 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Graph Condensation: Advancing Data Versatility through Self-Supervised Learning
Nov 26, 2024



With the increasing computation of training graph neural networks (GNNs) on large-scale graphs, graph condensation (GC) has emerged as a promising solution to synthesize a compact, substitute graph of the large-scale original graph for efficient GNN training. However, existing GC methods predominantly employ classification as the surrogate task for optimization, thus excessively relying on node labels and constraining their utility in label-sparsity scenarios. More critically, this surrogate task tends to overfit class-specific information within the condensed graph, consequently restricting the generalization capabilities of GC for other downstream tasks. To address these challenges, we introduce Contrastive Graph Condensation (CTGC), which adopts a self-supervised surrogate task to extract critical, causal information from the original graph and enhance the cross-task generalizability of the condensed graph. Specifically, CTGC employs a dual-branch framework to disentangle the generation of the node attributes and graph structures, where a dedicated structural branch is designed to explicitly encode geometric information through nodes' positional embeddings. By implementing an alternating optimization scheme with contrastive loss terms, CTGC promotes the mutual enhancement of both branches and facilitates high-quality graph generation through the model inversion technique. Extensive experiments demonstrate that CTGC excels in handling various downstream tasks with a limited number of labels, consistently outperforming state-of-the-art GC methods.
Inductive Graph Few-shot Class Incremental Learning
Nov 11, 2024



Node classification with Graph Neural Networks (GNN) under a fixed set of labels is well known in contrast to Graph Few-Shot Class Incremental Learning (GFSCIL), which involves learning a GNN classifier as graph nodes and classes growing over time sporadically. We introduce inductive GFSCIL that continually learns novel classes with newly emerging nodes while maintaining performance on old classes without accessing previous data. This addresses the practical concern of transductive GFSCIL, which requires storing the entire graph with historical data. Compared to the transductive GFSCIL, the inductive setting exacerbates catastrophic forgetting due to inaccessible previous data during incremental training, in addition to overfitting issue caused by label sparsity. Thus, we propose a novel method, called Topology-based class Augmentation and Prototype calibration (TAP). To be specific, it first creates a triple-branch multi-topology class augmentation method to enhance model generalization ability. As each incremental session receives a disjoint subgraph with nodes of novel classes, the multi-topology class augmentation method helps replicate such a setting in the base session to boost backbone versatility. In incremental learning, given the limited number of novel class samples, we propose an iterative prototype calibration to improve the separation of class prototypes. Furthermore, as backbone fine-tuning poses the feature distribution drift, prototypes of old classes start failing over time, we propose the prototype shift method for old classes to compensate for the drift. We showcase the proposed method on four datasets.
Graph Condensation for Open-World Graph Learning
May 27, 2024



The burgeoning volume of graph data presents significant computational challenges in training graph neural networks (GNNs), critically impeding their efficiency in various applications. To tackle this challenge, graph condensation (GC) has emerged as a promising acceleration solution, focusing on the synthesis of a compact yet representative graph for efficiently training GNNs while retaining performance. Despite the potential to promote scalable use of GNNs, existing GC methods are limited to aligning the condensed graph with merely the observed static graph distribution. This limitation significantly restricts the generalization capacity of condensed graphs, particularly in adapting to dynamic distribution changes. In real-world scenarios, however, graphs are dynamic and constantly evolving, with new nodes and edges being continually integrated. Consequently, due to the limited generalization capacity of condensed graphs, applications that employ GC for efficient GNN training end up with sub-optimal GNNs when confronted with evolving graph structures and distributions in dynamic real-world situations. To overcome this issue, we propose open-world graph condensation (OpenGC), a robust GC framework that integrates structure-aware distribution shift to simulate evolving graph patterns and exploit the temporal environments for invariance condensation. This approach is designed to extract temporal invariant patterns from the original graph, thereby enhancing the generalization capabilities of the condensed graph and, subsequently, the GNNs trained on it. Extensive experiments on both real-world and synthetic evolving graphs demonstrate that OpenGC outperforms state-of-the-art (SOTA) GC methods in adapting to dynamic changes in open-world graph environments.
