 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFusion of Radio and Camera Sensor Data for Accurate Indoor Positioning
Feb 01, 2023



Indoor positioning systems have received a lot of attention recently due to their importance for many location-based services, e.g. indoor navigation and smart buildings. Lightweight solutions based on WiFi and inertial sensing have gained popularity, but are not fit for demanding applications, such as expert museum guides and industrial settings, which typically require sub-meter location information. In this paper, we propose a novel positioning system, RAVEL (Radio And Vision Enhanced Localization), which fuses anonymous visual detections captured by widely available camera infrastructure, with radio readings (e.g. WiFi radio data). Although visual trackers can provide excellent positioning accuracy, they are plagued by issues such as occlusions and people entering/exiting the scene, preventing their use as a robust tracking solution. By incorporating radio measurements, visually ambiguous or missing data can be resolved through multi-hypothesis tracking. We evaluate our system in a complex museum environment with dim lighting and multiple people moving around in a space cluttered with exhibit stands. Our experiments show that although the WiFi measurements are not by themselves sufficiently accurate, when they are fused with camera data, they become a catalyst for pulling together ambiguous, fragmented, and anonymous visual tracklets into accurate and continuous paths, yielding typical errors below 1 meter.
Fleet Rebalancing for Expanding Shared e-Mobility Systems: A Multi-agent Deep Reinforcement Learning Approach
Nov 11, 2022



The electrification of shared mobility has become popular across the globe. Many cities have their new shared e-mobility systems deployed, with continuously expanding coverage from central areas to the city edges. A key challenge in the operation of these systems is fleet rebalancing, i.e., how EVs should be repositioned to better satisfy future demand. This is particularly challenging in the context of expanding systems, because i) the range of the EVs is limited while charging time is typically long, which constrain the viable rebalancing operations; and ii) the EV stations in the system are dynamically changing, i.e., the legitimate targets for rebalancing operations can vary over time. We tackle these challenges by first investigating rich sets of data collected from a real-world shared e-mobility system for one year, analyzing the operation model, usage patterns and expansion dynamics of this new mobility mode. With the learned knowledge we design a high-fidelity simulator, which is able to abstract key operation details of EV sharing at fine granularity. Then we model the rebalancing task for shared e-mobility systems under continuous expansion as a Multi-Agent Reinforcement Learning (MARL) problem, which directly takes the range and charging properties of the EVs into account. We further propose a novel policy optimization approach with action cascading, which is able to cope with the expansion dynamics and solve the formulated MARL. We evaluate the proposed approach extensively, and experimental results show that our approach outperforms the state-of-the-art, offering significant performance gain in both satisfied demand and net revenue.
BLOX: Macro Neural Architecture Search Benchmark and Algorithms
Oct 13, 2022
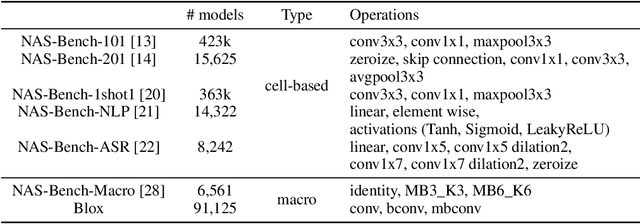
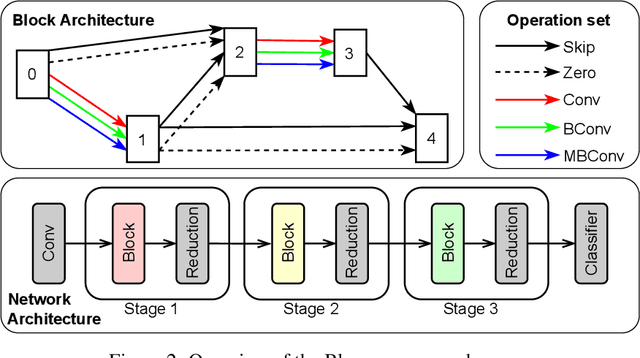
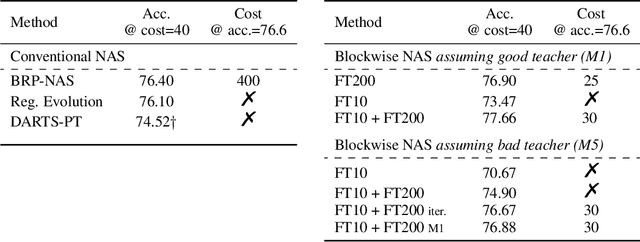
Neural architecture search (NAS) has been successfully used to design numerous high-performance neural networks. However, NAS is typically compute-intensive, so most existing approaches restrict the search to decide the operations and topological structure of a single block only, then the same block is stacked repeatedly to form an end-to-end model. Although such an approach reduces the size of search space, recent studies show that a macro search space, which allows blocks in a model to be different, can lead to better performance. To provide a systematic study of the performance of NAS algorithms on a macro search space, we release Blox - a benchmark that consists of 91k unique models trained on the CIFAR-100 dataset. The dataset also includes runtime measurements of all the models on a diverse set of hardware platforms. We perform extensive experiments to compare existing algorithms that are well studied on cell-based search spaces, with the emerging blockwise approaches that aim to make NAS scalable to much larger macro search spaces. The benchmark and code are available at https://github.com/SamsungLabs/blox.
