 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Learning of Energy-Constrained Deep Neural Networks
Jun 12, 2018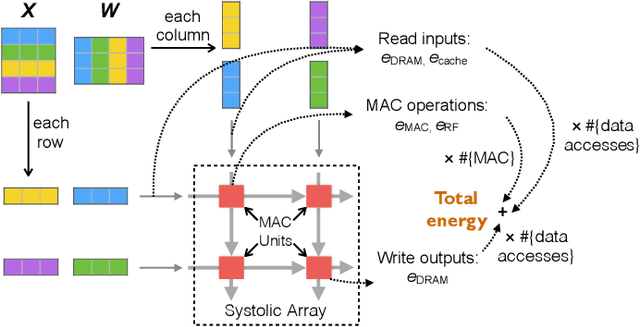

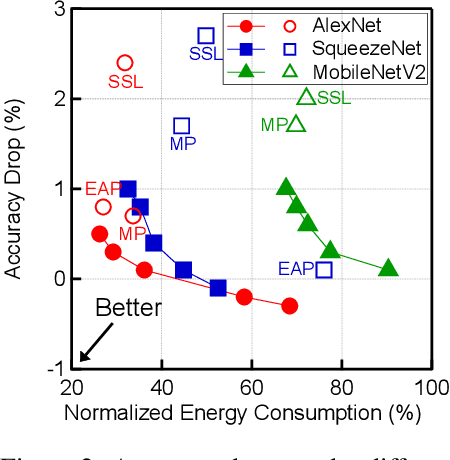

Deep Neural Networks (DNN) are increasingly deployed in highly energy-constrained environments such as autonomous drones and wearable devices while at the same time must operate in real-time. Therefore, reducing the energy consumption has become a major design consideration in DNN training. This paper proposes the first end-to-end DNN training framework that provides quantitative energy guarantees. The key idea is to formulate the DNN training as an optimization problem in which the energy budget imposes a previously unconsidered optimization constraint. We integrate the quantitative DNN energy estimation into the DNN training process to assist the constraint optimization. We prove that an approximate algorithm can be used to efficiently solve the optimization problem. Compared to the best prior energy-saving techniques, our framework trains DNNs that provide higher accuracies under same or lower energy budgets.
GESF: A Universal Discriminative Mapping Mechanism for Graph Representation Learning
Jun 05, 2018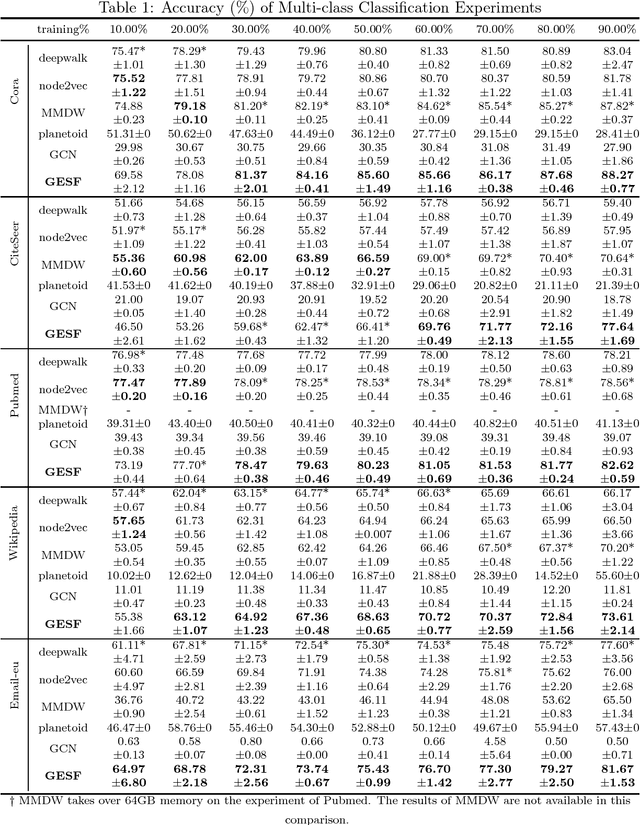
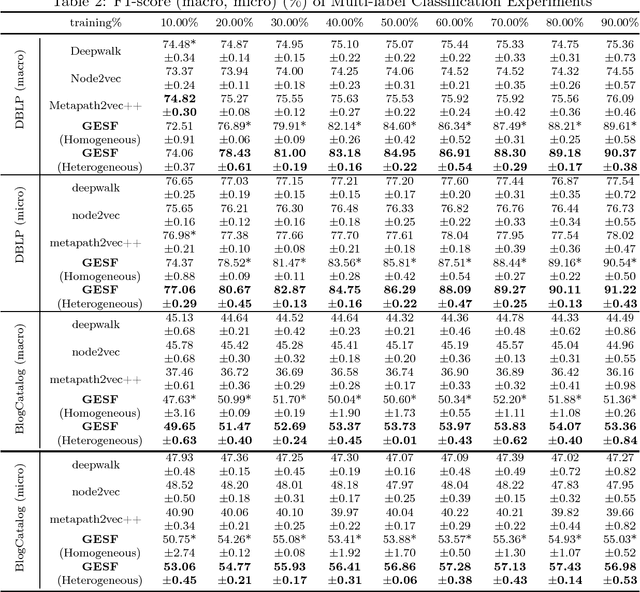
Graph embedding is a central problem in social network analysis and many other applications, aiming to learn the vector representation for each node. While most existing approaches need to specify the neighborhood and the dependence form to the neighborhood, which may significantly degrades the flexibility of representation, we propose a novel graph node embedding method (namely GESF) via the set function technique. Our method can 1) learn an arbitrary form of representation function from neighborhood, 2) automatically decide the significance of