 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSABlock: Semantic-Aware KV Cache Eviction with Adaptive Compression Block Size
Oct 26, 2025



The growing memory footprint of the Key-Value (KV) cache poses a severe scalability bottleneck for long-context Large Language Model (LLM) inference. While KV cache eviction has emerged as an effective solution by discarding less critical tokens, existing token-, block-, and sentence-level compression methods struggle to balance semantic coherence and memory efficiency. To this end, we introduce SABlock, a \underline{s}emantic-aware KV cache eviction framework with \underline{a}daptive \underline{block} sizes. Specifically, SABlock first performs semantic segmentation to align compression boundaries with linguistic structures, then applies segment-guided token scoring to refine token importance estimation. Finally, for each segment, a budget-driven search strategy adaptively determines the optimal block size that preserves semantic integrity while improving compression efficiency under a given cache budget. Extensive experiments on long-context benchmarks demonstrate that SABlock consistently outperforms state-of-the-art baselines under the same memory budgets. For instance, on Needle-in-a-Haystack (NIAH), SABlock achieves 99.9% retrieval accuracy with only 96 KV entries, nearly matching the performance of the full-cache baseline that retains up to 8K entries. Under a fixed cache budget of 1,024, SABlock further reduces peak memory usage by 46.28% and achieves up to 9.5x faster decoding on a 128K context length.
Efficient Federated Fine-Tuning of Large Language Models with Layer Dropout
Mar 13, 2025

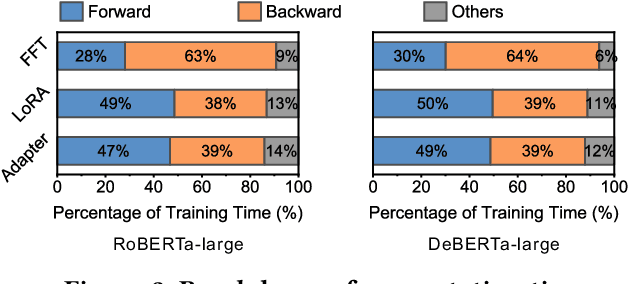

Fine-tuning plays a crucial role in enabling pre-trained LLMs to evolve from general language comprehension to task-specific expertise. To preserve user data privacy, federated fine-tuning is often employed and has emerged as the de facto paradigm. However, federated fine-tuning is prohibitively inefficient due to the tension between LLM complexity and the resource constraint of end devices, incurring unaffordable fine-tuning overhead. Existing literature primarily utilizes parameter-efficient fine-tuning techniques to mitigate communication costs, yet computational and memory burdens continue to pose significant challenges for developers. This work proposes DropPEFT, an innovative federated PEFT framework that employs a novel stochastic transformer layer dropout method, enabling devices to deactivate a considerable fraction of LLMs layers during training, thereby eliminating the associated computational load and memory footprint. In DropPEFT, a key challenge is the proper configuration of dropout ratios for layers, as overhead and training performance are highly sensitive to this setting. To address this challenge, we adaptively assign optimal dropout-ratio configurations to devices through an exploration-exploitation strategy, achieving efficient and effective fine-tuning. Extensive experiments show that DropPEFT can achieve a 1.3-6.3\times speedup in model convergence and a 40%-67% reduction in memory footprint compared to state-of-the-art methods.
Enhancing Federated Graph Learning via Adaptive Fusion of Structural and Node Characteristics
Dec 25, 2024



Federated Graph Learning (FGL) has demonstrated the advantage of training a global Graph Neural Network (GNN) model across distributed clients using their local graph data. Unlike Euclidean data (\eg, images), graph data is composed of nodes and edges, where the overall node-edge connections determine the topological structure, and individual nodes along with their neighbors capture local node features. However, existing studies tend to prioritize one aspect over the other, leading to an incomplete understanding of the data and the potential misidentification of key characteristics across varying graph scenarios. Additionally, the non-independent and identically distributed (non-IID) nature of graph data makes the extraction of these two data characteristics even more challenging. To address the above issues, we propose a novel FGL framework, named FedGCF, which aims to simultaneously extract and fuse structural properties and node features to effectively handle diverse graph scenarios. FedGCF first clusters clients by structural similarity, performing model aggregation within each cluster to form the shared structural model. Next, FedGCF selects the clients with common node features and aggregates their models to generate a common node model. This model is then propagated to all clients, allowing common node features to be shared. By combining these two models with a proper ratio, FedGCF can achieve a comprehensive understanding of the graph data and deliver better performance, even under non-IID distributions. Experimental results show that FedGCF improves accuracy by 4.94%-7.24% under different data distributions and reduces communication cost by 64.18%-81.25% to reach the same accuracy compared to baselines.