 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJames Zou
Post-hoc Concept Bottleneck Models
May 31, 2022
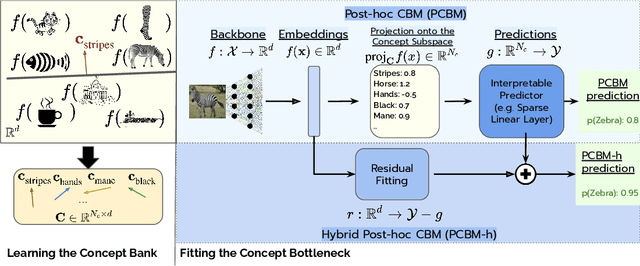
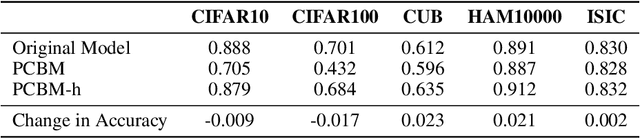
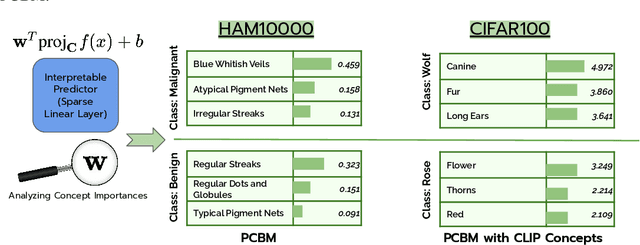

Concept Bottleneck Models (CBMs) map the inputs onto a set of interpretable concepts (``the bottleneck'') and use the concepts to make predictions. A concept bottleneck enhances interpretability since it can be investigated to understand what concepts the model "sees" in an input and which of these concepts are deemed important. However, CBMs are restrictive in practice as they require concept labels in the training data to learn the bottleneck and do not leverage strong pretrained models. Moreover, CBMs often do not match the accuracy of an unrestricted neural network, reducing the incentive to deploy them in practice. In this work, we address the limitations of CBMs by introducing Post-hoc Concept Bottleneck models (PCBMs). We show that we can turn any neural network into a PCBM without sacrificing model performance while still retaining interpretability benefits. When concept annotation is not available on the training data, we show that PCBM can transfer concepts from other datasets or from natural language descriptions of concepts. PCBM also enables users to quickly debug and update the model to reduce spurious correlations and improve generalization to new (potentially different) data. Through a model-editing user study, we show that editing PCBMs via concept-level feedback can provide significant performance gains without using any data from the target domain or model retraining.
A Unified f-divergence Framework Generalizing VAE and GAN
May 11, 2022
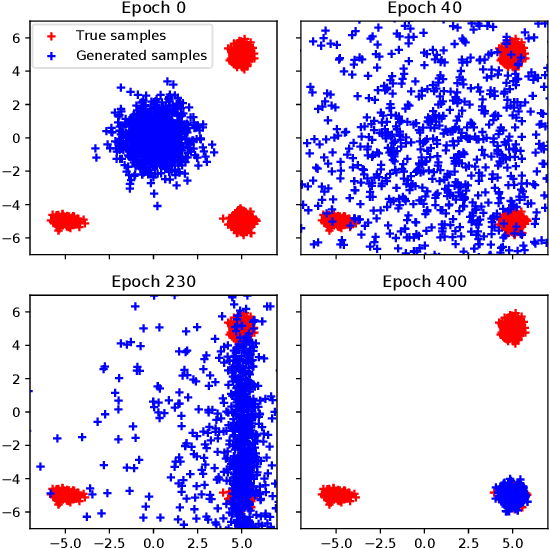
Developing deep generative models that flexibly incorporate diverse measures of probability distance is an important area of research. Here we develop an unified mathematical framework of f-divergence generative model, f-GM, that incorporates both VAE and f-GAN, and enables tractable learning with general f-divergences. f-GM allows the experimenter to flexibly design the f-divergence function without changing the structure of the networks or the learning procedure. f-GM jointly models three components: a generator, a inference network and a density estimator. Therefore it simultaneously enables sampling, posterior inference of the latent variable as well as evaluation of the likelihood of an arbitrary datum. f-GM belongs to the class of encoder-decoder GANs: our density estimator can be interpreted as playing the role of a discriminator between samples in the joint space of latent code and observed space. We prove that f-GM naturally simplifies to the standard VAE and to f-GAN as special cases, and illustrates the connections between different encoder-decoder GAN architectures. f-GM is compatible with general network architecture and optimizer. We leverage it to experimentally explore the effects -- e.g. mode collapse and image sharpness -- of different choices of f-divergence.
