 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Latent Actions to Control Assistive Robots
Jul 10, 2021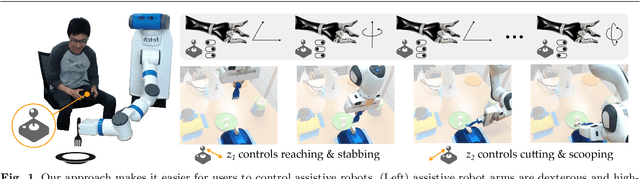

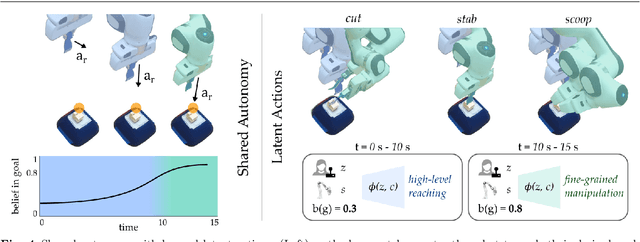
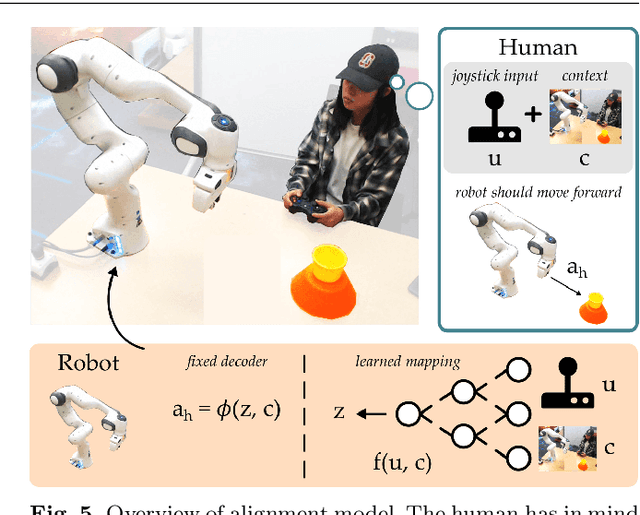
Assistive robot arms enable people with disabilities to conduct everyday tasks on their own. These arms are dexterous and high-dimensional; however, the interfaces people must use to control their robots are low-dimensional. Consider teleoperating a 7-DoF robot arm with a 2-DoF joystick. The robot is helping you eat dinner, and currently you want to cut a piece of tofu. Today's robots assume a pre-defined mapping between joystick inputs and robot actions: in one mode the joystick controls the robot's motion in the x-y plane, in another mode the joystick controls the robot's z-yaw motion, and so on. But this mapping misses out on the task you are trying to perform! Ideally, one joystick axis should control how the robot stabs the tofu and the other axis should control different cutting motions. Our insight is that we can achieve intuitive, user-friendly control of assistive robots by embedding the robot's high-dimensional actions into low-dimensional and human-controllable latent actions. We divide this process into three parts. First, we explore models for learning latent actions from offline task demonstrations, and formalize the properties that latent actions should satisfy. Next, we combine learned latent actions with autonomous robot assistance to help the user reach and maintain their high-level goals. Finally, we learn a personalized alignment model between joystick inputs and latent actions. We evaluate our resulting approach in four user studies where non-disabled participants reach marshmallows, cook apple pie, cut tofu, and assemble dessert. We then test our approach with two disabled adults who leverage assistive devices on a daily basis.
