 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Texts to Scores: Tracing the Emergence of Essay Quality Representations in Large Language Models
Jun 18, 2026Recent advances in Large Language Models (LLMs) have substantially transformed Automated Essay Scoring (AES), yet the internal mechanisms underlying LLM-based scoring remain poorly understood. In this work, we systematically analyze the hidden representations of eight LLMs across two English essay datasets (ASAP++, CSEE) and one Portuguese dataset (ENEM). Using linear probing, cross-prompt generalization, dimensionality reduction, and neuron-level analyses, we find consistent evidence that essay quality information is encoded in a linearly accessible form within LLM representations. These representations emerge progressively across layers, remain robust across prompting strategies, and partially transfer across essay prompts despite differences in scoring rubrics. In addition, nonlinear probes provide only marginal and inconsistent improvements over linear probes, suggesting that most essay quality information is already linearly decodable. We further identify individual ``essay scoring neurons'' whose activations strongly correlate with essay scores and whose behavior is sensitive to targeted intervention. Moreover, the layer-wise distribution of these neurons systematically shifts with essay length, with longer essays relying more heavily on deeper layers. Overall, our findings provide evidence that LLMs encode structured representations related to essay quality and offer new insights into the interpretability of LLM-based AES systems.
Mitigating Catastrophic Forgetting with Adaptive Transformer Block Expansion in Federated Fine-Tuning
Jun 06, 2025


Federated fine-tuning (FedFT) of large language models (LLMs) has emerged as a promising solution for adapting models to distributed data environments while ensuring data privacy. Existing FedFT methods predominantly utilize parameter-efficient fine-tuning (PEFT) techniques to reduce communication and computation overhead. However, they often fail to adequately address the catastrophic forgetting, a critical challenge arising from continual adaptation in distributed environments. The traditional centralized fine-tuning methods, which are not designed for the heterogeneous and privacy-constrained nature of federated environments, struggle to mitigate this issue effectively. Moreover, the challenge is further exacerbated by significant variation in data distributions and device capabilities across clients, which leads to intensified forgetting and degraded model generalization. To tackle these issues, we propose FedBE, a novel FedFT framework that integrates an adaptive transformer block expansion mechanism with a dynamic trainable-block allocation strategy. Specifically, FedBE expands trainable blocks within the model architecture, structurally separating newly learned task-specific knowledge from the original pre-trained representations. Additionally, FedBE dynamically assigns these trainable blocks to clients based on their data distributions and computational capabilities. This enables the framework to better accommodate heterogeneous federated environments and enhances the generalization ability of the model.Extensive experiments show that compared with existing federated fine-tuning methods, FedBE achieves 12-74% higher accuracy retention on general tasks after fine-tuning and a model convergence acceleration ratio of 1.9-3.1x without degrading the accuracy of downstream tasks.
Detecting Violence in Video using Subclasses
Apr 27, 2016
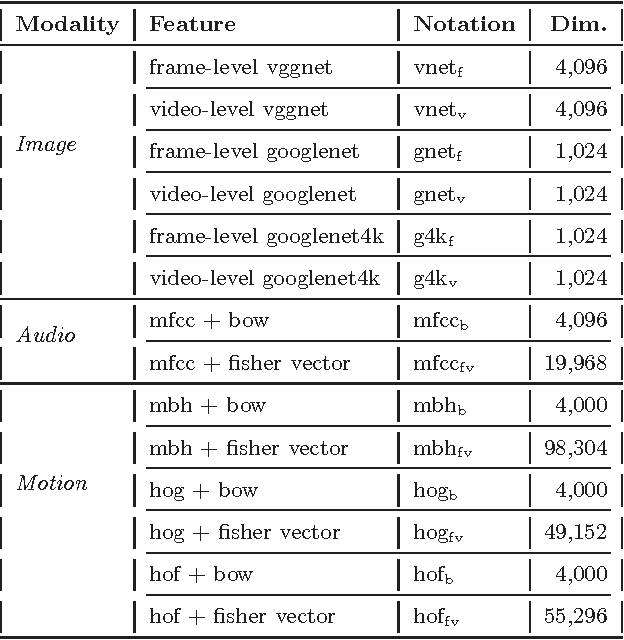
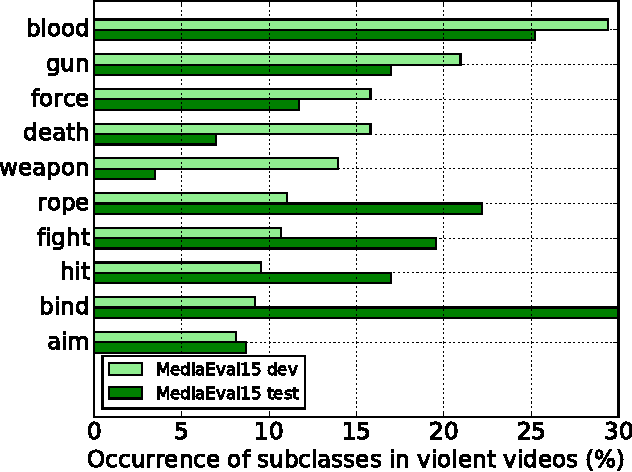
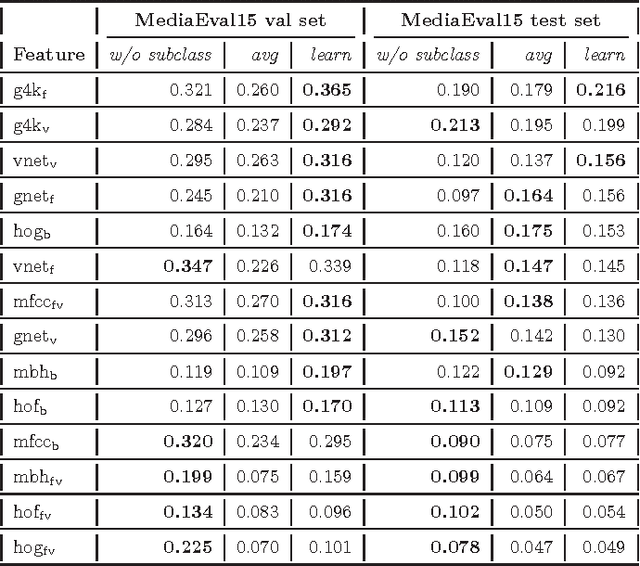
This paper attacks the challenging problem of violence detection in videos. Different from existing works focusing on combining multi-modal features, we go one step further by adding and exploiting subclasses visually related to violence. We enrich the MediaEval 2015 violence dataset by \emph{manually} labeling violence videos with respect to the subclasses. Such fine-grained annotations not only help understand what have impeded previous efforts on learning to fuse the multi-modal features, but also enhance the generalization ability of the learned fusion to novel test data. The new subclass based solution, with AP of 0.303 and P100 of 0.55 on the MediaEval 2015 test set, outperforms several state-of-the-art alternatives. Notice that our solution does not require fine-grained annotations on the test set, so it can be directly applied on novel and fully unlabeled videos. Interestingly, our study shows that motion related features, though being essential part in previous systems, are dispensable.