High Speed Rotation Estimation with Dynamic Vision Sensors
Sep 06, 2022

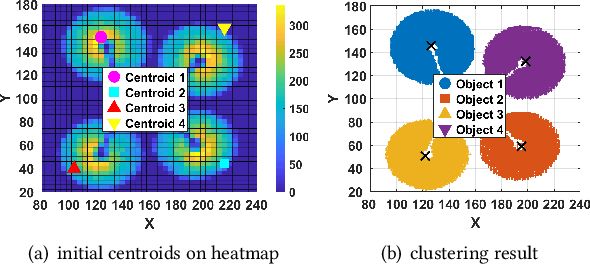
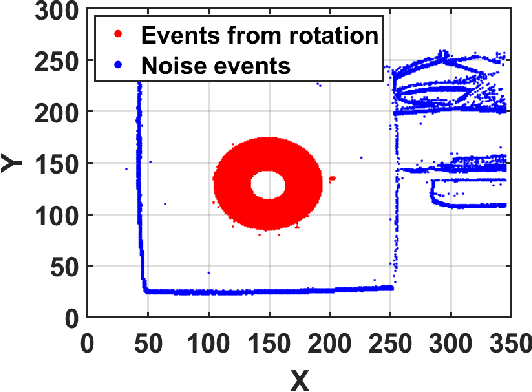
Rotational speed is one of the important metrics to be measured for calibrating the electric motors in manufacturing, monitoring engine during car repairing, faults detection on electrical appliance and etc. However, existing measurement techniques either require prohibitive hardware (e.g., high-speed camera) or are inconvenient to use in real-world application scenarios. In this paper, we propose, EV-Tach, an event-based tachometer via efficient dynamic vision sensing on mobile devices. EV-Tach is designed as a high-fidelity and convenient tachometer by introducing dynamic vision sensor as a new sensing modality to capture the high-speed rotation precisely under various real-world scenarios. By designing a series of signal processing algorithms bespoke for dynamic vision sensing on mobile devices, EV-Tach is able to extract the rotational speed accurately from the event stream produced by dynamic vision sensing on rotary targets. According to our extensive evaluations, the Relative Mean Absolute Error (RMAE) of EV-Tach is as low as 0.03% which is comparable to the state-of-the-art laser tachometer under fixed measurement mode. Moreover, EV-Tach is robust to subtle movement of user's hand, therefore, can be used as a handheld device, where the laser tachometer fails to produce reasonable results.
