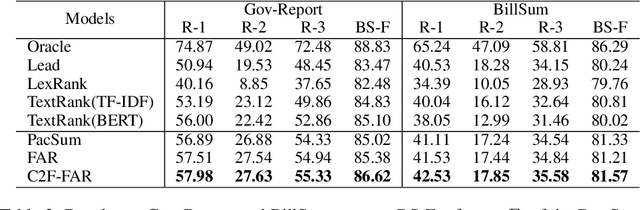
Unsupervised summarization methods have achieved remarkable results by incorporating representations from pre-trained language models. However, existing methods fail to consider efficiency and effectiveness at the same time when the input document is extremely long. To tackle this problem, in this paper, we proposed an efficient Coarse-to-Fine Facet-Aware Ranking (C2F-FAR) framework for unsupervised long document summarization, which is based on the semantic block. The semantic block refers to continuous sentences in the document that describe the same facet. Specifically, we address this problem by converting the one-step ranking method into the hierarchical multi-granularity two-stage ranking. In the coarse-level stage, we propose a new segment algorithm to split the document into facet-aware semantic blocks and then filter insignificant blocks. In the fine-level stage, we select salient sentences in each block and then extract the final summary from selected sentences. We evaluate our framework on four long document summarization datasets: Gov-Report, BillSum, arXiv, and PubMed. Our C2F-FAR can achieve new state-of-the-art unsupervised summarization results on Gov-Report and BillSum. In addition, our method speeds up 4-28 times more than previous methods.\footnote{\url{https://github.com/xnliang98/c2f-far}}
Task-guided Disentangled Tuning for Pretrained Language Models
Mar 22, 2022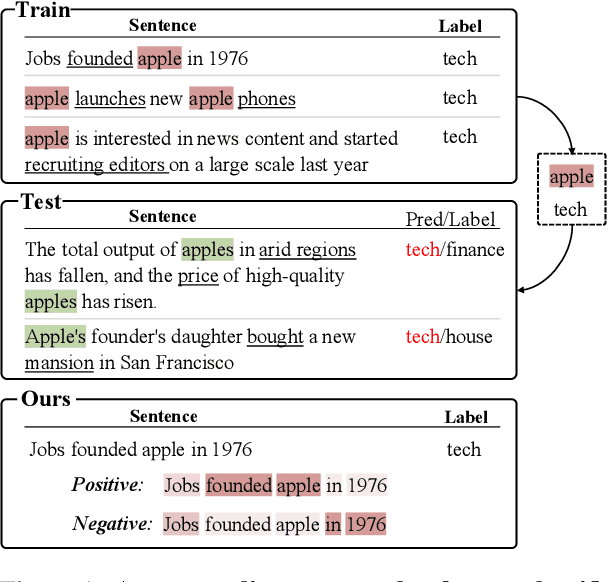
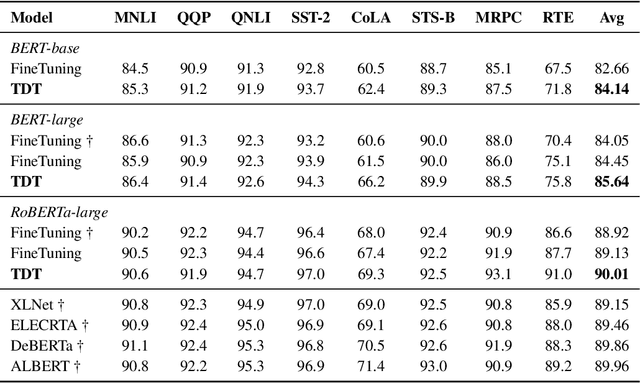

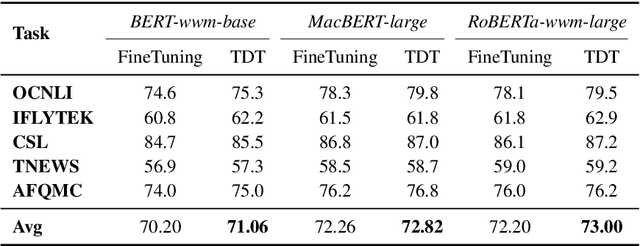
Pretrained language models (PLMs) trained on large-scale unlabeled corpus are typically fine-tuned on task-specific downstream datasets, which have produced state-of-the-art results on various NLP tasks. However, the data discrepancy issue in domain and scale makes fine-tuning fail to efficiently capture task-specific patterns, especially in the low data regime. To address this issue, we propose Task-guided Disentangled Tuning (TDT) for PLMs, which enhances the generalization of representations by disentangling task-relevant signals from the entangled representations. For a given task, we introduce a learnable confidence model to detect indicative guidance from context, and further propose a disentangled regularization to mitigate the over-reliance problem. Experimental results on GLUE and CLUE benchmarks show that TDT gives consistently better results than fine-tuning with different PLMs, and extensive analysis demonstrates the effectiveness and robustness of our method. Code is available at https://github.com/lemon0830/TDT.
