 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multimodal Fusion of Data with Heterogeneous Dimensionality via Projective Networks
Feb 02, 2024



The use of multimodal imaging has led to significant improvements in the diagnosis and treatment of many diseases. Similar to clinical practice, some works have demonstrated the benefits of multimodal fusion for automatic segmentation and classification using deep learning-based methods. However, current segmentation methods are limited to fusion of modalities with the same dimensionality (e.g., 3D+3D, 2D+2D), which is not always possible, and the fusion strategies implemented by classification methods are incompatible with localization tasks. In this work, we propose a novel deep learning-based framework for the fusion of multimodal data with heterogeneous dimensionality (e.g., 3D+2D) that is compatible with localization tasks. The proposed framework extracts the features of the different modalities and projects them into the common feature subspace. The projected features are then fused and further processed to obtain the final prediction. The framework was validated on the following tasks: segmentation of geographic atrophy (GA), a late-stage manifestation of age-related macular degeneration, and segmentation of retinal blood vessels (RBV) in multimodal retinal imaging. Our results show that the proposed method outperforms the state-of-the-art monomodal methods on GA and RBV segmentation by up to 3.10% and 4.64% Dice, respectively.
3DTINC: Time-Equivariant Non-Contrastive Learning for Predicting Disease Progression from Longitudinal OCTs
Dec 28, 2023



Self-supervised learning (SSL) has emerged as a powerful technique for improving the efficiency and effectiveness of deep learning models. Contrastive methods are a prominent family of SSL that extract similar representations of two augmented views of an image while pushing away others in the representation space as negatives. However, the state-of-the-art contrastive methods require large batch sizes and augmentations designed for natural images that are impractical for 3D medical images. To address these limitations, we propose a new longitudinal SSL method, 3DTINC, based on non-contrastive learning. It is designed to learn perturbation-invariant features for 3D optical coherence tomography (OCT) volumes, using augmentations specifically designed for OCT. We introduce a new non-contrastive similarity loss term that learns temporal information implicitly from intra-patient scans acquired at different times. Our experiments show that this temporal information is crucial for predicting progression of retinal diseases, such as age-related macular degeneration (AMD). After pretraining with 3DTINC, we evaluated the learned representations and the prognostic models on two large-scale longitudinal datasets of retinal OCTs where we predict the conversion to wet-AMD within a six months interval. Our results demonstrate that each component of our contributions is crucial for learning meaningful representations useful in predicting disease progression from longitudinal volumetric scans.
SAMedOCT: Adapting Segment Anything Model (SAM) for Retinal OCT
Aug 31, 2023The Segment Anything Model (SAM) has gained significant attention in the field of image segmentation due to its impressive capabilities and prompt-based interface. While SAM has already been extensively evaluated in various domains, its adaptation to retinal OCT scans remains unexplored. To bridge this research gap, we conduct a comprehensive evaluation of SAM and its adaptations on a large-scale public dataset of OCTs from RETOUCH challenge. Our evaluation covers diverse retinal diseases, fluid compartments, and device vendors, comparing SAM against state-of-the-art retinal fluid segmentation methods. Through our analysis, we showcase adapted SAM's efficacy as a powerful segmentation model in retinal OCT scans, although still lagging behind established methods in some circumstances. The findings highlight SAM's adaptability and robustness, showcasing its utility as a valuable tool in retinal OCT image analysis and paving the way for further advancements in this domain.
Pretrained Deep 2.5D Models for Efficient Predictive Modeling from Retinal OCT
Jul 25, 2023In the field of medical imaging, 3D deep learning models play a crucial role in building powerful predictive models of disease progression. However, the size of these models presents significant challenges, both in terms of computational resources and data requirements. Moreover, achieving high-quality pretraining of 3D models proves to be even more challenging. To address these issues, hybrid 2.5D approaches provide an effective solution for utilizing 3D volumetric data efficiently using 2D models. Combining 2D and 3D techniques offers a promising avenue for optimizing performance while minimizing memory requirements. In this paper, we explore 2.5D architectures based on a combination of convolutional neural networks (CNNs), long short-term memory (LSTM), and Transformers. In addition, leveraging the benefits of recent non-contrastive pretraining approaches in 2D, we enhanced the performance and data efficiency of 2.5D techniques even further. We demonstrate the effectiveness of architectures and associated pretraining on a task of predicting progression to wet age-related macular degeneration (AMD) within a six-month period on two large longitudinal OCT datasets.