Improving genetic risk prediction across diverse population by disentangling ancestry representations
May 10, 2022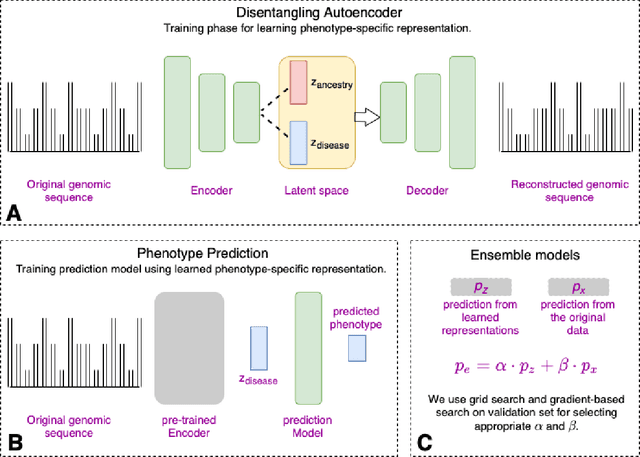
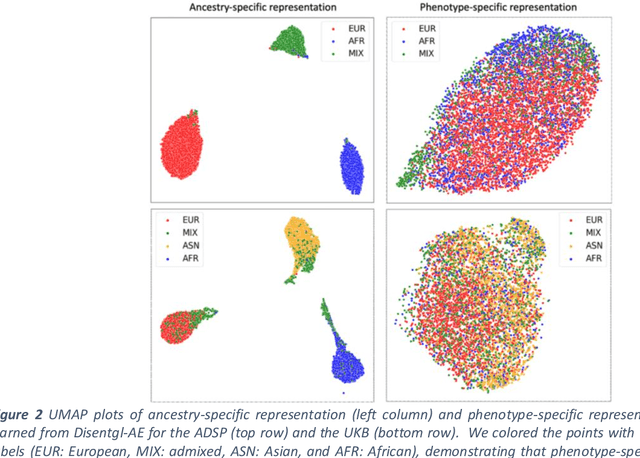
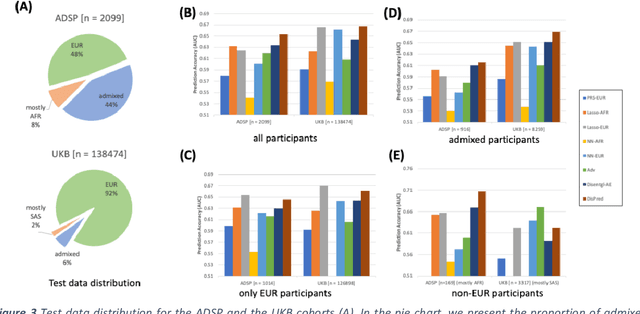
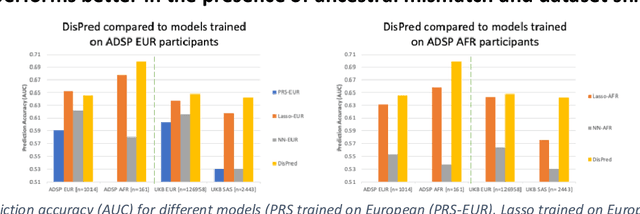
Risk prediction models using genetic data have seen increasing traction in genomics. However, most of the polygenic risk models were developed using data from participants with similar (mostly European) ancestry. This can lead to biases in the risk predictors resulting in poor generalization when applied to minority populations and admixed individuals such as African Americans. To address this bias, largely due to the prediction models being confounded by the underlying population structure, we propose a novel deep-learning framework that leverages data from diverse population and disentangles ancestry from the phenotype-relevant information in its representation. The ancestry disentangled representation can be used to build risk predictors that perform better across minority populations. We applied the proposed method to the analysis of Alzheimer's disease genetics. Comparing with standard linear and nonlinear risk prediction methods, the proposed method substantially improves risk prediction in minority populations, particularly for admixed individuals.
