 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Codomain Attention Neural Operators for Solving Multiphysics PDEs
Mar 19, 2024



Existing neural operator architectures face challenges when solving multiphysics problems with coupled partial differential equations (PDEs), due to complex geometries, interactions between physical variables, and the lack of large amounts of high-resolution training data. To address these issues, we propose Codomain Attention Neural Operator (CoDA-NO), which tokenizes functions along the codomain or channel space, enabling self-supervised learning or pretraining of multiple PDE systems. Specifically, we extend positional encoding, self-attention, and normalization layers to the function space. CoDA-NO can learn representations of different PDE systems with a single model. We evaluate CoDA-NO's potential as a backbone for learning multiphysics PDEs over multiple systems by considering few-shot learning settings. On complex downstream tasks with limited data, such as fluid flow simulations and fluid-structure interactions, we found CoDA-NO to outperform existing methods on the few-shot learning task by over $36\%$. The code is available at https://github.com/ashiq24/CoDA-NO.
Equivariant Graph Neural Operator for Modeling 3D Dynamics
Jan 19, 2024



Modeling the complex three-dimensional (3D) dynamics of relational systems is an important problem in the natural sciences, with applications ranging from molecular simulations to particle mechanics. Machine learning methods have achieved good success by learning graph neural networks to model spatial interactions. However, these approaches do not faithfully capture temporal correlations since they only model next-step predictions. In this work, we propose Equivariant Graph Neural Operator (EGNO), a novel and principled method that directly models dynamics as trajectories instead of just next-step prediction. Different from existing methods, EGNO explicitly learns the temporal evolution of 3D dynamics where we formulate the dynamics as a function over time and learn neural operators to approximate it. To capture the temporal correlations while keeping the intrinsic SE(3)-equivariance, we develop equivariant temporal convolutions parameterized in the Fourier space and build EGNO by stacking the Fourier layers over equivariant networks. EGNO is the first operator learning framework that is capable of modeling solution dynamics functions over time while retaining 3D equivariance. Comprehensive experiments in multiple domains, including particle simulations, human motion capture, and molecular dynamics, demonstrate the significantly superior performance of EGNO against existing methods, thanks to the equivariant temporal modeling.
Multi-Grid Tensorized Fourier Neural Operator for High-Resolution PDEs
Sep 29, 2023Memory complexity and data scarcity have so far prohibited learning solution operators of partial differential equations (PDEs) at high resolutions. We address these limitations by introducing a new data efficient and highly parallelizable operator learning approach with reduced memory requirement and better generalization, called multi-grid tensorized neural operator (MG-TFNO). MG-TFNO scales to large resolutions by leveraging local and global structures of full-scale, real-world phenomena, through a decomposition of both the input domain and the operator's parameter space. Our contributions are threefold: i) we enable parallelization over input samples with a novel multi-grid-based domain decomposition, ii) we represent the parameters of the model in a high-order latent subspace of the Fourier domain, through a global tensor factorization, resulting in an extreme reduction in the number of parameters and improved generalization, and iii) we propose architectural improvements to the backbone FNO. Our approach can be used in any operator learning setting. We demonstrate superior performance on the turbulent Navier-Stokes equations where we achieve less than half the error with over 150x compression. The tensorization combined with the domain decomposition, yields over 150x reduction in the number of parameters and 7x reduction in the domain size without losses in accuracy, while slightly enabling parallelism.
Neural Operators for Accelerating Scientific Simulations and Design
Sep 27, 2023Scientific discovery and engineering design are currently limited by the time and cost of physical experiments, selected mostly through trial-and-error and intuition that require deep domain expertise. Numerical simulations present an alternative to physical experiments, but are usually infeasible for complex real-world domains due to the computational requirements of existing numerical methods. Artificial intelligence (AI) presents a potential paradigm shift through the development of fast data-driven surrogate models. In particular, an AI framework, known as neural operators, presents a principled framework for learning mappings between functions defined on continuous domains, e.g., spatiotemporal processes and partial differential equations (PDE). They can extrapolate and predict solutions at new locations unseen during training, i.e., perform zero-shot super-resolution. Neural operators can augment or even replace existing simulators in many applications, such as computational fluid dynamics, weather forecasting, and material modeling, while being 4-5 orders of magnitude faster. Further, neural operators can be integrated with physics and other domain constraints enforced at finer resolutions to obtain high-fidelity solutions and good generalization. Since neural operators are differentiable, they can directly optimize parameters for inverse design and other inverse problems. We believe that neural operators present a transformative approach to simulation and design, enabling rapid research and development.
