 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Obstacle Representations for Neural Motion Planning
Aug 29, 2020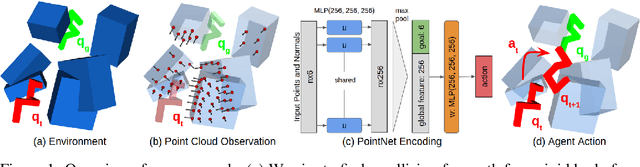
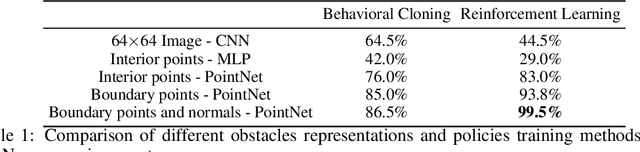

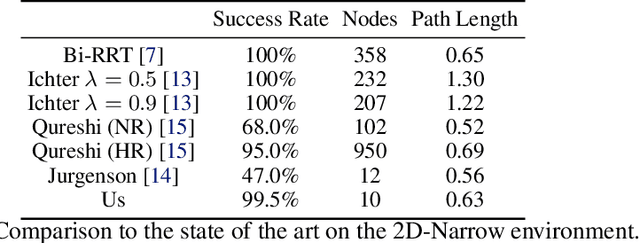
Motion planning and obstacle avoidance is a key challenge in robotics applications. While previous work succeeds to provide excellent solutions for known environments, sensor-based motion planning in new and dynamic environments remains difficult. In this work we address sensor-based motion planning from a learning perspective. Motivated by recent advances in visual recognition, we argue the importance of learning appropriate representations for motion planning. We propose a new obstacle representation based on the PointNet architecture and train it jointly with policies for obstacle avoidance. We experimentally evaluate our approach for rigid body motion planning in challenging environments and demonstrate significant improvements of the state of the art in terms of accuracy and efficiency.
RareAct: A video dataset of unusual interactions
Aug 03, 2020


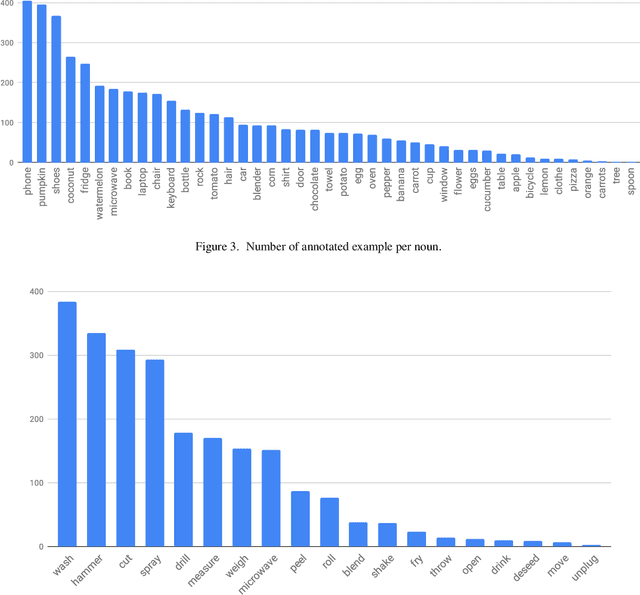
This paper introduces a manually annotated video dataset of unusual actions, namely RareAct, including actions such as "blend phone", "cut keyboard" and "microwave shoes". RareAct aims at evaluating the zero-shot and few-shot compositionality of action recognition models for unlikely compositions of common action verbs and object nouns. It contains 122 different actions which were obtained by combining verbs and nouns rarely co-occurring together in the large-scale textual corpus from HowTo100M, but that frequently appear separately. We provide benchmarks using a state-of-the-art HowTo100M pretrained video and text model and show that zero-shot and few-shot compositionality of actions remains a challenging and unsolved task.
