 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA New Meta-Baseline for Few-Shot Learning
Apr 01, 2020



Meta-learning has become a popular framework for few-shot learning in recent years, with the goal of learning a model from collections of few-shot classification tasks. While more and more novel meta-learning models are being proposed, our research has uncovered simple baselines that have been overlooked. We present a Meta-Baseline method, by pre-training a classifier on all base classes and meta-learning on a nearest-centroid based few-shot classification algorithm, it outperforms recent state-of-the-art methods by a large margin. Why does this simple method work so well? In the meta-learning stage, we observe that a model generalizing better on unseen tasks from base classes can have a decreasing performance on tasks from novel classes, indicating a potential objective discrepancy. We find both pre-training and inheriting a good few-shot classification metric from the pre-trained classifier are important for Meta-Baseline, which potentially helps the model better utilize the pre-trained representations with stronger transferability. Furthermore, we investigate when we need meta-learning in this Meta-Baseline. Our work sets up a new solid benchmark for this field and sheds light on further understanding the phenomenons in the meta-learning framework for few-shot learning.
Spatio-Temporal Action Detection with Multi-Object Interaction
Apr 01, 2020

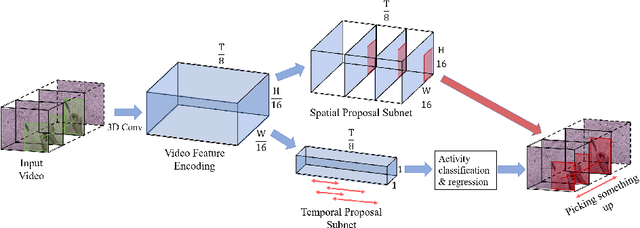
Spatio-temporal action detection in videos requires localizing the action both spatially and temporally in the form of an "action tube". Nowadays, most spatio-temporal action detection datasets (e.g. UCF101-24, AVA, DALY) are annotated with action tubes that contain a single person performing the action, thus the predominant action detection models simply employ a person detection and tracking pipeline for localization. However, when the action is defined as an interaction between multiple objects, such methods may fail since each bounding box in the action tube contains multiple objects instead of one person. In this paper, we study the spatio-temporal action detection problem with multi-object interaction. We introduce a new dataset that is annotated with action tubes containing multi-object interactions. Moreover, we propose an end-to-end spatio-temporal action detection