 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Network Social User Embedding with Hybrid Differential Privacy Guarantees
Sep 04, 2022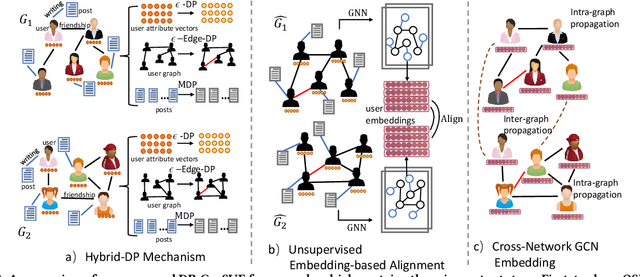

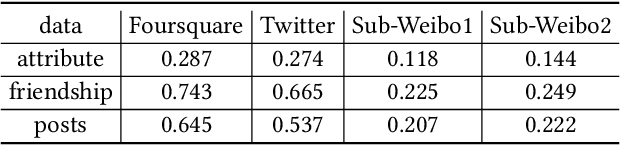
Integrating multiple online social networks (OSNs) has important implications for many downstream social mining tasks, such as user preference modelling, recommendation, and link prediction. However, it is unfortunately accompanied by growing privacy concerns about leaking sensitive user information. How to fully utilize the data from different online social networks while preserving user privacy remains largely unsolved. To this end, we propose a Cross-network Social User Embedding framework, namely DP-CroSUE, to learn the comprehensive representations of users in a privacy-preserving way. We jointly consider information from partially aligned social networks with differential privacy guarantees. In particular, for each heterogeneous social network, we first introduce a hybrid differential privacy notion to capture the variation of privacy expectations for heterogeneous data types. Next, to find user linkages across social networks, we make unsupervised user embedding-based alignment in which the user embeddings are achieved by the heterogeneous network embedding technology. To further enhance user embeddings, a novel cross-network GCN embedding model is designed to transfer knowledge across networks through those aligned users. Extensive experiments on three real-world datasets demonstrate that our approach makes a significant improvement on user interest prediction tasks as well as defending user attribute inference attacks from embedding.
Automating DBSCAN via Deep Reinforcement Learning
Aug 09, 2022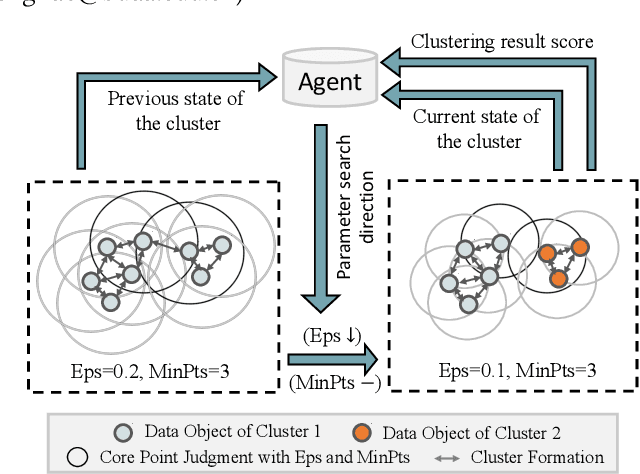
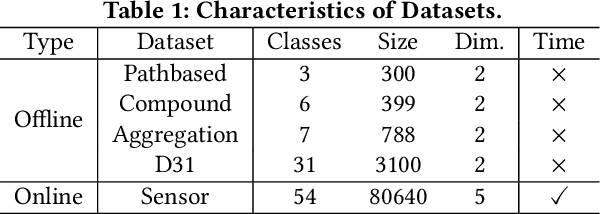
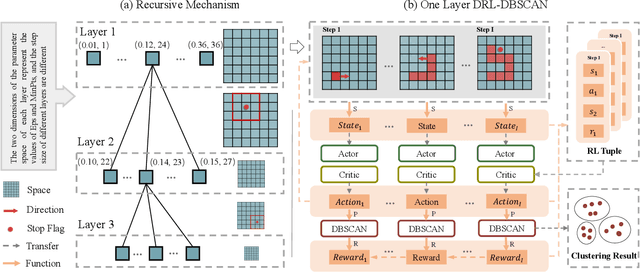
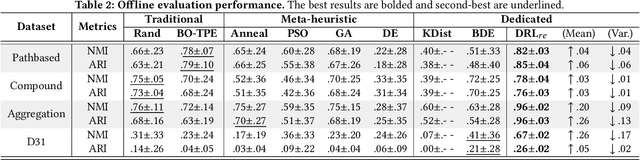
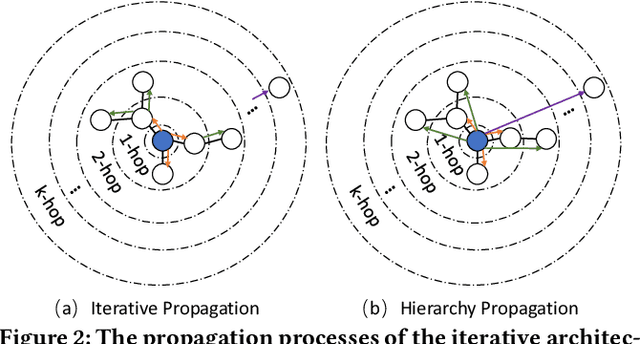