The End-of-End-to-End: A Video Understanding Pentathlon Challenge
Aug 03, 2020
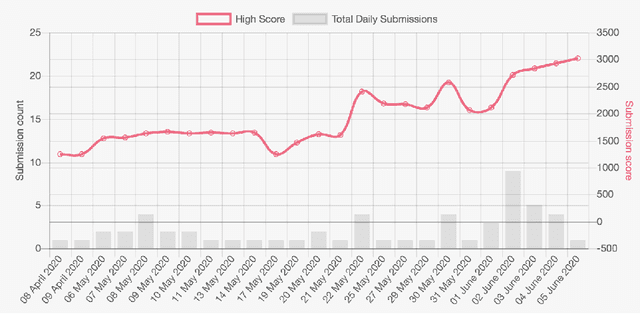
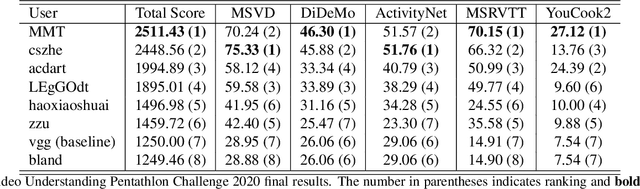
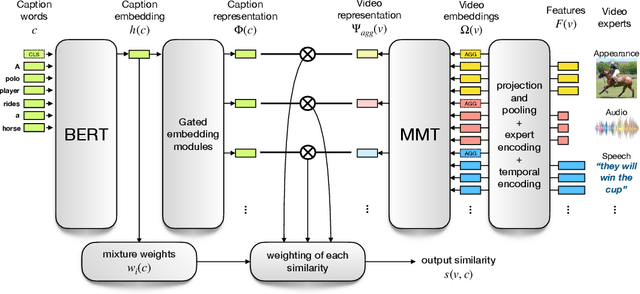
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.
Occlusion resistant learning of intuitive physics from videos
Apr 30, 2020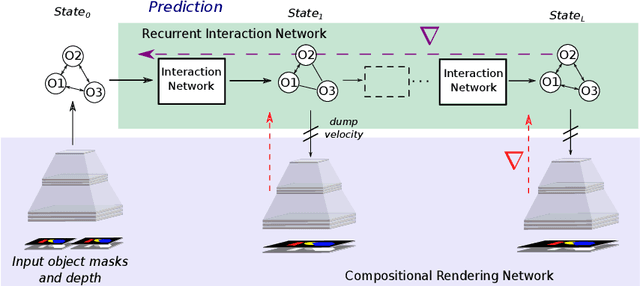
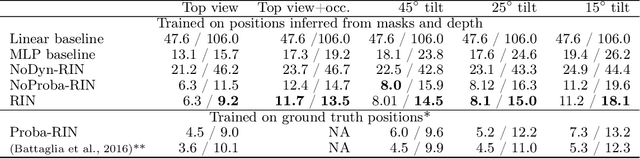


To reach human performance on complex tasks, a key ability for artificial systems is to understand physical interactions between objects, and predict future outcomes of a situation. This ability, often referred to as intuitive physics, has recently received attention and several methods were proposed to learn these physical rules from video sequences. Yet, most of these methods are restricted to the case where no, or only limited, occlusions occur. In this work we propose a probabilistic formulation of learning intuitive physics in 3D scenes with significant inter-object occlusions. In our formulation, object positions are modeled as latent variables enabling the reconstruction of the scene. We then propose a series of approximations that make this problem tractable. Object proposals are linked across frames using a combination of a recurrent interaction network, modeling the physics in object space, and a compositional renderer, modeling the way in which objects project onto pixel space. We demonstrate significant improvements over state-of-the-art in the intuitive physics benchmark of IntPhys. We apply our method to a second dataset with increasing levels of occlusions, showing it realistically predicts segmentation masks up to 30 frames in the future. Finally, we also show results on predicting motion of objects in real videos.