model that performs both spatial and temporal regression simultaneously. Our spatial regression may enclose multiple objects participating in the action. During test time, we simply connect the regressed bounding boxes within the predicted temporal duration using a simple heuristic. We report the baseline results of our proposed model on this new dataset, and also show competitive results on the standard benchmark UCF101-24 using only RGB input.
Weakly-Supervised Action Localization with Expectation-Maximization Multi-Instance Learning
Mar 31, 2020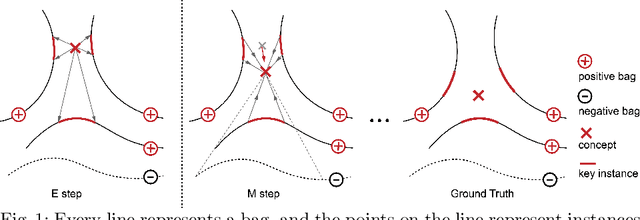
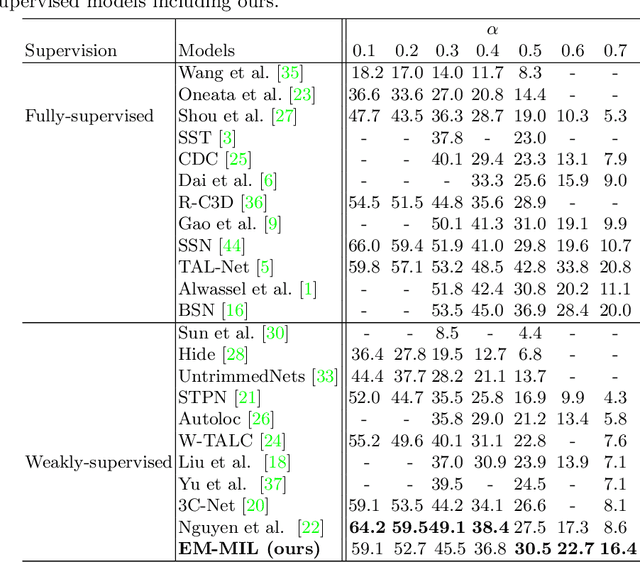
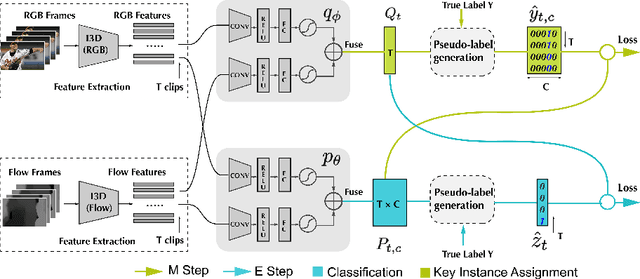
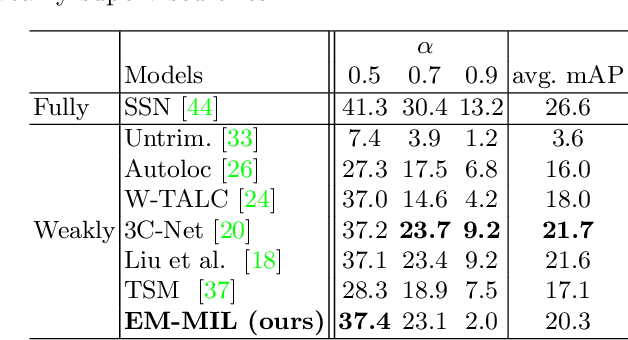
Weakly-supervised action localization problem requires training a model to localize the action segments in the video given only video level action label. It can be solved under the Multiple Instance Learning (MIL) framework, where a bag (video) contains multiple instances (action segments). Since only the bag's label is known, the main challenge is to assign which key instances within the bag trigger the bag's label. Most previous models use an attention-based approach. These models use attention to generate the bag's representation from instances and then train it via bag's classification. In this work, we explicitly model the key instances assignment as a hidden variable and adopt an Expectation-Maximization framework. We derive two pseudo-label generation schemes to model the E and M process and iteratively optimize the likelihood lower bound. We also show that previous attention-based models implicitly violate the MIL assumptions that instances in negative bags should be uniformly negative. In comparison, Our EM-MIL approach more accurately models these assumptions. Our model achieves state-of-the-art performance on two standard benchmarks, THUMOS14 and ActivityNet1.2, and shows the superiority of detecting relative complete action boundary in videos containing multiple actions.
Revisiting Few-shot Activity Detection with Class Similarity Control
Mar 31, 2020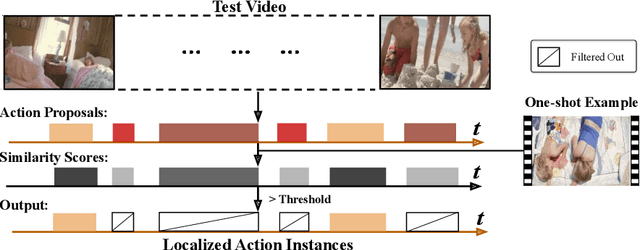
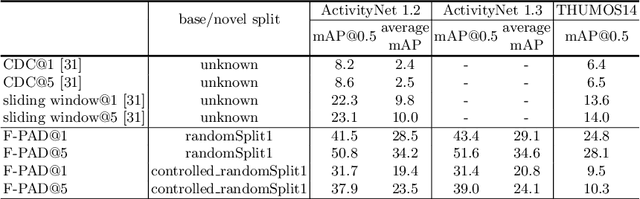
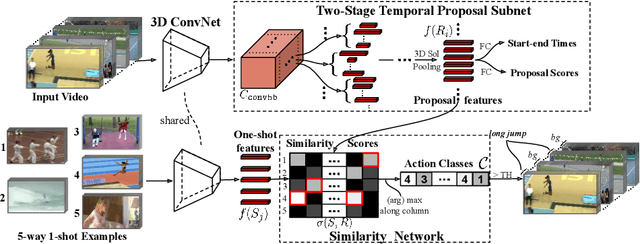
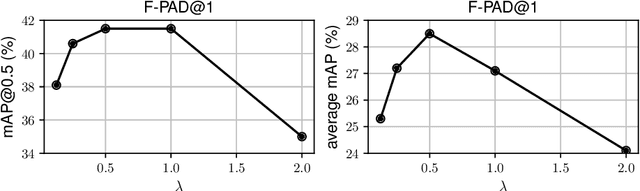
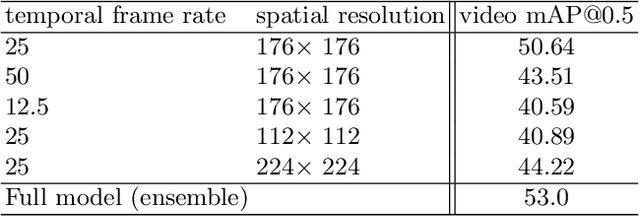
