 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSignificantly improving zero-shot X-ray pathology classification via fine-tuning pre-trained image-text encoders
Dec 14, 2022Deep neural networks have been successfully adopted to diverse domains including pathology classification based on medical images. However, large-scale and high-quality data to train powerful neural networks are rare in the medical domain as the labeling must be done by qualified experts. Researchers recently tackled this problem with some success by taking advantage of models pre-trained on large-scale general domain data. Specifically, researchers took contrastive image-text encoders (e.g., CLIP) and fine-tuned it with chest X-ray images and paired reports to perform zero-shot pathology classification, thus completely removing the need for pathology-annotated images to train a classification model. Existing studies, however, fine-tuned the pre-trained model with the same contrastive learning objective, and failed to exploit the multi-labeled nature of medical image-report pairs. In this paper, we propose a new fine-tuning strategy based on sentence sampling and positive-pair loss relaxation for improving the downstream zero-shot pathology classification performance, which can be applied to any pre-trained contrastive image-text encoders. Our method consistently showed dramatically improved zero-shot pathology classification performance on four different chest X-ray datasets and 3 different pre-trained models (5.77% average AUROC increase). In particular, fine-tuning CLIP with our method showed much comparable or marginally outperformed to board-certified radiologists (0.619 vs 0.625 in F1 score and 0.530 vs 0.544 in MCC) in zero-shot classification of five prominent diseases from the CheXpert dataset.
Transformers meet Stochastic Block Models: Attention with Data-Adaptive Sparsity and Cost
Oct 27, 2022



To overcome the quadratic cost of self-attention, recent works have proposed various sparse attention modules, most of which fall under one of two groups: 1) sparse attention under a hand-crafted patterns and 2) full attention followed by a sparse variant of softmax such as $\alpha$-entmax. Unfortunately, the first group lacks adaptability to data while the second still requires quadratic cost in training. In this work, we propose SBM-Transformer, a model that resolves both problems by endowing each attention head with a mixed-membership Stochastic Block Model (SBM). Then, each attention head data-adaptively samples a bipartite graph, the adjacency of which is used as an attention mask for each input. During backpropagation, a straight-through estimator is used to flow gradients beyond the discrete sampling step and adjust the probabilities of sampled edges based on the predictive loss. The forward and backward cost are thus linear to the number of edges, which each attention head can also choose flexibly based on the input. By assessing the distribution of graphs, we theoretically show that SBM-Transformer is a universal approximator for arbitrary sequence-to-sequence functions in expectation. Empirical evaluations under the LRA and GLUE benchmarks demonstrate that our model outperforms previous efficient variants as well as the original Transformer with full attention. Our implementation can be found in https://github.com/sc782/SBM-Transformer .