Leveraging Photometric Consistency over Time for Sparsely Supervised Hand-Object Reconstruction
Apr 28, 2020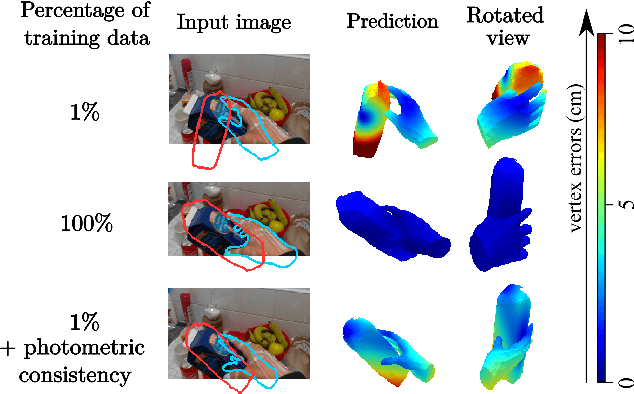

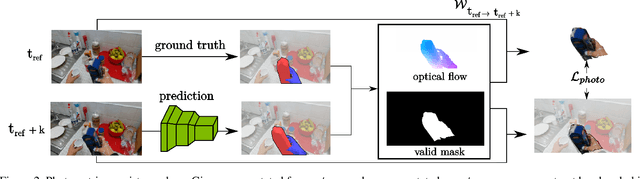

Modeling hand-object manipulations is essential for understanding how humans interact with their environment. While of practical importance, estimating the pose of hands and objects during interactions is challenging due to the large mutual occlusions that occur during manipulation. Recent efforts have been directed towards fully-supervised methods that require large amounts of labeled training samples. Collecting 3D ground-truth data for hand-object interactions, however, is costly, tedious, and error-prone. To overcome this challenge we present a method to leverage photometric consistency across time when annotations are only available for a sparse subset of frames in a video. Our model is trained end-to-end on color images to jointly reconstruct hands and objects in 3D by inferring their poses. Given our estimated reconstructions, we differentiably render the optical flow between pairs of adjacent images and use it within the network to warp one frame to another. We then apply a self-supervised photometric loss that relies on the visual consistency between nearby images. We achieve state-of-the-art results on 3D hand-object reconstruction benchmarks and demonstrate that our approach allows us to improve the pose estimation accuracy by leveraging information from neighboring frames in low-data regimes.
Learning visual policies for building 3D shape categories
Apr 15, 2020

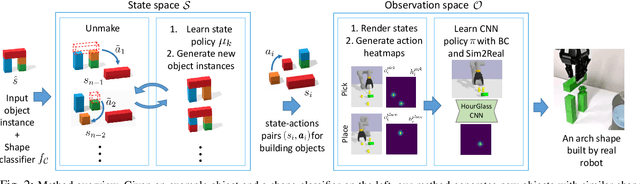
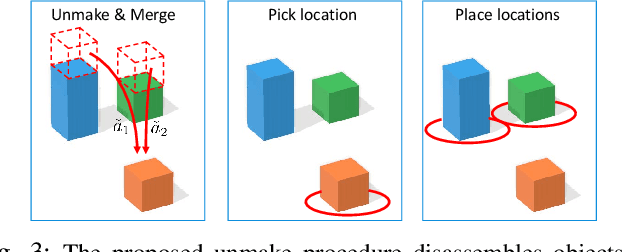
Manipulation and assembly tasks require non-trivial planning of actions depending on the environment and the final goal. Previous work in this domain often assembles particular instances of objects from known sets of primitives. In contrast, we here aim to handle varying sets of primitives and to construct different objects of the same shape category. Given a single object instance of a category, e.g. an arch, and a binary shape classifier, we learn a visual policy to assemble other instances of the same category. In particular, we propose a disassembly procedure and learn a state policy that discovers new object instances and their assembly plans in state space. We then render simulated states in the observation space and learn a heatmap representation to predict alternative actions from a given input image. To validate our approach, we first demonstrate its efficiency for building object categories in state space. We then show the success of our visual policies for building arches from different primitives. Moreover, we demonstrate (i) the reactive ability of our method to re-assemble objects using additional primitives and (ii) the robust performance of our policy for unseen primitives resembling building blocks used during training. Our visual assembly policies are trained with no real images and reach up to 95% success rate when evaluated on a real robot.
