 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoEE: Mixture of Emotion Experts for Audio-Driven Portrait Animation
Jan 03, 2025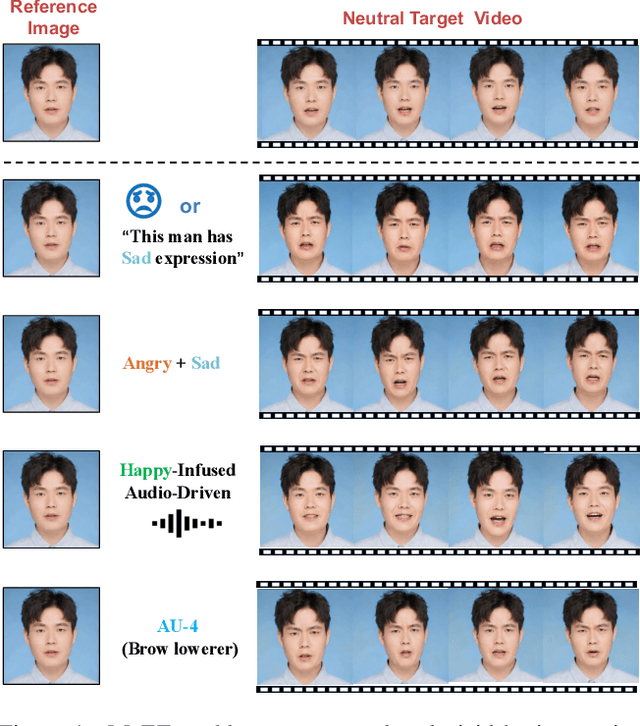


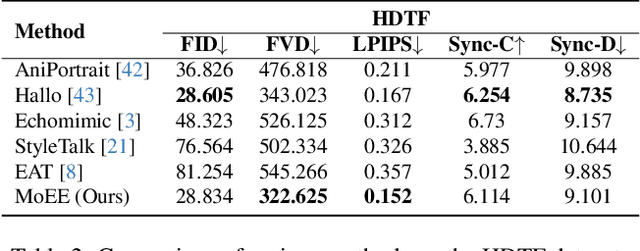
The generation of talking avatars has achieved significant advancements in precise audio synchronization. However, crafting lifelike talking head videos requires capturing a broad spectrum of emotions and subtle facial expressions. Current methods face fundamental challenges: a)the absence of frameworks for modeling single basic emotional expressions, which restricts the generation of complex emotions such as compound emotions; b)the lack of comprehensive datasets rich in human emotional expressions, which limits the potential of models. To address these challenges, we propose the following innovations: 1)the Mixture of Emotion Experts (MoEE) model, which decouples six fundamental emotions to enable the precise synthesis of both singular and compound emotional states; 2)the DH-FaceEmoVid-150 dataset, specifically curated to include six prevalent human emotional expressions as well as four types of compound emotions, thereby expanding the training potential of emotion-driven models. Furthermore, to enhance the flexibility of emotion control, we propose an emotion-to-latents module that leverages multimodal inputs, aligning diverse control signals-such as audio, text, and labels-to ensure more varied control inputs as well as the ability to control emotions using audio alone. Through extensive quantitative and qualitative evaluations, we demonstrate that the MoEE framework, in conjunction with the DH-FaceEmoVid-150 dataset, excels in generating complex emotional expressions and nuanced facial details, setting a new benchmark in the field. These datasets will be publicly released.
GURecon: Learning Detailed 3D Geometric Uncertainties for Neural Surface Reconstruction
Dec 19, 2024Neural surface representation has demonstrated remarkable success in the areas of novel view synthesis and 3D reconstruction. However, assessing the geometric quality of 3D reconstructions in the absence of ground truth mesh remains a significant challenge, due to its rendering-based optimization process and entangled learning of appearance and geometry with photometric losses. In this paper, we present a novel framework, i.e, GURecon, which establishes a geometric uncertainty field for the neural surface based on geometric consistency. Different from existing methods that rely on rendering-based measurement, GURecon models a continuous 3D uncertainty field for the reconstructed surface, and is learned by an online distillation approach without introducing real geometric information for supervision. Moreover, in order to mitigate the interference of illumination on geometric consistency, a decoupled field is learned and exploited to finetune the uncertainty field. Experiments on various datasets demonstrate the superiority of GURecon in modeling 3D geometric uncertainty, as well as its plug-and-play extension to various neural surface representations and improvement on downstream tasks such as incremental reconstruction. The code and supplementary material are available on the project website: https://zju3dv.github.io/GURecon/.
EnvGS: Modeling View-Dependent Appearance with Environment Gaussian
Dec 19, 2024



