 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuroplastic graph attention networks for nuclei segmentation in histopathology images
Jan 10, 2022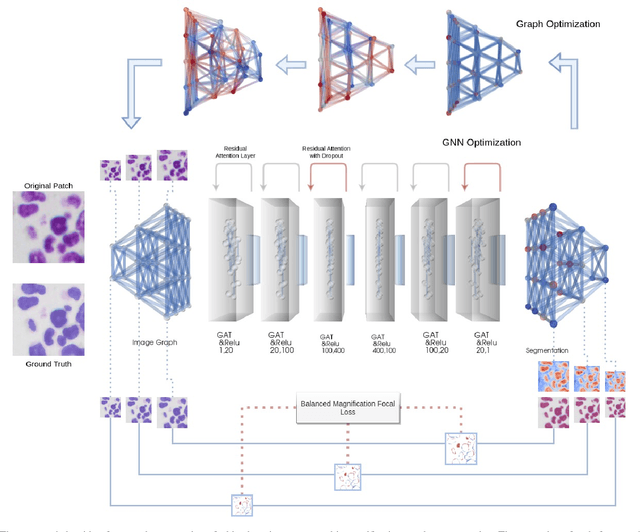
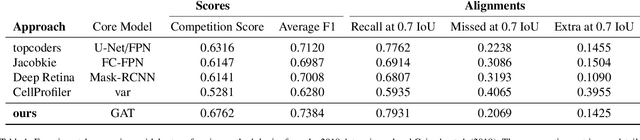

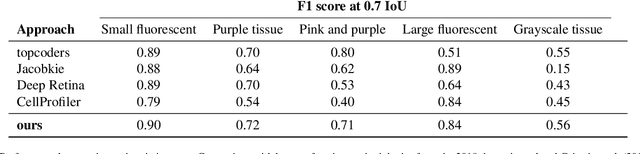
Modern histopathological image analysis relies on the segmentation of cell structures to derive quantitative metrics required in biomedical research and clinical diagnostics. State-of-the-art deep learning approaches predominantly apply convolutional layers in segmentation and are typically highly customized for a specific experimental configuration; often unable to generalize to unknown data. As the model capacity of classical convolutional layers is limited by a finite set of learned kernels, our approach uses a graph representation of the image and focuses on the node transitions in multiple magnifications. We propose a novel architecture for semantic segmentation of cell nuclei robust to differences in experimental configuration such as staining and variation of cell types. The architecture is comprised of a novel neuroplastic graph attention network based on residual graph attention layers and concurrent optimization of the graph structure representing multiple magnification levels of the histopathological image. The modification of graph structure, which generates the node features by projection, is as important to the architecture as the graph neural network itself. It determines the possible message flow and critical properties to optimize attention, graph structure, and node updates in a balanced magnification loss. In experimental evaluation, our framework outperforms ensembles of state-of-the-art neural networks, with a fraction of the neurons typically required, and sets new standards for the segmentation of new nuclei datasets.
Colour alignment for relative colour constancy via non-standard references
Dec 30, 2021
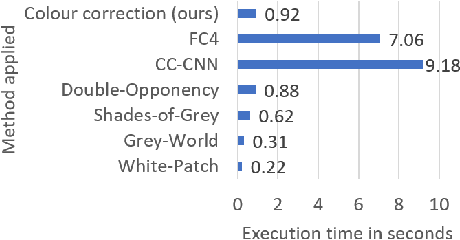
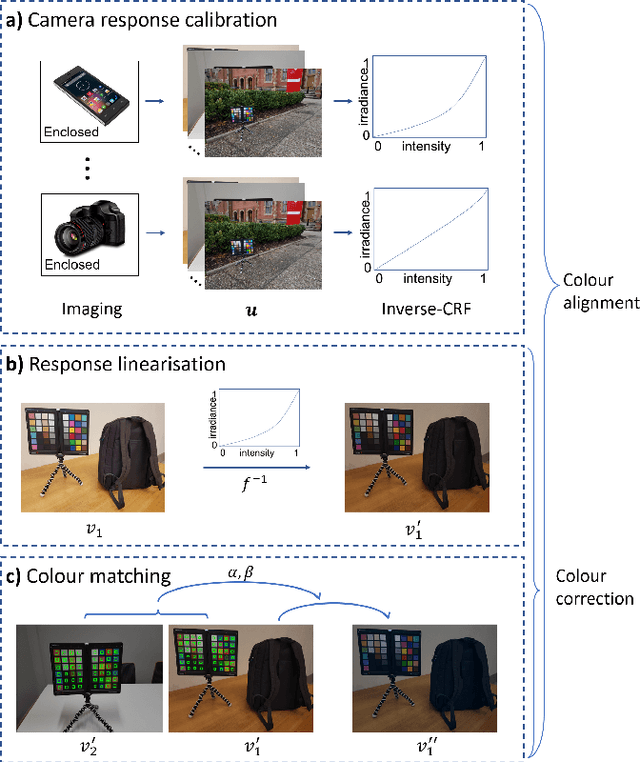
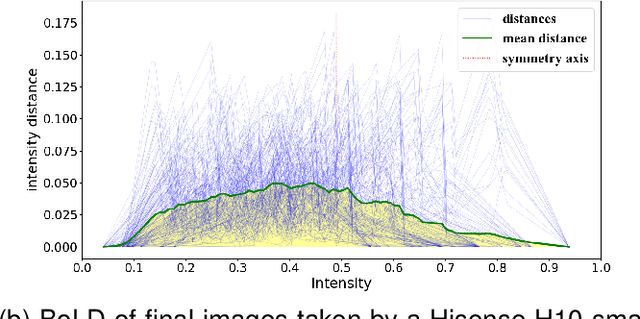