UniCLIP: Unified Framework for Contrastive Language-Image Pre-training
Sep 27, 2022
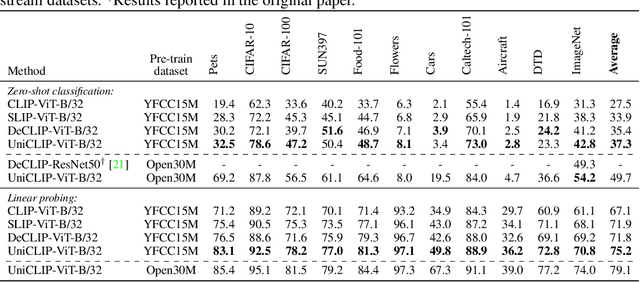
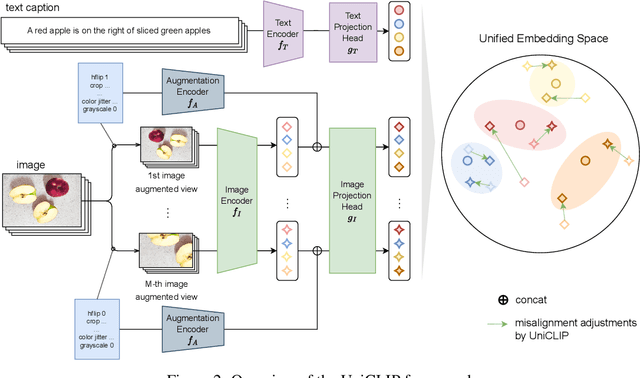
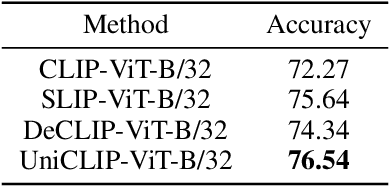
Pre-training vision-language models with contrastive objectives has shown promising results that are both scalable to large uncurated datasets and transferable to many downstream applications. Some following works have targeted to improve data efficiency by adding self-supervision terms, but inter-domain (image-text) contrastive loss and intra-domain (image-image) contrastive loss are defined on individual spaces in those works, so many feasible combinations of supervision are overlooked. To overcome this issue, we propose UniCLIP, a Unified framework for Contrastive Language-Image Pre-training. UniCLIP integrates the contrastive loss of both inter-domain pairs and intra-domain pairs into a single universal space. The discrepancies that occur when integrating contrastive loss between different domains are resolved by the three key components of UniCLIP: (1) augmentation-aware feature embedding, (2) MP-NCE loss, and (3) domain dependent similarity measure. UniCLIP outperforms previous vision-language pre-training methods on various single- and multi-modality downstream tasks. In our experiments, we show that each component that comprises UniCLIP contributes well to the final performance.
Grouping-matrix based Graph Pooling with Adaptive Number of Clusters
Sep 07, 2022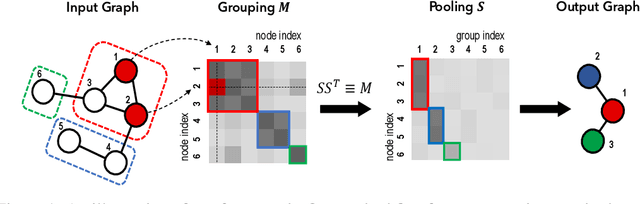
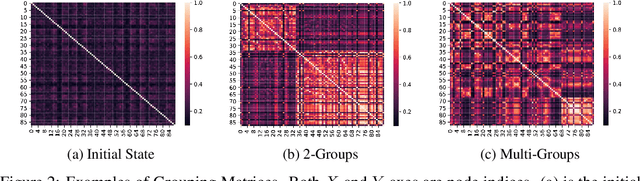
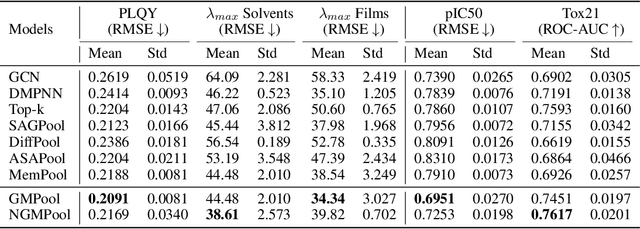
Graph pooling is a crucial operation for encoding hierarchical structures within graphs. Most existing graph pooling approaches formulate the problem as a node clustering task which effectively captures the graph topology. Conventional methods ask users to specify an appropriate number of clusters as a hyperparameter, then assume that all input graphs share the same number of clusters. In inductive settings where the number of clusters can vary, however, the model should be able to represent this variation in its pooling layers in order to learn suitable clusters. Thus we propose GMPool, a novel differentiable graph pooling architecture that automatically determines the appropriate number of clusters based on the input data. The main intuition involves a grouping matrix defined as a quadratic form of the pooling operator, which induces use of binary classification probabilities of pairwise combinations of nodes. GMPool obtains the pooling operator by first computing the grouping matrix, then decomposing it. Extensive evaluations on molecular property prediction tasks demonstrate that our method outperforms conventional methods.