GeoPointGAN: Synthetic Spatial Data with Local Label Differential Privacy
May 18, 2022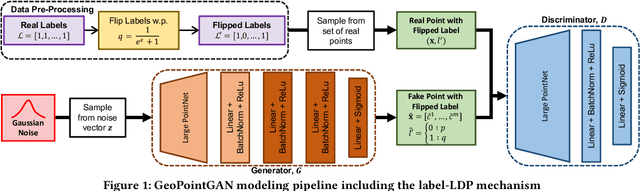
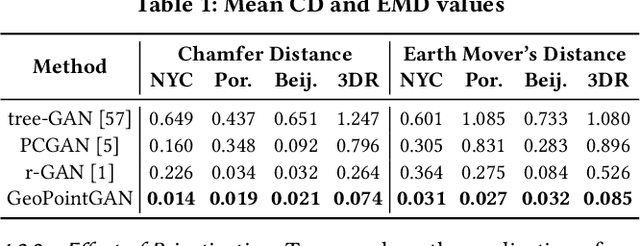
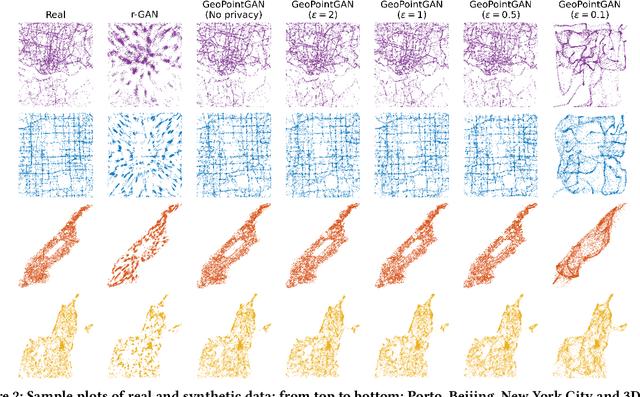
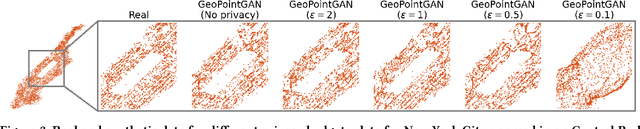
Synthetic data generation is a fundamental task for many data management and data science applications. Spatial data is of particular interest, and its sensitive nature often leads to privacy concerns. We introduce GeoPointGAN, a novel GAN-based solution for generating synthetic spatial point datasets with high utility and strong individual level privacy guarantees. GeoPointGAN's architecture includes a novel point transformation generator that learns to project randomly generated point co-ordinates into meaningful synthetic co-ordinates that capture both microscopic (e.g., junctions, squares) and macroscopic (e.g., parks, lakes) geographic features. We provide our privacy guarantees through label local differential privacy, which is more practical than traditional local differential privacy. We seamlessly integrate this level of privacy into GeoPointGAN by augmenting the discriminator to the point level and implementing a randomized response-based mechanism that flips the labels associated with the 'real' and 'fake' points used in training. Extensive experiments show that GeoPointGAN significantly outperforms recent solutions, improving by up to 10 times compared to the most competitive baseline. We also evaluate GeoPointGAN using range, hotspot, and facility location queries, which confirm the practical effectiveness of GeoPointGAN for privacy-preserving querying. The results illustrate that a strong level of privacy is achieved with little-to-no adverse utility cost, which we explain through the generalization and regularization effects that are realized by flipping the labels of the data during training.
Deployment Optimization for Shared e-Mobility Systems with Multi-agent Deep Neural Search
Nov 03, 2021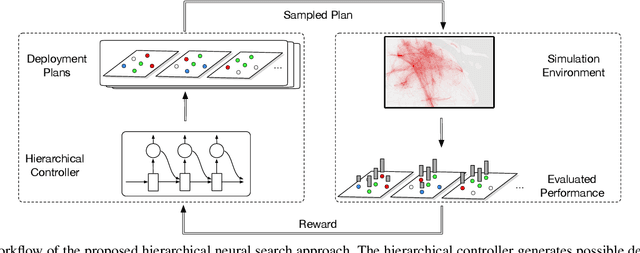
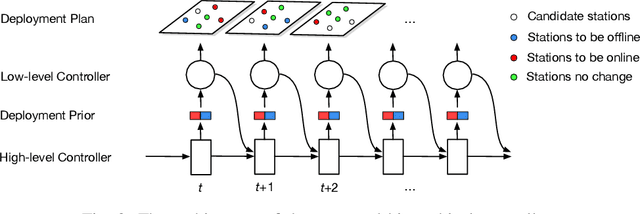
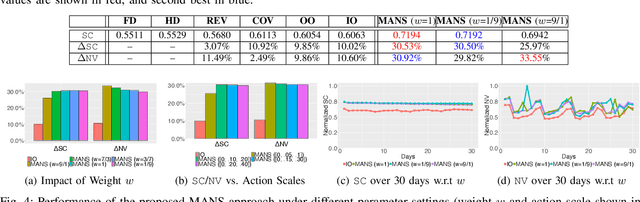
Shared e-mobility services have been widely tested and piloted in cities across the globe, and already woven into the fabric of modern urban planning. This paper studies a practical yet important problem in those systems: how to deploy and manage their infrastructure across space and time, so that the services are ubiquitous to the users while sustainable in profitability. However, in real-world systems evaluating the performance of different deployment strategies and then finding the optimal plan is prohibitively expensive, as it is often infeasible to conduct many iterations of trial-and-error. We tackle this by designing a high-fidelity simulation environment, which