XIRL: Cross-embodiment Inverse Reinforcement Learning
Jun 07, 2021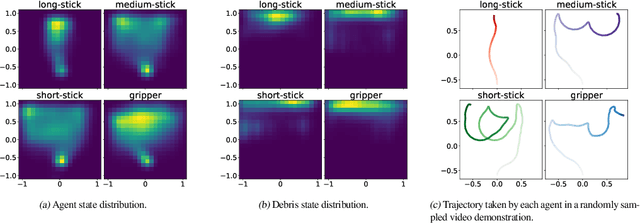

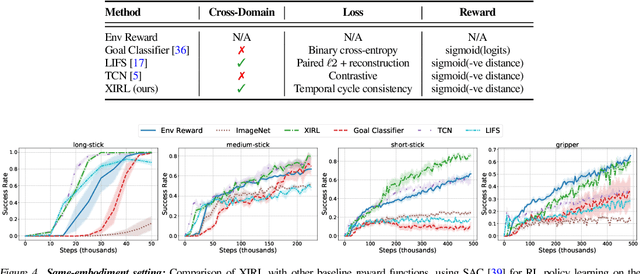
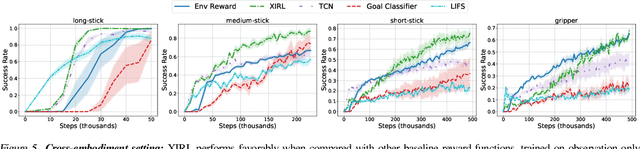
We investigate the visual cross-embodiment imitation setting, in which agents learn policies from videos of other agents (such as humans) demonstrating the same task, but with stark differences in their embodiments -- shape, actions, end-effector dynamics, etc. In this work, we demonstrate that it is possible to automatically discover and learn vision-based reward functions from cross-embodiment demonstration videos that are robust to these differences. Specifically, we present a self-supervised method for Cross-embodiment Inverse Reinforcement Learning (XIRL) that leverages temporal cycle-consistency constraints to learn deep visual embeddings that capture task progression from offline videos of demonstrations across multiple expert agents, each performing the same task differently due to embodiment differences. Prior to our work, producing rewards from self-supervised embeddings has typically required alignment with a reference trajectory, which may be difficult to acquire. We show empirically that if the embeddings are aware of task-progress, simply taking the negative distance between the current state and goal state in the learned embedding space is useful as a reward for training policies with reinforcement learning. We find our learned reward function not only works for embodiments seen during training, but also generalizes to entirely new embodiments. We also find that XIRL policies are more sample efficient than baselines, and in some cases exceed the sample efficiency of the same agent trained with ground truth sparse rewards.
Differentiable Factor Graph Optimization for Learning Smoothers
May 20, 2021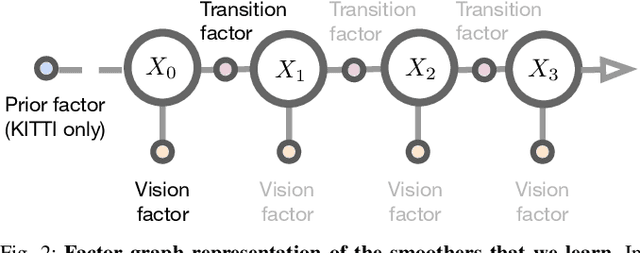
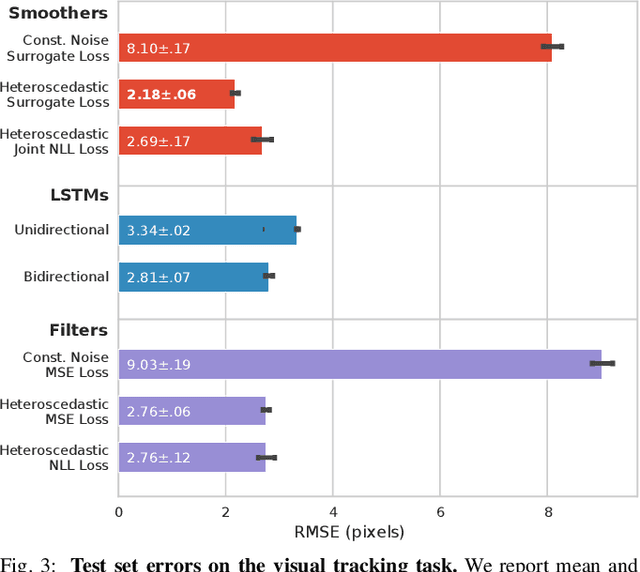
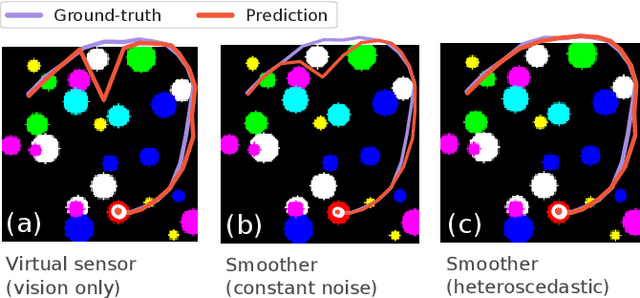
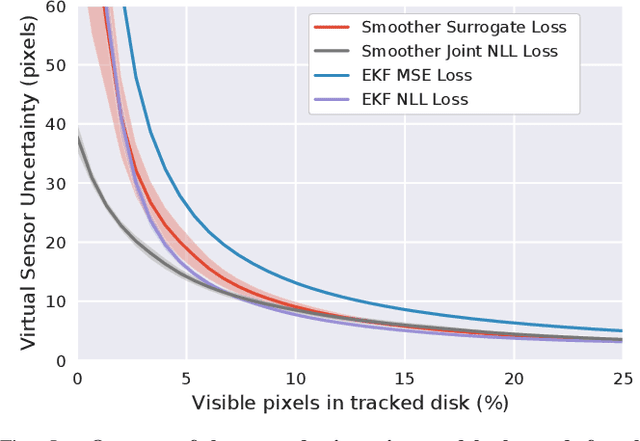
A recent line of work has shown that end-to-end optimization of Bayesian filters can be used to learn state estimators for systems whose underlying models are difficult to hand-design or tune, while retaining the core advantages of probabilistic state estimation. As an alternative approach for state estimation in these settings, we present an end-to-end approach for learning state estimators modeled as factor graph-based smoothers. By