 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobGC: Towards Robust Graph Condensation
Jun 19, 2024



Graph neural networks (GNNs) have attracted widespread attention for their impressive capability of graph representation learning. However, the increasing prevalence of large-scale graphs presents a significant challenge for GNN training due to their computational demands, limiting the applicability of GNNs in various scenarios. In response to this challenge, graph condensation (GC) is proposed as a promising acceleration solution, focusing on generating an informative compact graph that enables efficient training of GNNs while retaining performance. Despite the potential to accelerate GNN training, existing GC methods overlook the quality of large training graphs during both the training and inference stages. They indiscriminately emulate the training graph distributions, making the condensed graphs susceptible to noises within the training graph and significantly impeding the application of GC in intricate real-world scenarios. To address this issue, we propose robust graph condensation (RobGC), a plug-and-play approach for GC to extend the robustness and applicability of condensed graphs in noisy graph structure environments. Specifically, RobGC leverages the condensed graph as a feedback signal to guide the denoising process on the original training graph. A label propagation-based alternating optimization strategy is in place for the condensation and denoising processes, contributing to the mutual purification of the condensed graph and training graph. Additionally, as a GC method designed for inductive graph inference, RobGC facilitates test-time graph denoising by leveraging the noise-free condensed graph to calibrate the structure of the test graph. Extensive experiments show that RobGC is compatible with various GC methods, significantly boosting their robustness under different types and levels of graph structural noises.
PTF-FSR: A Parameter Transmission-Free Federated Sequential Recommender System
Jun 08, 2024Sequential recommender systems have made significant progress. Recently, due to increasing concerns about user data privacy, some researchers have implemented federated learning for sequential recommendation, a.k.a., Federated Sequential Recommender Systems (FedSeqRecs), in which a public sequential recommender model is shared and frequently transmitted between a central server and clients to achieve collaborative learning. Although these solutions mitigate user privacy to some extent, they present two significant limitations that affect their practical usability: (1) They require a globally shared sequential recommendation model. However, in real-world scenarios, the recommendation model constitutes a critical intellectual property for platform and service providers. Therefore, service providers may be reluctant to disclose their meticulously developed models. (2) The communication costs are high as they correlate with the number of model parameters. This becomes particularly problematic as the current FedSeqRec will be inapplicable when sequential recommendation marches into a large language model era. To overcome the above challenges, this paper proposes a parameter transmission-free federated sequential recommendation framework (PTF-FSR), which ensures both model and data privacy protection to meet the privacy needs of service providers and system users alike. Furthermore, since PTF-FSR only transmits prediction results under privacy protection, which are independent of model sizes, this new federated learning architecture can accommodate more complex and larger sequential recommendation models. Extensive experiments conducted on three widely used recommendation datasets, employing various sequential recommendation models from both ID-based and ID-free paradigms, demonstrate the effectiveness and generalization capability of our proposed framework.
Poisoning Attacks and Defenses in Recommender Systems: A Survey
Jun 03, 2024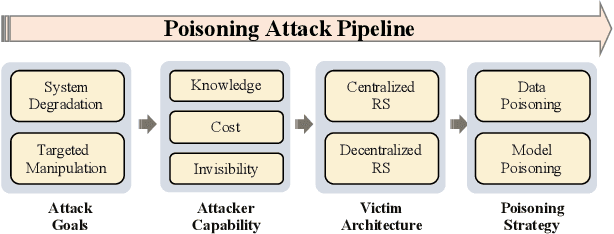
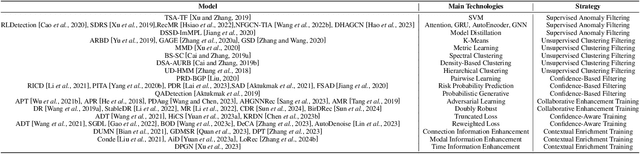
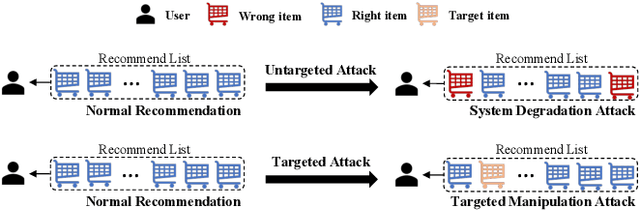
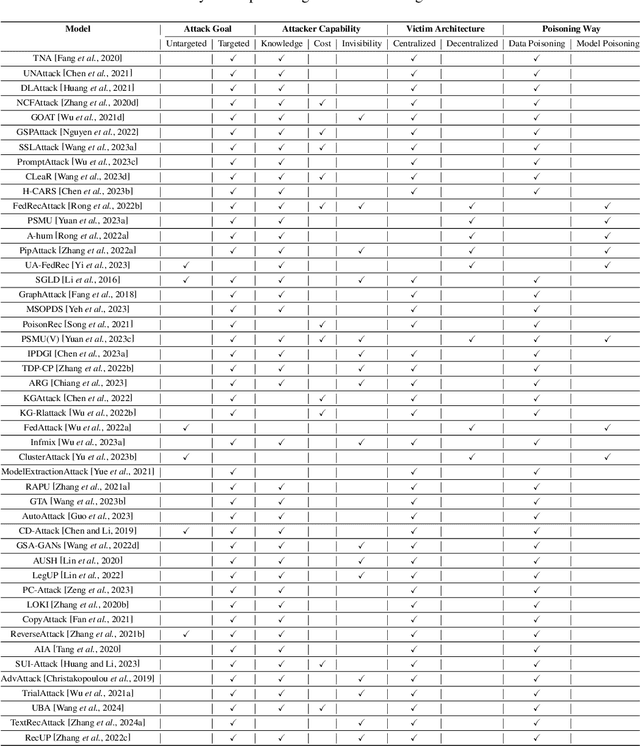
Modern recommender systems (RS) have profoundly enhanced user experience across digital platforms, yet they face significant threats from poisoning attacks. These attacks, aimed at manipulating recommendation outputs for unethical gains, exploit vulnerabilities in RS through injecting malicious data or intervening model training. This survey presents a unique perspective by examining these threats through the lens of an attacker, offering fresh insights into their mechanics and impacts. Concretely, we detail a systematic pipeline that encompasses four stages of a poisoning attack: setting attack goals, assessing attacker capabilities, analyzing victim architecture, and implementing poisoning strategies. The pipeline not only aligns with various attack tactics but also serves as a comprehensive taxonomy to pinpoint focuses of distinct poisoning attacks. Correspondingly, we further classify defensive strategies into two main categories: poisoning data filtering and robust training from the defender's perspective. Finally, we highlight existing limitations and suggest innovative directions for further exploration in this field.
Hate Speech Detection with Generalizable Target-aware Fairness
May 28, 2024



