 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSegmenter: Transformer for Semantic Segmentation
May 12, 2021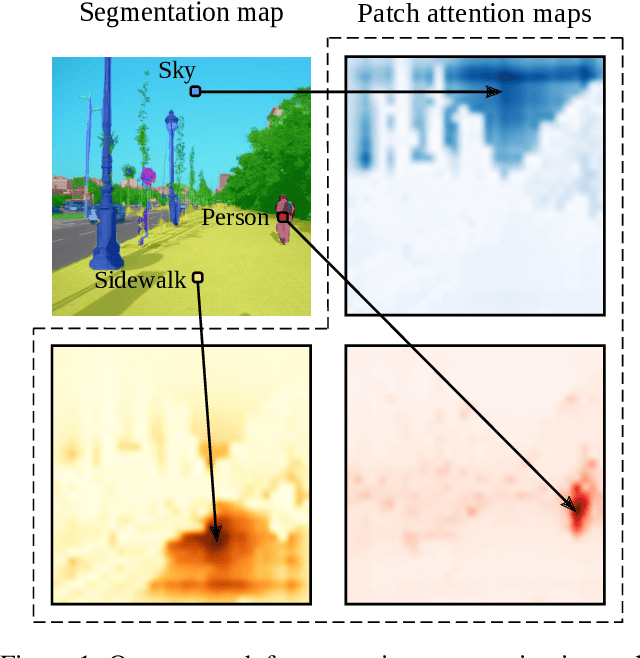
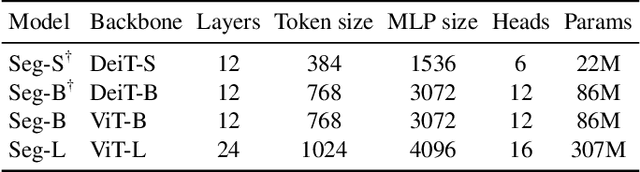
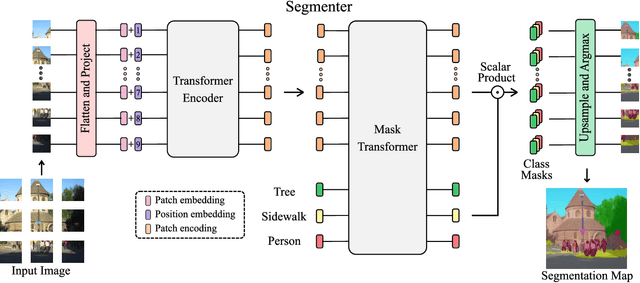
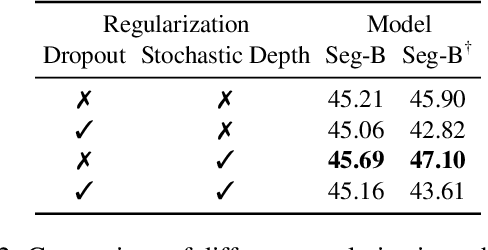
Image segmentation is often ambiguous at the level of individual image patches and requires contextual information to reach label consensus. In this paper we introduce Segmenter, a transformer model for semantic segmentation. In contrast to convolution based approaches, our approach allows to model global context already at the first layer and throughout the network. We build on the recent Vision Transformer (ViT) and extend it to semantic segmentation. To do so, we rely on the output embeddings corresponding to image patches and obtain class labels from these embeddings with a point-wise linear decoder or a mask transformer decoder. We leverage models pre-trained for image classification and show that we can fine-tune them on moderate sized datasets available for semantic segmentation. The linear decoder allows to obtain excellent results already, but the performance can be further improved by a mask transformer generating class masks. We conduct an extensive ablation study to show the impact of the different parameters, in particular the performance is better for large models and small patch sizes. Segmenter attains excellent results for semantic segmentation. It outperforms the state of the art on the challenging ADE20K dataset and performs on-par on Pascal Context and Cityscapes.