unrolling the optimizer we use for maximum a posteriori inference in these probabilistic graphical models, this method is able to learn probabilistic system models in the full context of an overall state estimator, while also taking advantage of the distinct accuracy and runtime advantages that smoothers offer over recursive filters. We study our approach using two fundamental state estimation problems, object tracking and visual odometry, where we demonstrate a significant improvement over existing baselines. Our work comes with an extensive code release, which includes the evaluated models and libraries for differentiable Lie theory and factor graph optimization: https://sites.google.com/view/diffsmoothing/
OmniHang: Learning to Hang Arbitrary Objects using Contact Point Correspondences and Neural Collision Estimation
Mar 26, 2021
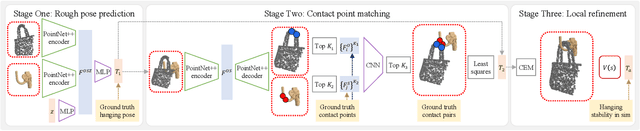
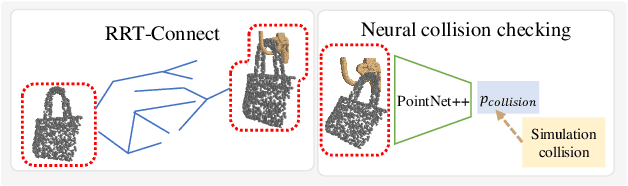
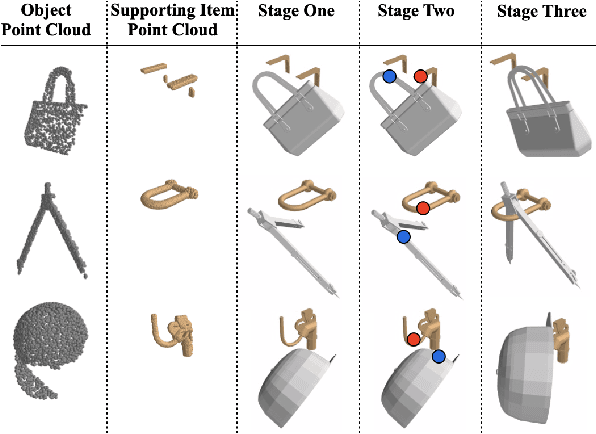
In this paper, we explore whether a robot can learn to hang arbitrary objects onto a diverse set of supporting items such as racks or hooks. Endowing robots with such an ability has applications in many domains such as domestic services, logistics, or manufacturing. Yet, it is a challenging manipulation task due to the large diversity of geometry and topology of everyday objects. In this paper, we propose a system that takes partial point clouds of an object and a supporting item as input and learns to decide where and how to hang the object stably. Our system learns to estimate the contact point correspondences between the object and supporting item to get an estimated stable pose. We then run a deep reinforcement learning algorithm to refine the predicted stable pose. Then, the robot needs to find a collision-free path to move the object from its initial pose to stable hanging pose. To this end, we train a neural network based collision estimator that takes as input partial point clouds of the object and supporting item. We generate a new and challenging, large-scale, synthetic dataset annotated with stable poses of objects hung on various supporting items and their contact point correspondences. In this dataset, we show that our system is able to achieve a 68.3% success rate of predicting stable object poses and has a 52.1% F1 score in terms of finding feasible paths. Supplemental material and videos are available on our project webpage.