Learning Interactions and Relationships between Movie Characters
Mar 29, 2020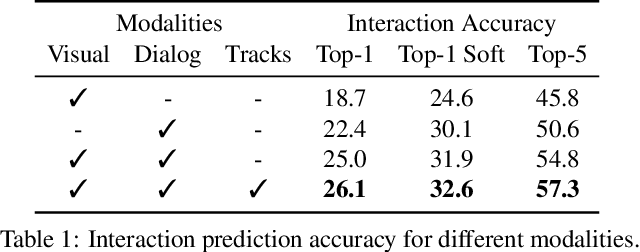
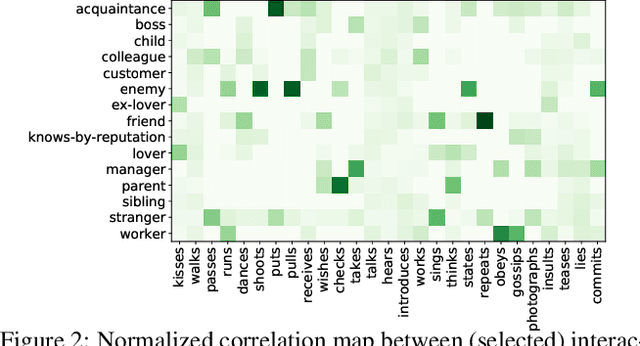
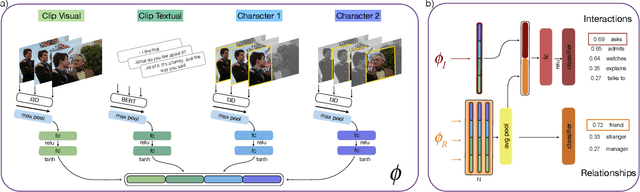

Interactions between people are often governed by their relationships. On the flip side, social relationships are built upon several interactions. Two strangers are more likely to greet and introduce themselves while becoming friends over time. We are fascinated by this interplay between interactions and relationships, and believe that it is an important aspect of understanding social situations. In this work, we propose neural models to learn and jointly predict interactions, relationships, and the pair of characters that are involved. We note that interactions are informed by a mixture of visual and dialog cues, and present a multimodal architecture to extract meaningful information from them. Localizing the pair of interacting characters in video is a time-consuming process, instead, we train our model to learn from clip-level weak labels. We evaluate our models on the MovieGraphs dataset and show the impact of modalities, use of longer temporal context for predicting relationships, and achieve encouraging performance using weak labels as compared with ground-truth labels. Code is online.
End-to-End Learning of Visual Representations from Uncurated Instructional Videos
Jan 17, 2020

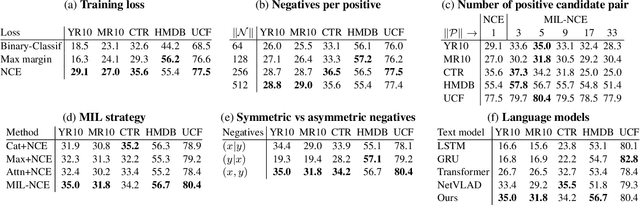
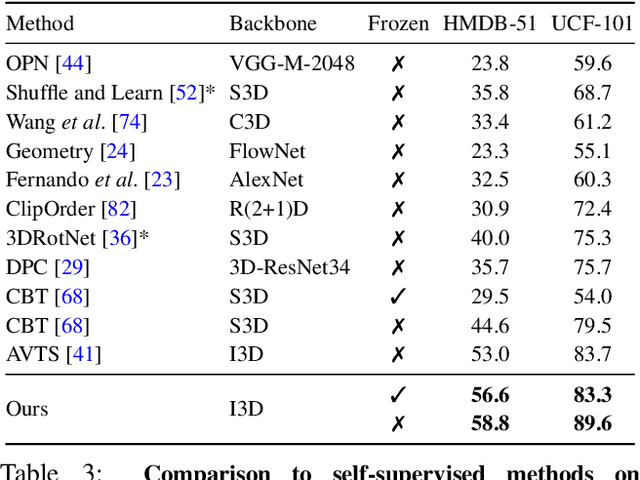
Annotating videos is cumbersome, expensive and not scalable. Yet, many strong video models still rely on manually annotated data. With the recent introduction of the HowTo100M dataset, narrated videos now offer the possibility of learning video representations without manual supervision. In this work we propose a new learning approach, MIL-NCE, capable of addressing misalignments inherent to narrated videos. With this approach we are able to learn strong video representations from scratch, without the need for any manual annotation. We evaluate our representations on a wide range of four downstream tasks over eight datasets: action recognition (HMDB-51, UCF-101, Kinetics-700), text-to-video retrieval (YouCook2, MSR-VTT), action localization (YouTube-8M Segments, CrossTask) and action segmentation (COIN). Our method outperforms all published self-supervised approaches for these tasks as well as several fully supervised baselines.