Relative colour constancy is an essential requirement for many scientific imaging applications. However, most digital cameras differ in their image formations and native sensor output is usually inaccessible, e.g., in smartphone camera applications. This makes it hard to achieve consistent colour assessment across a range of devices, and that undermines the performance of computer vision algorithms. To resolve this issue, we propose a colour alignment model that considers the camera image formation as a black-box and formulates colour alignment as a three-step process: camera response calibration, response linearisation, and colour matching. The proposed model works with non-standard colour references, i.e., colour patches without knowing the true colour values, by utilising a novel balance-of-linear-distances feature. It is equivalent to determining the camera parameters through an unsupervised process. It also works with a minimum number of corresponding colour patches across the images to be colour aligned to deliver the applicable processing. Two challenging image datasets collected by multiple cameras under various illumination and exposure conditions were used to evaluate the model. Performance benchmarks demonstrated that our model achieved superior performance compared to other popular and state-of-the-art methods.
Oil Spill SAR Image Segmentation via Probability Distribution Modelling
Dec 17, 2021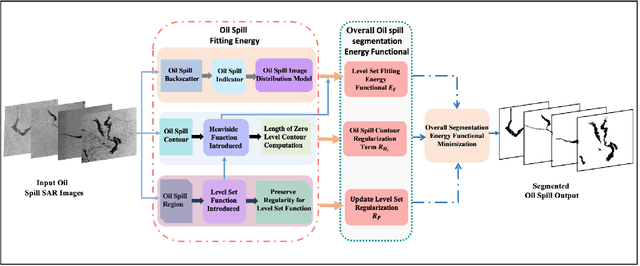
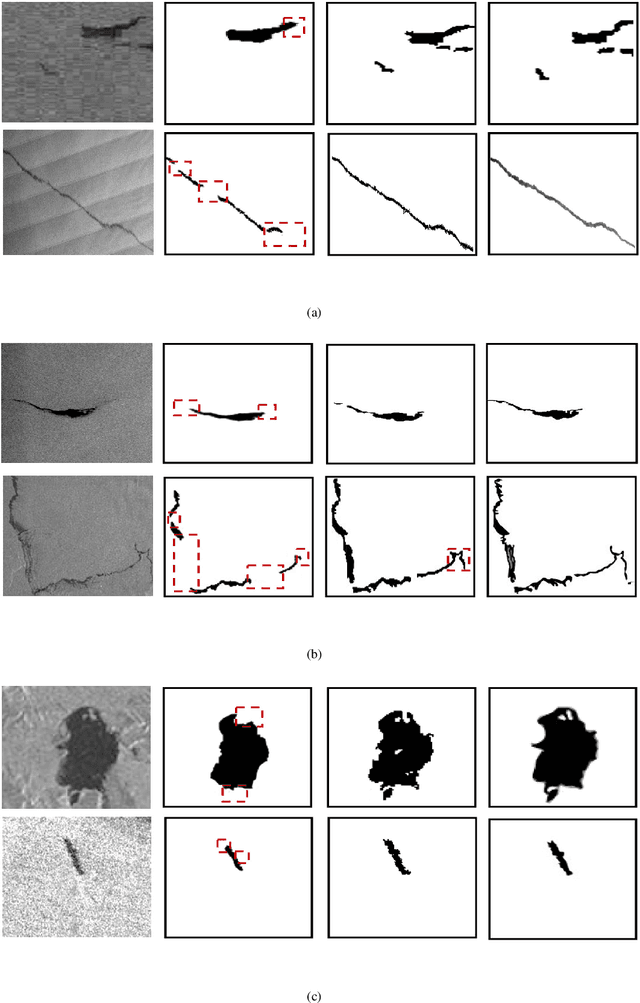
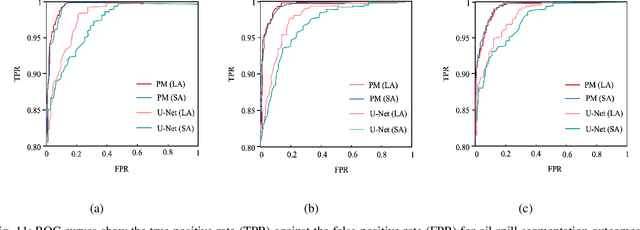

Segmentation of marine oil spills in Synthetic Aperture Radar (SAR) images is a challenging task because of the complexity and irregularities in SAR images. In this work, we aim to develop an effective segmentation method which addresses marine oil spill identification in SAR images by investigating the distribution representation of SAR images. To seek effective oil spill segmentation, we revisit the SAR imaging mechanism in order to attain the probability distribution representation of oil spill SAR images, in which the characteristics of SAR images are properly modelled. We then exploit the distribution representation to formulate the segmentation energy