Interpreting Contact Interactions to Overcome Failure in Robot Assembly Tasks
Jan 07, 2021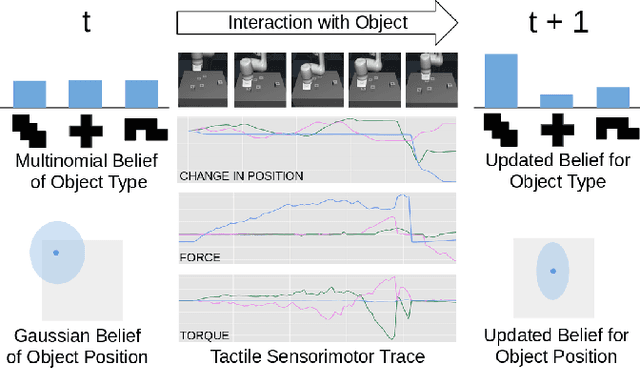
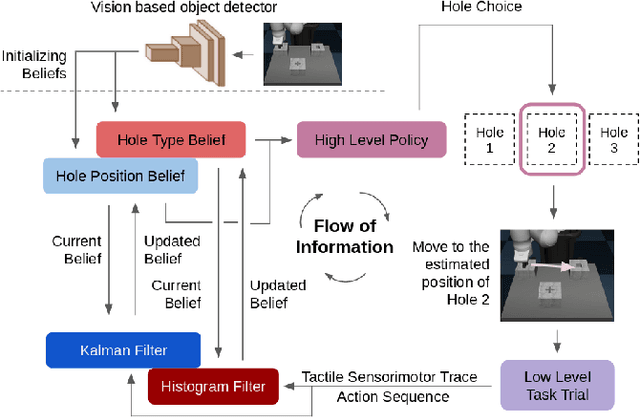
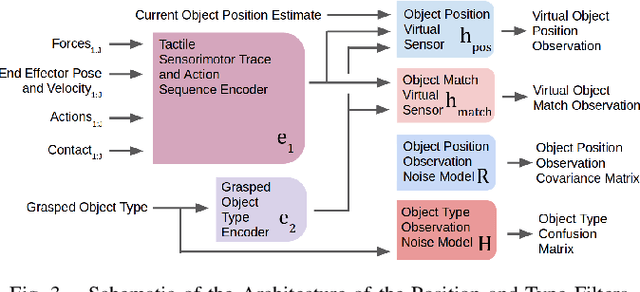
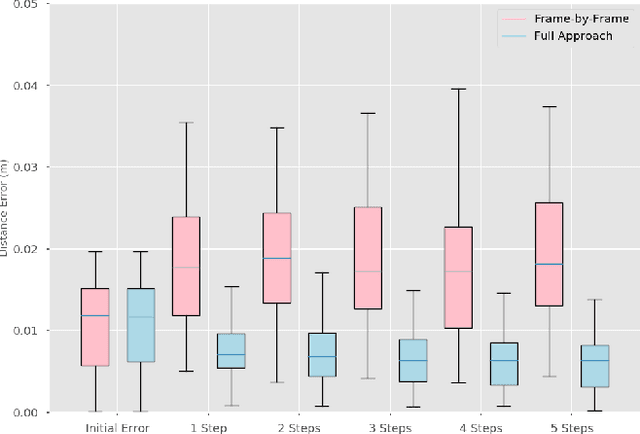
A key challenge towards the goal of multi-part assembly tasks is finding robust sensorimotor control methods in the presence of uncertainty. In contrast to previous works that rely on a priori knowledge on whether two parts match, we aim to learn this through physical interaction. We propose a hierachical approach that enables a robot to autonomously assemble parts while being uncertain about part types and positions. In particular, our probabilistic approach learns a set of differentiable filters that leverage the tactile sensorimotor trace from failed assembly attempts to update its belief about part position and type. This enables a robot to overcome assembly failure. We demonstrate the effectiveness of our approach on a set of object fitting tasks. The experimental results indicate that our proposed approach achieves higher precision in object position and type estimation, and accomplishes object fitting tasks faster than baselines.