Domino: Discovering Systematic Errors with Cross-Modal Embeddings
Apr 11, 2022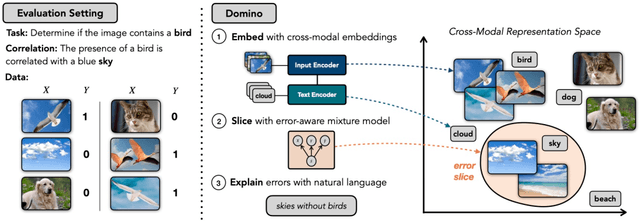
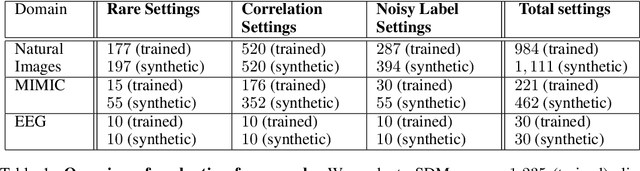
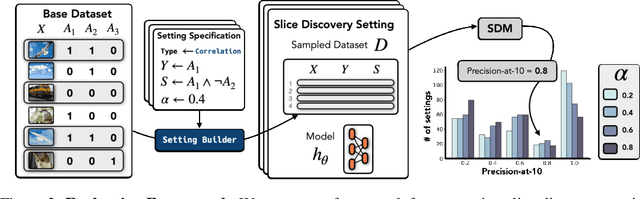
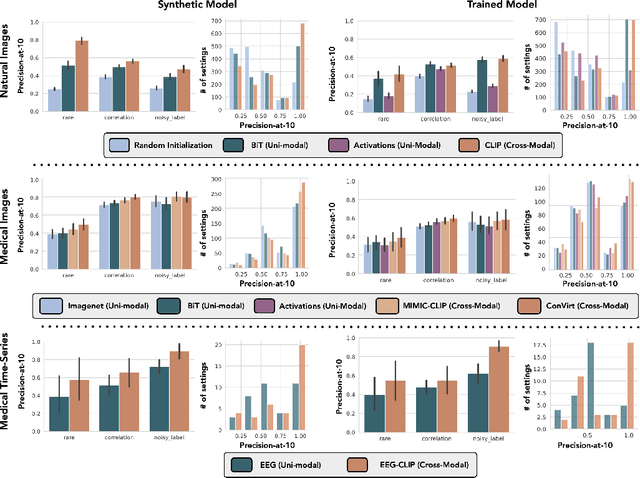
Machine learning models that achieve high overall accuracy often make systematic errors on important subsets (or slices) of data. Identifying underperforming slices is particularly challenging when working with high-dimensional inputs (e.g. images, audio), where important slices are often unlabeled. In order to address this issue, recent studies have proposed automated slice discovery methods (SDMs), which leverage learned model representations to mine input data for slices on which a model performs poorly. To be useful to a practitioner, these methods must identify slices that are both underperforming and coherent (i.e. united by a human-understandable concept). However, no quantitative evaluation framework currently exists for rigorously assessing SDMs with respect to these criteria. Additionally, prior qualitative evaluations have shown that SDMs often identify slices that are incoherent. In this work, we address these challenges by first designing a principled evaluation framework that enables a quantitative comparison of SDMs across 1,235 slice discovery settings in three input domains (natural images, medical images, and time-series data). Then, motivated by the recent development of powerful cross-modal representation learning approaches, we present Domino, an SDM that leverages cross-modal embeddings and a novel error-aware mixture model to discover and describe coherent slices. We find that Domino accurately identifies 36% of the 1,235 slices in our framework - a 12 percentage point improvement over prior methods. Further, Domino is the first SDM that can provide natural language descriptions of identified slices, correctly generating the exact name of the slice in 35% of settings.