Learning Confidence for Transformer-based Neural Machine Translation
Mar 22, 2022
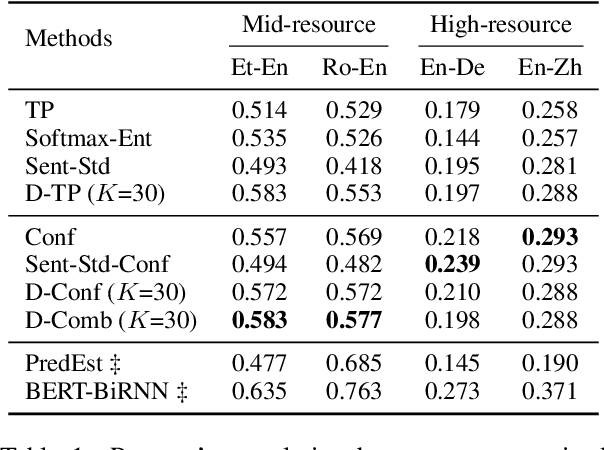
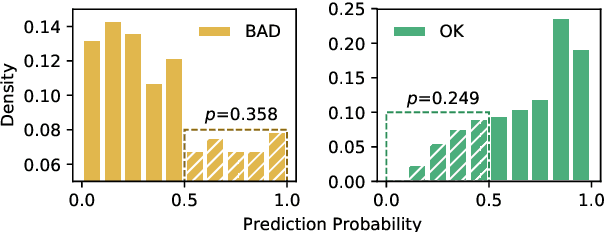

Confidence estimation aims to quantify the confidence of the model prediction, providing an expectation of success. A well-calibrated confidence estimate enables accurate failure prediction and proper risk measurement when given noisy samples and out-of-distribution data in real-world settings. However, this task remains a severe challenge for neural machine translation (NMT), where probabilities from softmax distribution fail to describe when the model is probably mistaken. To address this problem, we propose an unsupervised confidence estimate learning jointly with the training of the NMT model. We explain confidence as how many hints the NMT model needs to make a correct prediction, and more hints indicate low confidence. Specifically, the NMT model is given the option to ask for hints to improve translation accuracy at the cost of some slight penalty. Then, we approximate their level of confidence by counting the number of hints the model uses. We demonstrate that our learned confidence estimate achieves high accuracy on extensive sentence/word-level quality estimation tasks. Analytical results verify that our confidence estimate can correctly assess underlying risk in two real-world scenarios: (1) discovering noisy samples and (2) detecting out-of-domain data. We further propose a novel confidence-based instance-specific label smoothing approach based on our learned confidence estimate, which outperforms standard label smoothing.
