 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distillation Zero: Self-Revision Turns Binary Rewards into Dense Supervision
Apr 13, 2026Current post-training methods in verifiable settings fall into two categories. Reinforcement learning (RLVR) relies on binary rewards, which are broadly applicable and powerful, but provide only sparse supervision during training. Distillation provides dense token-level supervision, typically obtained from an external teacher or using high-quality demonstrations. Collecting such supervision can be costly or unavailable. We propose Self-Distillation Zero (SD-Zero), a method that is substantially more training sample-efficient than RL and does not require an external teacher or high-quality demonstrations. SD-Zero trains a single model to play two roles: a Generator, which produces an initial response, and a Reviser, which conditions on that response and its binary reward to produce an improved response. We then perform on-policy self-distillation to distill the reviser into the generator, using the reviser's token distributions conditioned on the generator's response and its reward as supervision. In effect, SD-Zero trains the model to transform binary rewards into dense token-level self-supervision. On math and code reasoning benchmarks with Qwen3-4B-Instruct and Olmo-3-7B-Instruct, SD-Zero improves performance by at least 10% over the base models and outperforms strong baselines, including Rejection Fine-Tuning (RFT), GRPO, and Self-Distillation Fine-Tuning (SDFT), under the same question set and training sample budget. Extensive ablation studies show two novel characteristics of our proposed algorithm: (a) token-level self-localization, where the reviser can identify the key tokens that need to be revised in the generator's response based on reward, and (b) iterative self-evolution, where the improving ability to revise answers can be distilled back into generation performance with regular teacher synchronization.
UniSAFE: A Comprehensive Benchmark for Safety Evaluation of Unified Multimodal Models
Mar 18, 2026Unified Multimodal Models (UMMs) offer powerful cross-modality capabilities but introduce new safety risks not observed in single-task models. Despite their emergence, existing safety benchmarks remain fragmented across tasks and modalities, limiting the comprehensive evaluation of complex system-level vulnerabilities. To address this gap, we introduce UniSAFE, the first comprehensive benchmark for system-level safety evaluation of UMMs across 7 I/O modality combinations, spanning conventional tasks and novel multimodal-context image generation settings. UniSAFE is built with a shared-target design that projects common risk scenarios across task-specific I/O configurations, enabling controlled cross-task comparisons of safety failures. Comprising 6,802 curated instances, we use UniSAFE to evaluate 15 state-of-the-art UMMs, both proprietary and open-source. Our results reveal critical vulnerabilities across current UMMs, including elevated safety violations in multi-image composition and multi-turn settings, with image-output tasks consistently more vulnerable than text-output tasks. These findings highlight the need for stronger system-level safety alignment for UMMs. Our code and data are publicly available at https://github.com/segyulee/UniSAFE
Automated Skill Discovery for Language Agents through Exploration and Iterative Feedback
Jun 04, 2025Training large language model (LLM) agents to acquire necessary skills and perform diverse tasks within an environment is gaining interest as a means to enable open-endedness. However, creating the training dataset for their skill acquisition faces several challenges. Manual trajectory collection requires significant human effort. Another approach, where LLMs directly propose tasks to learn, is often invalid, as the LLMs lack knowledge of which tasks are actually feasible. Moreover, the generated data may not provide a meaningful learning signal, as agents often already perform well on the proposed tasks. To address this, we propose a novel automatic skill discovery framework EXIF for LLM-powered agents, designed to improve the feasibility of generated target behaviors while accounting for the agents' capabilities. Our method adopts an exploration-first strategy by employing an exploration agent (Alice) to train the target agent (Bob) to learn essential skills in the environment. Specifically, Alice first interacts with the environment to retrospectively generate a feasible, environment-grounded skill dataset, which is then used to train Bob. Crucially, we incorporate an iterative feedback loop, where Alice evaluates Bob's performance to identify areas for improvement. This feedback then guides Alice's next round of exploration, forming a closed-loop data generation process. Experiments on Webshop and Crafter demonstrate EXIF's ability to effectively discover meaningful skills and iteratively expand the capabilities of the trained agent without any human intervention, achieving substantial performance improvements. Interestingly, we observe that setting Alice to the same model as Bob also notably improves performance, demonstrating EXIF's potential for building a self-evolving system.