Disparities in Dermatology AI Performance on a Diverse, Curated Clinical Image Set
Mar 15, 2022Access to dermatological care is a major issue, with an estimated 3 billion people lacking access to care globally. Artificial intelligence (AI) may aid in triaging skin diseases. However, most AI models have not been rigorously assessed on images of diverse skin tones or uncommon diseases. To ascertain potential biases in algorithm performance in this context, we curated the Diverse Dermatology Images (DDI) dataset-the first publicly available, expertly curated, and pathologically confirmed image dataset with diverse skin tones. Using this dataset of 656 images, we show that state-of-the-art dermatology AI models perform substantially worse on DDI, with receiver operator curve area under the curve (ROC-AUC) dropping by 27-36 percent compared to the models' original test results. All the models performed worse on dark skin tones and uncommon diseases, which are represented in the DDI dataset. Additionally, we find that dermatologists, who typically provide visual labels for AI training and test datasets, also perform worse on images of dark skin tones and uncommon diseases compared to ground truth biopsy annotations. Finally, fine-tuning AI models on the well-characterized and diverse DDI images closed the performance gap between light and dark skin tones. Moreover, algorithms fine-tuned on diverse skin tones outperformed dermatologists on identifying malignancy on images of dark skin tones. Our findings identify important weaknesses and biases in dermatology AI that need to be addressed to ensure reliable application to diverse patients and diseases.
Mind the Gap: Understanding the Modality Gap in Multi-modal Contrastive Representation Learning
Mar 03, 2022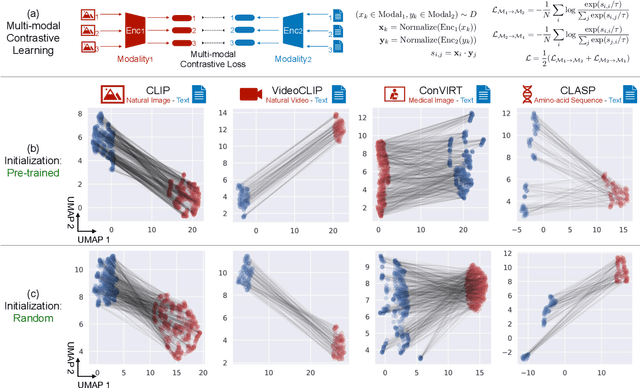

We present modality gap, an intriguing geometric phenomenon of the representation space of multi-modal models. Specifically, we show that different data modalities (e.g. images and text) are embedded at arm's length in their shared representation in multi-modal models such as CLIP. Our systematic analysis demonstrates that this gap is caused by a combination of model initialization and contrastive learning optimization. In model initialization, we show empirically and theoretically that the representation of a common deep neural network is