Thinking Fast and Slow: Efficient Text-to-Visual Retrieval with Transformers
Mar 30, 2021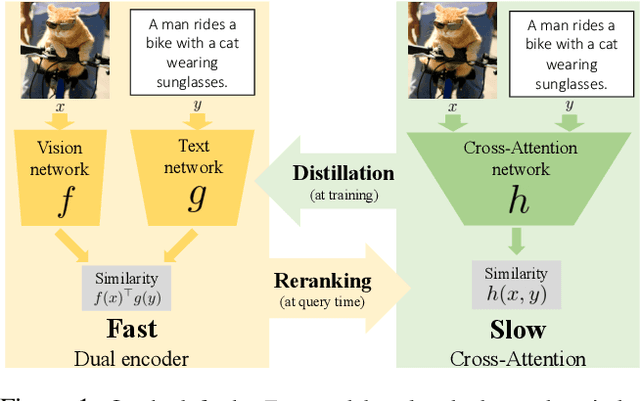
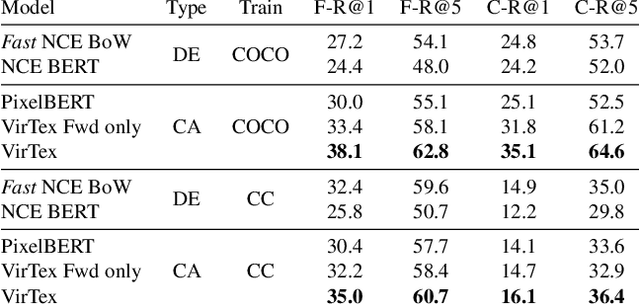
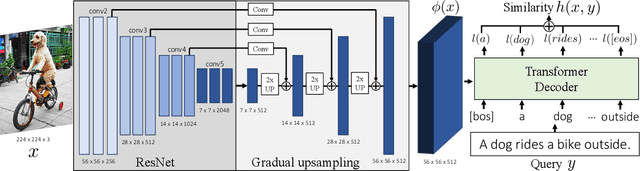
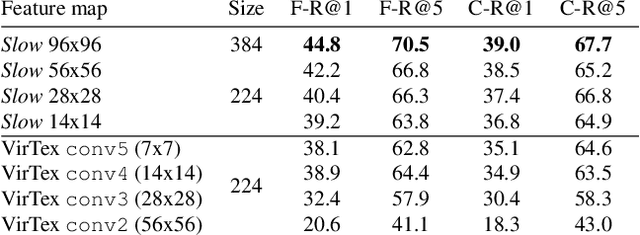
Our objective is language-based search of large-scale image and video datasets. For this task, the approach that consists of independently mapping text and vision to a joint embedding space, a.k.a. dual encoders, is attractive as retrieval scales and is efficient for billions of images using approximate nearest neighbour search. An alternative approach of using vision-text transformers with cross-attention gives considerable improvements in accuracy over the joint embeddings, but is often inapplicable in practice for large-scale retrieval given the cost of the cross-attention mechanisms required for each sample at test time. This work combines the best of both worlds. We make the following three contributions. First, we equip transformer-based models with a new fine-grained cross-attention architecture, providing significant improvements in retrieval accuracy whilst preserving scalability. Second, we introduce a generic approach for combining a Fast dual encoder model with our Slow but accurate transformer-based model via distillation and re-ranking. Finally, we validate our approach on the Flickr30K image dataset where we show an increase in inference speed by several orders of magnitude while having results competitive to the state of the art. We also extend our method to the video domain, improving the state of the art on the VATEX dataset.
