 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElectricity Price Prediction for Energy Storage System Arbitrage: A Decision-focused Approach
Apr 30, 2023



Electricity price prediction plays a vital role in energy storage system (ESS) management. Current prediction models focus on reducing prediction errors but overlook their impact on downstream decision-making. So this paper proposes a decision-focused electricity price prediction approach for ESS arbitrage to bridge the gap from the downstream optimization model to the prediction model. The decision-focused approach aims at utilizing the downstream arbitrage model for training prediction models. It measures the difference between actual decisions under the predicted price and oracle decisions under the true price, i.e., decision error, by regret, transforms it into the tractable surrogate regret, and then derives the gradients to predicted price for training prediction models. Based on the prediction and decision errors, this paper proposes the hybrid loss and corresponding stochastic gradient descent learning method to learn prediction models for prediction and decision accuracy. The case study verifies that the proposed approach can efficiently bring more economic benefits and reduce decision errors by flattening the time distribution of prediction errors, compared to prediction models for only minimizing prediction errors.
Towards Efficient Fine-tuning of Pre-trained Code Models: An Experimental Study and Beyond
Apr 11, 2023



Recently, fine-tuning pre-trained code models such as CodeBERT on downstream tasks has achieved great success in many software testing and analysis tasks. While effective and prevalent, fine-tuning the pre-trained parameters incurs a large computational cost. In this paper, we conduct an extensive experimental study to explore what happens to layer-wise pre-trained representations and their encoded code knowledge during fine-tuning. We then propose efficient alternatives to fine-tune the large pre-trained code model based on the above findings. Our experimental study shows that (1) lexical, syntactic and structural properties of source code are encoded in the lower, intermediate, and higher layers, respectively, while the semantic property spans across the entire model. (2) The process of fine-tuning preserves most of the code properties. Specifically, the basic code properties captured by lower and intermediate layers are still preserved during fine-tuning. Furthermore, we find that only the representations of the top two layers change most during fine-tuning for various downstream tasks. (3) Based on the above findings, we propose Telly to efficiently fine-tune pre-trained code models via layer freezing. The extensive experimental results on five various downstream tasks demonstrate that training parameters and the corresponding time cost are greatly reduced, while performances are similar or better. Replication package including source code, datasets, and online Appendix is available at: \url{https://github.com/DeepSoftwareAnalytics/Telly}.
Dynamic Grained Encoder for Vision Transformers
Jan 10, 2023Transformers, the de-facto standard for language modeling, have been recently applied for vision tasks. This paper introduces sparse queries for vision transformers to exploit the intrinsic spatial redundancy of natural images and save computational costs. Specifically, we propose a Dynamic Grained Encoder for vision transformers, which can adaptively assign a suitable number of queries to each spatial region. Thus it achieves a fine-grained representation in discriminative regions while keeping high efficiency. Besides, the dynamic grained encoder is compatible with most vision transformer frameworks. Without bells and whistles, our encoder allows the state-of-the-art vision transformers to reduce computational complexity by 40%-60% while maintaining comparable performance on image classification. Extensive experiments on object detection and segmentation further demonstrate the generalizability of our approach. Code is available at https://github.com/StevenGrove/vtpack.
Object-fabrication Targeted Attack for Object Detection
Dec 14, 2022Recent researches show that the deep learning based object detection is vulnerable to adversarial examples. Generally, the adversarial attack for object detection contains targeted attack and untargeted attack. According to our detailed investigations, the research on the former is relatively fewer than the latter and all the existing methods for the targeted attack follow the same mode, i.e., the object-mislabeling mode that misleads detectors to mislabel the detected object as a specific wrong label. However, this mode has limited attack success rate, universal and generalization performances. In this paper, we propose a new object-fabrication targeted attack mode which can mislead detectors to `fabricate' extra false objects with specific target labels. Furthermore, we design a dual attention based targeted feature space attack method to implement the proposed targeted attack mode. The attack performances of the proposed mode and method are evaluated on MS COCO and BDD100K datasets using FasterRCNN and YOLOv5. Evaluation results demonstrate that, the proposed object-fabrication targeted attack mode and the corresponding targeted feature space attack method show significant improvements in terms of image-specific attack, universal performance and generalization capability, compared with the previous targeted attack for object detection. Code will be made available.