neighbors at different distances, and 3) be applied to heterogeneous graph embedding, which may contain multiple types of nodes. Theoretical guarantee for the representation capability of our method has been proved for general homogeneous and heterogeneous graphs and evaluation results on benchmark data sets show that the proposed GESF outperforms the state-of-the-art approaches on producing node vectors for classification tasks.
Parallel Computation of PDFs on Big Spatial Data Using Spark
May 08, 2018

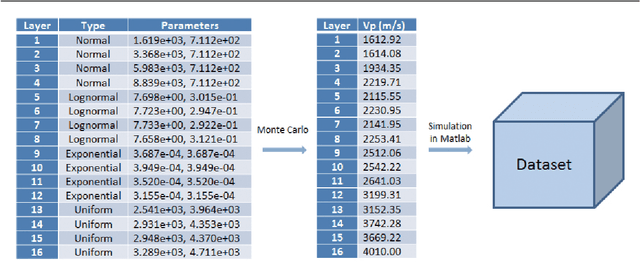
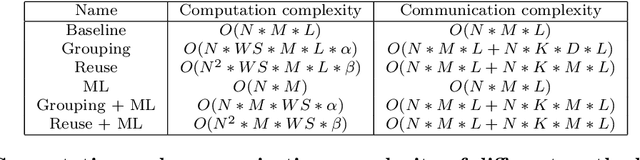
We consider big spatial data, which is typically produced in scientific areas such as geological or seismic interpretation. The spatial data can be produced by observation (e.g. using sensors or soil instrument) or numerical simulation programs and correspond to points that represent a 3D soil cube area. However, errors in signal processing and modeling create some uncertainty, and thus a lack of accuracy in identifying geological or seismic phenomenons. Such uncertainty must be carefully analyzed. To analyze uncertainty, the main solution is to compute a Probability Density Function (PDF) of each point in the spatial cube area. However, computing PDFs on big spatial data can be very time consuming (from several hours to even months on a parallel computer). In this paper, we propose a new solution to efficiently compute such PDFs in parallel using Spark, with three methods: data grouping, machine learning prediction and sampling. We evaluate our solution by extensive experiments on different computer clusters using big data ranging from hundreds of GB to several TB. The experimental results show that our solution scales up very well and can reduce the execution time by a factor of 33 (in the order of seconds or minutes) compared with a baseline method.