functional, by which oil spill characteristics are incorporated to guide oil spill segmentation. Moreover, the oil spill segmentation model contains the oil spill contour regularisation term and the updated level set regularisation term which enhance the representational power of the segmentation energy functional. Benefiting from the synchronisation of SAR image representation and oil spill segmentation, our proposed method establishes an effective oil spill segmentation framework. Experimental evaluations demonstrate the effectiveness of our proposed segmentation framework for different types of marine oil spill SAR image segmentation.
Anchor Retouching via Model Interaction for Robust Object Detection in Aerial Images
Dec 13, 2021
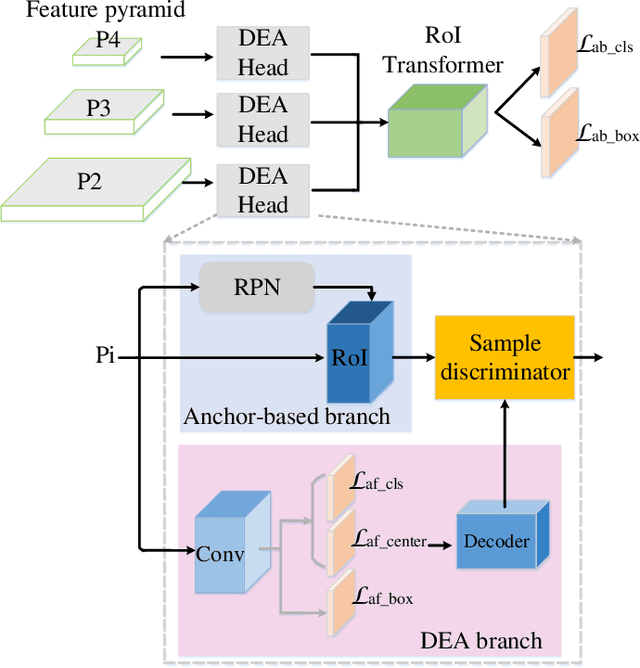
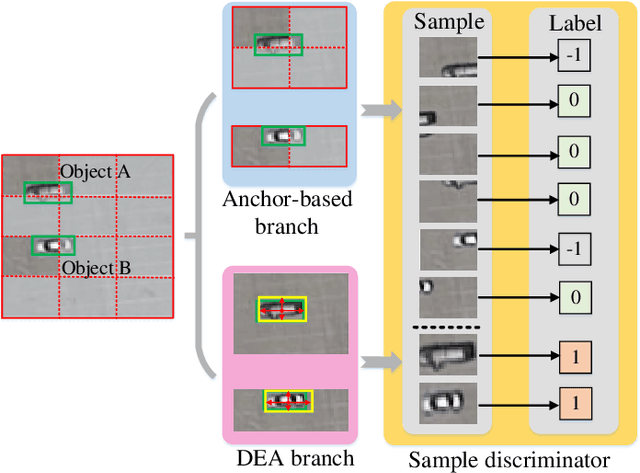
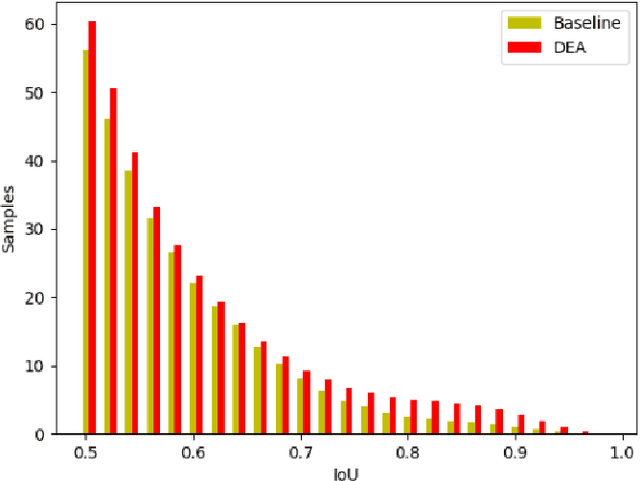
Object detection has made tremendous strides in computer vision. Small object detection with appearance degradation is a prominent challenge, especially for aerial observations. To collect sufficient positive/negative samples for heuristic training, most object detectors preset region anchors in order to calculate Intersection-over-Union (IoU) against the ground-truthed data. In this case, small objects are frequently abandoned or mislabeled. In this paper, we present an effective Dynamic Enhancement Anchor (DEA) network to construct a novel training sample generator. Different from the other state-of-the-art techniques, the proposed network leverages a sample discriminator to realize interactive sample screening between an anchor-based unit and an anchor-free unit to generate eligible samples. Besides, multi-task joint training with a conservative anchor-based inference scheme enhances the performance of the proposed model while reducing computational complexity. The proposed scheme supports both oriented and horizontal object detection tasks. Extensive experiments on two challenging aerial benchmarks (i.e., DOTA and HRSC2016) indicate that our method achieves state-of-the-art performance in accuracy with moderate inference speed and computational overhead