Reconstructing complex reflections in real-world scenes from 2D images is essential for achieving photorealistic novel view synthesis. Existing methods that utilize environment maps to model reflections from distant lighting often struggle with high-frequency reflection details and fail to account for near-field reflections. In this work, we introduce EnvGS, a novel approach that employs a set of Gaussian primitives as an explicit 3D representation for capturing reflections of environments. These environment Gaussian primitives are incorporated with base Gaussian primitives to model the appearance of the whole scene. To efficiently render these environment Gaussian primitives, we developed a ray-tracing-based renderer that leverages the GPU's RT core for fast rendering. This allows us to jointly optimize our model for high-quality reconstruction while maintaining real-time rendering speeds. Results from multiple real-world and synthetic datasets demonstrate that our method produces significantly more detailed reflections, achieving the best rendering quality in real-time novel view synthesis.
Prompting Depth Anything for 4K Resolution Accurate Metric Depth Estimation
Dec 18, 2024Prompts play a critical role in unleashing the power of language and vision foundation models for specific tasks. For the first time, we introduce prompting into depth foundation models, creating a new paradigm for metric depth estimation termed Prompt Depth Anything. Specifically, we use a low-cost LiDAR as the prompt to guide the Depth Anything model for accurate metric depth output, achieving up to 4K resolution. Our approach centers on a concise prompt fusion design that integrates the LiDAR at multiple scales within the depth decoder. To address training challenges posed by limited datasets containing both LiDAR depth and precise GT depth, we propose a scalable data pipeline that includes synthetic data LiDAR simulation and real data pseudo GT depth generation. Our approach sets new state-of-the-arts on the ARKitScenes and ScanNet++ datasets and benefits downstream applications, including 3D reconstruction and generalized robotic grasping.
CFSynthesis: Controllable and Free-view 3D Human Video Synthesis
Dec 17, 2024



Human video synthesis aims to create lifelike characters in various environments, with wide applications in VR, storytelling, and content creation. While 2D diffusion-based methods have made significant progress, they struggle to generalize to complex 3D poses and varying scene backgrounds. To address these limitations, we introduce CFSynthesis, a novel framework for generating high-quality human videos with customizable attributes, including identity, motion, and scene configurations. Our method leverages a texture-SMPL-based representation to ensure consistent and stable character appearances across free viewpoints. Additionally, we introduce a novel foreground-background separation strategy that effectively decomposes the scene as foreground and background, enabling seamless integration of user-defined backgrounds. Experimental results on multiple datasets show that CFSynthesis not only achieves state-of-the-art performance in complex human animations but also adapts effectively to 3D motions in free-view and user-specified scenarios.
StreetCrafter: Street View Synthesis with Controllable Video Diffusion Models
Dec 17, 2024



This paper aims to tackle the problem of photorealistic view synthesis from vehicle sensor data. Recent advancements in neural scene representation have achieved notable success in rendering high-quality autonomous driving scenes, but the performance significantly degrades as the viewpoint deviates from the training trajectory. To mitigate this problem, we introduce StreetCrafter, a novel controllable video diffusion model that utilizes LiDAR point cloud renderings as pixel-level conditions, which fully exploits the generative prior for novel view synthesis, while preserving precise camera control. Moreover, the utilization of pixel-level LiDAR conditions allows us to make accurate pixel-level edits to target scenes. In addition, the generative prior of StreetCrafter can be effectively incorporated into dynamic scene representations to achieve real-time rendering. Experiments on Waymo Open Dataset and PandaSet demonstrate that our model enables flexible control over viewpoint changes, enlarging the view synthesis regions for satisfying rendering, which outperforms existing methods.
Representing Long Volumetric Video with Temporal Gaussian Hierarchy
Dec 12, 2024