D$^2$: Decentralized Training over Decentralized Data
Apr 20, 2018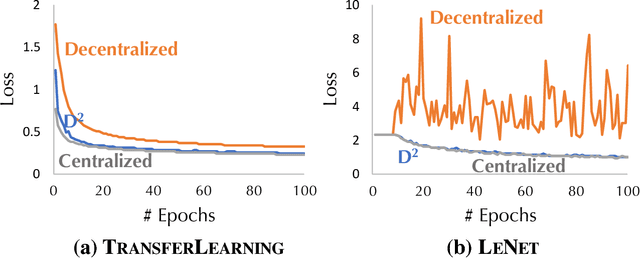
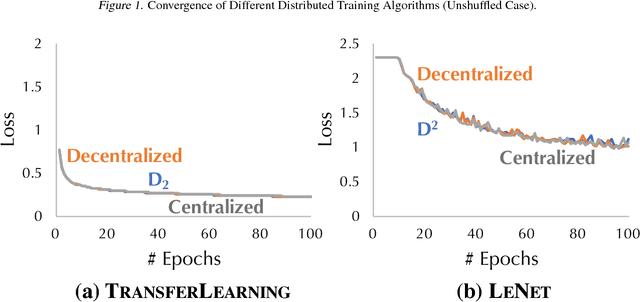
While training a machine learning model using multiple workers, each of which collects data from their own data sources, it would be most useful when the data collected from different workers can be {\em unique} and {\em different}. Ironically, recent analysis of decentralized parallel stochastic gradient descent (D-PSGD) relies on the assumption that the data hosted on different workers are {\em not too different}. In this paper, we ask the question: {\em Can we design a decentralized parallel stochastic gradient descent algorithm that is less sensitive to the data variance across workers?} In this paper, we present D$^2$, a novel decentralized parallel stochastic gradient descent algorithm designed for large data variance \xr{among workers} (imprecisely, "decentralized" data). The core of D$^2$ is a variance blackuction extension of the standard D-PSGD algorithm, which improves the convergence rate from $O\left({\sigma \over \sqrt{nT}} + {(n\zeta^2)^{\frac{1}{3}} \over T^{2/3}}\right)$ to $O\left({\sigma \over \sqrt{nT}}\right)$ where $\zeta^{2}$ denotes the variance among data on different workers. As a result, D$^2$ is robust to data variance among workers. We empirically evaluated D$^2$ on image classification tasks where each worker has access to only the data of a limited set of labels, and find that D$^2$ significantly outperforms D-PSGD.
Learning Simple Thresholded Features with Sparse Support Recovery
Apr 16, 2018
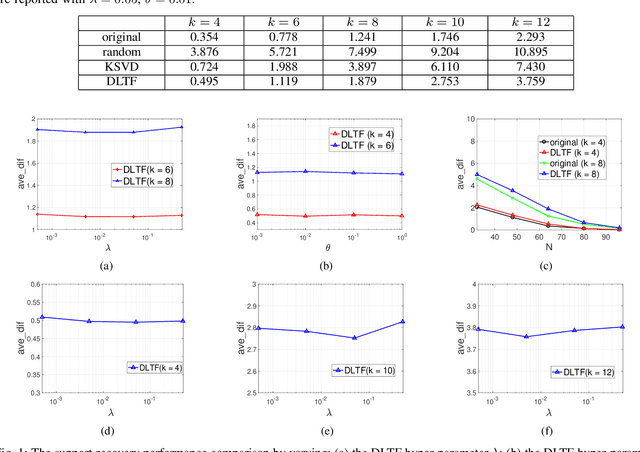
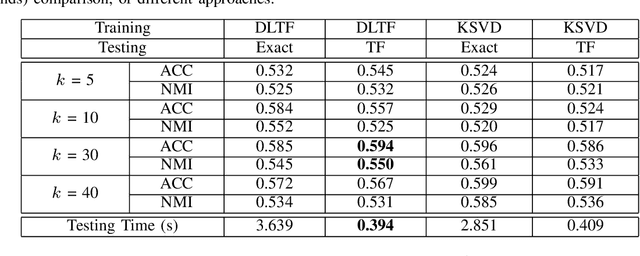

The thresholded feature has recently emerged as an extremely efficient, yet rough empirical approximation, of the time-consuming sparse coding inference process. Such an approximation has not yet been rigorously examined, and standard dictionaries often lead to non-optimal performance when used for computing thresholded features. In this paper, we first present two theoretical recovery guarantees for the thresholded feature to exactly recover the nonzero support of the sparse code. Motivated by them, we then formulate the Dictionary Learning for Thresholded Features (DLTF) model, which learns an optimized dictionary for applying the thresholded feature. In particular, for the $(k, 2)$ norm involved, a novel proximal operator with log-linear time complexity $O(m\log m)$ is derived. We evaluate the performance of DLTF on a vast range of synthetic and real-data tasks, where DLTF demonstrates remarkable efficiency, effectiveness and robustness in all experiments. In addition, we briefly discuss the potential link between DLTF and deep learning building blocks.