for training. On DOTA, our DEA-Net which integrated with the baseline of RoI-Transformer surpasses the advanced method by 0.40% mean-Average-Precision (mAP) for oriented object detection with a weaker backbone network (ResNet-101 vs ResNet-152) and 3.08% mean-Average-Precision (mAP) for horizontal object detection with the same backbone. Besides, our DEA-Net which integrated with the baseline of ReDet achieves the state-of-the-art performance by 80.37%. On HRSC2016, it surpasses the previous best model by 1.1% using only 3 horizontal anchors.
Semantically Contrastive Learning for Low-light Image Enhancement
Dec 13, 2021

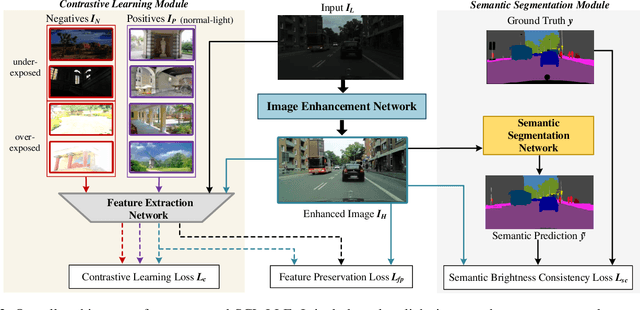

Low-light image enhancement (LLE) remains challenging due to the unfavorable prevailing low-contrast and weak-visibility problems of single RGB images. In this paper, we respond to the intriguing learning-related question -- if leveraging both accessible unpaired over/underexposed images and high-level semantic guidance, can improve the performance of cutting-edge LLE models? Here, we propose an effective semantically contrastive learning paradigm for LLE (namely SCL-LLE). Beyond the existing LLE wisdom, it casts the image enhancement task as multi-task joint learning, where LLE is converted into three constraints of contrastive learning, semantic brightness consistency, and feature preservation for simultaneously ensuring the exposure, texture, and color consistency. SCL-LLE allows the LLE model to learn from unpaired positives (normal-light)/negatives (over/underexposed), and enables it to interact with the scene semantics to regularize the image enhancement network, yet the interaction of high-level semantic knowledge and the low-level signal prior is seldom investigated in previous methods. Training on readily available open data, extensive experiments demonstrate that our method surpasses the state-of-the-arts LLE models over six independent cross-scenes datasets. Moreover, SCL-LLE's potential to benefit the downstream semantic segmentation under extremely dark conditions is discussed. Source Code: https://github.com/LingLIx/SCL-LLE.