Training Vision Transformers for Image Retrieval
Feb 10, 2021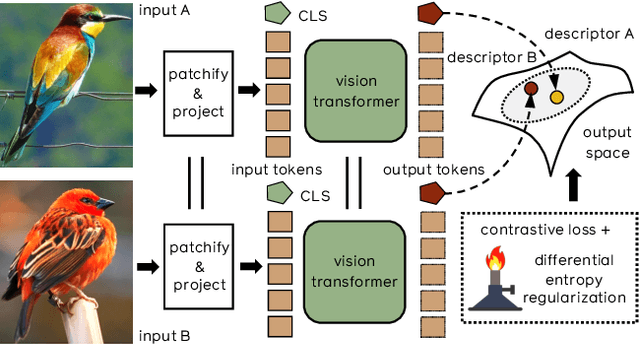
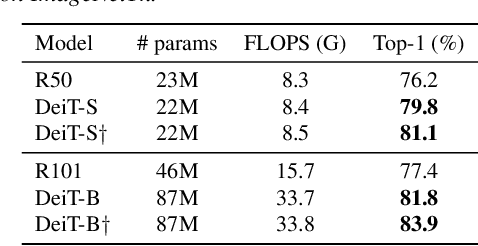
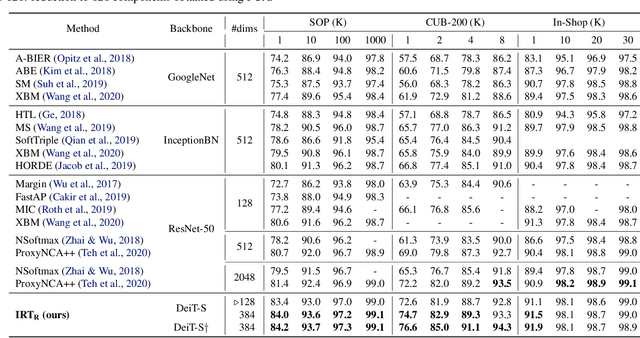
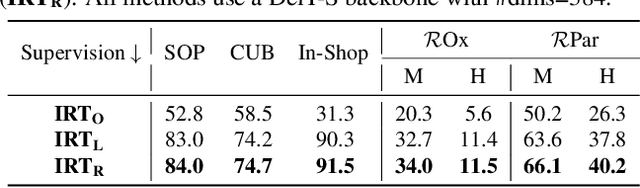
Transformers have shown outstanding results for natural language understanding and, more recently, for image classification. We here extend this work and propose a transformer-based approach for image retrieval: we adopt vision transformers for generating image descriptors and train the resulting model with a metric learning objective, which combines a contrastive loss with a differential entropy regularizer. Our results show consistent and significant improvements of transformers over convolution-based approaches. In particular, our method outperforms the state of the art on several public benchmarks for category-level retrieval, namely Stanford Online Product, In-Shop and CUB-200. Furthermore, our experiments on ROxford and RParis also show that, in comparable settings, transformers are competitive for particular object retrieval, especially in the regime of short vector representations and low-resolution images.
Just Ask: Learning to Answer Questions from Millions of Narrated Videos
Dec 01, 2020
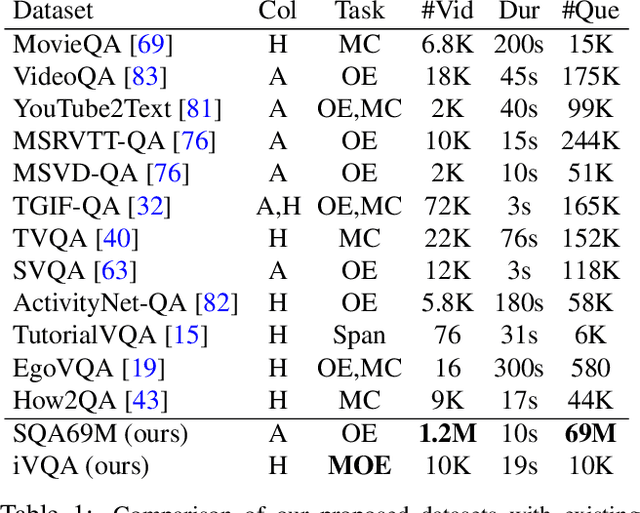


Modern approaches to visual question answering require large annotated datasets for training. Manual annotation of questions and answers for videos, however, is tedious, expensive and prevents scalability. In this work, we propose to avoid manual annotation and to learn video question answering (VideoQA) from millions of readily-available narrated videos. We propose to automatically generate question-answer pairs from transcribed video narrations leveraging a state-of-the-art text transformer pipeline and obtain a new large-scale VideoQA training dataset. To handle the open vocabulary of diverse answers in this dataset, we propose a training procedure based on a contrastive loss between a video-question multi-modal transformer and an answer embedding. We evaluate our model on the zero-shot VideoQA task and show excellent results, in particular for rare answers. Furthermore, we demonstrate that finetuning our model on target datasets significantly outperforms the state of the art on MSRVTT-QA, MSVD-QA and ActivityNet-QA. Finally, for a detailed evaluation we introduce a new manually annotated VideoQA dataset with reduced language biases and high quality annotations. Our code and datasets will be made publicly available at https://www.di.ens.fr/willow/research/just-ask/ .
