 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Do We (Not) Need Temporal Context in Low-Resource Video Task Adaptation?
Jun 02, 2026Parameter-efficient fine-tuning (PEFT) and probing enable adaptation of foundation models using only a small number of trainable parameters, making it attractive for video understanding where annotation and computation are expensive. However, video PEFT has focused on adapting image-pretrained models, while standard PEFT methods can also be applied to video representations. These settings are rarely compared and both confine temporal reasoning to a single component of the model, leaving open how temporal context should be distributed across backbone, PEFT and probe. In this work we provide a systematic study of model adaptation strategies for video understanding. We evaluate methods across appearance-focused, motion-focused and spatially dense settings, with a particular focus on scenarios with limited data where parameter-efficiency is most beneficial. Our results provide new insights into PEFT and probing across settings and demonstrate the importance of temporal context allocation for effective video adaptation
Let's Split Up: Zero-Shot Classifier Edits for Fine-Grained Video Understanding
Feb 18, 2026Video recognition models are typically trained on fixed taxonomies which are often too coarse, collapsing distinctions in object, manner or outcome under a single label. As tasks and definitions evolve, such models cannot accommodate emerging distinctions and collecting new annotations and retraining to accommodate such changes is costly. To address these challenges, we introduce category splitting, a new task where an existing classifier is edited to refine a coarse category into finer subcategories, while preserving accuracy elsewhere. We propose a zero-shot editing method that leverages the latent compositional structure of video classifiers to expose fine-grained distinctions without additional data. We further show that low-shot fine-tuning, while simple, is highly effective and benefits from our zero-shot initialization. Experiments on our new video benchmarks for category splitting demonstrate that our method substantially outperforms vision-language baselines, improving accuracy on the newly split categories without sacrificing performance on the rest. Project page: https://kaitingliu.github.io/Category-Splitting/.
Segmenting Collision Sound Sources in Egocentric Videos
Nov 17, 2025Humans excel at multisensory perception and can often recognise object properties from the sound of their interactions. Inspired by this, we propose the novel task of Collision Sound Source Segmentation (CS3), where we aim to segment the objects responsible for a collision sound in visual input (i.e. video frames from the collision clip), conditioned on the audio. This task presents unique challenges. Unlike isolated sound events, a collision sound arises from interactions between two objects, and the acoustic signature of the collision depends on both. We focus on egocentric video, where sounds are often clear, but the visual scene is cluttered, objects are small, and interactions are brief. To address these challenges, we propose a weakly-supervised method for audio-conditioned segmentation, utilising foundation models (CLIP and SAM2). We also incorporate egocentric cues, i.e. objects in hands, to find acting objects that can potentially be collision sound sources. Our approach outperforms competitive baselines by $3\times$ and $4.7\times$ in mIoU on two benchmarks we introduce for the CS3 task: EPIC-CS3 and Ego4D-CS3.
SEVERE++: Evaluating Benchmark Sensitivity in Generalization of Video Representation Learning
Apr 08, 2025Continued advances in self-supervised learning have led to significant progress in video representation learning, offering a scalable alternative to supervised approaches by removing the need for manual annotations. Despite strong performance on standard action recognition benchmarks, video self-supervised learning methods are largely evaluated under narrow protocols, typically pretraining on Kinetics-400 and fine-tuning on similar datasets, limiting our understanding of their generalization in real world scenarios. In this work, we present a comprehensive evaluation of modern video self-supervised models, focusing on generalization across four key downstream factors: domain shift, sample efficiency, action granularity, and task diversity. Building on our prior work analyzing benchmark sensitivity in CNN-based contrastive learning, we extend the study to cover state-of-the-art transformer-based video-only and video-text models. Specifically, we benchmark 12 transformer-based methods (7 video-only, 5 video-text) and compare them to 10 CNN-based methods, totaling over 1100 experiments across 8 datasets and 7 downstream tasks. Our analysis shows that, despite architectural advances, transformer-based models remain sensitive to downstream conditions. No method generalizes consistently across all factors, video-only transformers perform better under domain shifts, CNNs outperform for fine-grained tasks, and video-text models often underperform despite large scale pretraining. We also find that recent transformer models do not consistently outperform earlier approaches. Our findings provide a detailed view of the strengths and limitations of current video SSL methods and offer a unified benchmark for evaluating generalization in video representation learning.