abstracts the key operation details of the shared e-mobility systems at fine-granularity, and is calibrated using data collected from the real-world. This allows us to try out arbitrary deployment plans to learn the optimal given specific context, before actually implementing any in the real-world systems. In particular, we propose a novel multi-agent neural search approach, in which we design a hierarchical controller to produce tentative deployment plans. The generated deployment plans are then tested using a multi-simulation paradigm, i.e., evaluated in parallel, where the results are used to train the controller with deep reinforcement learning. With this closed loop, the controller can be steered to have higher probability of generating better deployment plans in future iterations. The proposed approach has been evaluated extensively in our simulation environment, and experimental results show that it outperforms baselines e.g., human knowledge, and state-of-the-art heuristic-based optimization approaches in both service coverage and net revenue.
Temporal Kernel Consistency for Blind Video Super-Resolution
Aug 18, 2021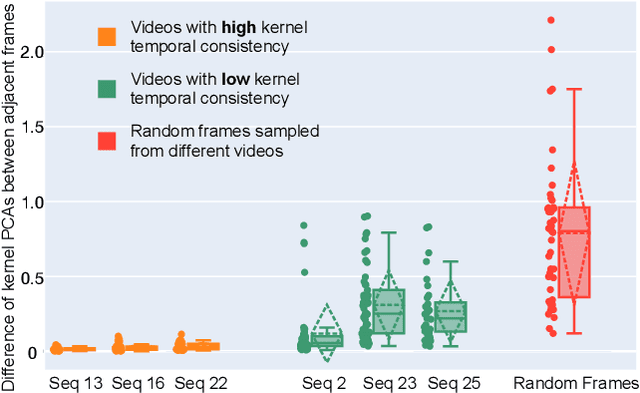
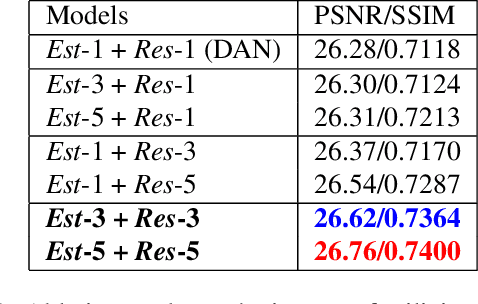

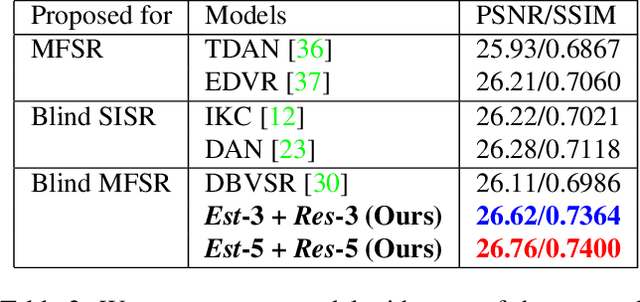
Deep learning-based blind super-resolution (SR) methods have recently achieved unprecedented performance in upscaling frames with unknown degradation. These models are able to accurately estimate the unknown downscaling kernel from a given low-resolution (LR) image in order to leverage the kernel during restoration. Although these approaches have largely been successful, they are predominantly image-based and therefore do not exploit the temporal properties of the kernels across multiple video frames. In this paper, we investigated the temporal properties of the kernels and highlighted its importance in the task of blind video super-resolution. Specifically, we measured the kernel temporal consistency of real-world videos and illustrated how the estimated kernels might change per frame in videos of varying dynamicity of the scene and its objects. With this new insight, we revisited previous popular video SR approaches, and showed that previous assumptions of using a fixed kernel throughout the restoration process can lead to visual artifacts when upscaling real-world videos. In order to counteract this, we tailored existing single-image and video SR techniques to leverage kernel consistency during both kernel estimation and video upscaling processes. Extensive experiments on synthetic and real-world videos show substantial restoration gains quantitatively and qualitatively, achieving the new state-of-the-art in blind video SR and underlining the potential of exploiting kernel temporal consistency.