DBSCAN is widely used in many scientific and engineering fields because of its simplicity and practicality. However, due to its high sensitivity parameters, the accuracy of the clustering result depends heavily on practical experience. In this paper, we first propose a novel Deep Reinforcement Learning guided automatic DBSCAN parameters search framework, namely DRL-DBSCAN. The framework models the process of adjusting the parameter search direction by perceiving the clustering environment as a Markov decision process, which aims to find the best clustering parameters without manual assistance. DRL-DBSCAN learns the optimal clustering parameter search policy for different feature distributions via interacting with the clusters, using a weakly-supervised reward training policy network. In addition, we also present a recursive search mechanism driven by the scale of the data to efficiently and controllably process large parameter spaces. Extensive experiments are conducted on five artificial and real-world datasets based on the proposed four working modes. The results of offline and online tasks show that the DRL-DBSCAN not only consistently improves DBSCAN clustering accuracy by up to 26% and 25% respectively, but also can stably find the dominant parameters with high computational efficiency. The code is available at https://github.com/RingBDStack/DRL-DBSCAN.
A Comprehensive Survey on Deep Clustering: Taxonomy, Challenges, and Future Directions
Jun 15, 2022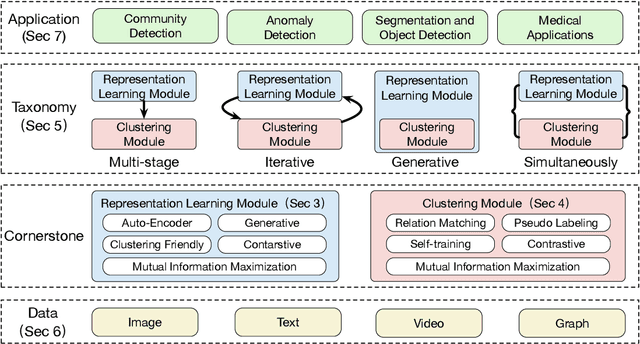
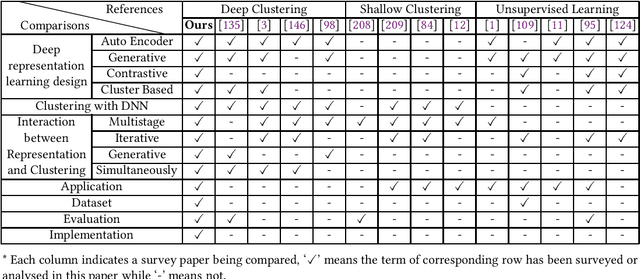
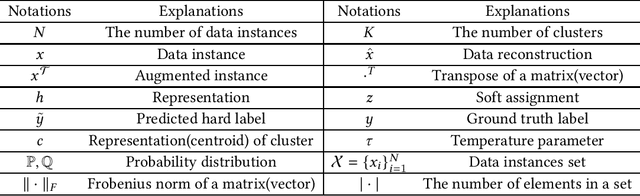
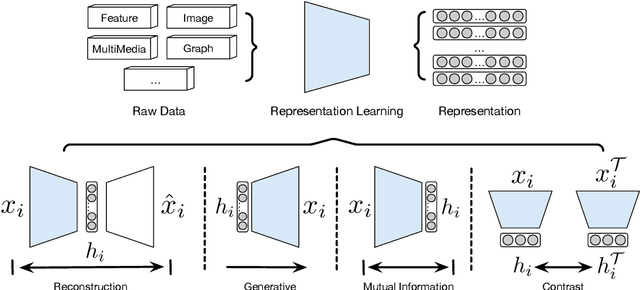
Clustering is a fundamental machine learning task which has been widely studied in the literature. Classic clustering methods follow the assumption that data are represented as features in a vectorized form through various representation learning techniques. As the data become increasingly complicated and complex, the shallow (traditional) clustering methods can no longer handle the high-dimensional data type. With the huge success of deep learning, especially the deep unsupervised learning, many representation learning techniques with deep architectures have been proposed in the past decade. Recently, the concept of Deep Clustering, i.e., jointly