Many interesting events in the real world are rare making preannotated machine learning ready videos a rarity in consequence. Thus, temporal activity detection models that are able to learn from a few examples are desirable. In this paper, we present a conceptually simple and general yet novel framework for few-shot temporal activity detection based on proposal regression which detects the start and end time of the activities in untrimmed videos. Our model is end-to-end trainable, takes into account the frame rate differences between few-shot activities and untrimmed test videos, and can benefit from additional few-shot examples. We experiment on three large scale benchmarks for temporal activity detection (ActivityNet1.2, ActivityNet1.3 and THUMOS14 datasets) in a few-shot setting. We also study the effect on performance of different amount of overlap with activities used to pretrain the video classification backbone and propose corrective measures for future works in this domain. Our code will be made available.
Something-Else: Compositional Action Recognition with Spatial-Temporal Interaction Networks
Dec 20, 2019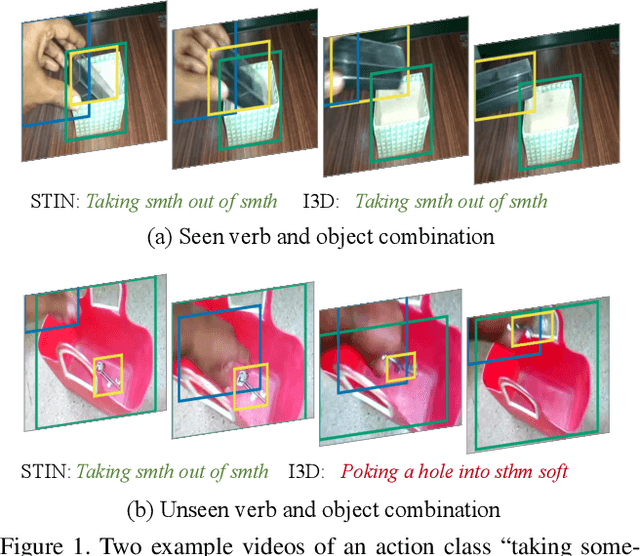
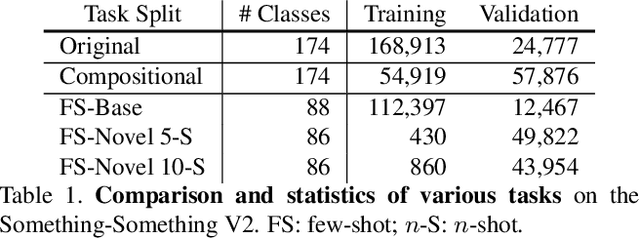
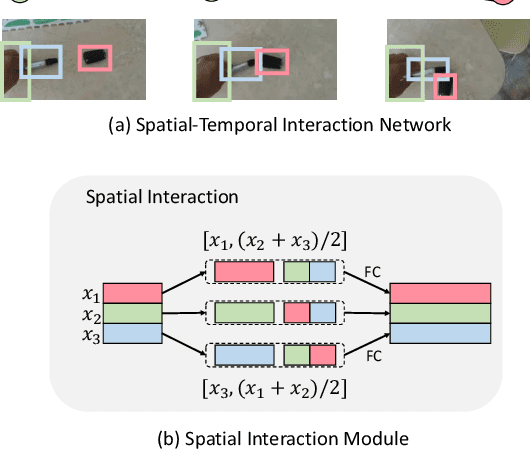
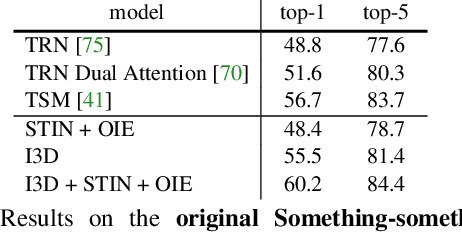
Human action is naturally compositional: humans can easily recognize and perform actions with objects that are different from those used in training demonstrations. In this paper, we study the compositionality of action by looking into the dynamics of subject-object interactions. We propose a novel model which can explicitly reason about the geometric relations between constituent objects and an agent performing an action. To train our model, we collect dense object box annotations on the Something-Something dataset. We propose a novel compositional action recognition task where the training combinations of verbs and nouns do not overlap with the test set. The novel aspects of our model are applicable to activities with prominent object interaction dynamics and to objects which can be tracked using state-of-the-art approaches; for activities without clearly defined spatial object-agent interactions, we rely on baseline scene-level spatio-temporal representations. We show the effectiveness of our approach not only on the proposed compositional action recognition task, but also in a few-shot compositional setting which requires the model to generalize across both object appearance and action category.