Geometry-Informed Neural Operator for Large-Scale 3D PDEs
Sep 01, 2023



We propose the geometry-informed neural operator (GINO), a highly efficient approach to learning the solution operator of large-scale partial differential equations with varying geometries. GINO uses a signed distance function and point-cloud representations of the input shape and neural operators based on graph and Fourier architectures to learn the solution operator. The graph neural operator handles irregular grids and transforms them into and from regular latent grids on which Fourier neural operator can be efficiently applied. GINO is discretization-convergent, meaning the trained model can be applied to arbitrary discretization of the continuous domain and it converges to the continuum operator as the discretization is refined. To empirically validate the performance of our method on large-scale simulation, we generate the industry-standard aerodynamics dataset of 3D vehicle geometries with Reynolds numbers as high as five million. For this large-scale 3D fluid simulation, numerical methods are expensive to compute surface pressure. We successfully trained GINO to predict the pressure on car surfaces using only five hundred data points. The cost-accuracy experiments show a $26,000 \times$ speed-up compared to optimized GPU-based computational fluid dynamics (CFD) simulators on computing the drag coefficient. When tested on new combinations of geometries and boundary conditions (inlet velocities), GINO obtains a one-fourth reduction in error rate compared to deep neural network approaches.
Speeding up Fourier Neural Operators via Mixed Precision
Jul 27, 2023



The Fourier neural operator (FNO) is a powerful technique for learning surrogate maps for partial differential equation (PDE) solution operators. For many real-world applications, which often require high-resolution data points, training time and memory usage are significant bottlenecks. While there are mixed-precision training techniques for standard neural networks, those work for real-valued datatypes on finite dimensions and therefore cannot be directly applied to FNO, which crucially operates in the (complex-valued) Fourier domain and in function spaces. On the other hand, since the Fourier transform is already an approximation (due to discretization error), we do not need to perform the operation at full precision. In this work, we (i) profile memory and runtime for FNO with full and mixed-precision training, (ii) conduct a study on the numerical stability of mixed-precision training of FNO, and (iii) devise a training routine which substantially decreases training time and memory usage (up to 34%), with little or no reduction in accuracy, on the Navier-Stokes and Darcy flow equations. Combined with the recently proposed tensorized FNO (Kossaifi et al., 2023), the resulting model has far better performance while also being significantly faster than the original FNO.
Score-based Diffusion Models in Function Space
Feb 14, 2023



Diffusion models have recently emerged as a powerful framework for generative modeling. They consist of a forward process that perturbs input data with Gaussian white noise and a reverse process that learns a score function to generate samples by denoising. Despite their tremendous success, they are mostly formulated on finite-dimensional spaces, e.g. Euclidean, limiting their applications to many domains where the data has a functional form such as in scientific computing and 3D geometric data analysis. In this work, we introduce a mathematically rigorous framework called Denoising Diffusion Operators (DDOs) for training diffusion models in function space. In DDOs, the forward process perturbs input functions gradually using a Gaussian process. The generative process is formulated by integrating a function-valued Langevin dynamic. Our approach requires an appropriate notion of the score for the perturbed data distribution, which we obtain by generalizing denoising score matching to function spaces that can be infinite-dimensional. We show that the corresponding discretized algorithm generates accurate samples at a fixed cost that is independent of the data resolution. We theoretically and numerically verify the applicability of our approach on a set of problems, including generating solutions to the Navier-Stokes equation viewed as the push-forward distribution of forcings from a Gaussian Random Field (GRF).