optimizing the representation learning and clustering, has been proposed and hence attracted growing attention in the community. Motivated by the tremendous success of deep learning in clustering, one of the most fundamental machine learning tasks, and the large number of recent advances in this direction, in this paper we conduct a comprehensive survey on deep clustering by proposing a new taxonomy of different state-of-the-art approaches. We summarize the essential components of deep clustering and categorize existing methods by the ways they design interactions between deep representation learning and clustering. Moreover, this survey also provides the popular benchmark datasets, evaluation metrics and open-source implementations to clearly illustrate various experimental settings. Last but not least, we discuss the practical applications of deep clustering and suggest challenging topics deserving further investigations as future directions.
Graph-level Neural Networks: Current Progress and Future Directions
May 31, 2022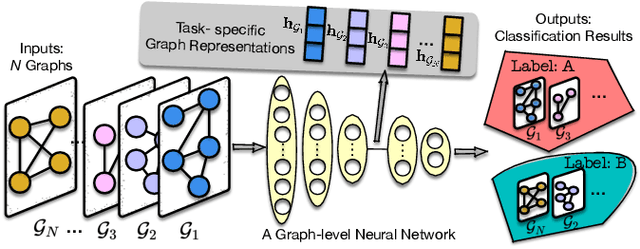

Graph-structured data consisting of objects (i.e., nodes) and relationships among objects (i.e., edges) are ubiquitous. Graph-level learning is a matter of studying a collection of graphs instead of a single graph. Traditional graph-level learning methods used to be the mainstream. However, with the increasing scale and complexity of graphs, Graph-level Neural Networks (GLNNs, deep learning-based graph-level learning methods) have been attractive due to their superiority in modeling high-dimensional data. Thus, a survey on GLNNs is necessary. To frame this survey, we propose a systematic taxonomy covering GLNNs upon deep neural networks, graph neural networks, and graph pooling. The representative and state-of-the-art models in each category are focused on this survey. We also investigate the reproducibility, benchmarks, and new graph datasets of GLNNs. Finally, we conclude future directions to further push forward GLNNs. The repository of this survey is available at https://github.com/GeZhangMQ/Awesome-Graph-level-Neural-Networks.