Informative Pseudo-Labeling for Graph Neural Networks with Few Labels
Jan 20, 2022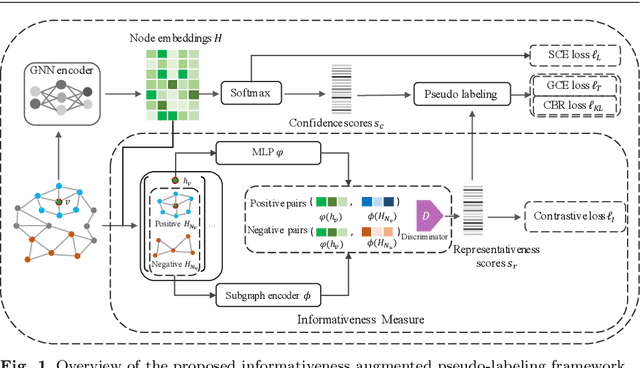

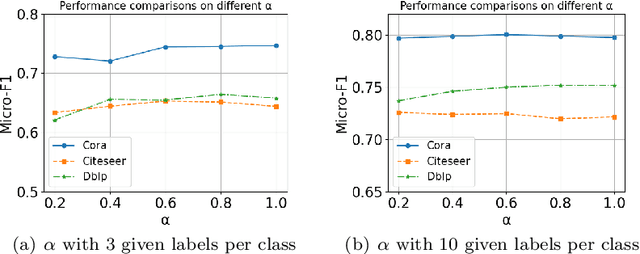
Graph Neural Networks (GNNs) have achieved state-of-the-art results for semi-supervised node classification on graphs. Nevertheless, the challenge of how to effectively learn GNNs with very few labels is still under-explored. As one of the prevalent semi-supervised methods, pseudo-labeling has been proposed to explicitly address the label scarcity problem. It aims to augment the training set with pseudo-labeled unlabeled nodes with high confidence so as to re-train a supervised model in a self-training cycle. However, the existing pseudo-labeling approaches often suffer from two major drawbacks. First, they tend to conservatively expand the label set by selecting only high-confidence unlabeled nodes without assessing their informativeness. Unfortunately, those high-confidence nodes often convey overlapping information with given labels, leading to minor improvements for model re-training. Second, these methods incorporate pseudo-labels to the same loss function with genuine labels, ignoring their distinct contributions to the classification task. In this paper, we propose a novel informative pseudo-labeling framework, called InfoGNN, to facilitate learning of GNNs with extremely few labels. Our key idea is to pseudo label the most informative nodes that can maximally represent the local neighborhoods via mutual information maximization. To mitigate the potential label noise and class-imbalance problem arising from pseudo labeling, we also carefully devise a generalized cross entropy loss with a class-balanced regularization to incorporate generated pseudo labels into model re-training. Extensive experiments on six real-world graph datasets demonstrate that our proposed approach significantly outperforms state-of-the-art baselines and strong self-supervised methods on graphs.
Unified Robust Training for Graph NeuralNetworks against Label Noise
Mar 05, 2021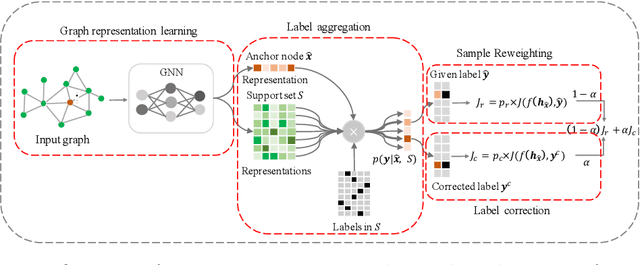
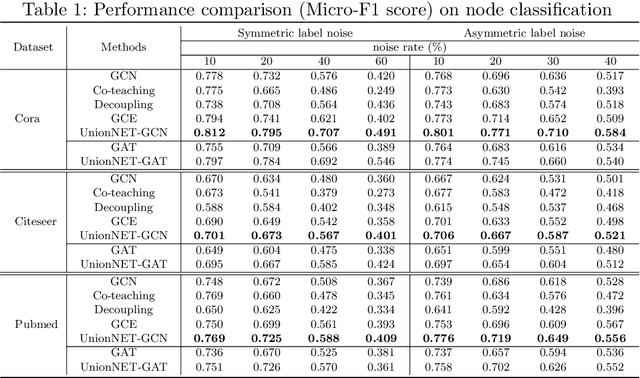
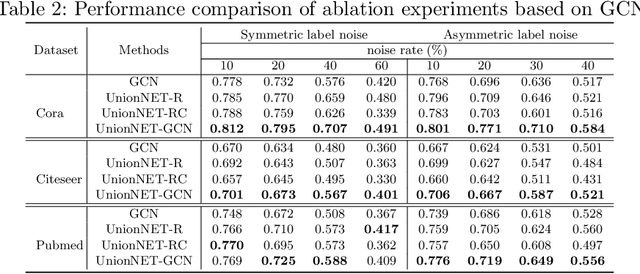
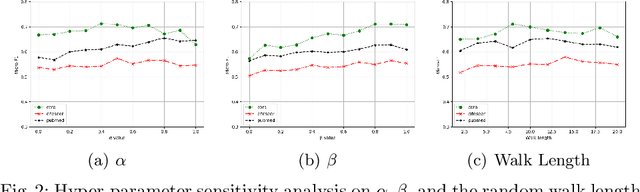
Graph neural networks (GNNs) have achieved state-of-the-art performance for node classification on graphs. The vast majority of existing works assume that genuine node labels are always provided for training. However, there has been very little research effort on how to improve the robustness of GNNs in the presence of label noise. Learning with label noise has been primarily studied in the context of image classification, but