HD-EPIC: A Highly-Detailed Egocentric Video Dataset
Feb 06, 2025
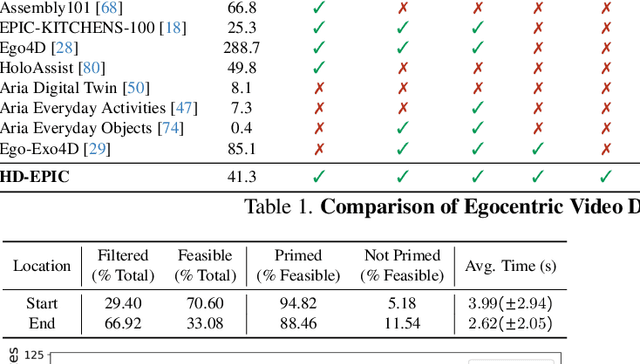


We present a validation dataset of newly-collected kitchen-based egocentric videos, manually annotated with highly detailed and interconnected ground-truth labels covering: recipe steps, fine-grained actions, ingredients with nutritional values, moving objects, and audio annotations. Importantly, all annotations are grounded in 3D through digital twinning of the scene, fixtures, object locations, and primed with gaze. Footage is collected from unscripted recordings in diverse home environments, making HDEPIC the first dataset collected in-the-wild but with detailed annotations matching those in controlled lab environments. We show the potential of our highly-detailed annotations through a challenging VQA benchmark of 26K questions assessing the capability to recognise recipes, ingredients, nutrition, fine-grained actions, 3D perception, object motion, and gaze direction. The powerful long-context Gemini Pro only achieves 38.5% on this benchmark, showcasing its difficulty and highlighting shortcomings in current VLMs. We additionally assess action recognition, sound recognition, and long-term video-object segmentation on HD-EPIC. HD-EPIC is 41 hours of video in 9 kitchens with digital twins of 413 kitchen fixtures, capturing 69 recipes, 59K fine-grained actions, 51K audio events, 20K object movements and 37K object masks lifted to 3D. On average, we have 263 annotations per minute of our unscripted videos.
Beyond Coarse-Grained Matching in Video-Text Retrieval
Oct 17, 2024



Video-text retrieval has seen significant advancements, yet the ability of models to discern subtle differences in captions still requires verification. In this paper, we introduce a new approach for fine-grained evaluation. Our approach can be applied to existing datasets by automatically generating hard negative test captions with subtle single-word variations across nouns, verbs, adjectives, adverbs, and prepositions. We perform comprehensive experiments using four state-of-the-art models across two standard benchmarks (MSR-VTT and VATEX) and two specially curated datasets enriched with detailed descriptions (VLN-UVO and VLN-OOPS), resulting in a number of novel insights: 1) our analyses show that the current evaluation benchmarks fall short in detecting a model's ability to perceive subtle single-word differences, 2) our fine-grained evaluation highlights the difficulty models face in distinguishing such subtle variations. To enhance fine-grained understanding, we propose a new baseline that can be easily combined with current methods. Experiments on our fine-grained evaluations demonstrate that this approach enhances a model's ability to understand fine-grained differences.