A Robust AUC Maximization Framework with Simultaneous Outlier Detection and Feature Selection for Positive-Unlabeled Classification
Mar 18, 2018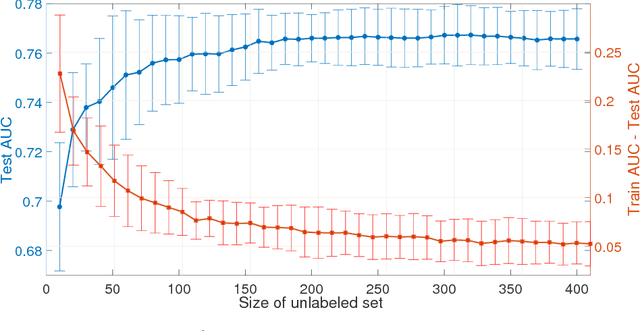
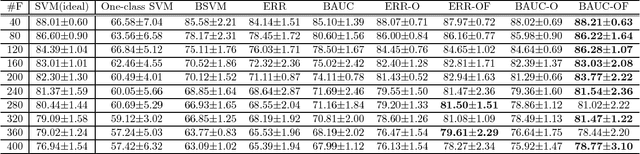
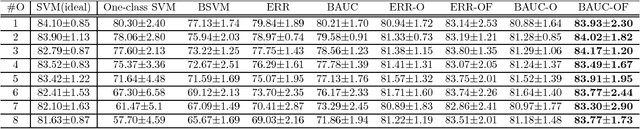
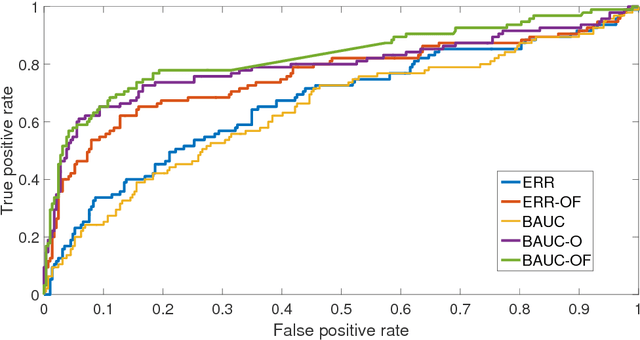
The positive-unlabeled (PU) classification is a common scenario in real-world applications such as healthcare, text classification, and bioinformatics, in which we only observe a few samples labeled as "positive" together with a large volume of "unlabeled" samples that may contain both positive and negative samples. Building robust classifier for the PU problem is very challenging, especially for complex data where the negative samples overwhelm and mislabeled samples or corrupted features exist. To address these three issues, we propose a robust learning framework that unifies AUC maximization (a robust metric for biased labels), outlier detection (for excluding wrong labels), and feature selection (for excluding corrupted features). The generalization error bounds are provided for the proposed model that give valuable insight into the theoretical performance of the method and lead to useful practical guidance, e.g., to train a model, we find that the included unlabeled samples are sufficient as long as the sample size is comparable to the number of positive samples in the training process. Empirical comparisons and two real-world applications on surgical site infection (SSI) and EEG seizure detection are also conducted to show the effectiveness of the proposed model.