Deep Convolution Network Based Emotion Analysis for Automatic Detection of Mild Cognitive Impairment in the Elderly
Nov 09, 2021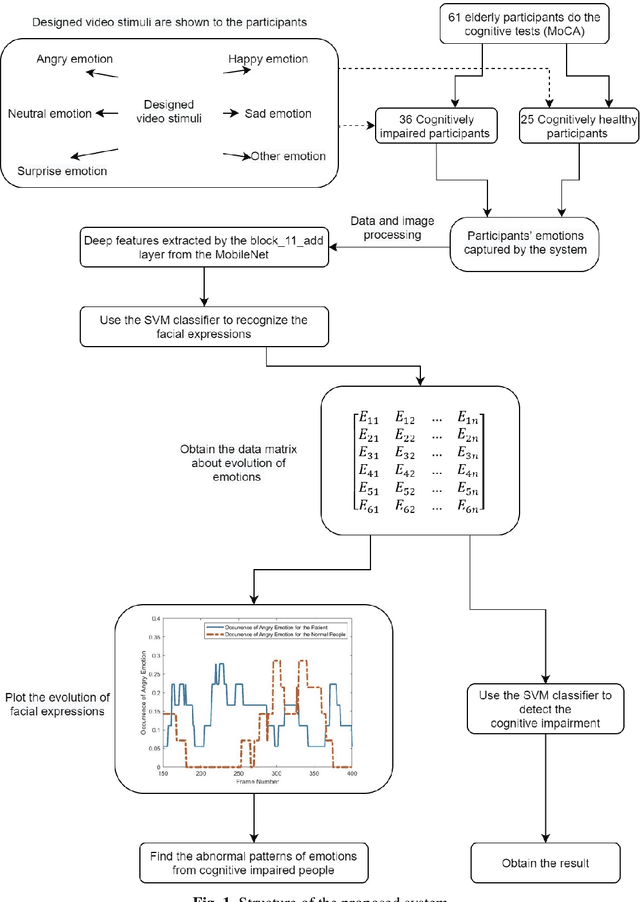
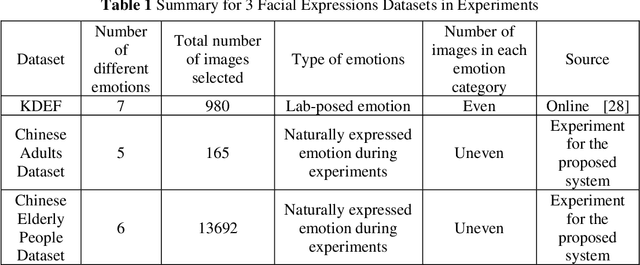
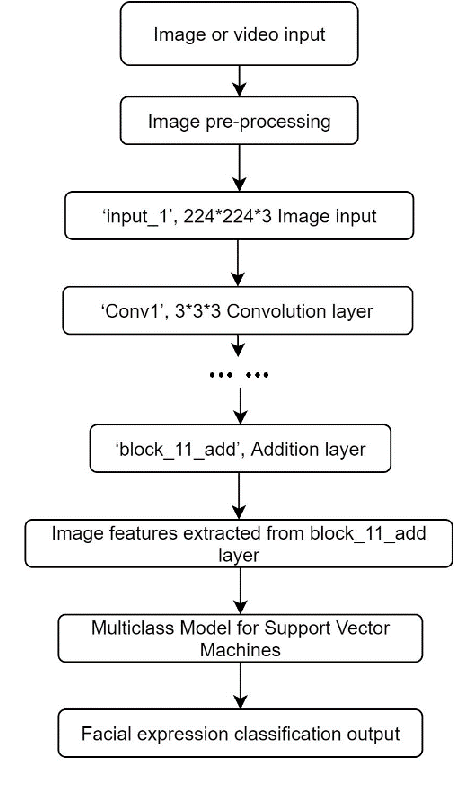
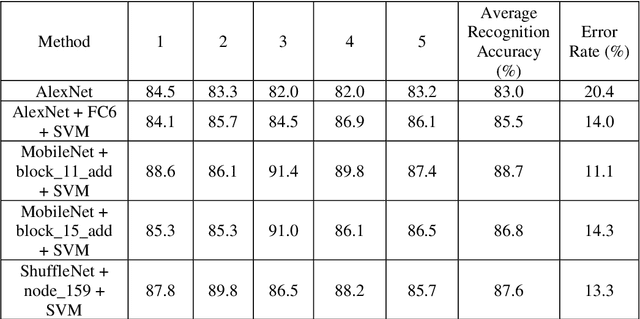
A significant number of people are suffering from cognitive impairment all over the world. Early detection of cognitive impairment is of great importance to both patients and caregivers. However, existing approaches have their shortages, such as time consumption and financial expenses involved in clinics and the neuroimaging stage. It has been found that patients with cognitive impairment show abnormal emotion patterns. In this paper, we present a novel deep convolution network-based system to detect the cognitive impairment through the analysis of the evolution of facial emotions while participants are watching designed video stimuli. In our proposed system, a novel facial expression recognition algorithm is developed using layers from MobileNet and Support Vector Machine (SVM), which showed satisfactory performance in 3 datasets. To verify the proposed system in detecting cognitive impairment, 61 elderly people including patients with cognitive impairment and healthy people as a control group have been invited to participate in the experiments and a dataset was built accordingly. With this dataset, the proposed system has successfully achieved the detection accuracy of 73.3%.
