 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUtility-Guided Agent Orchestration for Efficient LLM Tool Use
Mar 20, 2026Tool-using large language model (LLM) agents often face a fundamental tension between answer quality and execution cost. Fixed workflows are stable but inflexible, while free-form multi-step reasoning methods such as ReAct may improve task performance at the expense of excessive tool calls, longer trajectories, higher token consumption, and increased latency. In this paper, we study agent orchestration as an explicit decision problem rather than leaving it entirely to prompt-level behavior. We propose a utility-guided orchestration policy that selects among actions such as respond, retrieve, tool call, verify, and stop by balancing estimated gain, step cost, uncertainty, and redundancy. Our goal is not to claim universally best task performance, but to provide a controllable and analyzable policy framework for studying quality-cost trade-offs in tool-using LLM agents. Experiments across direct answering, threshold control, fixed workflows, ReAct, and several policy variants show that explicit orchestration signals substantially affect agent behavior. Additional analyses on cost definitions, workflow fairness, and redundancy control further demonstrate that lightweight utility design can provide a defensible and practical mechanism for agent control.
From Camera to World: A Plug-and-Play Module for Human Mesh Transformation
Dec 17, 2025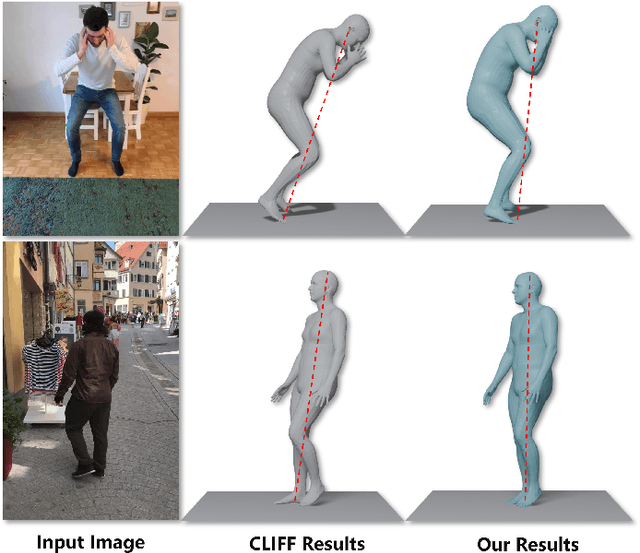
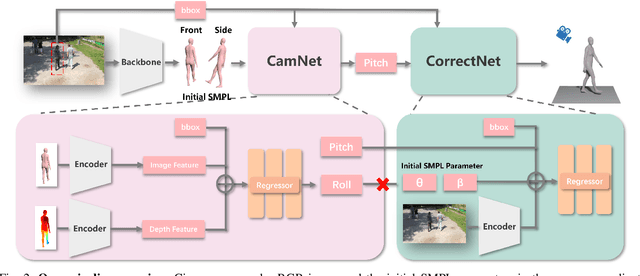
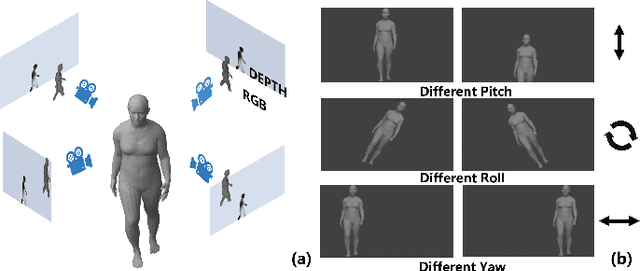

Reconstructing accurate 3D human meshes in the world coordinate system from in-the-wild images remains challenging due to the lack of camera rotation information. While existing methods achieve promising results in the camera coordinate system by assuming zero camera rotation, this simplification leads to significant errors when transforming the reconstructed mesh to the world coordinate system. To address this challenge, we propose Mesh-Plug, a plug-and-play module that accurately transforms human meshes from camera coordinates to world coordinates. Our key innovation lies in a human-centered approach that leverages both RGB images and depth maps rendered from the initial mesh to estimate camera rotation parameters, eliminating the dependency on environmental cues. Specifically, we first train a camera rotation prediction module that focuses on the human body's spatial configuration to estimate camera pitch angle. Then, by integrating the predicted camera parameters with the initial mesh, we design a mesh adjustment module that simultaneously refines the root joint orientation and body pose. Extensive experiments demonstrate that our framework outperforms state-of-the-art methods on the benchmark datasets SPEC-SYN and SPEC-MTP.