these techniques cannot be directly applied to graph-structured data, due to two major challenges -- label sparsity and label dependency -- faced by learning on graphs. In this paper, we propose a new framework, UnionNET, for learning with noisy labels on graphs under a semi-supervised setting. Our approach provides a unified solution for robustly training GNNs and performing label correction simultaneously. The key idea is to perform label aggregation to estimate node-level class probability distributions, which are used to guide sample reweighting and label correction. Compared with existing works, UnionNET has two appealing advantages. First, it requires no extra clean supervision, or explicit estimation of the noise transition matrix. Second, a unified learning framework is proposed to robustly train GNNs in an end-to-end manner. Experimental results show that our proposed approach: (1) is effective in improving model robustness against different types and levels of label noise; (2) yields significant improvements over state-of-the-art baselines.
Wide Graph Neural Networks: Aggregation Provably Leads to Exponentially Trainability Loss
Mar 03, 2021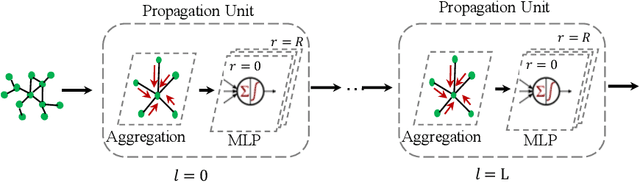
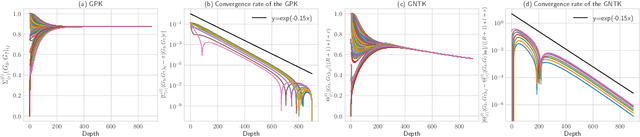
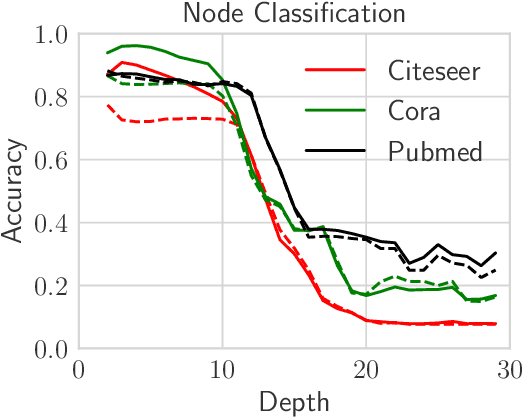
Graph convolutional networks (GCNs) and their variants have achieved great success in dealing with graph-structured data. However, it is well known that deep GCNs will suffer from over-smoothing problem, where node representations tend to be indistinguishable as we stack up more layers. Although extensive research has confirmed this prevailing understanding, few theoretical analyses have been conducted to study the expressivity and trainability of deep GCNs. In this work, we demonstrate these characterizations by studying the Gaussian Process Kernel (GPK) and Graph Neural Tangent Kernel (GNTK) of an infinitely-wide GCN, corresponding to the analysis on expressivity and trainability, respectively. We first prove the expressivity of infinitely-wide GCNs decaying at an exponential rate by applying the mean-field theory on GPK. Besides, we formulate the asymptotic behaviors of GNTK in the large depth, which enables us to reveal the dropping trainability of wide and deep GCNs at an exponential rate. Additionally, we extend our theoretical framework to analyze residual connection-resemble techniques. We found that these techniques can mildly mitigate exponential decay, but they failed to overcome it fundamentally. Finally, all theoretical results in this work are corroborated experimentally on a variety of graph-structured datasets.