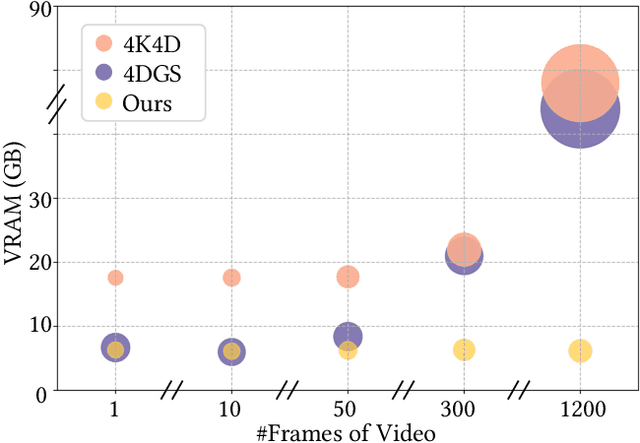
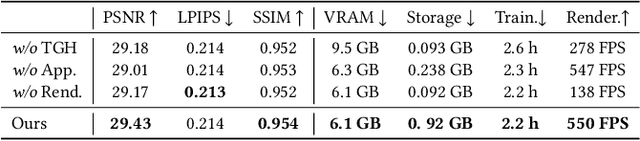
This paper aims to address the challenge of reconstructing long volumetric videos from multi-view RGB videos. Recent dynamic view synthesis methods leverage powerful 4D representations, like feature grids or point cloud sequences, to achieve high-quality rendering results. However, they are typically limited to short (1~2s) video clips and often suffer from large memory footprints when dealing with longer videos. To solve this issue, we propose a novel 4D representation, named Temporal Gaussian Hierarchy, to compactly model long volumetric videos. Our key observation is that there are generally various degrees of temporal redundancy in dynamic scenes, which consist of areas changing at different speeds. Motivated by this, our approach builds a multi-level hierarchy of 4D Gaussian primitives, where each level separately describes scene regions with different degrees of content change, and adaptively shares Gaussian primitives to represent unchanged scene content over different temporal segments, thus effectively reducing the number of Gaussian primitives. In addition, the tree-like structure of the Gaussian hierarchy allows us to efficiently represent the scene at a particular moment with a subset of Gaussian primitives, leading to nearly constant GPU memory usage during the training or rendering regardless of the video length. Extensive experimental results demonstrate the superiority of our method over alternative methods in terms of training cost, rendering speed, and storage usage. To our knowledge, this work is the first approach capable of efficiently handling minutes of volumetric video data while maintaining state-of-the-art rendering quality. Our project page is available at: https://zju3dv.github.io/longvolcap.
DATAP-SfM: Dynamic-Aware Tracking Any Point for Robust Structure from Motion in the Wild
Nov 20, 2024



This paper proposes a concise, elegant, and robust pipeline to estimate smooth camera trajectories and obtain dense point clouds for casual videos in the wild. Traditional frameworks, such as ParticleSfM~\cite{zhao2022particlesfm}, address this problem by sequentially computing the optical flow between adjacent frames to obtain point trajectories. They then remove dynamic trajectories through motion segmentation and perform global bundle adjustment. However, the process of estimating optical flow between two adjacent frames and chaining the matches can introduce cumulative errors. Additionally, motion segmentation combined with single-view depth estimation often faces challenges related to scale ambiguity. To tackle these challenges, we propose a dynamic-aware tracking any point (DATAP) method that leverages consistent video depth and point tracking. Specifically, our DATAP addresses these issues by estimating dense point tracking across the video sequence and predicting the visibility and dynamics of each point. By incorporating the consistent video depth prior, the performance of motion segmentation is enhanced. With the integration of DATAP, it becomes possible to estimate and optimize all camera poses simultaneously by performing global bundle adjustments for point tracking classified as static and visible, rather than relying on incremental camera registration. Extensive experiments on dynamic sequences, e.g., Sintel and TUM RGBD dynamic sequences, and on the wild video, e.g., DAVIS, demonstrate that the proposed method achieves state-of-the-art performance in terms of camera pose estimation even in complex dynamic challenge scenes.
A Global Depth-Range-Free Multi-View Stereo Transformer Network with Pose Embedding
Nov 04, 2024



In this paper, we propose a novel multi-view stereo (MVS) framework that gets rid of the depth range prior. Unlike recent prior-free MVS methods that work in a pair-wise manner, our method simultaneously considers all the source images. Specifically, we introduce a Multi-view Disparity Attention (MDA) module to aggregate long-range context information within and across multi-view images. Considering the asymmetry of the epipolar disparity flow, the key to our method lies in accurately modeling multi-view geometric constraints. We integrate pose embedding to encapsulate information such as multi-view camera poses, providing implicit geometric constraints for multi-view disparity feature fusion dominated by attention. Additionally, we construct corresponding hidden states for each source image due to significant differences in the observation quality of the same pixel in the reference frame across multiple source frames. We explicitly estimate the quality of the current pixel corresponding to sampled points on the epipolar line of the source image and dynamically update hidden states through the uncertainty estimation module. Extensive results on the DTU dataset and Tanks&Temple benchmark demonstrate the effectiveness of our method. The code is available at our project page: https://zju3dv.github.io/GD-PoseMVS/.
ETO:Efficient Transformer-based Local Feature Matching by Organizing Multiple Homography Hypotheses
Oct 31, 2024



We tackle the efficiency problem of learning local feature matching. Recent advancements have given rise to purely CNN-based and transformer-based approaches, each augmented with deep learning techniques. While CNN-based methods often excel in matching speed, transformer-based methods tend to provide more accurate matches. We propose an efficient transformer-based network architecture for local feature matching. This technique is built on constructing multiple homography hypotheses to approximate the continuous correspondence in the real world and uni-directional cross-attention to accelerate the refinement. On the YFCC100M dataset, our matching accuracy is competitive with LoFTR, a state-of-the-art transformer-based architecture, while the inference speed is boosted to 4 times, even outperforming the CNN-based methods. Comprehensive evaluations on other open datasets such as Megadepth, ScanNet, and HPatches demonstrate our method's efficacy, highlighting its potential to significantly enhance a wide array of downstream applications.