Action Modifiers: Learning from Adverbs in Instructional Videos
Dec 16, 2019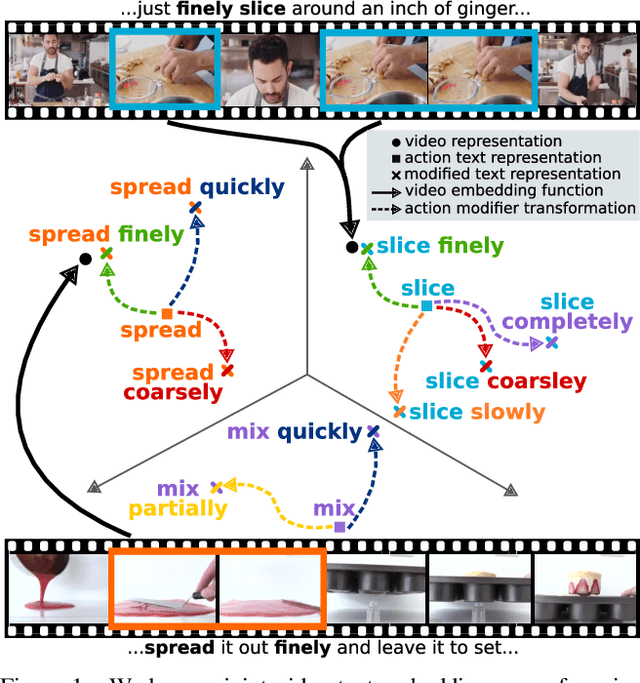
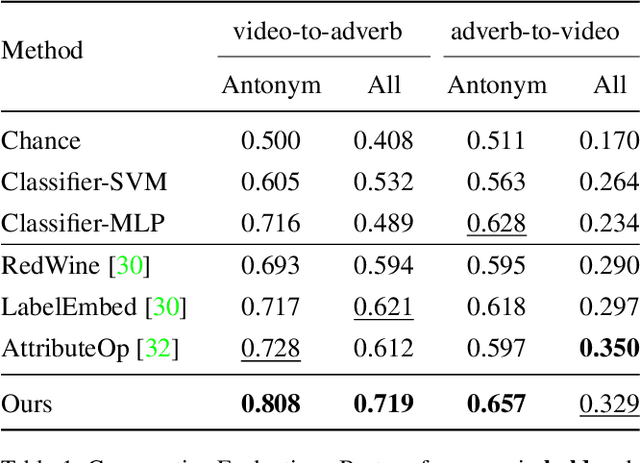
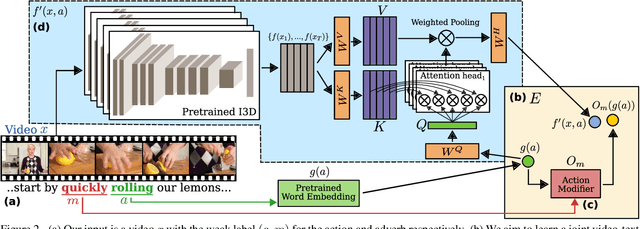
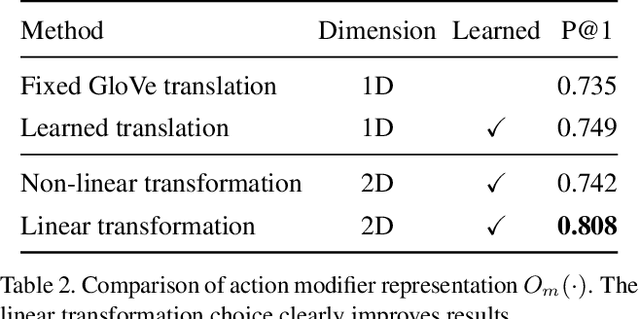
We present a method to learn a representation for adverbs from instructional videos using weak supervision from the accompanying narrations. Key to our method is the fact that the visual representation of the adverb is highly dependant on the action to which it applies, although the same adverb will modify multiple actions in a similar way. For instance, while 'spread quickly' and 'mix quickly' will look dissimilar, we can learn a common representation that allows us to recognize both, among other actions. We formulate this as an embedding problem, and use scaled dot-product attention to learn from weakly-supervised video narrations. We jointly learn adverbs as invertible transformations operating on the embedding space, so as to add or remove the effect of the adverb. As there is no prior work on weakly supervised learning from adverbs, we gather paired action-adverb annotations from a subset of the HowTo100M dataset for 6 adverbs: quickly/slowly, finely/coarsely, and partially/completely. Our method outperforms all baselines for video-to-adverb retrieval with a performance of 0.719 mAP. We also demonstrate our model's ability to attend to the relevant video parts in order to determine the adverb for a given action.
