 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive and Expressive Code-Augmented Planning with Large Language Models
Nov 21, 2024



Large Language Models (LLMs) demonstrate strong abilities in common-sense reasoning and interactive decision-making, but often struggle with complex, long-horizon planning tasks. Recent techniques have sought to structure LLM outputs using control flow and other code-adjacent techniques to improve planning performance. These techniques include using variables (to track important information) and functions (to divide complex tasks into smaller re-usable sub-tasks). However, purely code-based approaches can be error-prone and insufficient for handling ambiguous or unstructured data. To address these challenges, we propose REPL-Plan, an LLM planning approach that is fully code-expressive (it can utilize all the benefits of code) while also being dynamic (it can flexibly adapt from errors and use the LLM for fuzzy situations). In REPL-Plan, an LLM solves tasks by interacting with a Read-Eval-Print Loop (REPL), which iteratively executes and evaluates code, similar to language shells or interactive code notebooks, allowing the model to flexibly correct errors and handle tasks dynamically. We demonstrate that REPL-Plan achieves strong results across various planning domains compared to previous methods.
A Picture is Worth a Thousand Words: Language Models Plan from Pixels
Mar 16, 2023Planning is an important capability of artificial agents that perform long-horizon tasks in real-world environments. In this work, we explore the use of pre-trained language models (PLMs) to reason about plan sequences from text instructions in embodied visual environments. Prior PLM based approaches for planning either assume observations are available in the form of text (e.g., provided by a captioning model), reason about plans from the instruction alone, or incorporate information about the visual environment in limited ways (such as a pre-trained affordance function). In contrast, we show that PLMs can accurately plan even when observations are directly encoded as input prompts for the PLM. We show that this simple approach outperforms prior approaches in experiments on the ALFWorld and VirtualHome benchmarks.
Learning Parameterized Task Structure for Generalization to Unseen Entities
Mar 28, 2022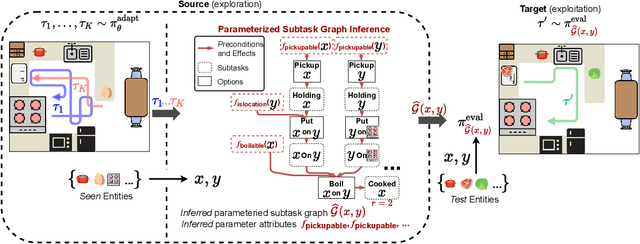


Real world tasks are hierarchical and compositional. Tasks can be composed of multiple subtasks (or sub-goals) that are dependent on each other. These subtasks are defined in terms of entities (e.g., "apple", "pear") that can be recombined to form new subtasks (e.g., "pickup apple", and "pickup pear"). To solve these tasks efficiently, an agent must infer subtask dependencies (e.g. an agent must execute "pickup apple" before "place apple in pot"), and generalize the inferred dependencies to new subtasks (e.g. "place apple in pot" is similar to "place apple in pan"). Moreover, an agent may also need to solve unseen tasks, which can involve unseen entities. To this end, we formulate parameterized subtask graph inference (PSGI), a method for modeling subtask dependencies using first-order logic with subtask entities. To facilitate this, we learn entity attributes in a zero-shot manner, which are used as quantifiers (e.g. "is_pickable(X)") for the parameterized subtask graph. We show this approach accurately learns the latent structure on hierarchical and compositional tasks more efficiently than prior work, and show PSGI can generalize by modelling structure on subtasks unseen during adaptation.