Learning Object Manipulation Skills via Approximate State Estimation from Real Videos
Nov 13, 2020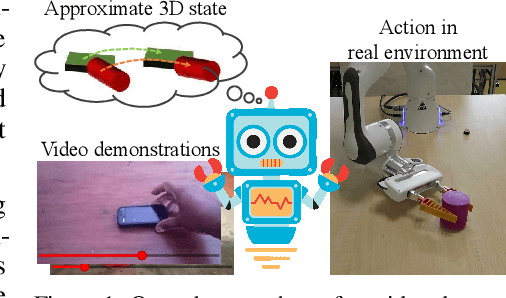
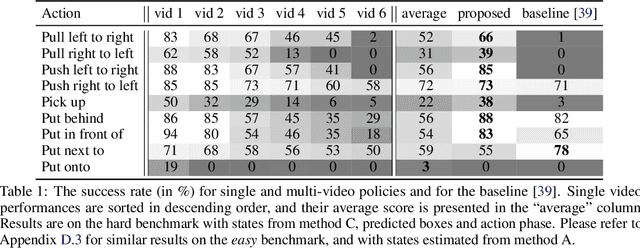
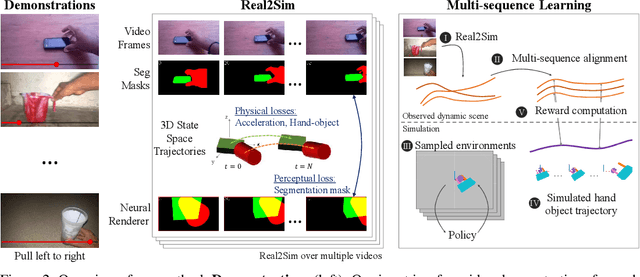

Humans are adept at learning new tasks by watching a few instructional videos. On the other hand, robots that learn new actions either require a lot of effort through trial and error, or use expert demonstrations that are challenging to obtain. In this paper, we explore a method that facilitates learning object manipulation skills directly from videos. Leveraging recent advances in 2D visual recognition and differentiable rendering, we develop an optimization based method to estimate a coarse 3D state representation for the hand and the manipulated object(s) without requiring any supervision. We use these trajectories as dense rewards for an agent that learns to mimic them through reinforcement learning. We evaluate our method on simple single- and two-object actions from the Something-Something dataset. Our approach allows an agent to learn actions from single videos, while watching multiple demonstrations makes the policy more robust. We show that policies learned in a simulated environment can be easily transferred to a real robot.
Learning Obstacle Representations for Neural Motion Planning
Aug 29, 2020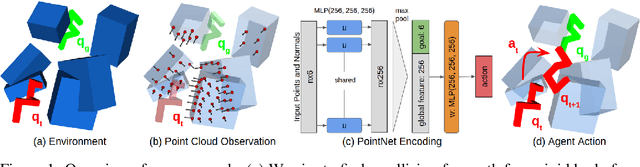
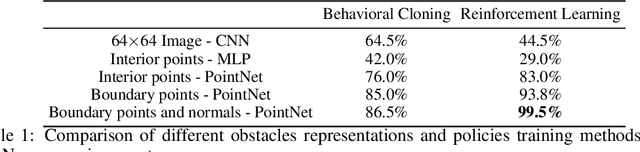

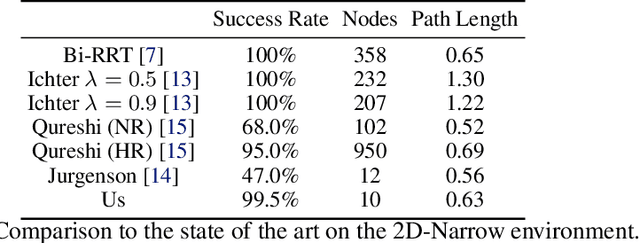
Motion planning and obstacle avoidance is a key challenge in robotics applications. While previous work succeeds to provide excellent solutions for known environments, sensor-based motion planning in new and dynamic environments remains difficult. In this work we address sensor-based motion planning from a learning perspective. Motivated by recent advances in visual recognition, we argue the importance of learning appropriate representations for motion planning. We propose a new obstacle representation based on the PointNet architecture and train it jointly with policies for obstacle avoidance. We experimentally evaluate our approach for rigid body motion planning in challenging environments and demonstrate significant improvements of the state of the art in terms of accuracy and efficiency.