Accelerated Method for Stochastic Composition Optimization with Nonsmooth Regularization
Dec 29, 2017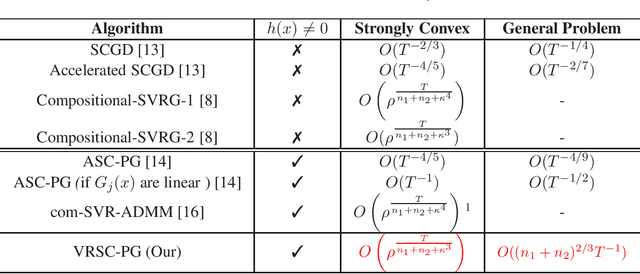
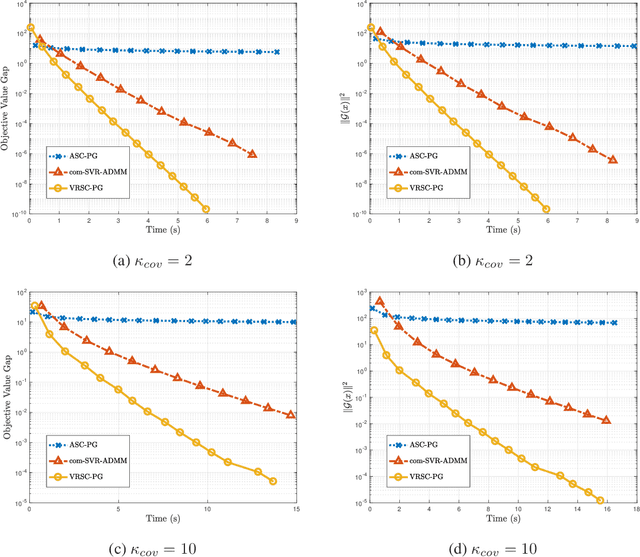
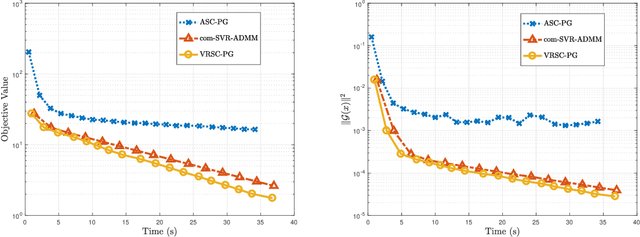
Stochastic composition optimization draws much attention recently and has been successful in many emerging applications of machine learning, statistical analysis, and reinforcement learning. In this paper, we focus on the composition problem with nonsmooth regularization penalty. Previous works either have slow convergence rate or do not provide complete convergence analysis for the general problem. In this paper, we tackle these two issues by proposing a new stochastic composition optimization method for composition problem with nonsmooth regularization penalty. In our method, we apply variance reduction technique to accelerate the speed of convergence. To the best of our knowledge, our method admits the fastest convergence rate for stochastic composition optimization: for strongly convex composition problem, our algorithm is proved to admit linear convergence; for general composition problem, our algorithm significantly improves the state-of-the-art convergence rate from $O(T^{-1/2})$ to $O((n_1+n_2)^{{2}/{3}}T^{-1})$. Finally, we apply our proposed algorithm to portfolio management and policy evaluation in reinforcement learning. Experimental results verify our theoretical analysis.
