 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImportance-Aware Scheduling for High-Dimensional Hyperparameter Optimization
Jun 08, 2026Hyperparameter Optimization (HPO) is essential for building high-performing ML/DL models, yet conventional optimizers often struggle in high-dimensional spaces where evaluations are costly and progress is diluted across many low-impact variables. We propose Greedy Importance First (GIF), an importance-aware scheduling strategy that uses a small-sample warm start to estimate hyperparameter importance, forms importance-based groups, allocates trials proportionally, and retains a full-space fallback. We evaluate GIF under fixed evaluation budgets on five anisotropic analytic functions, Bayesmark, and NAS-Bench-301. On the higher-dimensional benchmarks, GIF reaches better incumbents with faster convergence than TPE, BOHB, Random Search, and Sequential Grouping. On Bayesmark, where the effective dimensionality is smaller, GIF remains competitive but the margins are smaller. Ablation studies show that importance estimation, proportional allocation, and the fallback step all contribute to the gains. We also verify that the HIA component recovers the intended anisotropy on the analytic benchmarks. These results suggest that GIF is a simple and plug-compatible way to improve sample efficiency in high-dimensional HPO.
SynLeaF: A Dual-Stage Multimodal Fusion Framework for Synthetic Lethality Prediction Across Pan- and Single-Cancer Contexts
Mar 23, 2026Accurate prediction of synthetic lethality (SL) is important for guiding the development of cancer drugs and therapies. SL prediction faces significant challenges in the effective fusion of heterogeneous multi-source data. Existing multimodal methods often suffer from "modality laziness" due to disparate convergence speeds, which hinders the exploitation of complementary information. This is also one reason why most existing SL prediction models cannot perform well on both pan-cancer and single-cancer SL pair prediction. In this study, we propose SynLeaF, a dual-stage multimodal fusion framework for SL prediction across pan- and single-cancer contexts. The framework employs a VAE-based cross-encoder with a product of experts mechanism to fuse four omics data types (gene expression, mutation, methylation, and CNV), while simultaneously utilizing a relational graph convolutional network to capture structured gene representations from biomedical knowledge graphs. To mitigate modality laziness, SynLeaF introduces a dual-stage training mechanism employing featurelevel knowledge distillation with adaptive uni-modal teacher and ensemble strategies. In extensive experiments across eight specific cancer types and a pancancer dataset, SynLeaF achieves superior performance in 17 out of 19 scenarios. Ablation studies and gradient analyses further validate the critical contributions of the proposed fusion and distillation mechanisms to model robustness and generalization. To facilitate community use, a web server is available at https://synleaf.bioinformatics-lilab.cn.
Grouped Sequential Optimization Strategy -- the Application of Hyperparameter Importance Assessment in Deep Learning
Mar 07, 2025Hyperparameter optimization (HPO) is a critical component of machine learning pipelines, significantly affecting model robustness, stability, and generalization. However, HPO is often a time-consuming and computationally intensive task. Traditional HPO methods, such as grid search and random search, often suffer from inefficiency. Bayesian optimization, while more efficient, still struggles with high-dimensional search spaces. In this paper, we contribute to the field by exploring how insights gained from hyperparameter importance assessment (HIA) can be leveraged to accelerate HPO, reducing both time and computational resources. Building on prior work that quantified hyperparameter importance by evaluating 10 hyperparameters on CNNs using 10 common image classification datasets, we implement a novel HPO strategy called 'Sequential Grouping.' That prior work assessed the importance weights of the investigated hyperparameters based on their influence on model performance, providing valuable insights that we leverage to optimize our HPO process. Our experiments, validated across six additional image classification datasets, demonstrate that incorporating hyperparameter importance assessment (HIA) can significantly accelerate HPO without compromising model performance, reducing optimization time by an average of 31.9\% compared to the conventional simultaneous strategy.
Efficient Hyperparameter Importance Assessment for CNNs
Oct 11, 2024



Hyperparameter selection is an essential aspect of the machine learning pipeline, profoundly impacting models' robustness, stability, and generalization capabilities. Given the complex hyperparameter spaces associated with Neural Networks and the constraints of computational resources and time, optimizing all hyperparameters becomes impractical. In this context, leveraging hyperparameter importance assessment (HIA) can provide valuable guidance by narrowing down the search space. This enables machine learning practitioners to focus their optimization efforts on the hyperparameters with the most significant impact on model performance while conserving time and resources. This paper aims to quantify the importance weights of some hyperparameters in Convolutional Neural Networks (CNNs) with an algorithm called N-RReliefF, laying the groundwork for applying HIA methodologies in the Deep Learning field. We conduct an extensive study by training over ten thousand CNN models across ten popular image classification datasets, thereby acquiring a comprehensive dataset containing hyperparameter configuration instances and their corresponding performance metrics. It is demonstrated that among the investigated hyperparameters, the top five important hyperparameters of the CNN model are the number of convolutional layers, learning rate, dropout rate, optimizer and epoch.