Learning Action Translator for Meta Reinforcement Learning on Sparse-Reward Tasks
Jul 20, 2022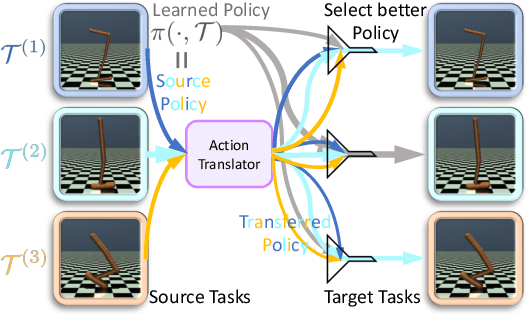
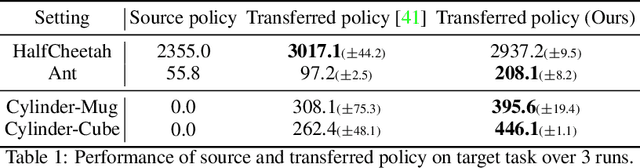
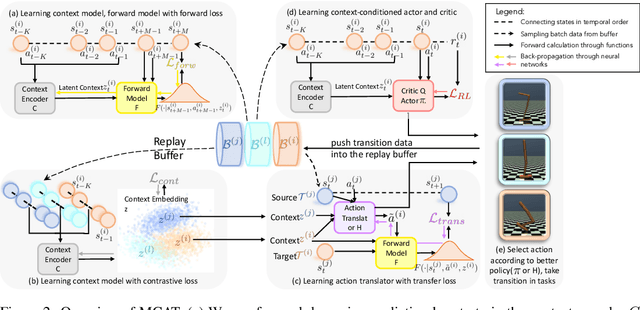

Meta reinforcement learning (meta-RL) aims to learn a policy solving a set of training tasks simultaneously and quickly adapting to new tasks. It requires massive amounts of data drawn from training tasks to infer the common structure shared among tasks. Without heavy reward engineering, the sparse rewards in long-horizon tasks exacerbate the problem of sample efficiency in meta-RL. Another challenge in meta-RL is the discrepancy of difficulty level among tasks, which might cause one easy task dominating learning of the shared policy and thus preclude policy adaptation to new tasks. This work introduces a novel objective function to learn an action translator among training tasks. We theoretically verify that the value of the transferred policy with the action translator can be close to the value of the source policy and our objective function (approximately) upper bounds the value difference. We propose to combine the action translator with context-based meta-RL algorithms for better data collection and more efficient exploration during meta-training. Our approach empirically improves the sample efficiency and performance of meta-RL algorithms on sparse-reward tasks.
Pure Transformers are Powerful Graph Learners
Jul 06, 2022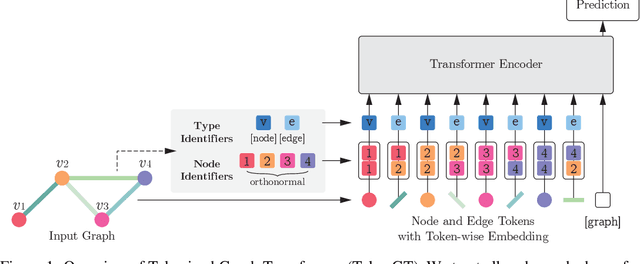
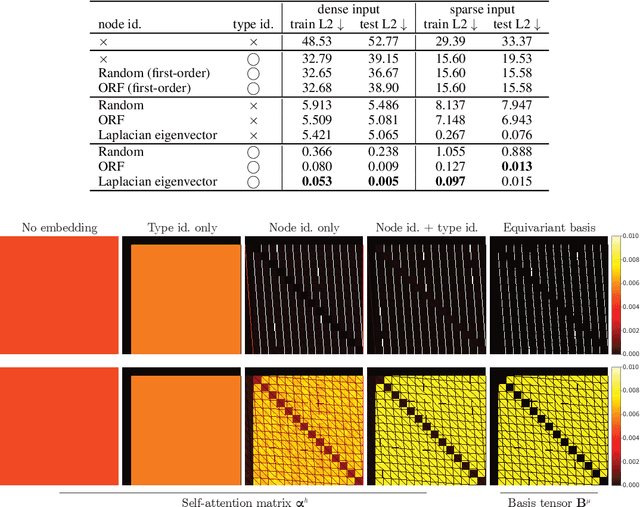
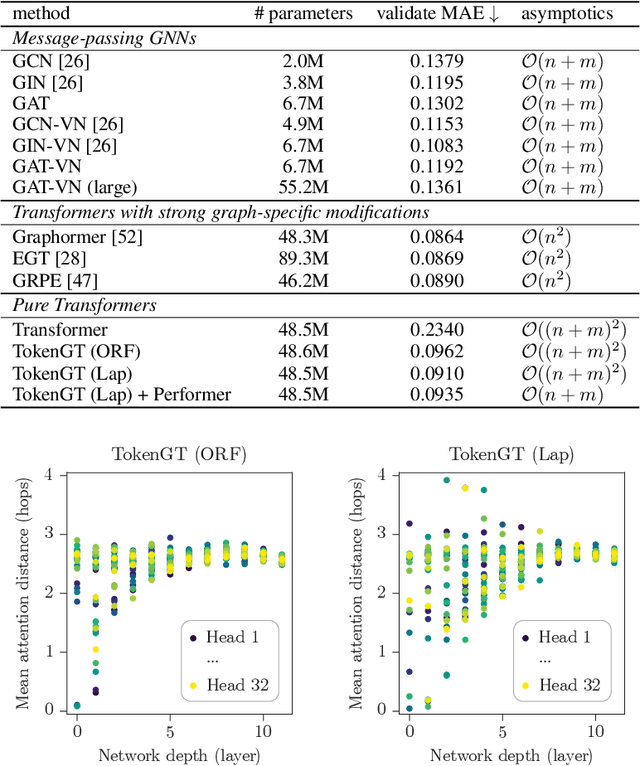

We show that standard Transformers without graph-specific modifications can lead to promising results in graph learning both in theory and practice. Given a graph, we simply treat all nodes and edges as independent tokens, augment them with token embeddings, and feed them to a Transformer. With an appropriate choice of token embeddings, we prove that this