Self-supervised learning via inter-modal reconstruction and feature projection networks for label-efficient 3D-to-2D segmentation
Jul 13, 2023Deep learning has become a valuable tool for the automation of certain medical image segmentation tasks, significantly relieving the workload of medical specialists. Some of these tasks require segmentation to be performed on a subset of the input dimensions, the most common case being 3D-to-2D. However, the performance of existing methods is strongly conditioned by the amount of labeled data available, as there is currently no data efficient method, e.g. transfer learning, that has been validated on these tasks. In this work, we propose a novel convolutional neural network (CNN) and self-supervised learning (SSL) method for label-efficient 3D-to-2D segmentation. The CNN is composed of a 3D encoder and a 2D decoder connected by novel 3D-to-2D blocks. The SSL method consists of reconstructing image pairs of modalities with different dimensionality. The approach has been validated in two tasks with clinical relevance: the en-face segmentation of geographic atrophy and reticular pseudodrusen in optical coherence tomography. Results on different datasets demonstrate that the proposed CNN significantly improves the state of the art in scenarios with limited labeled data by up to 8% in Dice score. Moreover, the proposed SSL method allows further improvement of this performance by up to 23%, and we show that the SSL is beneficial regardless of the network architecture.
PALM: Open Fundus Photograph Dataset with Pathologic Myopia Recognition and Anatomical Structure Annotation
May 13, 2023Pathologic myopia (PM) is a common blinding retinal degeneration suffered by highly myopic population. Early screening of this condition can reduce the damage caused by the associated fundus lesions and therefore prevent vision loss. Automated diagnostic tools based on artificial intelligence methods can benefit this process by aiding clinicians to identify disease signs or to screen mass populations using color fundus photographs as inputs. This paper provides insights about PALM, our open fundus imaging dataset for pathological myopia recognition and anatomical structure annotation. Our databases comprises 1200 images with associated labels for the pathologic myopia category and manual annotations of the optic disc, the position of the fovea and delineations of lesions such as patchy retinal atrophy (including peripapillary atrophy) and retinal detachment. In addition, this paper elaborates on other details such as the labeling process used to construct the database, the quality and characteristics of the samples and provides other relevant usage notes.
Morph-SSL: Self-Supervision with Longitudinal Morphing to Predict AMD Progression from OCT
Apr 17, 2023



The lack of reliable biomarkers makes predicting the conversion from intermediate to neovascular age-related macular degeneration (iAMD, nAMD) a challenging task. We develop a Deep Learning (DL) model to predict the future risk of conversion of an eye from iAMD to nAMD from its current OCT scan. Although eye clinics generate vast amounts of longitudinal OCT scans to monitor AMD progression, only a small subset can be manually labeled for supervised DL. To address this issue, we propose Morph-SSL, a novel Self-supervised Learning (SSL) method for longitudinal data. It uses pairs of unlabelled OCT scans from different visits and involves morphing the scan from the previous visit to the next. The Decoder predicts the transformation for morphing and ensures a smooth feature manifold that can generate intermediate scans between visits through linear interpolation. Next, the Morph-SSL trained features are input to a Classifier which is trained in a supervised manner to model the cumulative probability distribution of the time to conversion with a sigmoidal function. Morph-SSL was trained on unlabelled scans of 399 eyes (3570 visits). The Classifier was evaluated with a five-fold cross-validation on 2418 scans from 343 eyes with clinical labels of the conversion date. The Morph-SSL features achieved an AUC of 0.766 in predicting the conversion to nAMD within the next 6 months, outperforming the same network when trained end-to-end from scratch or pre-trained with popular SSL methods. Automated prediction of the future risk of nAMD onset can enable timely treatment and individualized AMD management.
AIROGS: Artificial Intelligence for RObust Glaucoma Screening Challenge
Feb 10, 2023



The early detection of glaucoma is essential in preventing visual impairment. Artificial intelligence (AI) can be used to analyze color fundus photographs (CFPs) in a cost-effective manner, making glaucoma screening more accessible. While AI models for glaucoma screening from CFPs have shown promising results in laboratory settings, their performance decreases significantly in real-world scenarios due to the presence of out-of-distribution and low-quality images. To address this issue, we propose the Artificial Intelligence for Robust Glaucoma Screening (AIROGS) challenge. This challenge includes a large dataset of around 113,000 images from about 60,000 patients and 500 different screening centers, and encourages the development of algorithms that are robust to ungradable and unexpected input data. We evaluated solutions from 14 teams in this paper, and found that the best teams performed similarly to a set of 20 expert ophthalmologists and optometrists. The highest-scoring team achieved an area under the receiver operating characteristic curve of 0.99 (95% CI: 0.98-0.99) for detecting ungradable images on-the-fly. Additionally, many of the algorithms showed robust performance when tested on three other publicly available datasets. These results demonstrate the feasibility of robust AI-enabled glaucoma screening.
Clustering disease trajectories in contrastive feature space for biomarker discovery in age-related macular degeneration
Jan 11, 2023Age-related macular degeneration (AMD) is the leading cause of blindness in the elderly. Despite this, the exact dynamics of disease progression are poorly understood. There is a clear need for imaging biomarkers in retinal optical coherence tomography (OCT) that aid the diagnosis, prognosis and management of AMD. However, current grading systems, which coarsely group disease stage into broad categories describing early and intermediate AMD, have very limited prognostic value for the conversion to late AMD. In this paper, we are the first to analyse disease progression as clustered trajectories in a self-supervised feature space. Our method first pretrains an encoder with contrastive learning to project images from longitudinal time series to points in feature space. This enables the creation of disease trajectories, which are then denoised, partitioned and grouped into clusters. These clusters, found in two datasets containing time series of 7,912 patients imaged over eight years, were correlated with known OCT biomarkers. This reinforced efforts by four expert ophthalmologists to investigate clusters, during a clinical comparison and interpretation task, as candidates for time-dependent biomarkers that describe progression of AMD.