Zero-Cost Proxies Meet Differentiable Architecture Search
Jun 12, 2021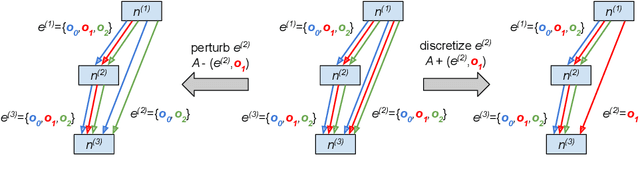

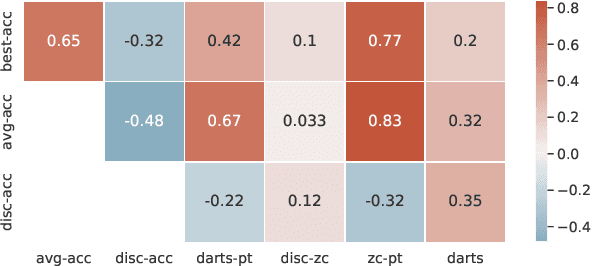

Differentiable neural architecture search (NAS) has attracted significant attention in recent years due to its ability to quickly discover promising architectures of deep neural networks even in very large search spaces. Despite its success, DARTS lacks robustness in certain cases, e.g. it may degenerate to trivial architectures with excessive parametric-free operations such as skip connection or random noise, leading to inferior performance. In particular, operation selection based on the magnitude of architectural parameters was recently proven to be fundamentally wrong showcasing the need to rethink this aspect. On the other hand, zero-cost proxies have been recently studied in the context of sample-based NAS showing promising results -- speeding up the search process drastically in some cases but also failing on some of the large search spaces typical for differentiable NAS. In this work we propose a novel operation selection paradigm in the context of differentiable NAS which utilises zero-cost proxies. Our perturbation-based zero-cost operation selection (Zero-Cost-PT) improves searching time and, in many cases, accuracy compared to the best available differentiable architecture search, regardless of the search space size. Specifically, we are able to find comparable architectures to DARTS-PT on the DARTS CNN search space while being over 40x faster (total searching time 25 minutes on a single GPU).
Journey Towards Tiny Perceptual Super-Resolution
Jul 08, 2020

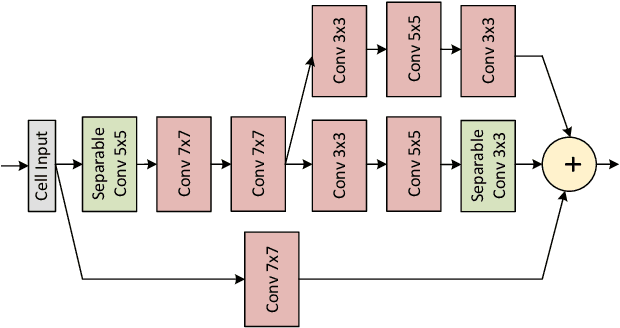
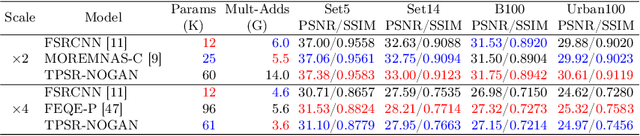
Recent works in single-image perceptual super-resolution (SR) have demonstrated unprecedented performance in generating realistic textures by means of deep convolutional networks. However, these convolutional models are excessively large and expensive, hindering their effective deployment to end devices. In this work, we propose a neural architecture search (NAS) approach that integrates NAS and generative adversarial networks (GANs) with recent advances in perceptual SR and pushes the efficiency of small perceptual SR models to facilitate on-device execution. Specifically, we search over the architectures of both the generator and the discriminator sequentially, highlighting the unique challenges and key observations of searching for an SR-optimized discriminator and comparing them with existing discriminator architectures in the literature. Our tiny perceptual SR (TPSR) models outperform SRGAN and EnhanceNet on both full-reference perceptual metric (LPIPS) and distortion metric (PSNR) while being up to 26.4$\times$ more memory efficient and 33.6$\times$ more compute efficient respectively.