Deep Reinforcement Learning Microgrid Optimization Strategy Considering Priority Flexible Demand Side
Nov 11, 2022



As an efficient way to integrate multiple distributed energy resources and the user side, a microgrid is mainly faced with the problems of small-scale volatility, uncertainty, intermittency and demand-side uncertainty of DERs. The traditional microgrid has a single form and cannot meet the flexible energy dispatch between the complex demand side and the microgrid. In response to this problem, the overall environment of wind power, thermostatically controlled loads, energy storage systems, price-responsive loads and the main grid is proposed. Secondly, the centralized control of the microgrid operation is convenient for the control of the reactive power and voltage of the distributed power supply and the adjustment of the grid frequency. However, there is a problem in that the flexible loads aggregate and generate peaks during the electricity price valley. The existing research takes into account the power constraints of the microgrid and fails to ensure a sufficient supply of electric energy for a single flexible load. This paper considers the response priority of each unit component of TCLs and ESSs on the basis of the overall environment operation of the microgrid so as to ensure the power supply of the flexible load of the microgrid and save the power input cost to the greatest extent. Finally, the simulation optimization of the environment can be expressed as a Markov decision process process. It combines two stages of offline and online operations in the training process. The addition of multiple threads with the lack of historical data learning leads to low learning efficiency. The asynchronous advantage actor-critic with the experience replay pool memory library is added to solve the data correlation and nonstatic distribution problems during training.
DBQ-SSD: Dynamic Ball Query for Efficient 3D Object Detection
Jul 22, 2022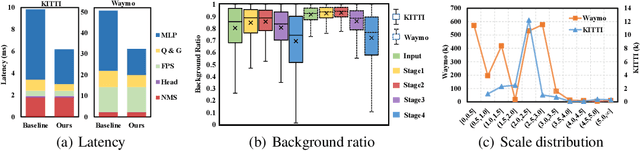
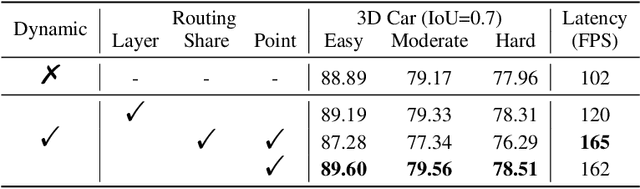
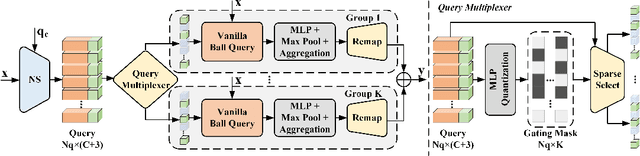
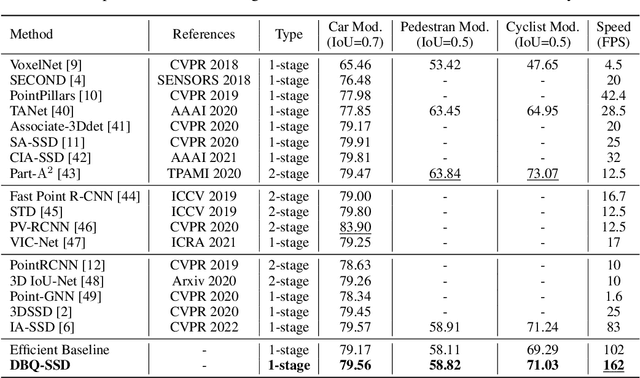
Many point-based 3D detectors adopt point-feature sampling strategies to drop some points for efficient inference. These strategies are typically based on fixed and handcrafted rules, making difficult to handle complicated scenes. Different from them, we propose a Dynamic Ball Query (DBQ) network to adaptively select a subset of input points according to the input features, and assign the feature transform with suitable receptive field for each selected point. It can be embedded into some state-of-the-art 3D detectors and trained in an end-to-end manner, which significantly reduces the computational cost. Extensive experiments demonstrate that our method can reduce latency by 30%-60% on KITTI and Waymo datasets. Specifically, the inference speed of our detector can reach 162 FPS and 30 FPS with negligible performance degradation on KITTI and Waymo datasets, respectively.