Evidential Temporal-aware Graph-based Social Event Detection via Dempster-Shafer Theory
May 24, 2022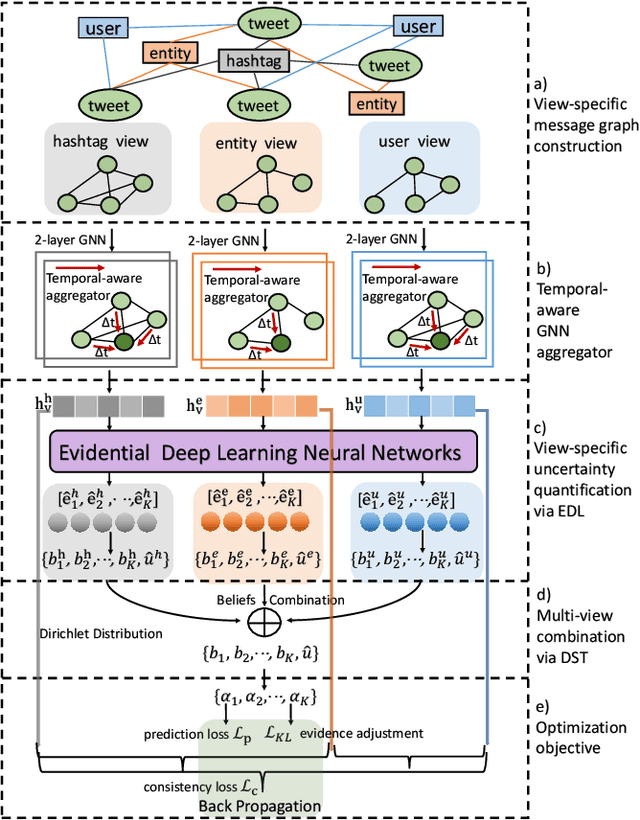
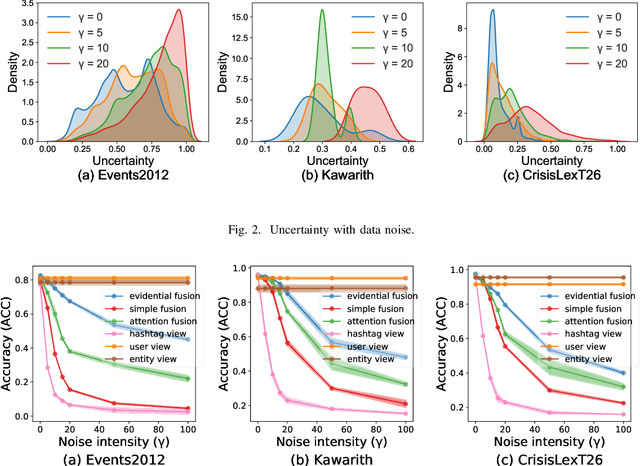
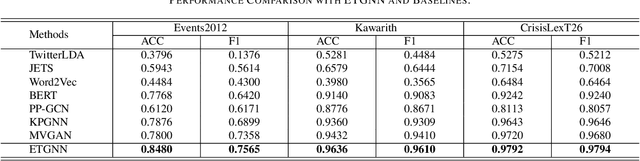
The rising popularity of online social network services has attracted lots of research on mining social media data, especially on mining social events. Social event detection, due to its wide applications, has now become a trivial task. State-of-the-art approaches exploiting Graph Neural Networks (GNNs) usually follow a two-step strategy: 1) constructing text graphs based on various views (\textit{co-user}, \textit{co-entities} and \textit{co-hashtags}); and 2) learning a unified text representation by a specific GNN model. Generally, the results heavily rely on the quality of the constructed graphs and the specific message passing scheme. However, existing methods have deficiencies in both aspects: 1) They fail to recognize the noisy information induced by unreliable views. 2) Temporal information which works as a vital indicator of events is neglected in most works. To this end, we propose ETGNN, a novel Evidential Temporal-aware Graph Neural Network. Specifically, we construct view-specific graphs whose nodes are the texts and edges are determined by several types of shared elements respectively. To incorporate temporal information into the message passing scheme, we introduce a novel temporal-aware aggregator which assigns weights to neighbours according to an adaptive time exponential decay formula. Considering the view-specific uncertainty, the representations of all views are converted into mass functions through evidential deep learning (EDL) neural networks, and further combined via Dempster-Shafer theory (DST) to make the final detection. Experimental results on three real-world datasets demonstrate the effectiveness of ETGNN in accuracy, reliability and robustness in social event detection.