Synthetic Humans for Action Recognition from Unseen Viewpoints
Dec 09, 2019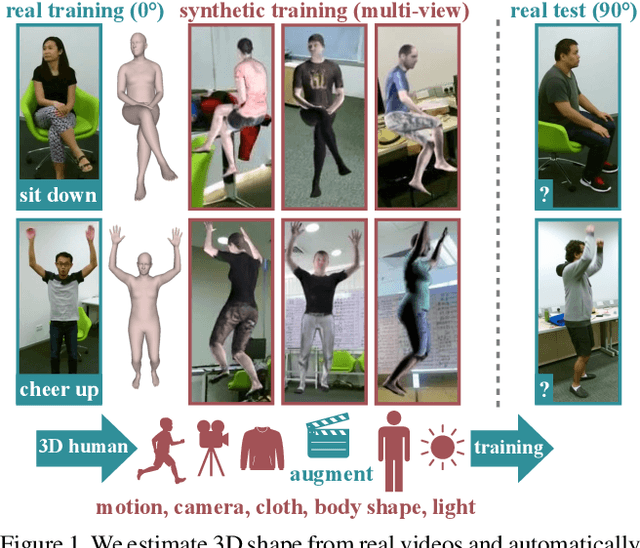
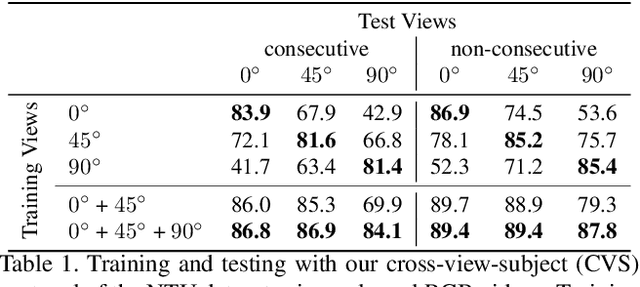

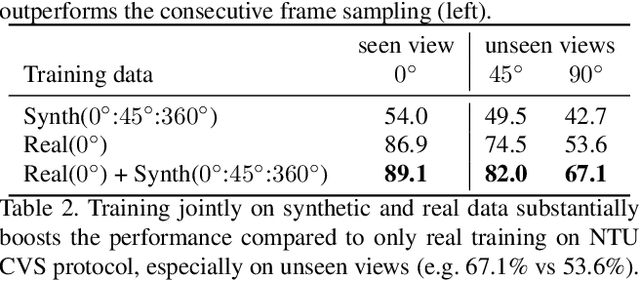
Our goal in this work is to improve the performance of human action recognition for viewpoints unseen during training by using synthetic training data. Although synthetic data has been shown to be beneficial for tasks such as human pose estimation, its use for RGB human action recognition is relatively unexplored. We make use of the recent advances in monocular 3D human body reconstruction from real action sequences to automatically render synthetic training videos for the action labels. We make the following contributions: (i) we investigate the extent of variations and augmentations that are beneficial to improving performance at new viewpoints. We consider changes in body shape and clothing for individuals, as well as more action relevant augmentations such as non-uniform frame sampling, and interpolating between the motion of individuals performing the same action; (ii) We introduce a new dataset, SURREACT, that allows supervised training of spatio-temporal CNNs for action classification; (iii) We substantially improve the state-of-the-art action recognition performance on the NTU RGB+D and UESTC standard human action multi-view benchmarks; Finally, (iv) we extend the augmentation approach to in-the-wild videos from a subset of the Kinetics dataset to investigate the case when only one-shot training data is available, and demonstrate improvements in this case as well.