To counter the side effect brought by the proliferation of social media platforms, hate speech detection (HSD) plays a vital role in halting the dissemination of toxic online posts at an early stage. However, given the ubiquitous topical communities on social media, a trained HSD classifier easily becomes biased towards specific targeted groups (e.g., female and black people), where a high rate of false positive/negative results can significantly impair public trust in the fairness of content moderation mechanisms, and eventually harm the diversity of online society. Although existing fairness-aware HSD methods can smooth out some discrepancies across targeted groups, they are mostly specific to a narrow selection of targets that are assumed to be known and fixed. This inevitably prevents those methods from generalizing to real-world use cases where new targeted groups constantly emerge over time. To tackle this defect, we propose Generalizable target-aware Fairness (GetFair), a new method for fairly classifying each post that contains diverse and even unseen targets during inference. To remove the HSD classifier's spurious dependence on target-related features, GetFair trains a series of filter functions in an adversarial pipeline, so as to deceive the discriminator that recovers the targeted group from filtered post embeddings. To maintain scalability and generalizability, we innovatively parameterize all filter functions via a hypernetwork that is regularized by the semantic affinity among targets. Taking a target's pretrained word embedding as input, the hypernetwork generates the weights used by each target-specific filter on-the-fly without storing dedicated filter parameters. Finally, comparative experiments on two HSD datasets have shown advantageous performance of GetFair on out-of-sample targets.
Graph Condensation for Open-World Graph Learning
May 27, 2024