Embedding Knowledge for Document Summarization: A Survey
Apr 24, 2022
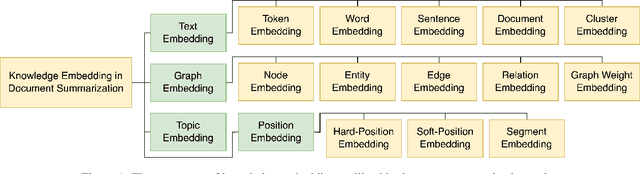
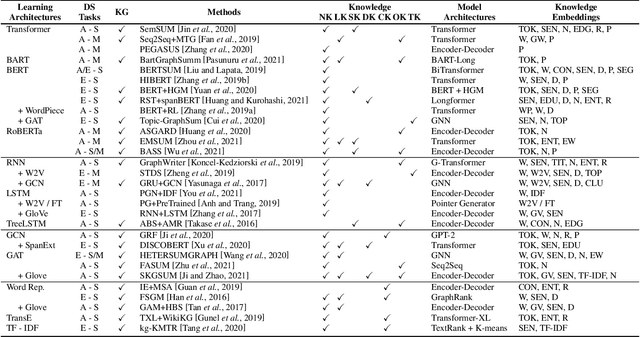
Knowledge-aware methods have boosted a range of Natural Language Processing applications over the last decades. With the gathered momentum, knowledge recently has been pumped into enormous attention in document summarization research. Previous works proved that knowledge-embedded document summarizers excel at generating superior digests, especially in terms of informativeness, coherence, and fact consistency. This paper pursues to present the first systematic survey for the state-of-the-art methodologies that embed knowledge into document summarizers. Particularly, we propose novel taxonomies to recapitulate knowledge and knowledge embeddings under the document summarization view. We further explore how embeddings are generated in learning architectures of document summarization models, especially in deep learning models. At last, we discuss the challenges of this topic and future directions.
Graph Pooling for Graph Neural Networks: Progress, Challenges, and Opportunities
Apr 15, 2022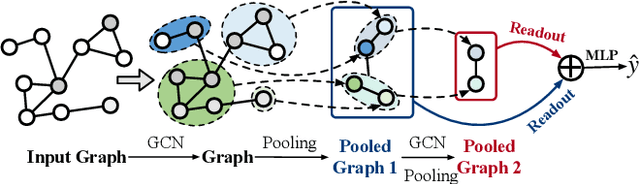

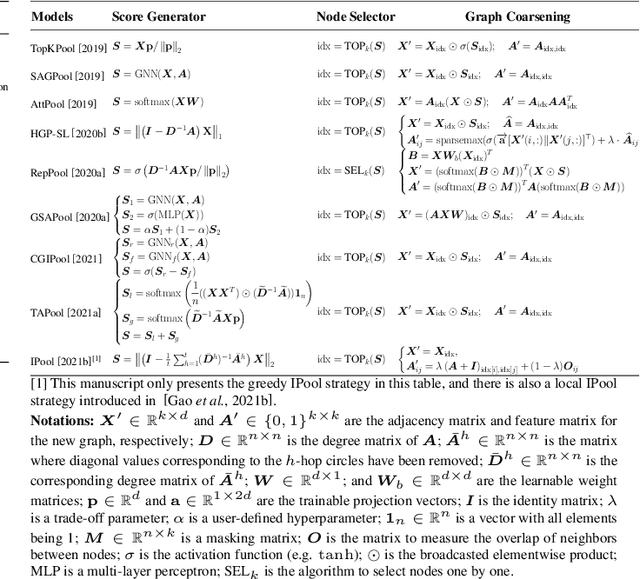
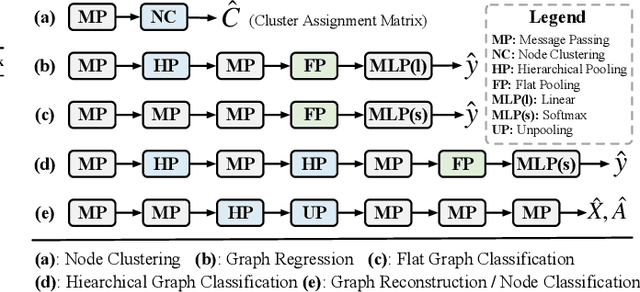
Graph neural networks have emerged as a leading architecture for many graph-level tasks such as graph classification and graph generation with a notable improvement. Among these tasks, graph pooling is an essential component of graph neural network architectures for obtaining a holistic graph-level representation of the entire graph. Although a great variety of methods have been proposed in this promising and fast-developing research field, to the best of our knowledge, little effort has been made to systematically summarize these methods. To set the stage for the development of future works, in this paper, we attempt to fill this gap by providing a broad review of recent methods on graph pooling. Specifically, 1) we first propose a taxonomy of existing graph pooling methods and provide a mathematical summary for each category; 2) next, we provide an overview of the libraries related to