Learning Canonical Representations for Scene Graph to Image Generation
Dec 16, 2019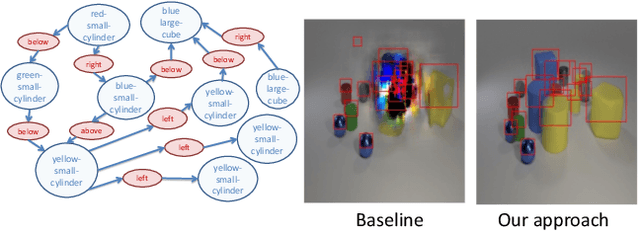
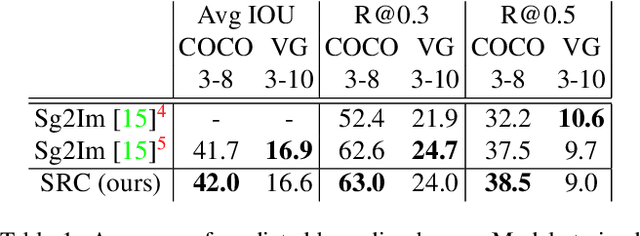
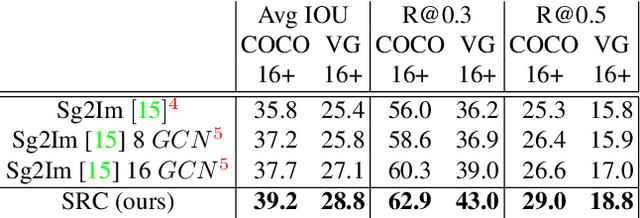
Generating realistic images of complex visual scenes becomes very challenging when one wishes to control the structure of the generated images. Previous approaches showed that scenes with few entities can be controlled using scene graphs, but this approach struggles as the complexity of the graph (number of objects and edges) increases. Moreover, current approaches fail to generalize conditioned on the number of objects or when given different input graphs which are semantic equivalent. In this work, we propose a novel approach to mitigate these issues. We present a novel model which can inherently learn canonical graph representations, thus ensuring that semantically similar scene graphs will result in similar predictions. In addition, the proposed model can better capture object representation independently of the number of objects in the graph. We show improved performance of the model on three different benchmarks: Visual Genome, COCO and CLEVR.