How to Train Your Differentiable Filter
Dec 28, 2020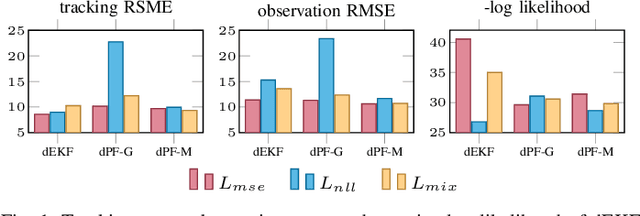
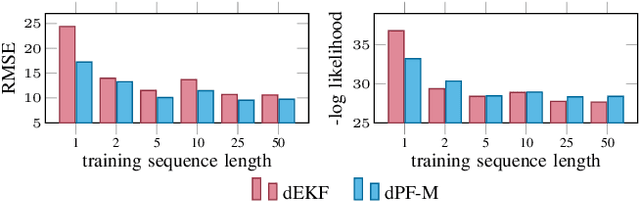

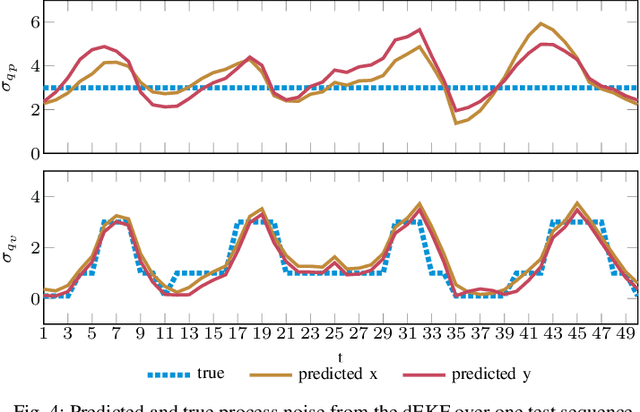
In many robotic applications, it is crucial to maintain a belief about the state of a system, which serves as input for planning and decision making and provides feedback during task execution. Bayesian Filtering algorithms address this state estimation problem, but they require models of process dynamics and sensory observations and the respective noise characteristics of these models. Recently, multiple works have demonstrated that these models can be learned by end-to-end training through differentiable versions of recursive filtering algorithms. In this work, we investigate the advantages of differentiable filters (DFs) over both unstructured learning approaches and manually-tuned filtering algorithms, and provide practical guidance to researchers interested in applying such differentiable filters. For this, we implement DFs with four different underlying filtering algorithms and compare them in extensive experiments. Specifically, we (i) evaluate different implementation choices and training approaches, (ii) investigate how well complex models of uncertainty can be learned in DFs, (iii) evaluate the effect of end-to-end training through DFs and (iv) compare the DFs among each other and to unstructured LSTM models.
Probabilistic 3D Multi-Modal, Multi-Object Tracking for Autonomous Driving
Dec 26, 2020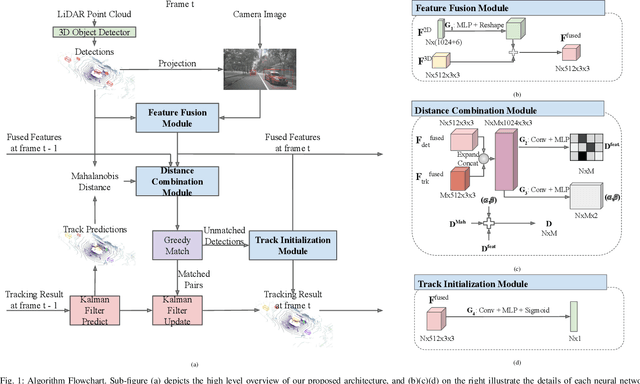



Multi-object tracking is an important ability for an autonomous vehicle to safely navigate a traffic scene. Current state-of-the-art follows the tracking-by-detection paradigm where existing tracks are associated with detected objects through some distance metric. The key challenges to increase tracking accuracy lie in data association and track life cycle management. We