3DCFS: Fast and Robust Joint 3D Semantic-Instance Segmentation via Coupled Feature Selection
Mar 01, 2020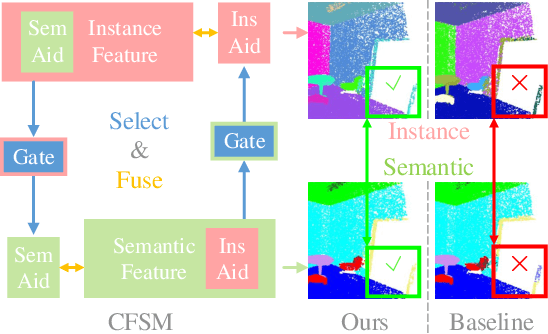
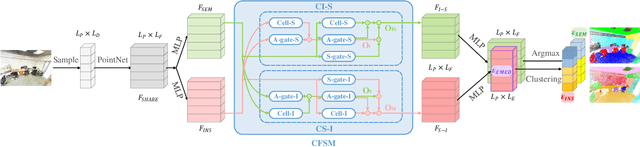
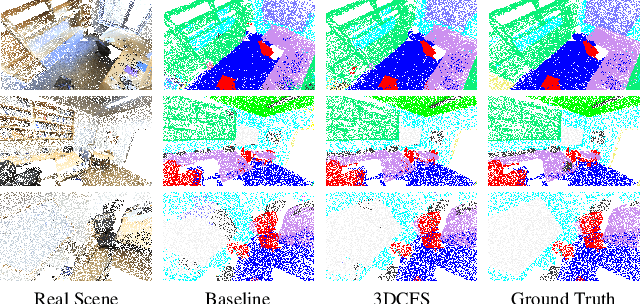
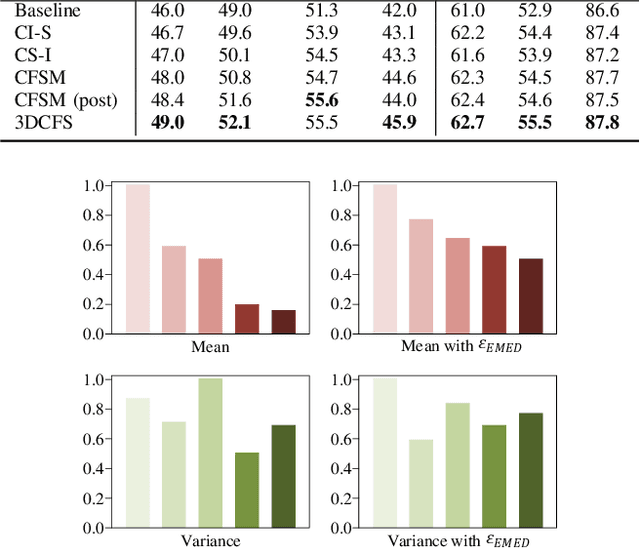
We propose a novel fast and robust 3D point clouds segmentation framework via coupled feature selection, named 3DCFS, that jointly performs semantic and instance segmentation. Inspired by the human scene perception process, we design a novel coupled feature selection module, named CFSM, that adaptively selects and fuses the reciprocal semantic and instance features from two tasks in a coupled manner. To further boost the performance of the instance segmentation task in our 3DCFS, we investigate a loss function that helps the model learn to balance the magnitudes of the output embedding dimensions during training, which makes calculating the Euclidean distance more reliable and enhances the generalizability of the model. Extensive experiments demonstrate that our 3DCFS outperforms state-of-the-art methods on benchmark datasets in terms of accuracy, speed and computational cost.