Type-Driven Multi-Turn Corrections for Grammatical Error Correction
Mar 17, 2022

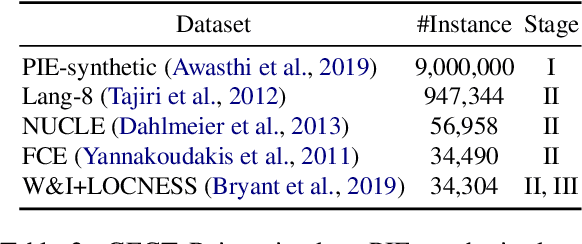
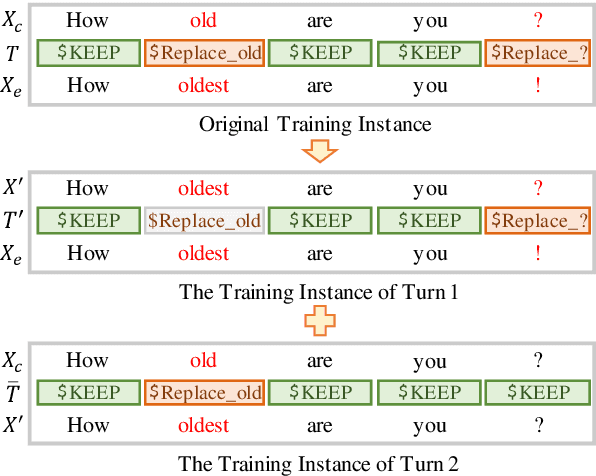
Grammatical Error Correction (GEC) aims to automatically detect and correct grammatical errors. In this aspect, dominant models are trained by one-iteration learning while performing multiple iterations of corrections during inference. Previous studies mainly focus on the data augmentation approach to combat the exposure bias, which suffers from two drawbacks. First, they simply mix additionally-constructed training instances and original ones to train models, which fails to help models be explicitly aware of the procedure of gradual corrections. Second, they ignore the interdependence between different types of corrections. In this paper, we propose a Type-Driven Multi-Turn Corrections approach for GEC. Using this approach, from each training instance, we additionally construct multiple training instances, each of which involves the correction of a specific type of errors. Then, we use these additionally-constructed training instances and the original one to train the model in turn. Experimental results and in-depth analysis show that our approach significantly benefits the model training. Particularly, our enhanced model achieves state-of-the-art single-model performance on English GEC benchmarks. We release our code at Github.
Improving Graph-based Sentence Ordering with Iteratively Predicted Pairwise Orderings
Oct 13, 2021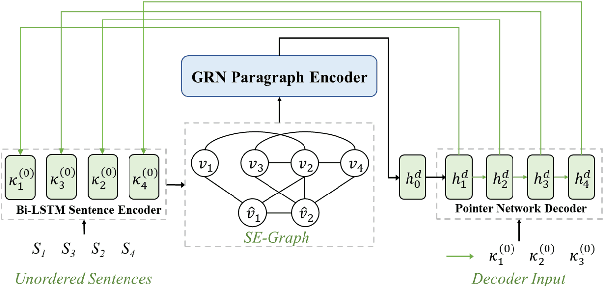
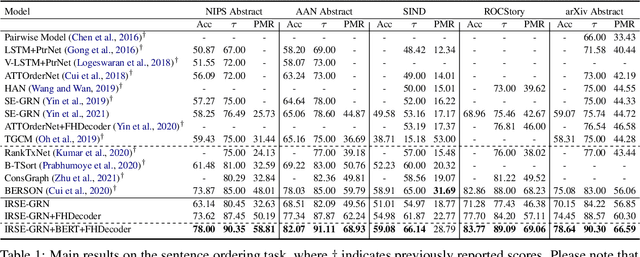
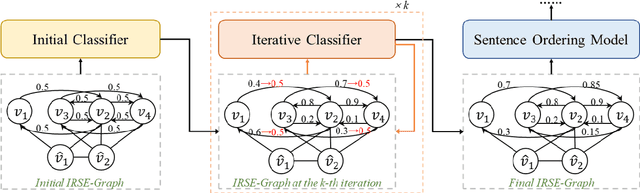
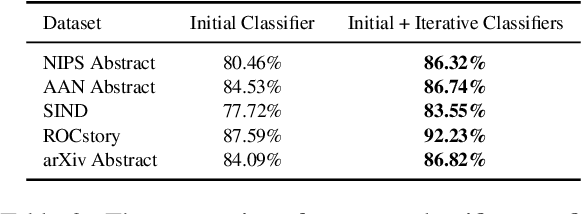
Dominant sentence ordering models can be classified into pairwise ordering models and set-to-sequence models. However, there is little attempt to combine these two types of models, which inituitively possess complementary advantages. In this paper, we propose a novel sentence ordering framework which introduces two classifiers to make better use of pairwise orderings for graph-based sentence ordering. Specially, given an initial sentence-entity graph, we first introduce a graph-based classifier to predict pairwise orderings between linked sentences. Then, in an iterative manner, based on the graph updated by previously predicted high-confident pairwise orderings, another classifier is used to predict the remaining uncertain pairwise orderings. At last, we adapt a GRN-based sentence ordering model on the basis of final graph. Experiments on five commonly-used datasets demonstrate the effectiveness and generality of our model. Particularly, when equipped with BERT and FHDecoder, our model achieves state-of-the-art performance.