approach is theoretically at least as expressive as an invariant graph network (2-IGN) composed of equivariant linear layers, which is already more expressive than all message-passing Graph Neural Networks (GNN). When trained on a large-scale graph dataset (PCQM4Mv2), our method coined Tokenized Graph Transformer (TokenGT) achieves significantly better results compared to GNN baselines and competitive results compared to Transformer variants with sophisticated graph-specific inductive bias. Our implementation is available at https://github.com/jw9730/tokengt.
OpenSRH: optimizing brain tumor surgery using intraoperative stimulated Raman histology
Jun 16, 2022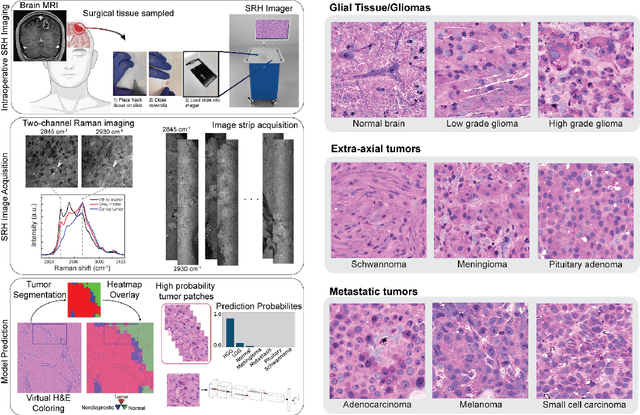

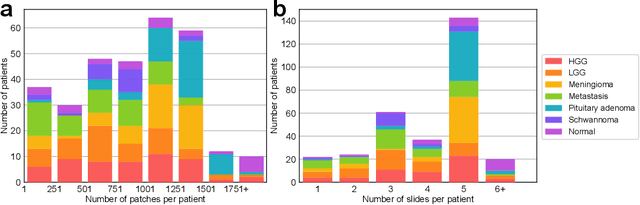
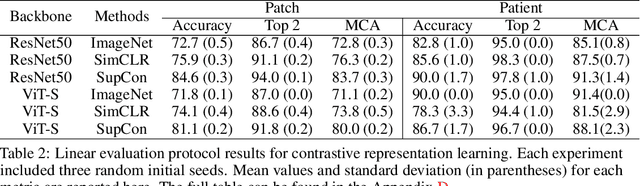
Accurate intraoperative diagnosis is essential for providing safe and effective care during brain tumor surgery. Our standard-of-care diagnostic methods are time, resource, and labor intensive, which restricts access to optimal surgical treatments. To address these limitations, we propose an alternative workflow that combines stimulated Raman histology (SRH), a rapid optical imaging method, with deep learning-based automated interpretation of SRH images for intraoperative brain tumor diagnosis and real-time surgical decision support. Here, we present OpenSRH, the first public dataset of clinical SRH images from 300+ brain tumors patients and 1300+ unique whole slide optical images. OpenSRH contains data from the most common brain tumors diagnoses, full pathologic annotations, whole slide tumor segmentations, raw and processed optical imaging data for end-to-end model development and validation. We provide a framework for patch-based whole slide SRH classification and inference using weak (i.e. patient-level) diagnostic labels. Finally, we benchmark two computer vision tasks: multiclass histologic brain tumor classification and patch-based