Dispensed Transformer Network for Unsupervised Domain Adaptation
Oct 28, 2021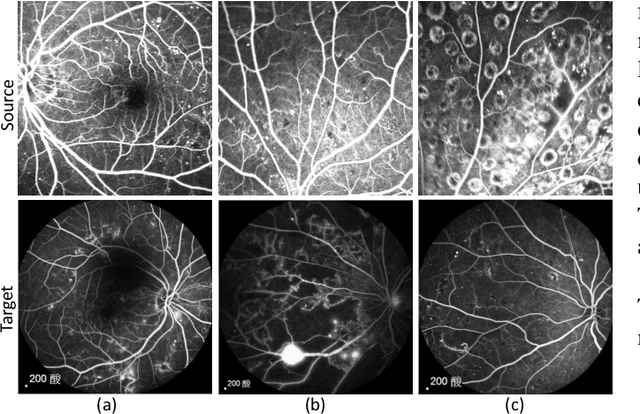
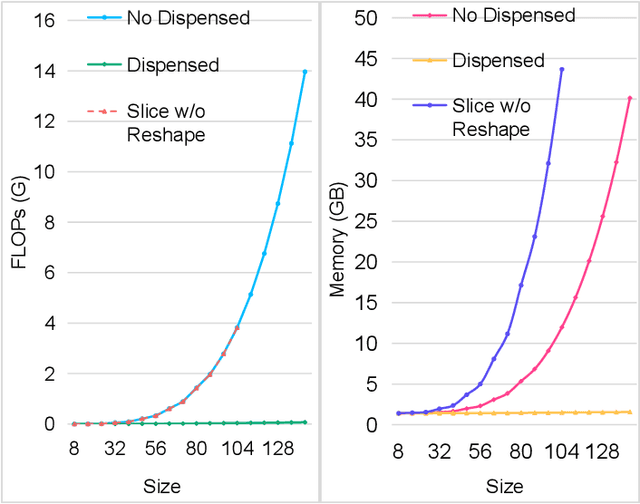
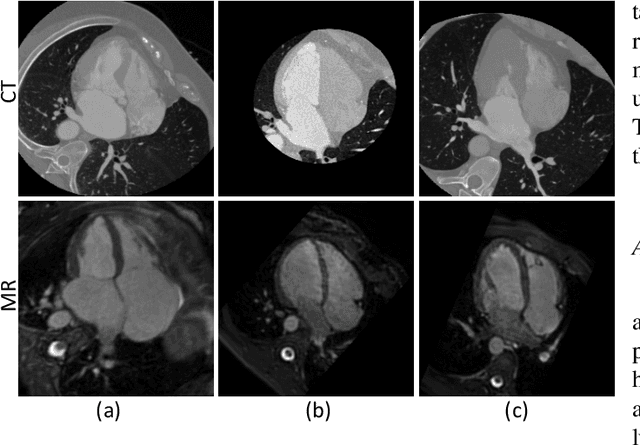
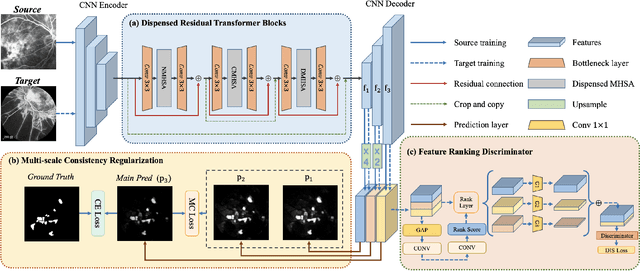
Accurate segmentation is a crucial step in medical image analysis and applying supervised machine learning to segment the organs or lesions has been substantiated effective. However, it is costly to perform data annotation that provides ground truth labels for training the supervised algorithms, and the high variance of data that comes from different domains tends to severely degrade system performance over cross-site or cross-modality datasets. To mitigate this problem, a novel unsupervised domain adaptation (UDA) method named dispensed Transformer network (DTNet) is introduced in this paper. Our novel DTNet contains three modules. First, a dispensed residual transformer block is designed, which realizes global attention by dispensed interleaving operation and deals with the excessive computational cost and GPU memory usage of the Transformer. Second, a multi-scale consistency regularization is proposed to alleviate the loss of details in the low-resolution output for better feature alignment. Finally, a feature ranking discriminator is introduced to automatically assign different weights to domain-gap features to lessen the feature distribution distance, reducing the performance shift of two domains. The proposed method is evaluated on large fluorescein angiography (FA) retinal nonperfusion (RNP) cross-site dataset with 676 images and a wide used cross-modality dataset from the MM-WHS challenge. Extensive results demonstrate that our proposed network achieves the best performance in comparison with several state-of-the-art techniques.