Cascaded Region-based Densely Connected Network for Event Detection: A Seismic Application
Nov 29, 2017
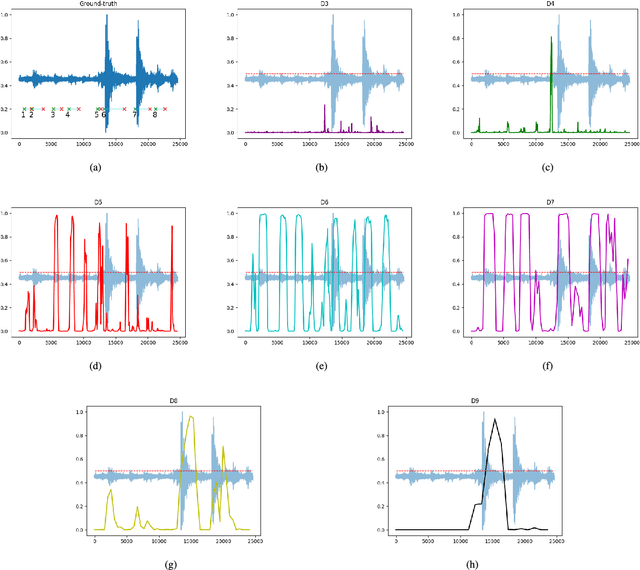
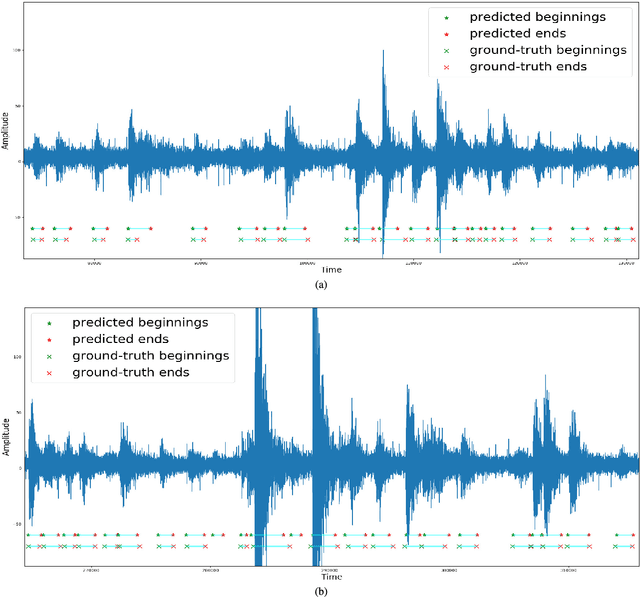
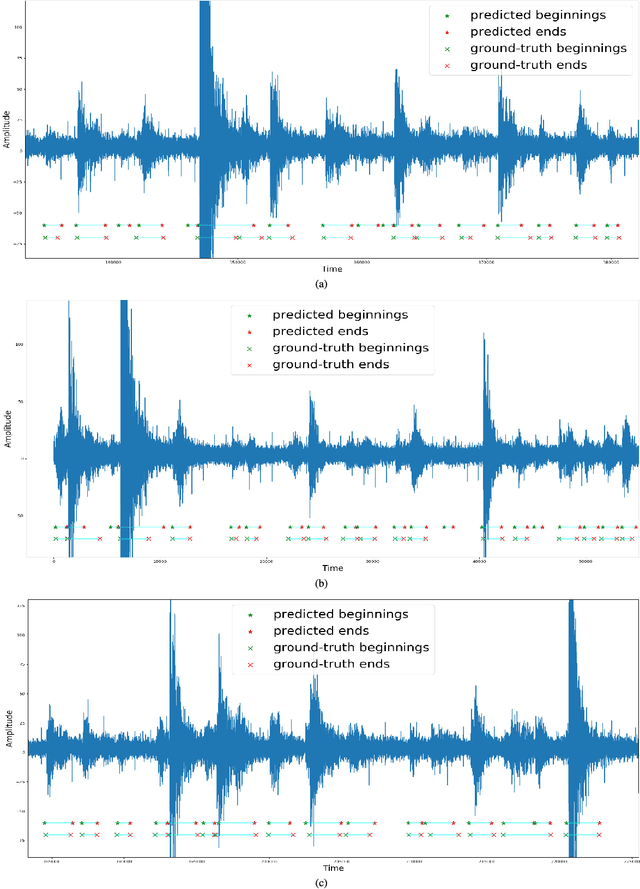
Automatic event detection from time series signals has wide applications, such as abnormal event detection in video surveillance and event detection in geophysical data. Traditional detection methods detect events primarily by the use of similarity and correlation in data. Those methods can be inefficient and yield low accuracy. In recent years, because of the significantly increased computational power, machine learning techniques have revolutionized many science and engineering domains. In this study, we apply a deep-learning-based method to the detection of events from time series seismic signals. However, a direct adaptation of the similar ideas from 2D object detection to our problem faces two challenges. The first challenge is that the duration of earthquake event varies significantly; The other is that the proposals generated are temporally correlated. To address these challenges, we propose a novel cascaded region-based convolutional neural network to capture earthquake events in different sizes, while incorporating contextual information to enrich features for each individual proposal. To achieve a better generalization performance, we use densely connected blocks as the backbone of our network. Because of the fact that some positive events are not correctly annotated, we further formulate the detection problem as a learning-from-noise problem. To verify the performance of our detection methods, we employ our methods to seismic data generated from a bi-axial "earthquake machine" located at Rock Mechanics Laboratory, and we acquire labels with the help of experts. Through our numerical tests, we show that our novel detection techniques yield high accuracy. Therefore, our novel deep-learning-based detection methods can potentially be powerful tools for locating events from time series data in various applications.