contrastive representation learning. We hope OpenSRH will facilitate the clinical translation of rapid optical imaging and real-time ML-based surgical decision support in order to improve the access, safety, and efficacy of cancer surgery in the era of precision medicine. Dataset access, code, and benchmarks are available at opensrh.mlins.org.
Is Continual Learning Truly Learning Representations Continually?
Jun 16, 2022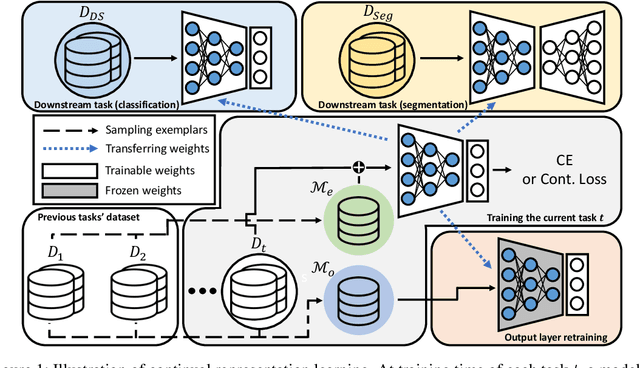
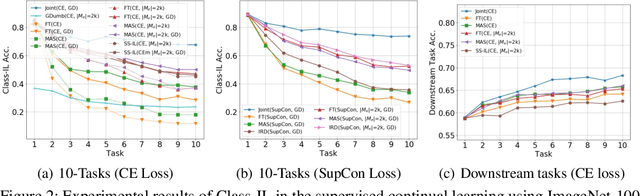
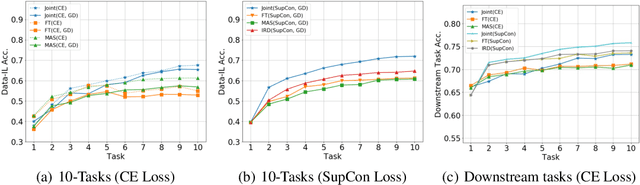
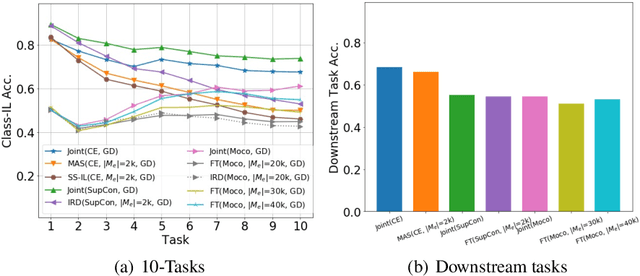
Continual learning (CL) aims to learn from sequentially arriving tasks without forgetting previous tasks. Whereas CL algorithms have tried to achieve higher average test accuracy across all the tasks learned so far, learning continuously useful representations is critical for successful generalization and downstream transfer. To measure representational quality, we re-train only the output layers using a small balanced dataset for all the tasks, evaluating the average accuracy without any biased predictions toward the current task. We also test on several downstream tasks, measuring transfer learning accuracy of the learned representations. By testing our new formalism on ImageNet-100 and ImageNet-1000, we find that using more exemplar memory is the only option to make a meaningful difference in learned representations, and most of the regularization- or distillation-based CL algorithms that use the exemplar memory fail to learn continuously useful representations in class-incremental learning. Surprisingly, unsupervised (or self-supervised) CL with sufficient memory size can achieve comparable performance to the supervised counterparts. Considering non-trivial labeling costs, we claim that finding more efficient unsupervised CL algorithms that minimally use exemplary memory would be the next promising direction for CL research.