Structure-aware scale-adaptive networks for cancer segmentation in whole-slide images
Sep 26, 2021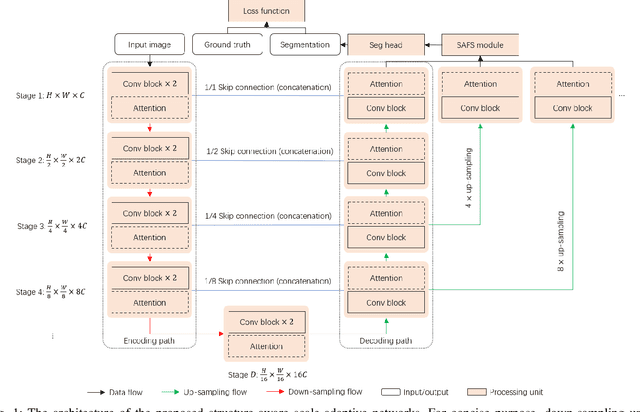

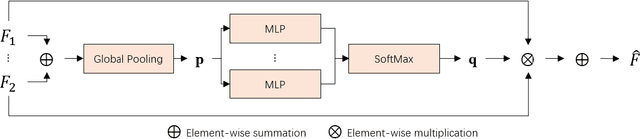
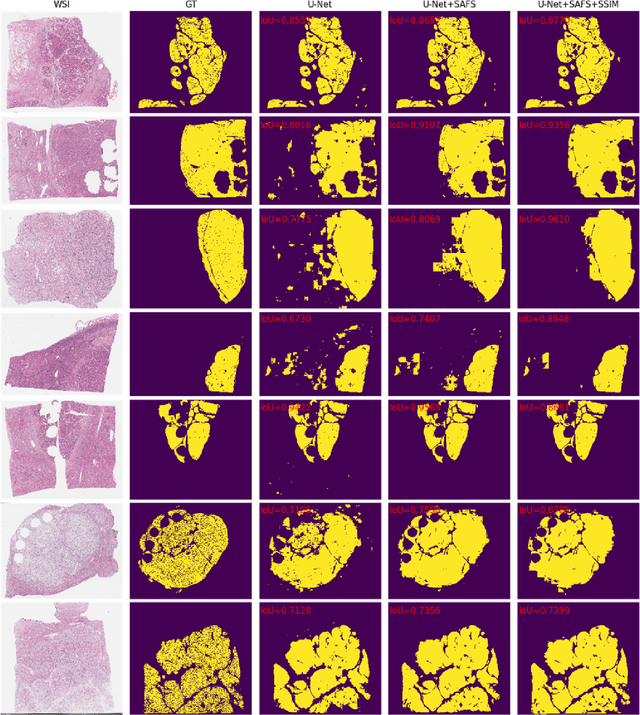
Cancer segmentation in whole-slide images is a fundamental step for viable tumour burden estimation, which is of great value for cancer assessment. However, factors like vague boundaries or small regions dissociated from viable tumour areas make it a challenging task. Considering the usefulness of multi-scale features in various vision-related tasks, we present a structure-aware scale-adaptive feature selection method for efficient and accurate cancer segmentation. Based on a segmentation network with a popular encoder-decoder architecture, a scale-adaptive module is proposed for selecting more robust features to represent the vague, non-rigid boundaries. Furthermore, a structural similarity metric is proposed for better tissue structure awareness to deal with small region segmentation. In addition, advanced designs including several attention mechanisms and the selective-kernel convolutions are applied to the baseline network for comparative study purposes. Extensive experimental results show that the proposed structure-aware scale-adaptive networks achieve outstanding performance on liver cancer segmentation when compared to top ten submitted results in the challenge of PAIP 2019. Further evaluation on colorectal cancer segmentation shows that the scale-adaptive module improves the baseline network or outperforms the other excellent designs of attention mechanisms when considering the tradeoff between efficiency and accuracy.