wMAN: Weakly-supervised Moment Alignment Network for Text-based Video Segment Retrieval
Sep 27, 2019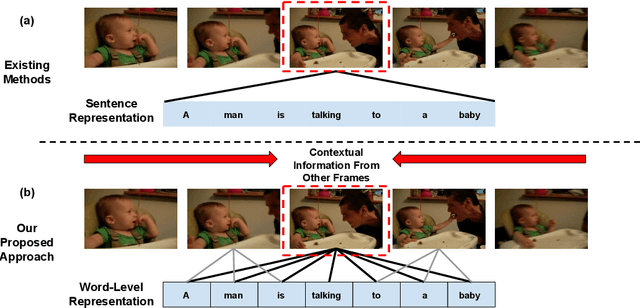

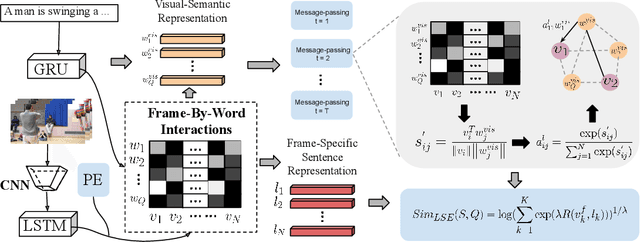
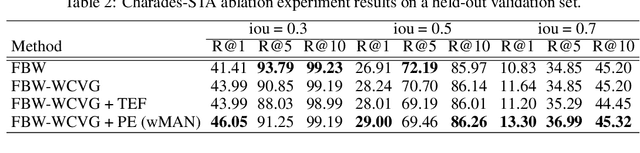
Given a video and a sentence, the goal of weakly-supervised video moment retrieval is to locate the video segment which is described by the sentence without having access to temporal annotations during training. Instead, a model must learn how to identify the correct segment (i.e. moment) when only being provided with video-sentence pairs. Thus, an inherent challenge is automatically inferring the latent correspondence between visual and language representations. To facilitate this alignment, we propose our Weakly-supervised Moment Alignment Network (wMAN) which exploits a multi-level co-attention mechanism to learn richer multimodal representations. The aforementioned mechanism is comprised of a Frame-By-Word interaction module as well as a novel Word-Conditioned Visual Graph (WCVG). Our approach also incorporates a novel application of positional encodings, commonly used in Transformers, to learn visual-semantic representations that contain contextual information of their relative positions in the temporal sequence through iterative message-passing. Comprehensive experiments on the DiDeMo and Charades-STA datasets demonstrate the effectiveness of our learned representations: our combined wMAN model not only outperforms the state-of-the-art weakly-supervised method by a significant margin but also does better than strongly-supervised state-of-the-art methods on some metrics.
Multi-user Resource Control with Deep Reinforcement Learning in IoT Edge Computing
Jun 19, 2019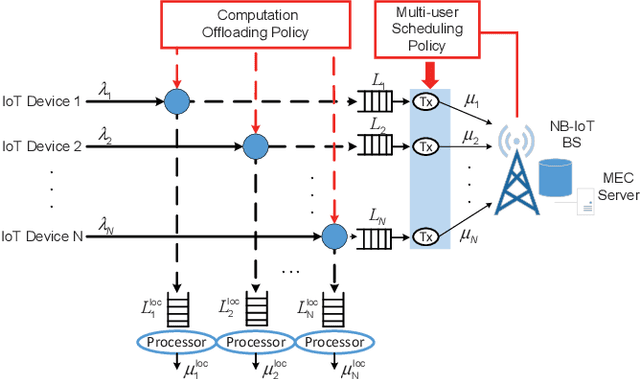
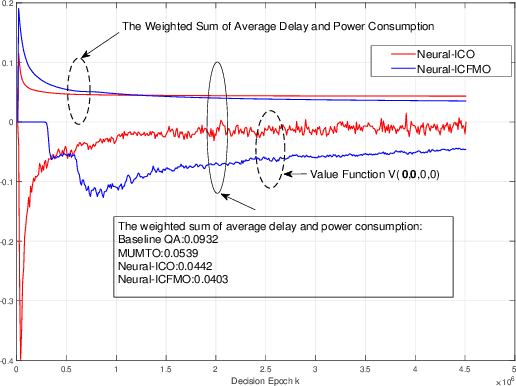
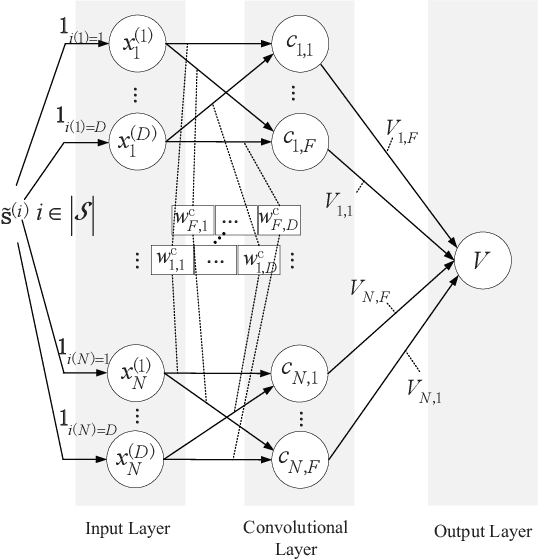
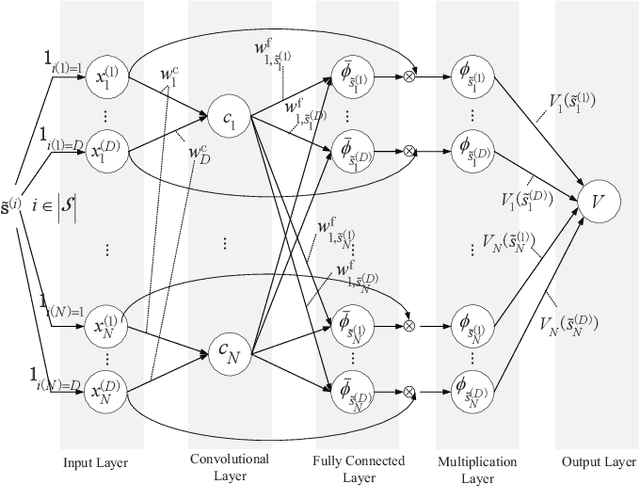
By leveraging the concept of mobile edge computing (MEC), massive amount of data generated by a large number of Internet of Things (IoT) devices could be offloaded to MEC server at the edge of wireless network for further computational intensive processing. However, due to the resource constraint of IoT devices and wireless network, both