Few-shot Subgoal Planning with Language Models
May 28, 2022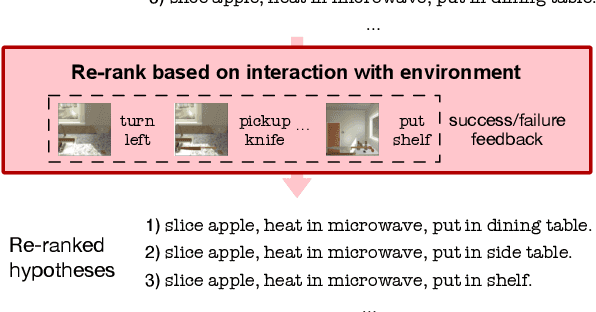
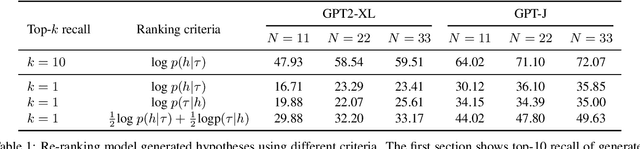
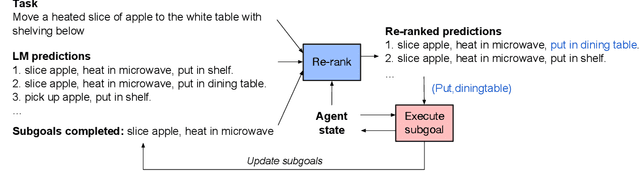
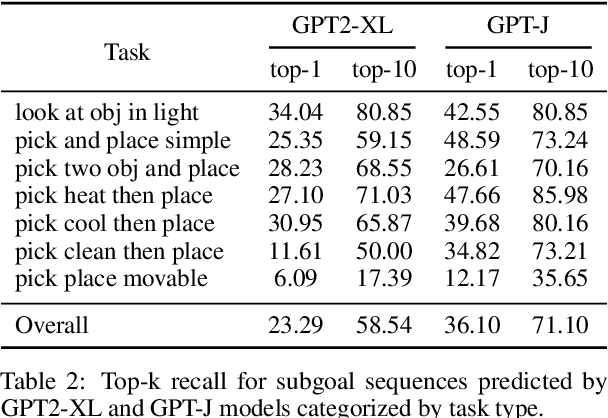
Pre-trained large language models have shown successful progress in many language understanding benchmarks. This work explores the capability of these models to predict actionable plans in real-world environments. Given a text instruction, we show that language priors encoded in pre-trained language models allow us to infer fine-grained subgoal sequences. In contrast to recent methods which make strong assumptions about subgoal supervision, our experiments show that language models can infer detailed subgoal sequences from few training sequences without any fine-tuning. We further propose a simple strategy to re-rank language model predictions based on interaction and feedback from the environment. Combined with pre-trained navigation and visual reasoning components, our approach demonstrates competitive performance on subgoal prediction and task completion in the ALFRED benchmark compared to prior methods that assume more subgoal supervision.