The burgeoning volume of graph data presents significant computational challenges in training graph neural networks (GNNs), critically impeding their efficiency in various applications. To tackle this challenge, graph condensation (GC) has emerged as a promising acceleration solution, focusing on the synthesis of a compact yet representative graph for efficiently training GNNs while retaining performance. Despite the potential to promote scalable use of GNNs, existing GC methods are limited to aligning the condensed graph with merely the observed static graph distribution. This limitation significantly restricts the generalization capacity of condensed graphs, particularly in adapting to dynamic distribution changes. In real-world scenarios, however, graphs are dynamic and constantly evolving, with new nodes and edges being continually integrated. Consequently, due to the limited generalization capacity of condensed graphs, applications that employ GC for efficient GNN training end up with sub-optimal GNNs when confronted with evolving graph structures and distributions in dynamic real-world situations. To overcome this issue, we propose open-world graph condensation (OpenGC), a robust GC framework that integrates structure-aware distribution shift to simulate evolving graph patterns and exploit the temporal environments for invariance condensation. This approach is designed to extract temporal invariant patterns from the original graph, thereby enhancing the generalization capabilities of the condensed graph and, subsequently, the GNNs trained on it. Extensive experiments on both real-world and synthetic evolving graphs demonstrate that OpenGC outperforms state-of-the-art (SOTA) GC methods in adapting to dynamic changes in open-world graph environments.
Diffusion-Based Cloud-Edge-Device Collaborative Learning for Next POI Recommendations
May 22, 2024



The rapid expansion of Location-Based Social Networks (LBSNs) has highlighted the importance of effective next Point-of-Interest (POI) recommendations, which leverage historical check-in data to predict users' next POIs to visit. Traditional centralized deep neural networks (DNNs) offer impressive POI recommendation performance but face challenges due to privacy concerns and limited timeliness. In response, on-device POI recommendations have been introduced, utilizing federated learning (FL) and decentralized approaches to ensure privacy and recommendation timeliness. However, these methods often suffer from computational strain on devices and struggle to adapt to new users and regions. This paper introduces a novel collaborative learning framework, Diffusion-Based Cloud-Edge-Device Collaborative Learning for Next POI Recommendations (DCPR), leveraging the diffusion model known for its success across various domains. DCPR operates with a cloud-edge-device architecture to offer region-specific and highly personalized POI recommendations while reducing on-device computational burdens. DCPR minimizes on-device computational demands through a unique blend of global and local learning processes. Our evaluation with two real-world datasets demonstrates DCPR's superior performance in recommendation accuracy, efficiency, and adaptability to new users and regions, marking a significant step forward in on-device POI recommendation technology.
Rethinking and Accelerating Graph Condensation: A Training-Free Approach with Class Partition
May 22, 2024



The increasing prevalence of large-scale graphs poses a significant challenge for graph neural network training, attributed to their substantial computational requirements. In response, graph condensation (GC) emerges as a promising data-centric solution aiming to substitute the large graph with a small yet informative condensed graph to facilitate data-efficient GNN training. However, existing GC methods suffer from intricate optimization processes, necessitating excessive computing resources. In this paper, we revisit existing GC optimization strategies and identify two pervasive issues: 1. various GC optimization strategies converge to class-level node feature matching between the original and condensed graphs, making the optimization target coarse-grained despite the complex computations; 2. to bridge the original and condensed graphs, existing GC methods rely on a Siamese graph network architecture that requires time-consuming bi-level optimization with iterative gradient computations. To overcome these issues, we propose a training-free GC framework termed Class-partitioned Graph Condensation (CGC), which refines the node feature matching from the class-to-class paradigm into a novel class-to-node paradigm. Remarkably, this refinement also simplifies the GC optimization as a class partition problem, which can be efficiently solved by any clustering methods. Moreover, CGC incorporates a pre-defined graph structure to enable a closed-form solution for condensed node features, eliminating the back-and-forth gradient descent in existing GC approaches without sacrificing accuracy. Extensive experiments demonstrate that CGC achieves state-of-the-art performance with a more efficient condensation process. For instance, compared with the seminal GC method (i.e., GCond), CGC condenses the largest Reddit graph within 10 seconds, achieving a 2,680X speedup and a 1.4% accuracy increase.
A Survey of Generative Techniques for Spatial-Temporal Data Mining
May 15, 2024