Semi-supervised Adversarial Active Learning on Attributed Graphs
Aug 22, 2019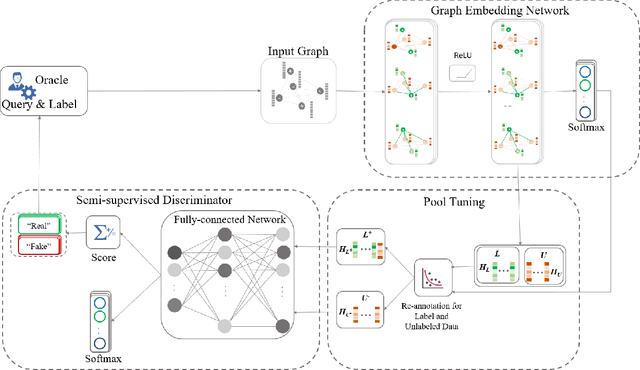
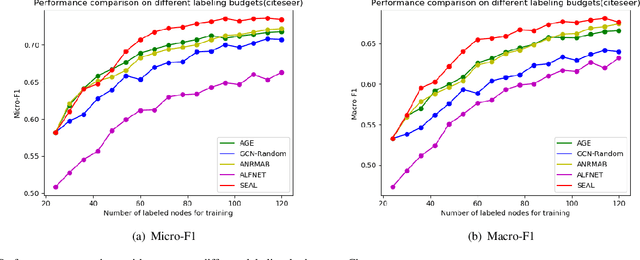
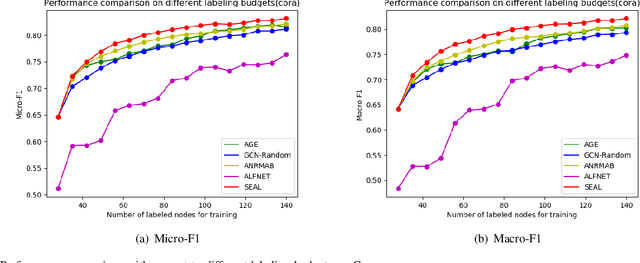
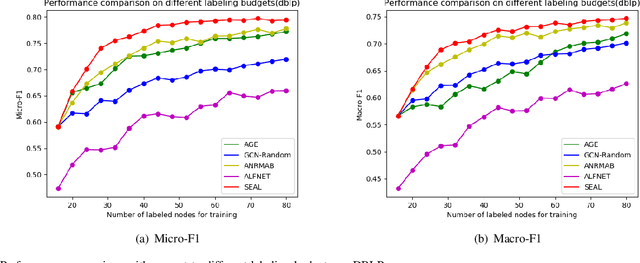
Active learning (AL) on attributed graphs has received increasing attention with the prevalence of graph-structured data. Although AL has been widely studied for alleviating label sparsity issues with the conventional independent and identically distributed (i.i.d.) data, how to make it effective over attributed graphs remains an open research question. Existing AL algorithms on graphs attempt to reuse the classic AL query strategies designed for i.i.d. data. However, they suffer from two major limitations. First, different AL query strategies calculated in distinct scoring spaces are often naively combined to determine which nodes to be labelled. Second, the AL query engine and the learning of the classifier are treated as two separating processes, resulting in unsatisfactory performance. In this paper, we propose a SEmi-supervised Adversarial active Learning (SEAL) framework on attributed graphs, which fully leverages the representation power of deep neural networks and devises a novel AL query strategy in an adversarial way. Our framework learns two adversarial components: a graph embedding network that encodes both the unlabelled and labelled nodes into a latent space, expecting to trick the discriminator to regard all nodes as already labelled, and a semi-supervised discriminator network that distinguishes the unlabelled from the existing labelled nodes in the latent space. The divergence score, generated by the discriminator in a unified latent space, serves as the informativeness measure to actively select the most informative node to be labelled by an oracle. The two adversarial components form a closed loop to mutually and simultaneously reinforce each other towards enhancing the active learning performance. Extensive experiments on four real-world networks validate the effectiveness of the SEAL framework with superior performance improvements to state-of-the-art baselines.