HEAT: Hardware-Efficient Automatic Tensor Decomposition for Transformer Compression
Nov 30, 2022



Transformers have attained superior performance in natural language processing and computer vision. Their self-attention and feedforward layers are overparameterized, limiting inference speed and energy efficiency. Tensor decomposition is a promising technique to reduce parameter redundancy by leveraging tensor algebraic properties to express the parameters in a factorized form. Prior efforts used manual or heuristic factorization settings without hardware-aware customization, resulting in poor hardware efficiencies and large performance degradation. In this work, we propose a hardware-aware tensor decomposition framework, dubbed HEAT, that enables efficient exploration of the exponential space of possible decompositions and automates the choice of tensorization shape and decomposition rank with hardware-aware co-optimization. We jointly investigate tensor contraction path optimizations and a fused Einsum mapping strategy to bridge the gap between theoretical benefits and real hardware efficiency improvement. Our two-stage knowledge distillation flow resolves the trainability bottleneck and thus significantly boosts the final accuracy of factorized Transformers. Overall, we experimentally show that our hardware-aware factorized BERT variants reduce the energy-delay product by 5.7x with less than 1.1% accuracy loss and achieve a better efficiency-accuracy Pareto frontier than hand-tuned and heuristic baselines.
Reinforcement Learning in Factored Action Spaces using Tensor Decompositions
Oct 27, 2021
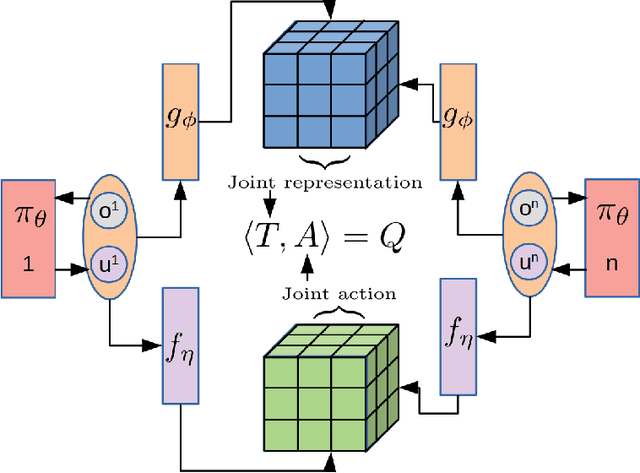
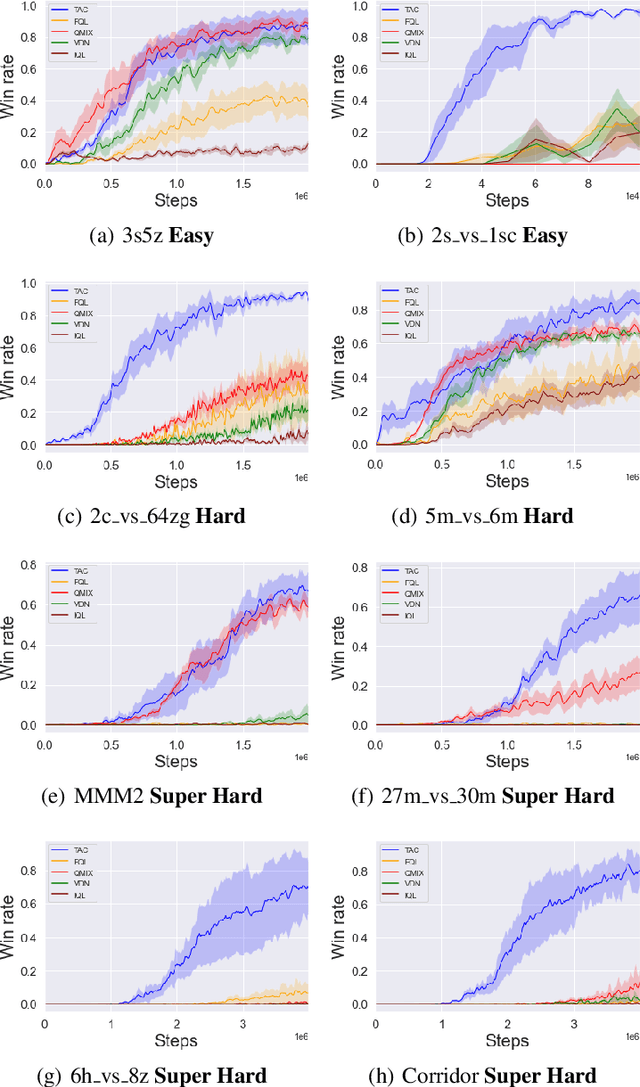
We present an extended abstract for the previously published work TESSERACT [Mahajan et al., 2021], which proposes a novel solution for Reinforcement Learning (RL) in large, factored action spaces using tensor decompositions. The goal of this abstract is twofold: (1) To garner greater interest amongst the tensor research community for creating methods and analysis for approximate RL, (2) To elucidate the generalised setting of factored action spaces where tensor decompositions can be used. We use cooperative multi-agent reinforcement learning scenario as the exemplary setting where the action space is naturally factored across agents and learning becomes intractable without resorting to approximation on the underlying hypothesis space for candidate solutions.