RareAct: A video dataset of unusual interactions
Aug 03, 2020


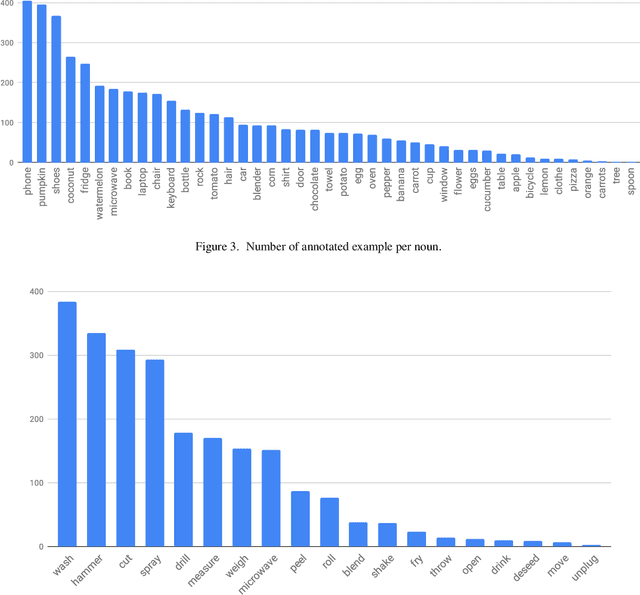
This paper introduces a manually annotated video dataset of unusual actions, namely RareAct, including actions such as "blend phone", "cut keyboard" and "microwave shoes". RareAct aims at evaluating the zero-shot and few-shot compositionality of action recognition models for unlikely compositions of common action verbs and object nouns. It contains 122 different actions which were obtained by combining verbs and nouns rarely co-occurring together in the large-scale textual corpus from HowTo100M, but that frequently appear separately. We provide benchmarks using a state-of-the-art HowTo100M pretrained video and text model and show that zero-shot and few-shot compositionality of actions remains a challenging and unsolved task.
The End-of-End-to-End: A Video Understanding Pentathlon Challenge
Aug 03, 2020
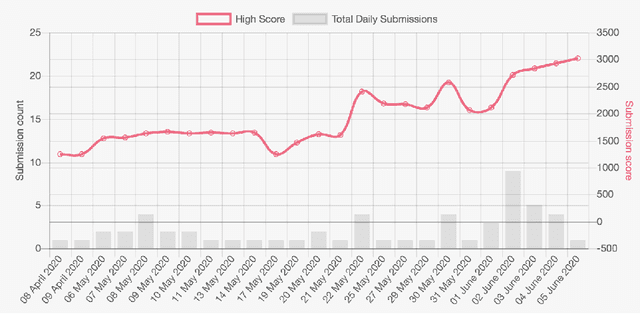
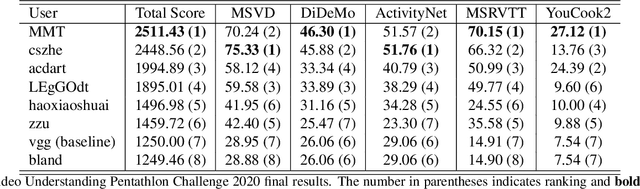
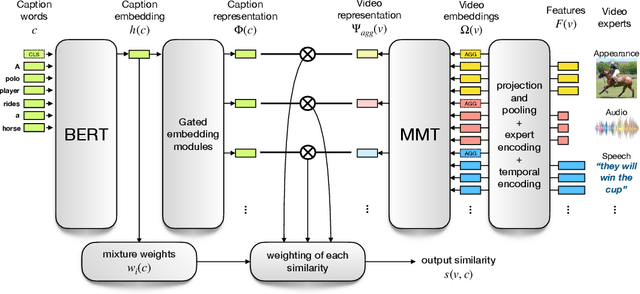
We present a new video understanding pentathlon challenge, an open competition held in conjunction with the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2020. The objective of the challenge was to explore and evaluate new methods for text-to-video retrieval-the task of searching for content within a corpus of videos using natural language queries. This report summarizes the results of the first edition of the challenge together with the findings of the participants.