This paper focuses on the integration of generative techniques into spatial-temporal data mining, considering the significant growth and diverse nature of spatial-temporal data. With the advancements in RNNs, CNNs, and other non-generative techniques, researchers have explored their application in capturing temporal and spatial dependencies within spatial-temporal data. However, the emergence of generative techniques such as LLMs, SSL, Seq2Seq and diffusion models has opened up new possibilities for enhancing spatial-temporal data mining further. The paper provides a comprehensive analysis of generative technique-based spatial-temporal methods and introduces a standardized framework specifically designed for the spatial-temporal data mining pipeline. By offering a detailed review and a novel taxonomy of spatial-temporal methodology utilizing generative techniques, the paper enables a deeper understanding of the various techniques employed in this field. Furthermore, the paper highlights promising future research directions, urging researchers to delve deeper into spatial-temporal data mining. It emphasizes the need to explore untapped opportunities and push the boundaries of knowledge to unlock new insights and improve the effectiveness and efficiency of spatial-temporal data mining. By integrating generative techniques and providing a standardized framework, the paper contributes to advancing the field and encourages researchers to explore the vast potential of generative techniques in spatial-temporal data mining.
Manipulating Recommender Systems: A Survey of Poisoning Attacks and Countermeasures
Apr 23, 2024



Recommender systems have become an integral part of online services to help users locate specific information in a sea of data. However, existing studies show that some recommender systems are vulnerable to poisoning attacks, particularly those that involve learning schemes. A poisoning attack is where an adversary injects carefully crafted data into the process of training a model, with the goal of manipulating the system's final recommendations. Based on recent advancements in artificial intelligence, such attacks have gained importance recently. While numerous countermeasures to poisoning attacks have been developed, they have not yet been systematically linked to the properties of the attacks. Consequently, assessing the respective risks and potential success of mitigation strategies is difficult, if not impossible. This survey aims to fill this gap by primarily focusing on poisoning attacks and their countermeasures. This is in contrast to prior surveys that mainly focus on attacks and their detection methods. Through an exhaustive literature review, we provide a novel taxonomy for poisoning attacks, formalise its dimensions, and accordingly organise 30+ attacks described in the literature. Further, we review 40+ countermeasures to detect and/or prevent poisoning attacks, evaluating their effectiveness against specific types of attacks. This comprehensive survey should serve as a point of reference for protecting recommender systems against poisoning attacks. The article concludes with a discussion on open issues in the field and impactful directions for future research. A rich repository of resources associated with poisoning attacks is available at https://github.com/tamlhp/awesome-recsys-poisoning.
Automated Similarity Metric Generation for Recommendation
Apr 18, 2024



The embedding-based architecture has become the dominant approach in modern recommender systems, mapping users and items into a compact vector space. It then employs predefined similarity metrics, such as the inner product, to calculate similarity scores between user and item embeddings, thereby guiding the recommendation of items that align closely with a user's preferences. Given the critical role of similarity metrics in recommender systems, existing methods mainly employ handcrafted similarity metrics to capture the complex characteristics of user-item interactions. Yet, handcrafted metrics may not fully capture the diverse range of similarity patterns that can significantly vary across different domains. To address this issue, we propose an Automated Similarity Metric Generation method for recommendations, named AutoSMG, which can generate tailored similarity metrics for various domains and datasets. Specifically, we first construct a similarity metric space by sampling from a set of basic embedding operators, which are then integrated into computational graphs to represent metrics. We employ an evolutionary algorithm to search for the optimal metrics within this metric space iteratively. To improve search efficiency, we utilize an early stopping strategy and a surrogate model to approximate the performance of candidate metrics instead of fully training models. Notably, our proposed method is model-agnostic, which can seamlessly plugin into different recommendation model architectures. The proposed method is validated on three public recommendation datasets across various domains in the Top-K recommendation task, and experimental results demonstrate that AutoSMG outperforms both commonly used handcrafted metrics and those generated by other search strategies.