propose a probabilistic, multi-modal, multi-object tracking system consisting of different trainable modules to provide robust and data-driven tracking results. First, we learn how to fuse features from 2D images and 3D LiDAR point clouds to capture the appearance and geometric information of an object. Second, we propose to learn a metric that combines the Mahalanobis and feature distances when comparing a track and a new detection in data association. And third, we propose to learn when to initialize a track from an unmatched object detection. Through extensive quantitative and qualitative results, we show that our method outperforms current state-of-the-art on the NuScenes Tracking dataset.
Detect, Reject, Correct: Crossmodal Compensation of Corrupted Sensors
Dec 01, 2020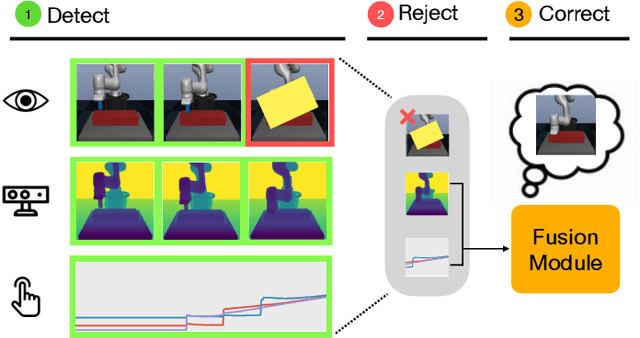
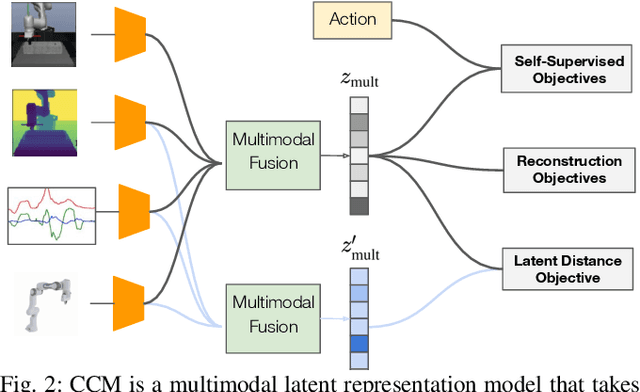
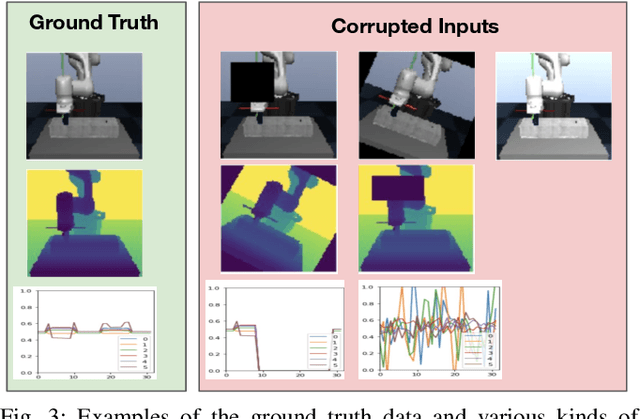
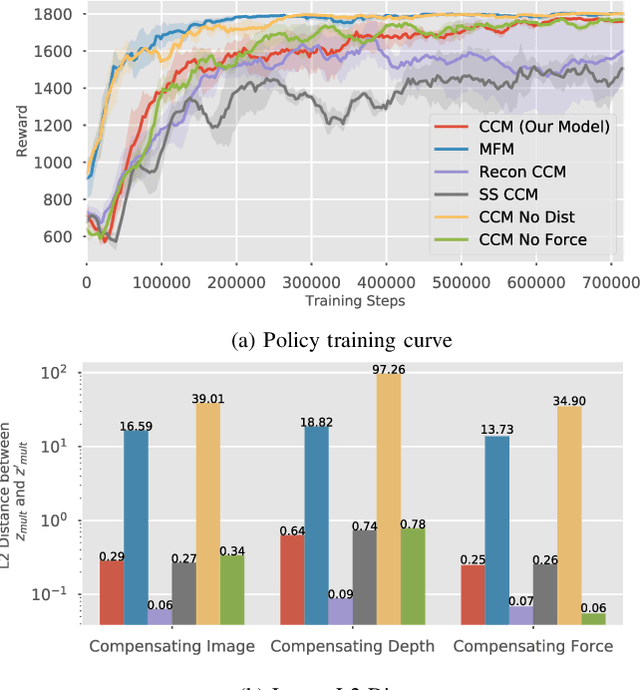
Using sensor data from multiple modalities presents an opportunity to encode redundant and complementary features that can be useful when one modality is corrupted or noisy. Humans do this everyday, relying on touch and proprioceptive feedback in visually-challenging environments. However, robots might not always know when their sensors are corrupted, as even broken sensors can return valid values. In this work, we introduce the Crossmodal Compensation Model (CCM), which can detect corrupted sensor modalities and compensate for them. CMM is a representation model learned with self-supervision that leverages unimodal reconstruction loss for corruption detection. CCM then discards the corrupted modality and compensates for it with information from the remaining sensors. We show that CCM learns rich state representations that can be used for contact-rich manipulation policies, even when input modalities are corrupted in ways not seen during training time.