restricted to a narrow cone. As a consequence, in a multi-modal model with two encoders, the representations of the two modalities are clearly apart when the model is initialized. During optimization, contrastive learning keeps the different modalities separate by a certain distance, which is influenced by the temperature parameter in the loss function. Our experiments further demonstrate that varying the modality gap distance has a significant impact in improving the model's downstream zero-shot classification performance and fairness. Our code and data are available at https://modalitygap.readthedocs.io/
MetaShift: A Dataset of Datasets for Evaluating Contextual Distribution Shifts and Training Conflicts
Feb 14, 2022

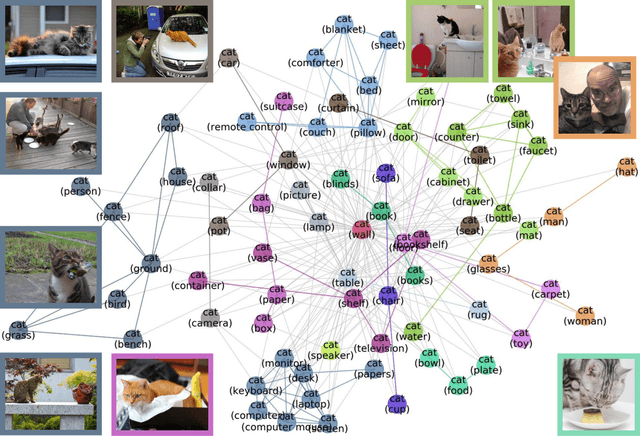
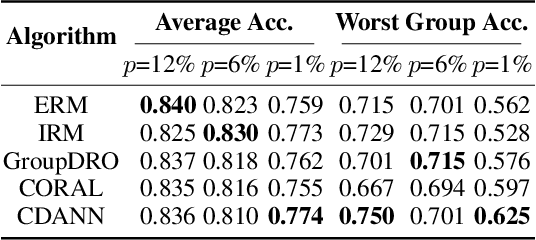
Understanding the performance of machine learning models across diverse data distributions is critically important for reliable applications. Motivated by this, there is a growing focus on curating benchmark datasets that capture distribution shifts. While valuable, the existing benchmarks are limited in that many of them only contain a small number of shifts and they lack systematic annotation about what is different across different shifts. We present MetaShift--a collection of 12,868 sets of natural images across 410 classes--to address this challenge. We leverage the natural heterogeneity of Visual Genome and its annotations to construct MetaShift. The key construction idea is to cluster images using its metadata, which provides context for each image (e.g. "cats with cars" or "cats in bathroom") that represent distinct data distributions. MetaShift has two important benefits: first, it contains orders of magnitude more natural data shifts than previously available. Second, it provides explicit explanations of what is unique about each of its data sets and a distance score that measures the amount of distribution shift between any two of its data sets. We demonstrate the utility of MetaShift in benchmarking several recent proposals for training models to be robust to data shifts. We find that the simple empirical risk minimization performs the best when shifts are moderate and no method had a systematic advantage for large shifts. We also show how MetaShift can help to visualize conflicts between data subsets during model training.