Revisiting Multi-Agent Debate as Test-Time Scaling: A Systematic Study of Conditional Effectiveness
May 29, 2025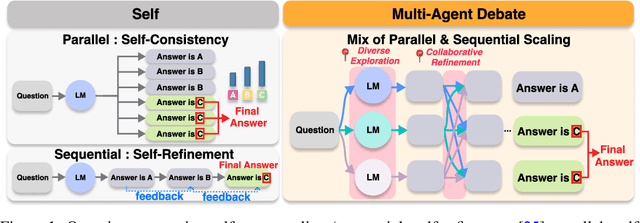
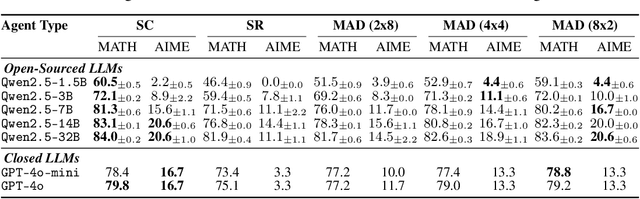
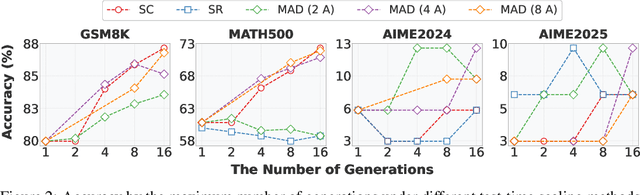
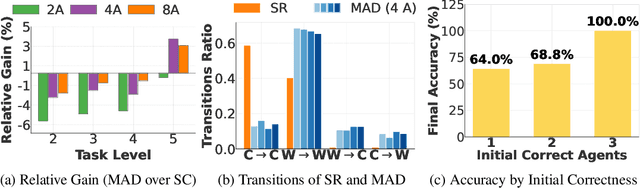
The remarkable growth in large language model (LLM) capabilities has spurred exploration into multi-agent systems, with debate frameworks emerging as a promising avenue for enhanced problem-solving. These multi-agent debate (MAD) approaches, where agents collaboratively present, critique, and refine arguments, potentially offer improved reasoning, robustness, and diverse perspectives over monolithic models. Despite prior studies leveraging MAD, a systematic understanding of its effectiveness compared to self-agent methods, particularly under varying conditions, remains elusive. This paper seeks to fill this gap by conceptualizing MAD as a test-time computational scaling technique, distinguished by collaborative refinement and diverse exploration capabilities. We conduct a comprehensive empirical investigation comparing MAD with strong self-agent test-time scaling baselines on mathematical reasoning and safety-related tasks. Our study systematically examines the influence of task difficulty, model scale, and agent diversity on MAD's performance. Key findings reveal that, for mathematical reasoning, MAD offers limited advantages over self-agent scaling but becomes more effective with increased problem difficulty and decreased model capability, while agent diversity shows little benefit. Conversely, for safety tasks, MAD's collaborative refinement can increase vulnerability, but incorporating diverse agent configurations facilitates a gradual reduction in attack success through the collaborative refinement process. We believe our findings provide critical guidance for the future development of more effective and strategically deployed MAD systems.
Self-Training Elicits Concise Reasoning in Large Language Models
Feb 28, 2025Chain-of-thought (CoT) reasoning has enabled large language models (LLMs) to utilize additional computation through intermediate tokens to solve complex tasks. However, we posit that typical reasoning traces contain many redundant tokens, incurring extraneous inference costs. Upon examination of the output distribution of current LLMs, we find evidence on their latent ability to reason more concisely, relative to their default behavior. To elicit this capability, we propose simple fine-tuning methods which leverage self-generated concise reasoning paths obtained by best-of-N sampling and few-shot conditioning, in task-specific settings. Our combined method achieves a 30% reduction in output tokens on average, across five model families on GSM8K and MATH, while maintaining average accuracy. By exploiting the fundamental stochasticity and in-context learning capabilities of LLMs, our self-training approach robustly elicits concise reasoning on a wide range of models, including those with extensive post-training. Code is available at https://github.com/TergelMunkhbat/concise-reasoning
Automated Filtering of Human Feedback Data for Aligning Text-to-Image Diffusion Models
Oct 14, 2024



Fine-tuning text-to-image diffusion models with human feedback is an effective method for aligning model behavior with human intentions. However, this alignment process often suffers from slow convergence due to the large size and noise present in human feedback datasets. In this work, we propose FiFA, a novel automated data filtering algorithm designed to enhance the fine-tuning of diffusion models using human feedback datasets with direct preference optimization (DPO). Specifically, our approach selects data by solving an optimization problem to maximize three components: preference margin, text quality, and text diversity. The concept of preference margin is used to identify samples that contain high informational value to address the noisy nature of feedback dataset, which is calculated using a proxy reward model. Additionally, we incorporate text quality, assessed by large language models to prevent harmful contents, and consider text diversity through a k-nearest neighbor entropy estimator to improve generalization. Finally, we integrate all these components into an optimization process, with approximating the solution by assigning importance score to each data pair and selecting the most important ones. As a result, our method efficiently filters data automatically, without the need for manual intervention, and can be applied to any large-scale dataset. Experimental results show that FiFA significantly enhances training stability and achieves better performance, being preferred by humans 17% more, while using less than 0.5% of the full data and thus 1% of the GPU hours compared to utilizing full human feedback datasets.