Multimodal Sensor Fusion with Differentiable Filters
Oct 25, 2020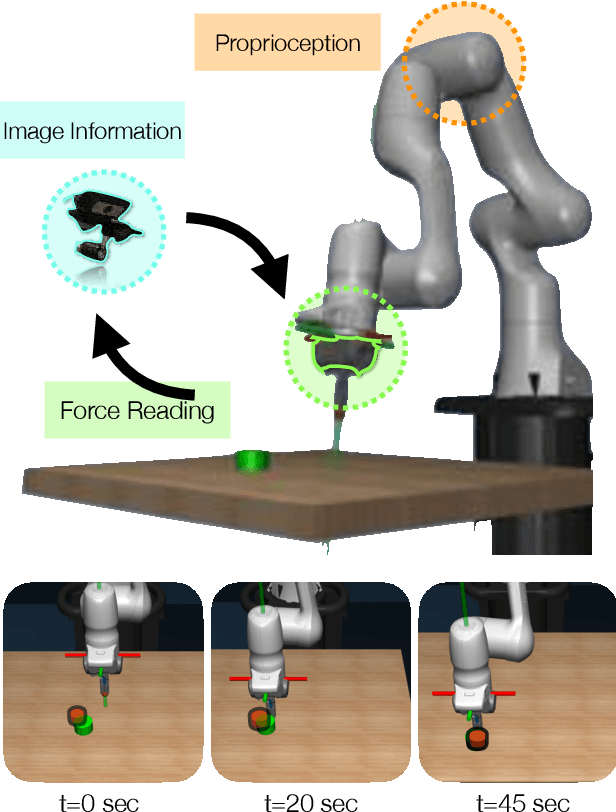
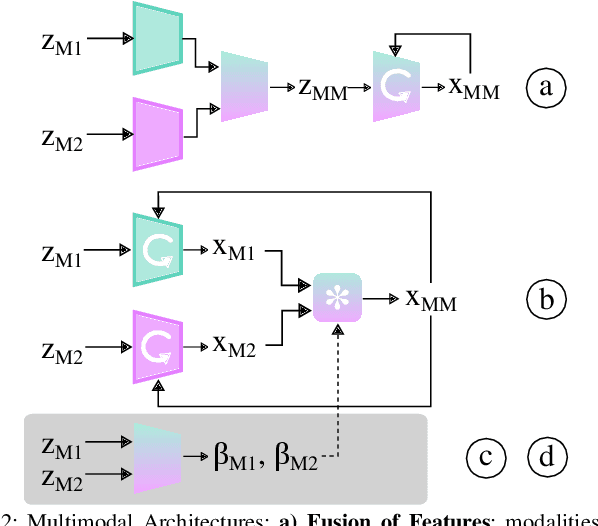
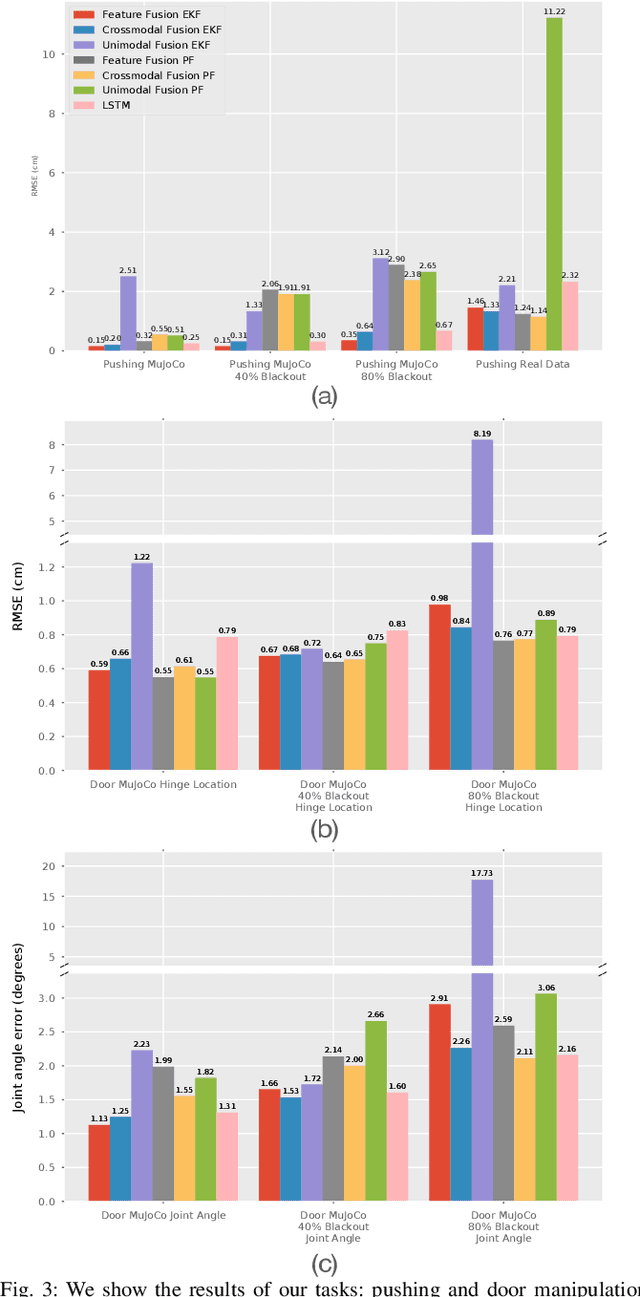
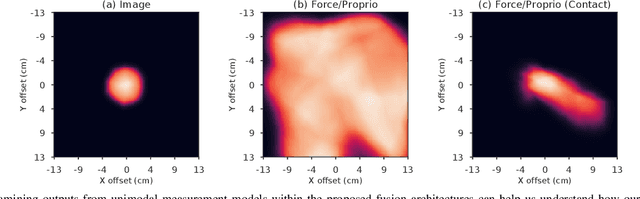
Leveraging multimodal information with recursive Bayesian filters improves performance and robustness of state estimation, as recursive filters can combine different modalities according to their uncertainties. Prior work has studied how to optimally fuse different sensor modalities with analytical state estimation algorithms. However, deriving the dynamics and measurement models along with their noise profile can be difficult or lead to intractable models. Differentiable filters provide a way to learn these models end-to-end while retaining the algorithmic structure of recursive filters. This can be especially helpful when working with sensor modalities that are high dimensional and have very different characteristics. In contact-rich manipulation, we want to combine visual sensing (which gives us global information) with tactile sensing (which gives us local information). In this paper, we study new differentiable filtering architectures to fuse heterogeneous sensor information. As case studies, we evaluate three tasks: two in planar pushing (simulated and real) and one in manipulating a kinematically constrained door (simulated). In extensive evaluations, we find that differentiable filters that leverage crossmodal sensor information reach comparable accuracies to unstructured LSTM models, while presenting interpretability benefits that may be important for safety-critical systems. We also release an open-source library for creating and training differentiable Bayesian filters in PyTorch, which can be found on our project website: https://sites.google.com/view/ multimodalfilter.