S2TNet: Spatio-Temporal Transformer Networks for Trajectory Prediction in Autonomous Driving
Jun 22, 2022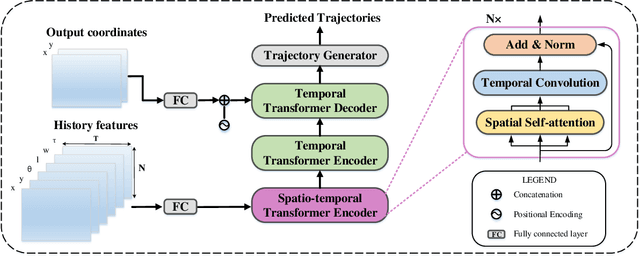
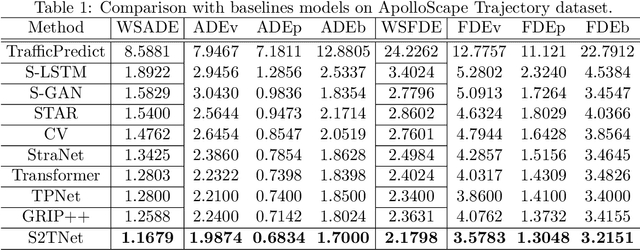
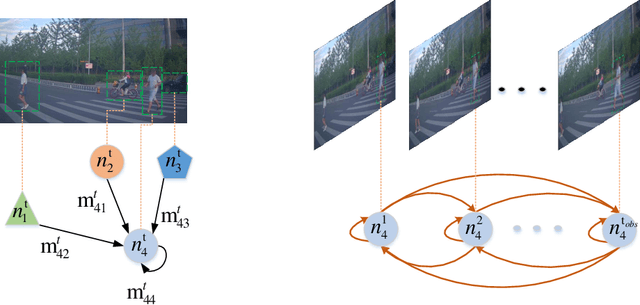
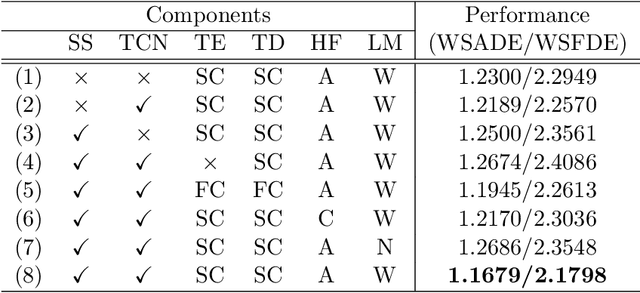
To safely and rationally participate in dense and heterogeneous traffic, autonomous vehicles require to sufficiently analyze the motion patterns of surrounding traffic-agents and accurately predict their future trajectories. This is challenging because the trajectories of traffic-agents are not only influenced by the traffic-agents themselves but also by spatial interaction with each other. Previous methods usually rely on the sequential step-by-step processing of Long Short-Term Memory networks (LSTMs) and merely extract the interactions between spatial neighbors for single type traffic-agents. We propose the Spatio-Temporal Transformer Networks (S2TNet), which models the spatio-temporal interactions by spatio-temporal Transformer and deals with the temporel sequences by temporal Transformer. We input additional category, shape and heading information into our networks to handle the heterogeneity of traffic-agents. The proposed methods outperforms state-of-the-art methods on ApolloScape Trajectory dataset by more than 7\% on both the weighted sum of Average and Final Displacement Error. Our code is available at https://github.com/chenghuang66/s2tnet.