the communications and computation resources need to be allocated and scheduled efficiently for better system performance. In this paper, we propose a joint computation offloading and multi-user scheduling algorithm for IoT edge computing system to minimize the long-term average weighted sum of delay and power consumption under stochastic traffic arrival. We formulate the dynamic optimization problem as an infinite-horizon average-reward continuous-time Markov decision process (CTMDP) model. One critical challenge in solving this MDP problem for the multi-user resource control is the curse-of-dimensionality problem, where the state space of the MDP model and the computation complexity increase exponentially with the growing number of users or IoT devices. In order to overcome this challenge, we use the deep reinforcement learning (RL) techniques and propose a neural network architecture to approximate the value functions for the post-decision system states. The designed algorithm to solve the CTMDP problem supports semi-distributed auction-based implementation, where the IoT devices submit bids to the BS to make the resource control decisions centrally. Simulation results show that the proposed algorithm provides significant performance improvement over the baseline algorithms, and also outperforms the RL algorithms based on other neural network architectures.
Two-Stream Region Convolutional 3D Network for Temporal Activity Detection
Jun 05, 2019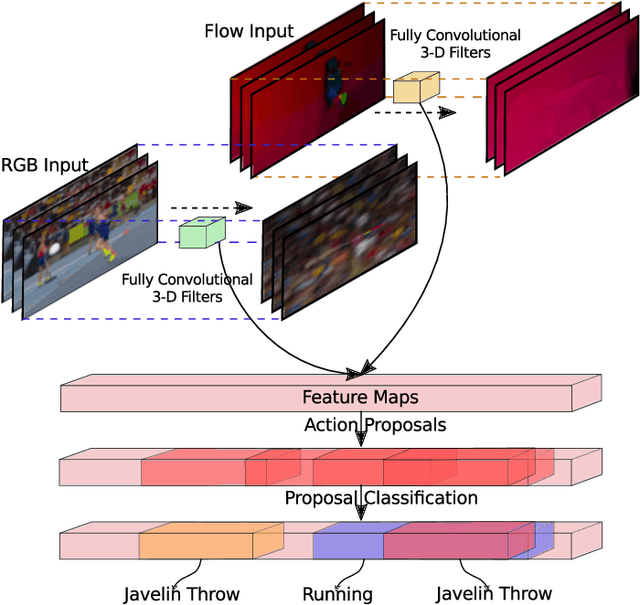

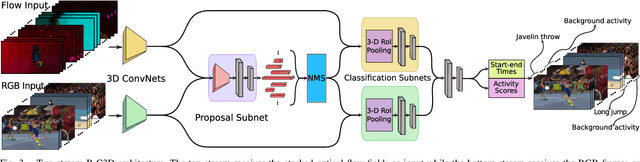

We address the problem of temporal activity detection in continuous, untrimmed video streams. This is a difficult task that requires extracting meaningful spatio-temporal features to capture activities, accurately localizing the start and end times of each activity. We introduce a new model, Region Convolutional 3D Network (R-C3D), which encodes the video streams using a three-dimensional fully convolutional network, then generates candidate temporal regions containing activities and finally classifies selected regions into specific activities. Computation is saved due to the sharing of convolutional features between the proposal and the classification pipelines. We