LEPUS: Prompt-based Unsupervised Multi-hop Reranking for Open-domain QA
May 25, 2022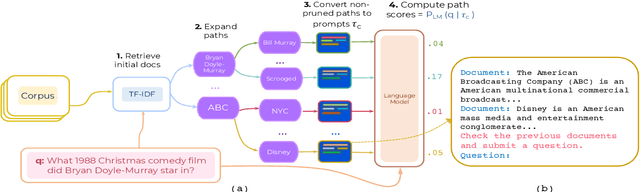
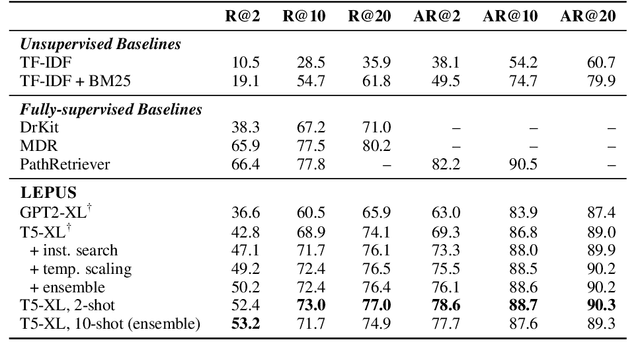
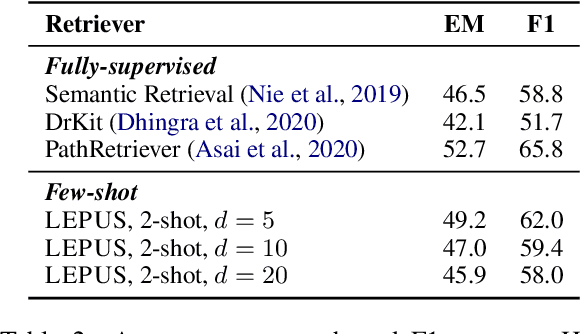
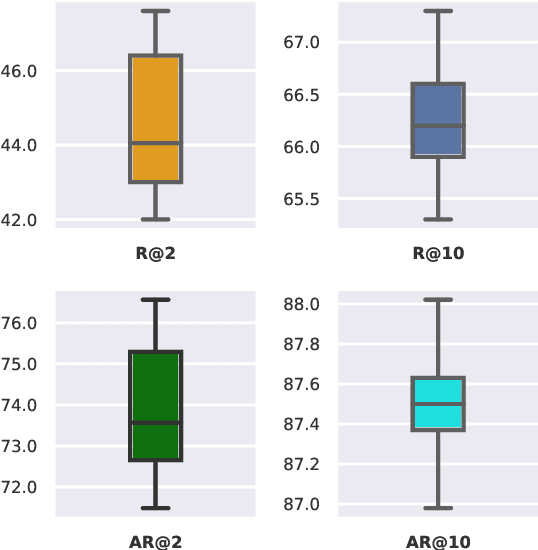
We study unsupervised multi-hop reranking for multi-hop QA (MQA) with open-domain questions. Since MQA requires piecing information from multiple documents, the main challenge thus resides in retrieving and reranking chains of passages that support the reasoning process. Our approach relies on LargE models with Prompt-Utilizing reranking Strategy (LEPUS): we construct an instruction-like prompt based on a candidate document path and compute a relevance score of the path as the probability of generating a given question, according to a pre-trained language model. Though unsupervised, LEPUS yields competitive reranking performance against state-of-the-art methods that are trained on thousands of examples. Adding a small number of samples (e.g., $2$), we demonstrate further performance gain using in-context learning. Finally, we show that when integrated with a reader module, LEPUS can obtain competitive multi-hop QA performance, e.g., outperforming fully-supervised QA systems. Code will be released at https://github.com/mukhal/LEPUS