Variance Reduced methods for Non-convex Composition Optimization
Nov 13, 2017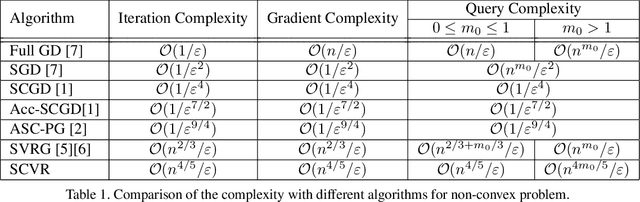
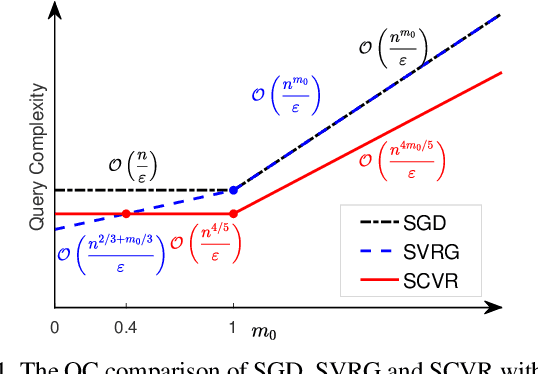
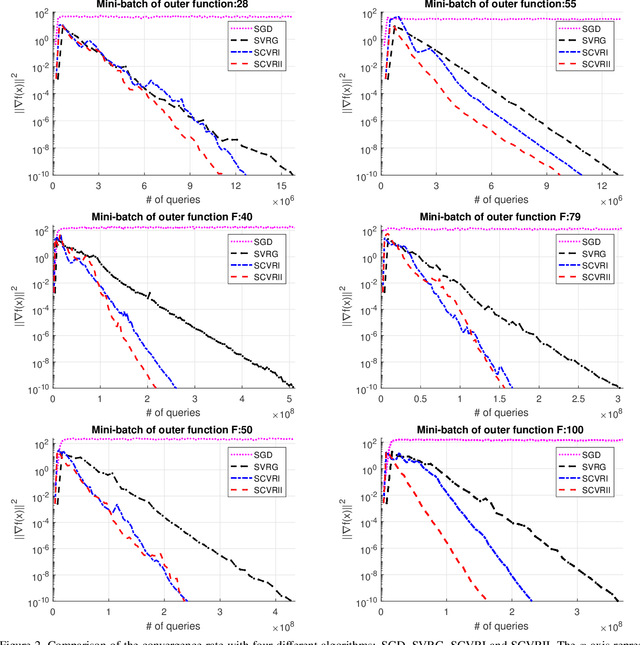
This paper explores the non-convex composition optimization in the form including inner and outer finite-sum functions with a large number of component functions. This problem arises in some important applications such as nonlinear embedding and reinforcement learning. Although existing approaches such as stochastic gradient descent (SGD) and stochastic variance reduced gradient (SVRG) descent can be applied to solve this problem, their query complexity tends to be high, especially when the number of inner component functions is large. In this paper, we apply the variance-reduced technique to derive two variance reduced algorithms that significantly improve the query complexity if the number of inner component functions is large. To the best of our knowledge, this is the first work that establishes the query complexity analysis for non-convex stochastic composition. Experiments validate the proposed algorithms and theoretical analysis.