Defensive Tensorization
Oct 26, 2021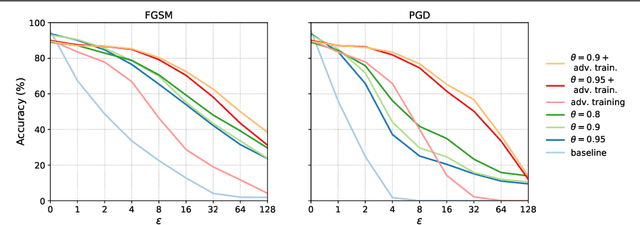
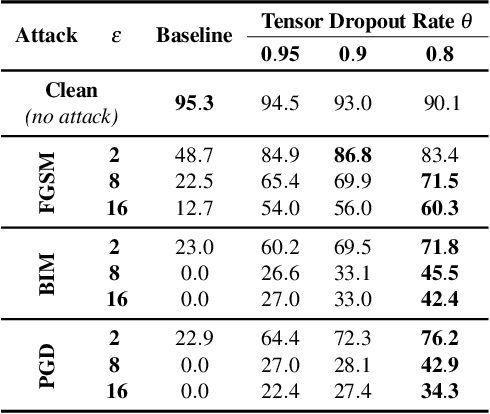
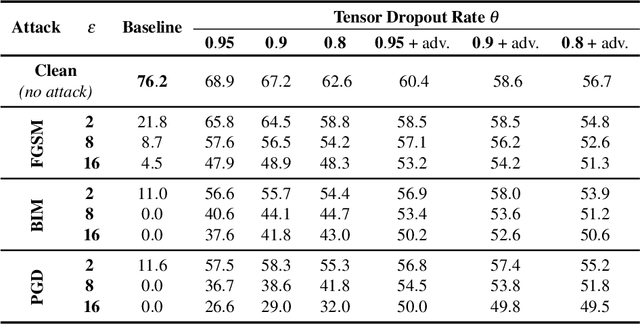
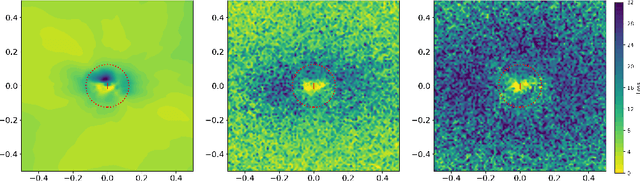
We propose defensive tensorization, an adversarial defence technique that leverages a latent high-order factorization of the network. The layers of a network are first expressed as factorized tensor layers. Tensor dropout is then applied in the latent subspace, therefore resulting in dense reconstructed weights, without the sparsity or perturbations typically induced by the randomization.Our approach can be readily integrated with any arbitrary neural architecture and combined with techniques like adversarial training. We empirically demonstrate the effectiveness of our approach on standard image classification benchmarks. We validate the versatility of our approach across domains and low-precision architectures by considering an audio classification task and binary networks. In all cases, we demonstrate improved performance compared to prior works.