Occlusion resistant learning of intuitive physics from videos
Apr 30, 2020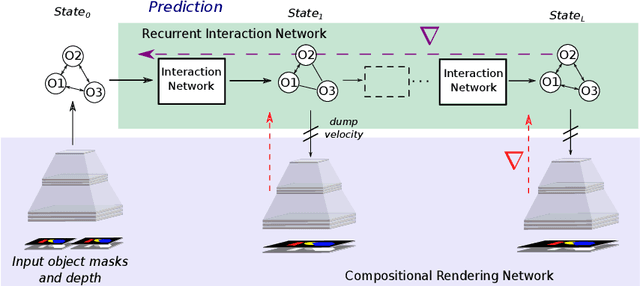
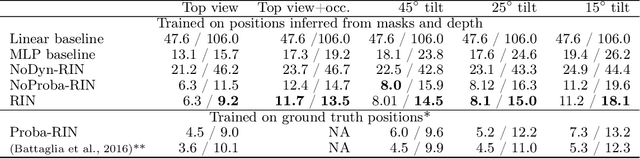


To reach human performance on complex tasks, a key ability for artificial systems is to understand physical interactions between objects, and predict future outcomes of a situation. This ability, often referred to as intuitive physics, has recently received attention and several methods were proposed to learn these physical rules from video sequences. Yet, most of these methods are restricted to the case where no, or only limited, occlusions occur. In this work we propose a probabilistic formulation of learning intuitive physics in 3D scenes with significant inter-object occlusions. In our formulation, object positions are modeled as latent variables enabling the reconstruction of the scene. We then propose a series of approximations that make this problem tractable. Object proposals are linked across frames using a combination of a recurrent interaction network, modeling the physics in object space, and a compositional renderer, modeling the way in which objects project onto pixel space. We demonstrate significant improvements over state-of-the-art in the intuitive physics benchmark of IntPhys. We apply our method to a second dataset with increasing levels of occlusions, showing it realistically predicts segmentation masks up to 30 frames in the future. Finally, we also show results on predicting motion of objects in real videos.
Leveraging Photometric Consistency over Time for Sparsely Supervised Hand-Object Reconstruction
Apr 28, 2020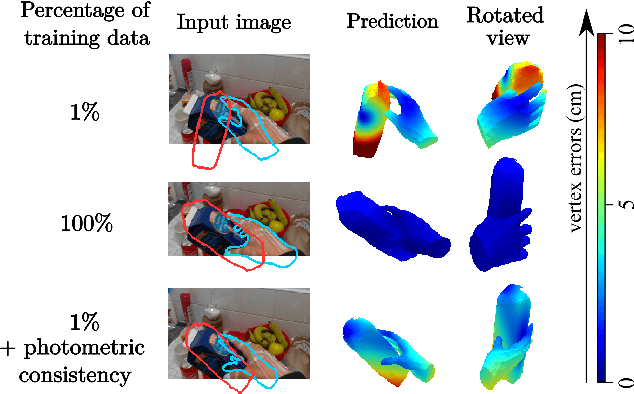

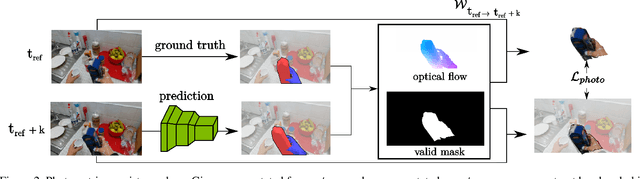

Modeling hand-object manipulations is essential for understanding how humans interact with their environment. While of practical importance, estimating the pose of hands and objects during interactions is challenging due to the large mutual occlusions that occur during manipulation. Recent efforts have been directed towards fully-supervised methods that require large amounts of labeled training samples. Collecting 3D ground-truth data for hand-object interactions, however, is costly, tedious, and error-prone. To overcome this challenge we present a method to leverage photometric consistency across time when annotations are only available for a sparse subset of frames in a video. Our model is trained end-to-end on color images to jointly reconstruct hands and objects in 3D by inferring their poses. Given our estimated reconstructions, we differentiably render the optical flow between pairs of adjacent images and use it within the network to warp one frame to another. We then apply a self-supervised photometric loss that relies on the visual consistency between nearby images. We achieve state-of-the-art results on 3D hand-object reconstruction benchmarks and demonstrate that our approach allows us to improve the pose estimation accuracy by leveraging information from neighboring frames in low-data regimes.