Gradient Sparsification for Communication-Efficient Distributed Optimization
Oct 26, 2017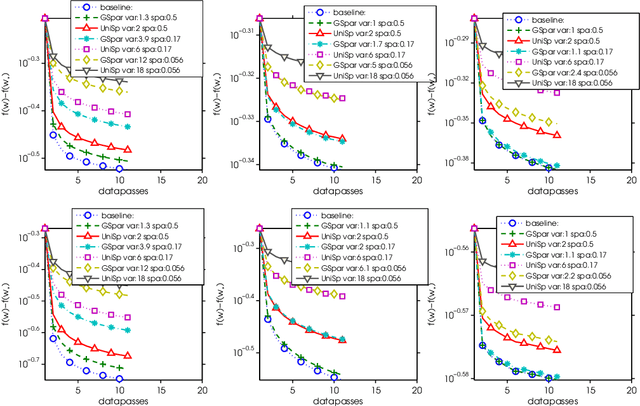
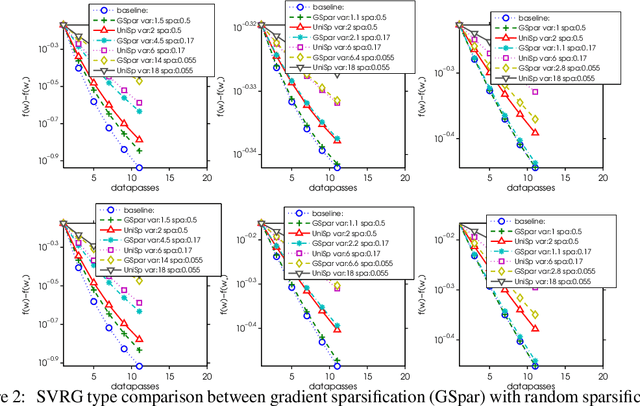
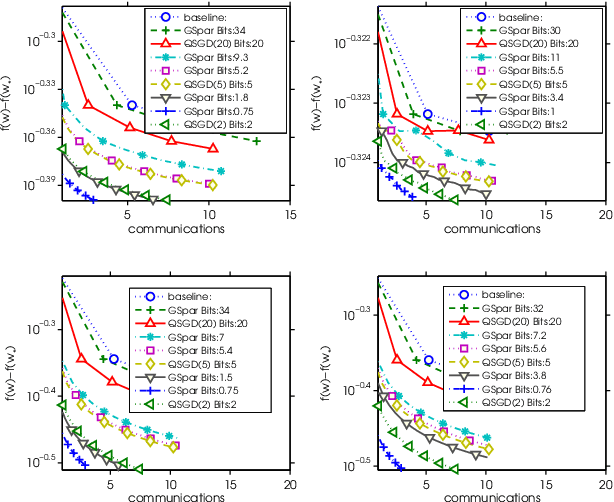
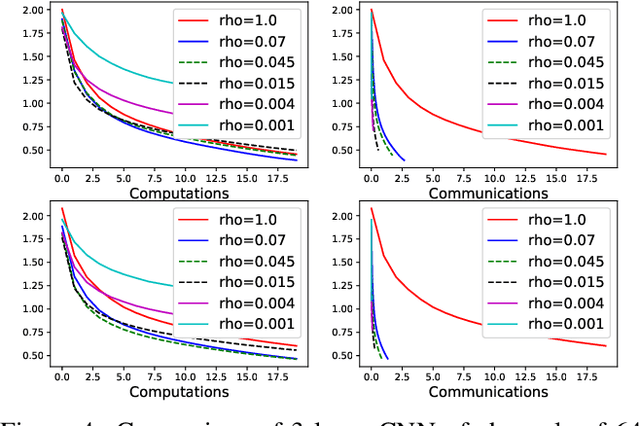
Modern large scale machine learning applications require stochastic optimization algorithms to be implemented on distributed computational architectures. A key bottleneck is the communication overhead for exchanging information such as stochastic gradients among different workers. In this paper, to reduce the communication cost we propose a convex optimization formulation to minimize the coding length of stochastic gradients. To solve the optimal sparsification efficiently, several simple and fast algorithms are proposed for approximate solution, with theoretical guaranteed for sparseness. Experiments on $\ell_2$ regularized logistic regression, support vector machines, and convolutional neural networks validate our sparsification approaches.