graph pooling, including the commonly used datasets, model architectures for downstream tasks, and open-source implementations; 3) then, we further outline in brief the applications that incorporate the idea of graph pooling in a number of domains; 4) and finally, we discuss some critical challenges faced by the current studies and share our insights on potential directions for improving graph pooling in the future.
Deep Reinforcement Learning Guided Graph Neural Networks for Brain Network Analysis
Mar 18, 2022
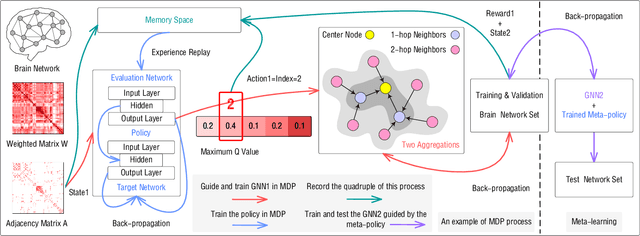

Modern neuroimaging techniques, such as diffusion tensor imaging (DTI) and functional magnetic resonance imaging (fMRI), enable us to model the human brain as a brain network or connectome. Capturing brain networks' structural information and hierarchical patterns is essential for understanding brain functions and disease states. Recently, the promising network representation learning capability of graph neural networks (GNNs) has prompted many GNN-based methods for brain network analysis to be proposed. Specifically, these methods apply feature aggregation and global pooling to convert brain network instances into meaningful low-dimensional representations used for downstream brain network analysis tasks. However, existing GNN-based methods often neglect that brain networks of different subjects may require various aggregation iterations and use GNN with a fixed number of layers to learn all brain networks. Therefore, how to fully release the potential of GNNs to promote brain network analysis is still non-trivial. To solve this problem, we propose a novel brain network representation framework, namely BN-GNN, which searches for the optimal GNN architecture for each brain network. Concretely, BN-GNN employs deep reinforcement learning (DRL) to train a meta-policy to automatically determine the optimal number of feature aggregations (reflected in the number of GNN layers) required for a given brain network. Extensive experiments on eight real-world brain network datasets demonstrate that our proposed BN-GNN improves the performance of traditional GNNs on different brain network analysis tasks.