further improve the detection performance by efficiently integrating an optical flow based motion stream with the original RGB stream. The two-stream network is jointly optimized by fusing the flow and RGB feature maps at different levels. Additionally, the training stage incorporates an online hard example mining strategy to address the extreme foreground-background imbalance typically observed in any detection pipeline. Instead of heuristically sampling the candidate segments for the final activity classification stage, we rank them according to their performance and only select the worst performers to update the model. This improves the model without heavy hyper-parameter tuning. Extensive experiments on three benchmark datasets are carried out to show superior performance over existing temporal activity detection methods. Our model achieves state-of-the-art results on the THUMOS'14 and Charades datasets. We further demonstrate that our model is a general temporal activity detection framework that does not rely on assumptions about particular dataset properties by evaluating our approach on the ActivityNet dataset.
Similarity R-C3D for Few-shot Temporal Activity Detection
Dec 25, 2018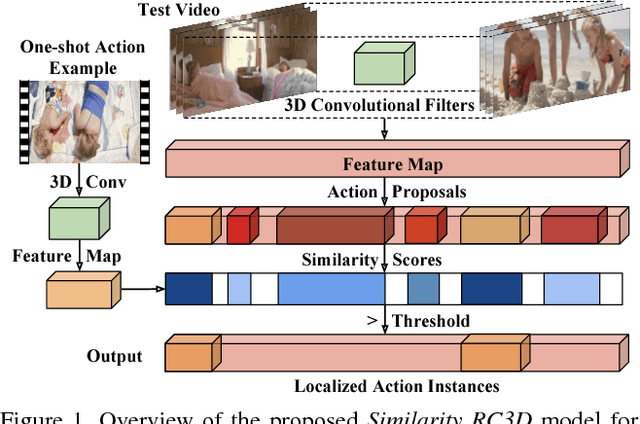
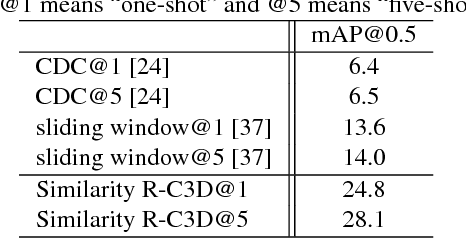
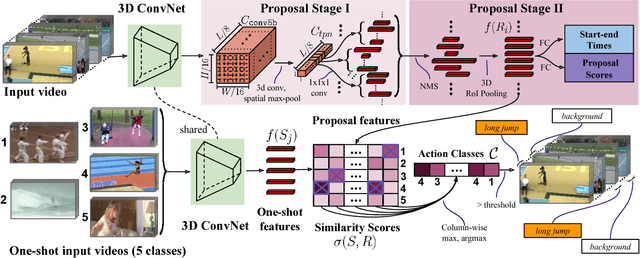
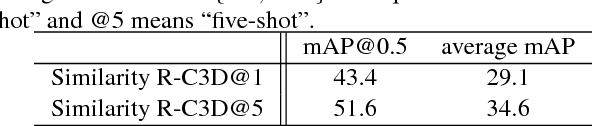
Many activities of interest are rare events, with only a few labeled examples available. Therefore models for temporal activity detection which are able to learn from a few examples are desirable. In this paper, we present a conceptually simple and general yet novel framework for few-shot temporal activity detection which detects the start and end time of the few-shot input activities in an untrimmed video. Our model is end-to-end trainable and can benefit from more few-shot examples. At test time, each proposal is assigned the label of the few-shot activity class corresponding to the maximum similarity score. Our Similarity R-C3D method outperforms previous work on three large-scale benchmarks for temporal activity detection (THUMOS14, ActivityNet1.2, and ActivityNet1.3 datasets) in the few-shot setting. Our code will be made available.