Robust Ensembling Network for Unsupervised Domain Adaptation
Aug 21, 2021Recently, in order to address the unsupervised domain adaptation (UDA) problem, extensive studies have been proposed to achieve transferrable models. Among them, the most prevalent method is adversarial domain adaptation, which can shorten the distance between the source domain and the target domain. Although adversarial learning is very effective, it still leads to the instability of the network and the drawbacks of confusing category information. In this paper, we propose a Robust Ensembling Network (REN) for UDA, which applies a robust time ensembling teacher network to learn global information for domain transfer. Specifically, REN mainly includes a teacher network and a student network, which performs standard domain adaptation training and updates weights of the teacher network. In addition, we also propose a dual-network conditional adversarial loss to improve the ability of the discriminator. Finally, for the purpose of improving the basic ability of the student network, we utilize the consistency constraint to balance the error between the student network and the teacher network. Extensive experimental results on several UDA datasets have demonstrated the effectiveness of our model by comparing with other state-of-the-art UDA algorithms.
Multi-scale Edge-based U-shape Network for Salient Object Detection
Aug 21, 2021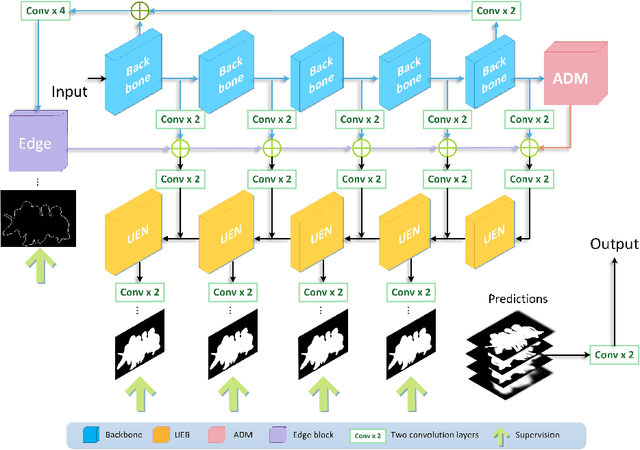
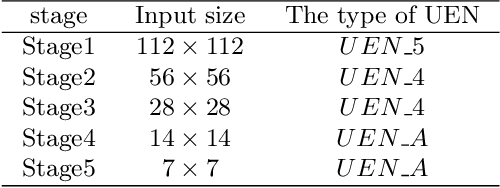
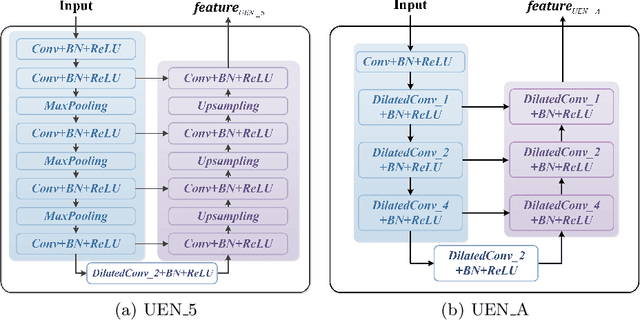
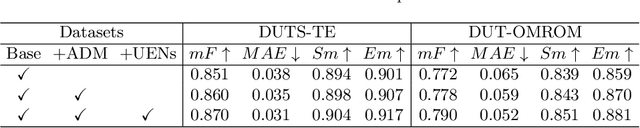
Deep-learning based salient object detection methods achieve great improvements. However, there are still problems existing in the predictions, such as blurry boundary and inaccurate location, which is mainly caused by inadequate feature extraction and integration. In this paper, we propose a Multi-scale Edge-based U-shape Network (MEUN) to integrate various features at different scales to achieve better performance. To extract more useful information for boundary prediction, U-shape Edge Network modules are embedded in each decoder units. Besides, the additional down-sampling module alleviates the location inaccuracy. Experimental results on four benchmark datasets demonstrate the validity and reliability of the proposed method. Multi-scale Edge based U-shape Network also shows its superiority when compared with 15 state-of-the-art salient object detection methods.