Uncalibrated Models Can Improve Human-AI Collaboration
Feb 12, 2022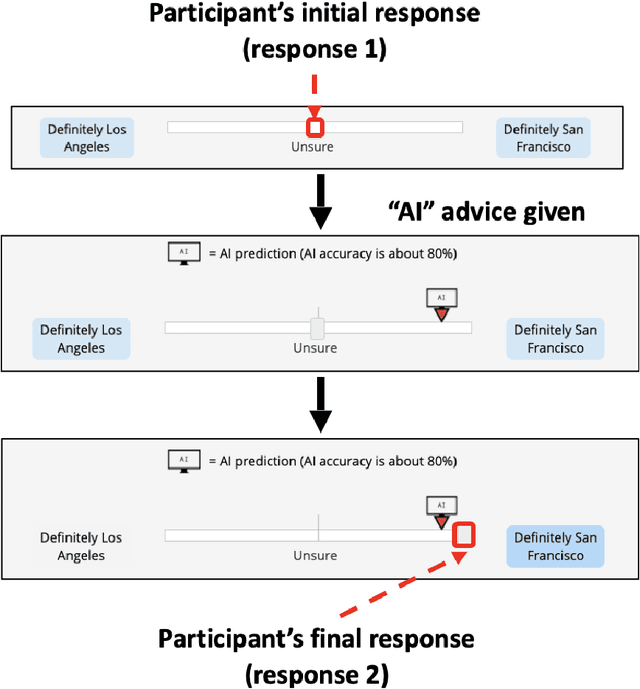
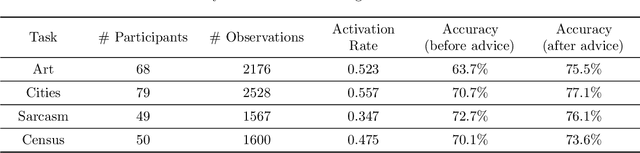


In many practical applications of AI, an AI model is used as a decision aid for human users. The AI provides advice that a human (sometimes) incorporates into their decision-making process. The AI advice is often presented with some measure of "confidence" that the human can use to calibrate how much they depend on or trust the advice. In this paper, we demonstrate that presenting AI models as more confident than they actually are, even when the original AI is well-calibrated, can improve human-AI performance (measured as the accuracy and confidence of the human's final prediction after seeing the AI advice). We first learn a model for how humans incorporate AI advice using data from thousands of human interactions. This enables us to explicitly estimate how to transform the AI's prediction confidence, making the AI uncalibrated, in order to improve the final human prediction. We empirically validate our results across four different tasks -- dealing with images, text and tabular data -- involving hundreds of human participants. We further support our findings with simulation analysis. Our findings suggest the importance of and a framework for jointly optimizing the human-AI system as opposed to the standard paradigm of optimizing the AI model alone.
Competition over data: how does data purchase affect users?
Jan 26, 2022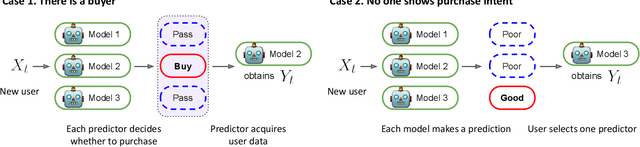
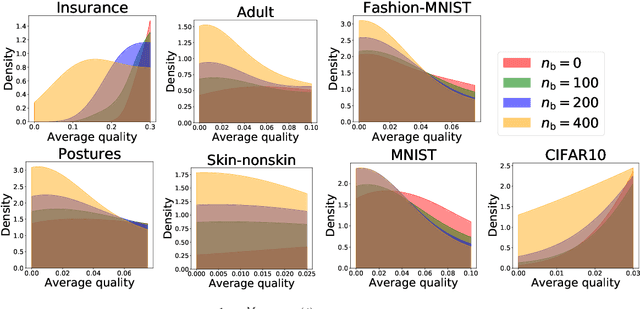
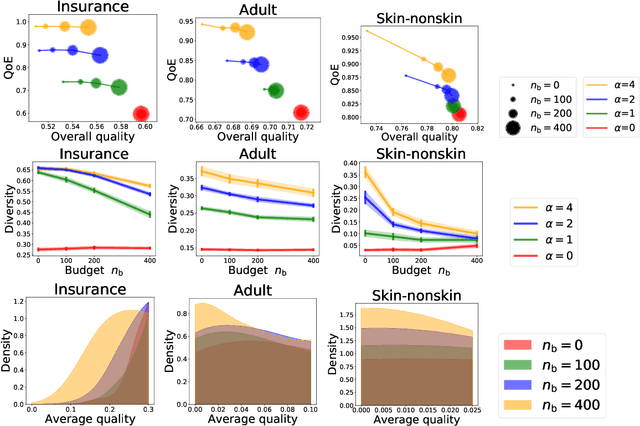
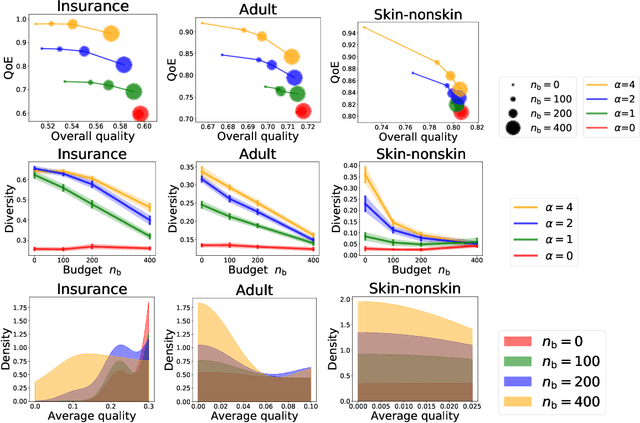
As machine learning (ML) is deployed by many competing service providers, the underlying ML predictors also compete against each other, and it is increasingly important to understand the impacts and biases from such competition. In this paper, we study what happens when the competing predictors can acquire additional labeled data to improve their prediction quality. We introduce a new