LocoMotion: Learning Motion-Focused Video-Language Representations
Oct 15, 2024



This paper strives for motion-focused video-language representations. Existing methods to learn video-language representations use spatial-focused data, where identifying the objects and scene is often enough to distinguish the relevant caption. We instead propose LocoMotion to learn from motion-focused captions that describe the movement and temporal progression of local object motions. We achieve this by adding synthetic motions to videos and using the parameters of these motions to generate corresponding captions. Furthermore, we propose verb-variation paraphrasing to increase the caption variety and learn the link between primitive motions and high-level verbs. With this, we are able to learn a motion-focused video-language representation. Experiments demonstrate our approach is effective for a variety of downstream tasks, particularly when limited data is available for fine-tuning. Code is available: https://hazeldoughty.github.io/Papers/LocoMotion/
SelEx: Self-Expertise in Fine-Grained Generalized Category Discovery
Aug 26, 2024



In this paper, we address Generalized Category Discovery, aiming to simultaneously uncover novel categories and accurately classify known ones. Traditional methods, which lean heavily on self-supervision and contrastive learning, often fall short when distinguishing between fine-grained categories. To address this, we introduce a novel concept called `self-expertise', which enhances the model's ability to recognize subtle differences and uncover unknown categories. Our approach combines unsupervised and supervised self-expertise strategies to refine the model's discernment and generalization. Initially, hierarchical pseudo-labeling is used to provide `soft supervision', improving the effectiveness of self-expertise. Our supervised technique differs from traditional methods by utilizing more abstract positive and negative samples, aiding in the formation of clusters that can generalize to novel categories. Meanwhile, our unsupervised strategy encourages the model to sharpen its category distinctions by considering within-category examples as `hard' negatives. Supported by theoretical insights, our empirical results showcase that our method outperforms existing state-of-the-art techniques in Generalized Category Discovery across several fine-grained datasets. Our code is available at: https://github.com/SarahRastegar/SelEx.
Low-Resource Vision Challenges for Foundation Models
Jan 10, 2024Low-resource settings are well-established in natural language processing, where many languages lack sufficient data for machine learning at scale. However, low-resource problems are under-explored in computer vision. In this paper, we strive to address this gap and explore the challenges of low-resource image tasks with vision foundation models. Thus, we first collect a benchmark of genuinely low-resource image data, covering historic maps, circuit diagrams, and mechanical drawings. These low-resource settings all share the three challenges of data scarcity, fine-grained differences, and the distribution shift from natural images to the specialized domain of interest. While existing foundation models have shown impressive generalizability, we find they cannot transfer well to our low-resource tasks. To begin to tackle the challenges of low-resource vision, we introduce one simple baseline per challenge. Specifically, we propose to i) enlarge the data space by generative models, ii) adopt the best sub-kernels to encode local regions for fine-grained difference discovery and iii) learn attention for specialized domains. Experiments on the three low-resource data sources in our benchmark demonstrate our proposals already provide a better baseline than common transfer learning, data augmentation, and fine-grained methods. This highlights the unique characteristics and challenges of low-resource vision for foundation models that warrant further investigation. Project website: https://xiaobai1217.github.io/Low-Resource-Vision/.
Learn to Categorize or Categorize to Learn? Self-Coding for Generalized Category Discovery
Nov 06, 2023In the quest for unveiling novel categories at test time, we confront the inherent limitations of traditional supervised recognition models that are restricted by a predefined category set. While strides have been made in the realms of self-supervised and open-world learning towards test-time category discovery, a crucial yet often overlooked question persists: what exactly delineates a category? In this paper, we conceptualize a category through the lens of optimization, viewing it as an optimal solution to a well-defined problem. Harnessing this unique conceptualization, we propose a novel, efficient and self-supervised method capable of discovering previously unknown categories at test time. A salient feature of our approach is the assignment of minimum length category codes to individual data instances, which encapsulates the implicit category hierarchy prevalent in real-world datasets. This mechanism affords us enhanced control over category granularity, thereby equipping our model to handle fine-grained categories adeptly. Experimental evaluations, bolstered by state-of-the-art benchmark comparisons, testify to the efficacy of our solution in managing unknown categories at test time. Furthermore, we fortify our proposition with a theoretical foundation, providing proof of its optimality. Our code is available at https://github.com/SarahRastegar/InfoSieve.