MAQA: Evaluating Uncertainty Quantification in LLMs Regarding Data Uncertainty
Aug 13, 2024Although large language models (LLMs) are capable of performing various tasks, they still suffer from producing plausible but incorrect responses. To improve the reliability of LLMs, recent research has focused on uncertainty quantification to predict whether a response is correct or not. However, most uncertainty quantification methods have been evaluated on questions requiring a single clear answer, ignoring the existence of data uncertainty that arises from irreducible randomness. Instead, these methods only consider model uncertainty, which arises from a lack of knowledge. In this paper, we investigate previous uncertainty quantification methods under the presence of data uncertainty. Our contributions are two-fold: 1) proposing a new Multi-Answer Question Answering dataset, MAQA, consisting of world knowledge, mathematical reasoning, and commonsense reasoning tasks to evaluate uncertainty quantification regarding data uncertainty, and 2) assessing 5 uncertainty quantification methods of diverse white- and black-box LLMs. Our findings show that entropy and consistency-based methods estimate the model uncertainty well even under data uncertainty, while other methods for white- and black-box LLMs struggle depending on the tasks. Additionally, methods designed for white-box LLMs suffer from overconfidence in reasoning tasks compared to simple knowledge queries. We believe our observations will pave the way for future work on uncertainty quantification in realistic setting.
CSRT: Evaluation and Analysis of LLMs using Code-Switching Red-Teaming Dataset
Jun 17, 2024



Recent studies in large language models (LLMs) shed light on their multilingual ability and safety, beyond conventional tasks in language modeling. Still, current benchmarks reveal their inability to comprehensively evaluate them and are excessively dependent on manual annotations. In this paper, we introduce code-switching red-teaming (CSRT), a simple yet effective red-teaming technique that simultaneously tests multilingual understanding and safety of LLMs. We release the CSRT dataset, which comprises 315 code-switching queries combining up to 10 languages and eliciting a wide range of undesirable behaviors. Through extensive experiments with ten state-of-the-art LLMs, we demonstrate that CSRT significantly outperforms existing multilingual red-teaming techniques, achieving 46.7% more attacks than existing methods in English. We analyze the harmful responses toward the CSRT dataset concerning various aspects under ablation studies with 16K samples, including but not limited to scaling laws, unsafe behavior categories, and input conditions for optimal data generation. Additionally, we validate the extensibility of CSRT, by generating code-switching attack prompts with monolingual data.
Towards Unbiased Evaluation of Detecting Unanswerable Questions in EHRSQL
Apr 29, 2024



Incorporating unanswerable questions into EHR QA systems is crucial for testing the trustworthiness of a system, as providing non-existent responses can mislead doctors in their diagnoses. The EHRSQL dataset stands out as a promising benchmark because it is the only dataset that incorporates unanswerable questions in the EHR QA system alongside practical questions. However, in this work, we identify a data bias in these unanswerable questions; they can often be discerned simply by filtering with specific N-gram patterns. Such biases jeopardize the authenticity and reliability of QA system evaluations. To tackle this problem, we propose a simple debiasing method of adjusting the split between the validation and test sets to neutralize the undue influence of N-gram filtering. By experimenting on the MIMIC-III dataset, we demonstrate both the existing data bias in EHRSQL and the effectiveness of our data split strategy in mitigating this bias.
Leveraging Normalization Layer in Adapters With Progressive Learning and Adaptive Distillation for Cross-Domain Few-Shot Learning
Dec 18, 2023



Cross-domain few-shot learning presents a formidable challenge, as models must be trained on base classes and then tested on novel classes from various domains with only a few samples at hand. While prior approaches have primarily focused on parameter-efficient methods of using adapters, they often overlook two critical issues: shifts in batch statistics and noisy sample statistics arising from domain discrepancy variations. In this paper, we introduce a novel generic framework that leverages normalization layer in adapters with Progressive Learning and Adaptive Distillation (ProLAD), marking two principal contributions. First, our methodology utilizes two separate adapters: one devoid of a normalization layer, which is more effective for similar domains, and another embedded with a normalization layer, designed to leverage the batch statistics of the target domain, thus proving effective for dissimilar domains. Second, to address the pitfalls of noisy statistics, we deploy two strategies: a progressive training of the two adapters and an adaptive distillation technique derived from features determined by the model solely with the adapter devoid of a normalization layer. Through this adaptive distillation, our approach functions as a modulator, controlling the primary adapter for adaptation, based on each domain. Evaluations on standard cross-domain few-shot learning benchmarks confirm that our technique outperforms existing state-of-the-art methodologies.