GRAC: Self-Guided and Self-Regularized Actor-Critic
Sep 18, 2020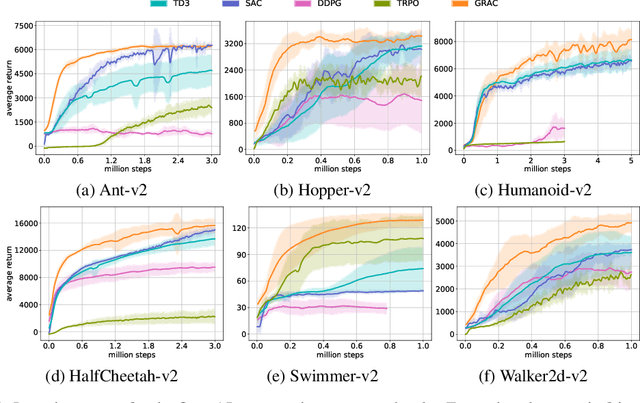
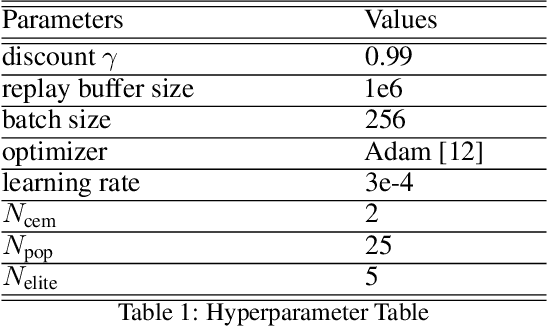
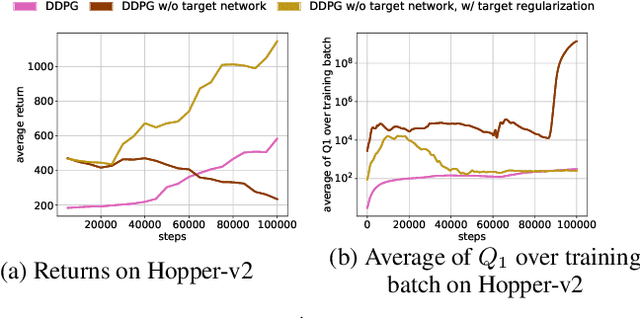
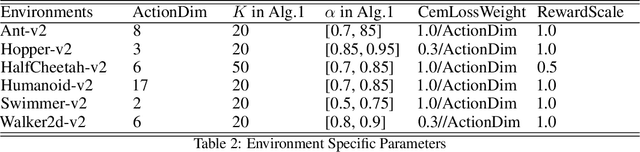
Deep reinforcement learning (DRL) algorithms have successfully been demonstrated on a range of challenging decision making and control tasks. One dominant component of recent deep reinforcement learning algorithms is the target network which mitigates the divergence when learning the Q function. However, target networks can slow down the learning process due to delayed function updates. Another dominant component especially in continuous domains is the policy gradient method which models and optimizes the policy directly. However, when Q functions are approximated with neural networks, their landscapes can be complex and therefore mislead the local gradient. In this work, we propose a self-regularized and self-guided actor-critic method. We introduce a self-regularization term within the TD-error minimization and remove the need for the target network. In addition, we propose a self-guided policy improvement method by combining policy-gradient with zero-order optimization such as the Cross Entropy Method. It helps to search for actions associated with higher Q-values in a broad neighborhood and is robust to local noise in the Q function approximation. These actions help to guide the updates of our actor network. We evaluate our method on the suite of OpenAI gym tasks, achieving or outperforming state of the art in every environment tested.