Curvature Graph Generative Adversarial Networks
Mar 03, 2022
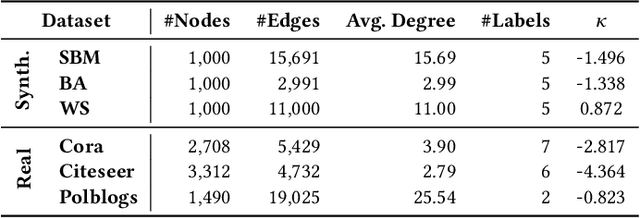
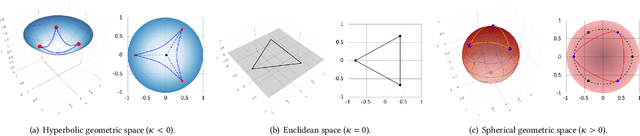
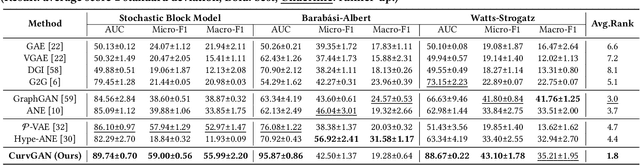
Generative adversarial network (GAN) is widely used for generalized and robust learning on graph data. However, for non-Euclidean graph data, the existing GAN-based graph representation methods generate negative samples by random walk or traverse in discrete space, leading to the information loss of topological properties (e.g. hierarchy and circularity). Moreover, due to the topological heterogeneity (i.e., different densities across the graph structure) of graph data, they suffer from serious topological distortion problems. In this paper, we proposed a novel Curvature Graph Generative Adversarial Networks method, named \textbf{\modelname}, which is the first GAN-based graph representation method in the Riemannian geometric manifold. To better preserve the topological properties, we approximate the discrete structure as a continuous Riemannian geometric manifold and generate negative samples efficiently from the wrapped normal distribution. To deal with the topological heterogeneity, we leverage the Ricci curvature for local structures with different topological properties, obtaining to low-distortion representations. Extensive experiments show that CurvGAN consistently and significantly outperforms the state-of-the-art methods across multiple tasks and shows superior robustness and generalization.
Single-stage Rotate Object Detector via Two Points with Solar Corona Heatmap
Feb 14, 2022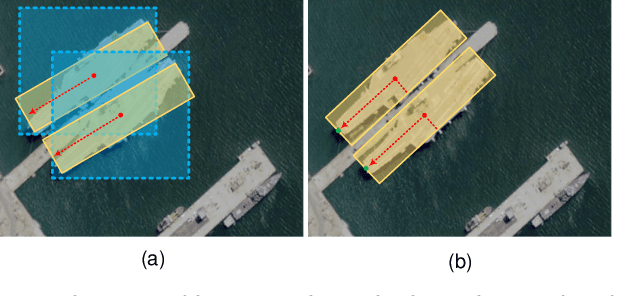

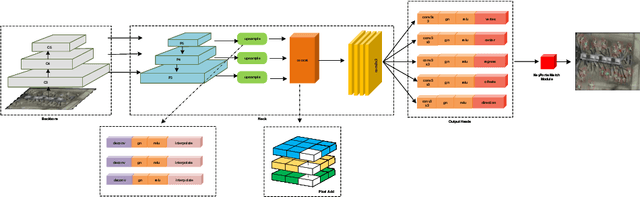
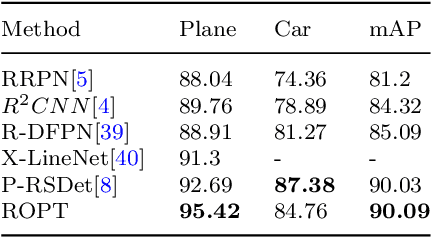
Oriented object detection is a crucial task in computer vision. Current top-down oriented detection methods usually directly detect entire objects, and not only neglecting the authentic direction of targets, but also do not fully utilise the key semantic information, which causes a decrease in detection accuracy. In this study, we developed a single-stage rotating object detector via two points with a solar corona heatmap (ROTP) to detect oriented objects. The ROTP predicts parts of the object and then aggregates them to form a whole image. Herein, we meticulously represent an object in a random direction using the vertex, centre point with width, and height. Specifically, we regress two heatmaps that characterise the relative location of each object, which enhances the accuracy of locating objects and avoids deviations caused by angle predictions. To rectify the central misjudgement of the Gaussian heatmap on high-aspect ratio targets, we designed a solar corona heatmap generation method to improve the perception difference between the central and non-central samples. Additionally, we predicted the vertex relative to the direction of the centre point to connect two key points that belong to the same goal. Experiments on the HRSC 2016, UCASAOD, and DOTA datasets show that our ROTP achieves the most advanced performance with a simpler modelling and less manual intervention.