Metadata-enhanced contrastive learning from retinal optical coherence tomography images
Aug 04, 2022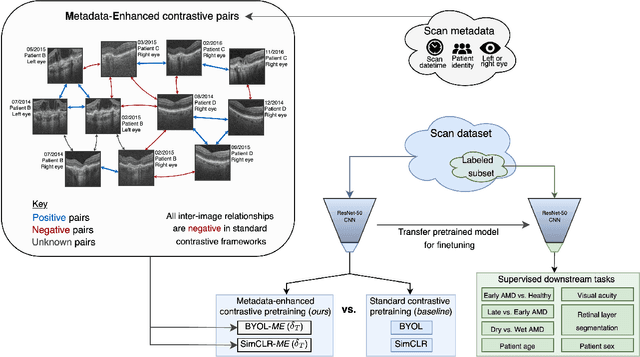
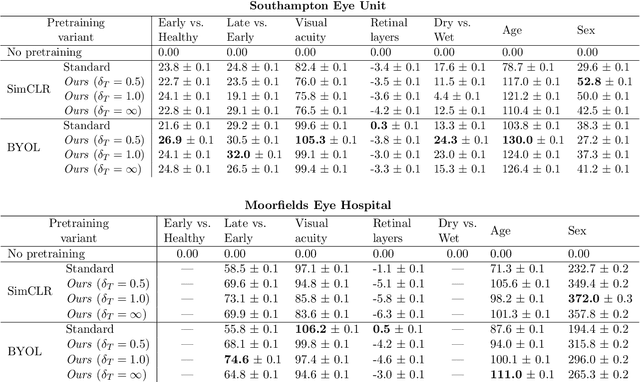
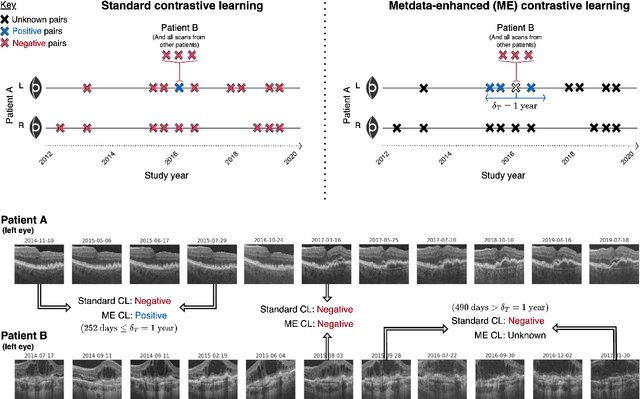
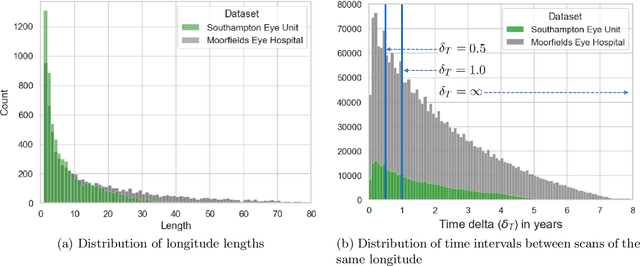
Supervised deep learning algorithms hold great potential to automate screening, monitoring and grading of medical images. However, training performant models has typically required vast quantities of labelled data, which is scarcely available in the medical domain. Self-supervised contrastive frameworks relax this dependency by first learning from unlabelled images. In this work we show that pretraining with two contrastive methods, SimCLR and BYOL, improves the utility of deep learning with regard to the clinical assessment of age-related macular degeneration (AMD). In experiments using two large clinical datasets containing 170,427 optical coherence tomography (OCT) images of 7,912 patients, we evaluate benefits attributed to pretraining across seven downstream tasks ranging from AMD stage and type classification to prediction of functional endpoints to segmentation of retinal layers, finding performance significantly increased in six out of seven tasks with fewer labels. However, standard contrastive frameworks have two known weaknesses that are detrimental to pretraining in the medical domain. Several of the image transformations used to create positive contrastive pairs are not applicable to greyscale medical scans. Furthermore, medical images often depict the same anatomical region and disease severity, resulting in numerous misleading negative pairs. To address these issues we develop a novel metadata-enhanced approach that exploits the rich set of inherently available patient information. To this end we employ records for patient identity, eye position (i.e. left or right) and time series data to indicate the typically unknowable set of inter-image contrastive relationships. By leveraging this often neglected information our metadata-enhanced contrastive pretraining leads to further benefits and outperforms conventional contrastive methods in five out of seven downstream tasks.