environment that allows ML predictors to use active learning algorithms to purchase labeled data within their budgets while competing against each other to attract users. Our environment models a critical aspect of data acquisition in competing systems which has not been well-studied before. We found that the overall performance of an ML predictor improves when predictors can purchase additional labeled data. Surprisingly, however, the quality that users experience -- i.e. the accuracy of the predictor selected by each user -- can decrease even as the individual predictors get better. We show that this phenomenon naturally arises due to a trade-off whereby competition pushes each predictor to specialize in a subset of the population while data purchase has the effect of making predictors more uniform. We support our findings with both experiments and theories.
Submix: Practical Private Prediction for Large-Scale Language Models
Jan 04, 2022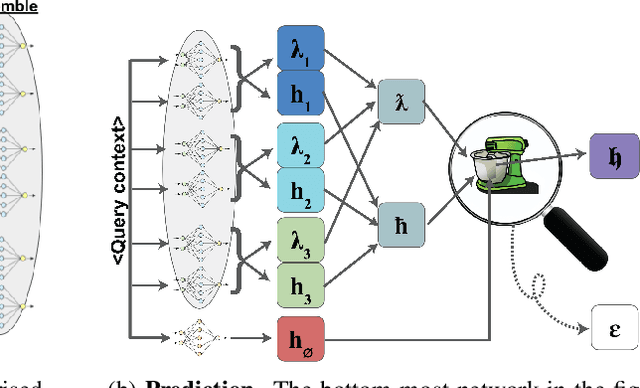

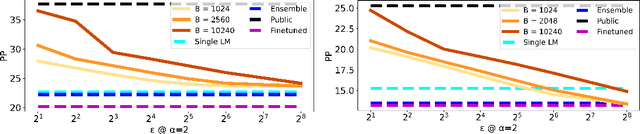
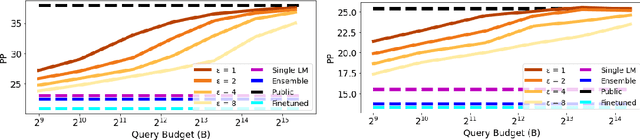
Recent data-extraction attacks have exposed that language models can memorize some training samples verbatim. This is a vulnerability that can compromise the privacy of the model's training data. In this work, we introduce SubMix: a practical protocol for private next-token prediction designed to prevent privacy violations by language models that were fine-tuned on a private corpus after pre-training on a public corpus. We show that SubMix limits the leakage of information that is unique to any individual user in the private corpus via a relaxation of group differentially private prediction. Importantly, SubMix admits a tight, data-dependent privacy accounting mechanism, which allows it to thwart existing data-extraction attacks while maintaining the utility of the language model. SubMix is the first protocol that maintains privacy even when publicly releasing tens of thousands of next-token predictions made by large transformer-based models such as GPT-2.