 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAI GPT-5 System Card
Dec 19, 2025This is the system card published alongside the OpenAI GPT-5 launch, August 2025. GPT-5 is a unified system with a smart and fast model that answers most questions, a deeper reasoning model for harder problems, and a real-time router that quickly decides which model to use based on conversation type, complexity, tool needs, and explicit intent (for example, if you say 'think hard about this' in the prompt). The router is continuously trained on real signals, including when users switch models, preference rates for responses, and measured correctness, improving over time. Once usage limits are reached, a mini version of each model handles remaining queries. This system card focuses primarily on gpt-5-thinking and gpt-5-main, while evaluations for other models are available in the appendix. The GPT-5 system not only outperforms previous models on benchmarks and answers questions more quickly, but -- more importantly -- is more useful for real-world queries. We've made significant advances in reducing hallucinations, improving instruction following, and minimizing sycophancy, and have leveled up GPT-5's performance in three of ChatGPT's most common uses: writing, coding, and health. All of the GPT-5 models additionally feature safe-completions, our latest approach to safety training to prevent disallowed content. Similarly to ChatGPT agent, we have decided to treat gpt-5-thinking as High capability in the Biological and Chemical domain under our Preparedness Framework, activating the associated safeguards. While we do not have definitive evidence that this model could meaningfully help a novice to create severe biological harm -- our defined threshold for High capability -- we have chosen to take a precautionary approach.
BridgeData V2: A Dataset for Robot Learning at Scale
Aug 24, 2023We introduce BridgeData V2, a large and diverse dataset of robotic manipulation behaviors designed to facilitate research on scalable robot learning. BridgeData V2 contains 60,096 trajectories collected across 24 environments on a publicly available low-cost robot. BridgeData V2 provides extensive task and environment variability, leading to skills that can generalize across environments, domains, and institutions, making the dataset a useful resource for a broad range of researchers. Additionally, the dataset is compatible with a wide variety of open-vocabulary, multi-task learning methods conditioned on goal images or natural language instructions. In our experiments, we train 6 state-of-the-art imitation learning and offline reinforcement learning methods on our dataset, and find that they succeed on a suite of tasks requiring varying amounts of generalization. We also demonstrate that the performance of these methods improves with more data and higher capacity models, and that training on a greater variety of skills leads to improved generalization. By publicly sharing BridgeData V2 and our pre-trained models, we aim to accelerate research in scalable robot learning methods. Project page at https://rail-berkeley.github.io/bridgedata
Multi-modal Ensemble Models for Predicting Video Memorability
Feb 01, 2021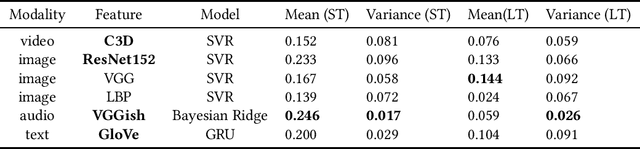
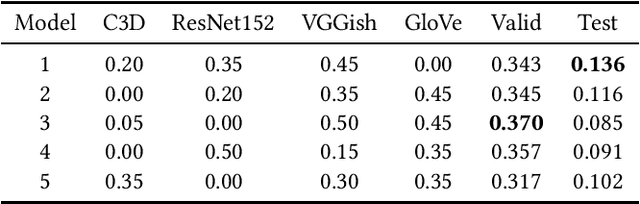
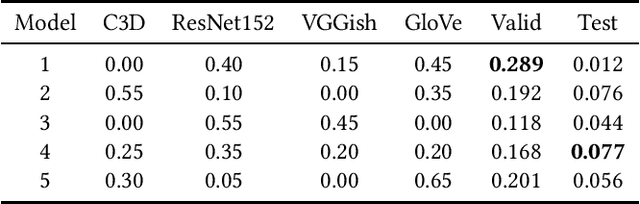
Modeling media memorability has been a consistent challenge in the field of machine learning. The Predicting Media Memorability task in MediaEval2020 is the latest benchmark among similar challenges addressing this topic. Building upon techniques developed in previous iterations of the challenge, we developed ensemble methods with the use of extracted video, image, text, and audio features. Critically, in this work we introduce and demonstrate the efficacy and high generalizability of extracted audio embeddings as a feature for the task of predicting media memorability.
DIME: An Online Tool for the Visual Comparison of Cross-Modal Retrieval Models
Oct 19, 2020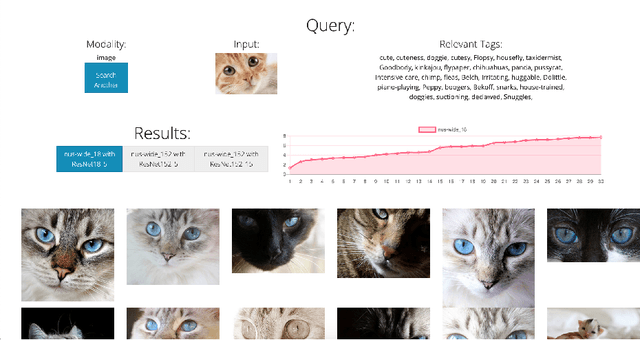
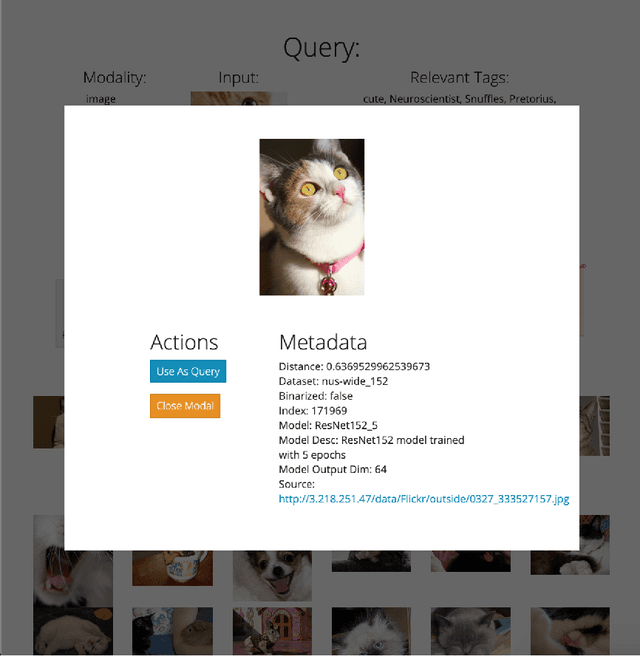
Cross-modal retrieval relies on accurate models to retrieve relevant results for queries across modalities such as image, text, and video. In this paper, we build upon previous work by tackling the difficulty of evaluating models both quantitatively and qualitatively quickly. We present DIME (Dataset, Index, Model, Embedding), a modality-agnostic tool that handles multimodal datasets, trained models, and data preprocessors to support straightforward model comparison with a web browser graphical user interface. DIME inherently supports building modality-agnostic queryable indexes and extraction of relevant feature embeddings, and thus effectively doubles as an efficient cross-modal tool to explore and search through datasets.