Masked Imitation Learning: Discovering Environment-Invariant Modalities in Multimodal Demonstrations
Sep 16, 2022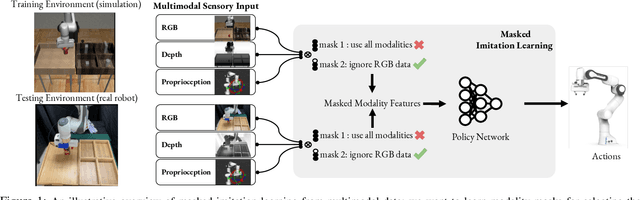
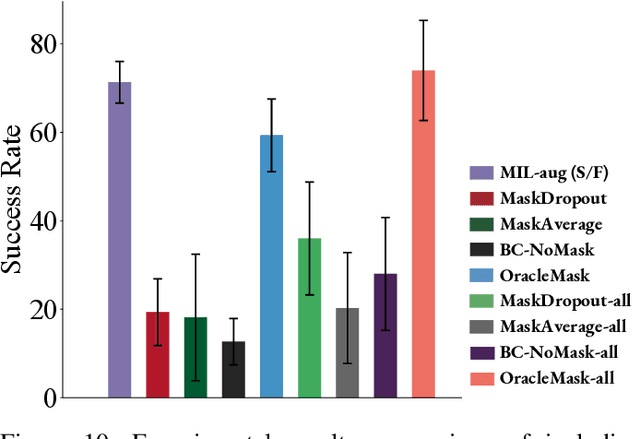
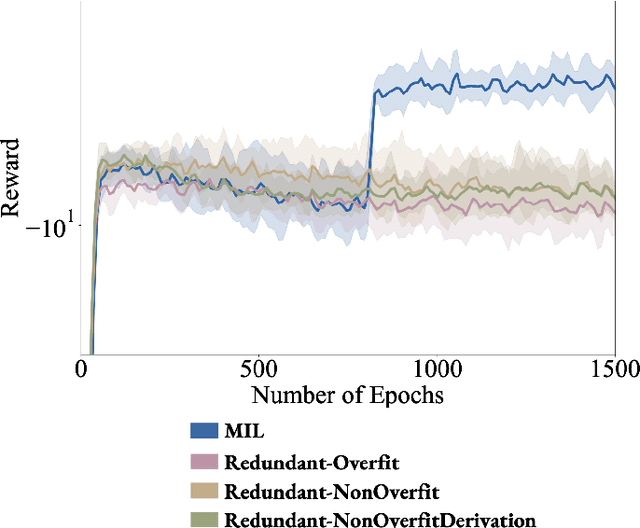
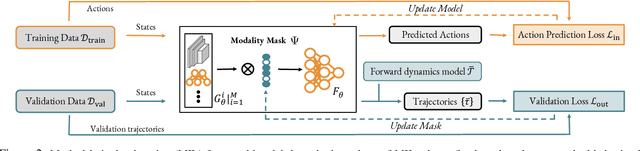
Multimodal demonstrations provide robots with an abundance of information to make sense of the world. However, such abundance may not always lead to good performance when it comes to learning sensorimotor control policies from human demonstrations. Extraneous data modalities can lead to state over-specification, where the state contains modalities that are not only useless for decision-making but also can change data distribution across environments. State over-specification leads to issues such as the learned policy not generalizing outside of the training data distribution. In this work, we propose Masked Imitation Learning (MIL) to address state over-specification by selectively using informative modalities. Specifically, we design a masked policy network with a binary mask to block certain modalities. We develop a bi-level optimization algorithm that learns this mask to accurately filter over-specified modalities. We demonstrate empirically that MIL outperforms baseline algorithms in simulated domains including MuJoCo and a robot arm environment using the Robomimic dataset, and effectively recovers the environment-invariant modalities on a multimodal dataset collected on a real robot. Our project website presents supplemental details and videos of our results at: https://tinyurl.com/masked-il