RF-LIO: Removal-First Tightly-coupled Lidar Inertial Odometry in High Dynamic Environments
Jun 19, 2022
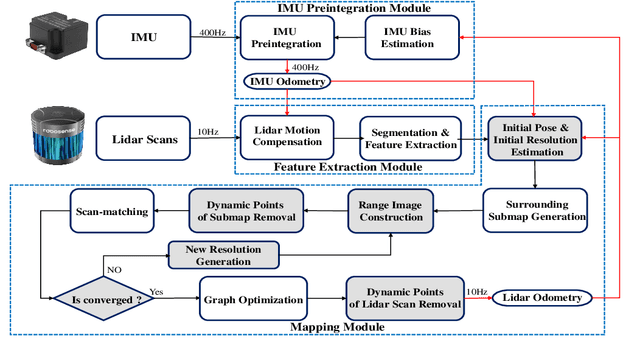
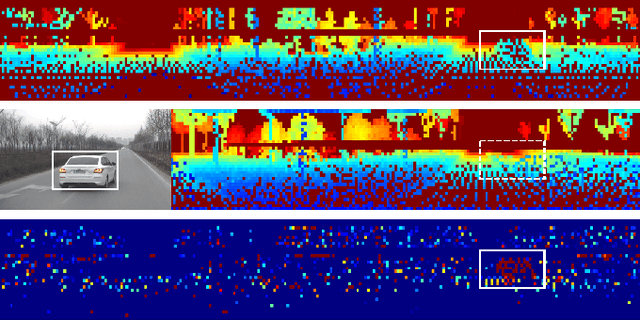
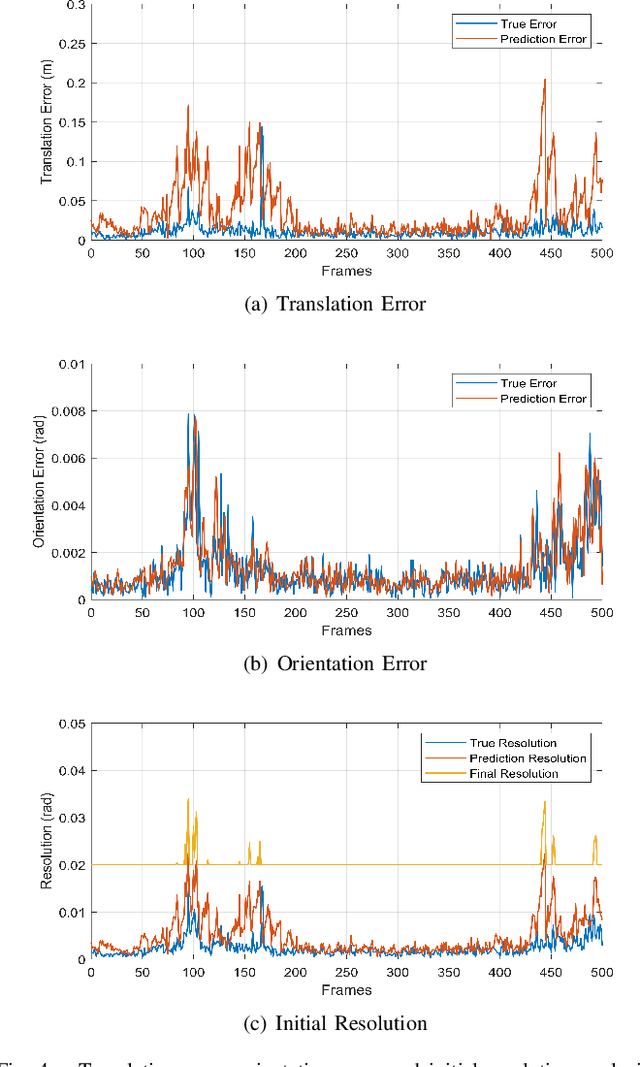
Simultaneous Localization and Mapping (SLAM) is considered to be an essential capability for intelligent vehicles and mobile robots. However, most of the current lidar SLAM approaches are based on the assumption of a static environment. Hence the localization in a dynamic environment with multiple moving objects is actually unreliable. The paper proposes a dynamic SLAM framework RF-LIO, building on LIO-SAM, which adds adaptive multi-resolution range images and uses tightly-coupled lidar inertial odometry to first remove moving objects, and then match lidar scan to the submap. Thus, it can obtain accurate poses even in high dynamic environments. The proposed RF-LIO is evaluated on both self-collected datasets and open Urbanloco datasets. The experimental results in high dynamic environments demonstrate that, compared with LOAM and LIO-SAM, the absolute trajectory accuracy of the proposed RF-LIO can be improved by 90% and 70%, respectively. RF-LIO is one of the state-of-the-art SLAM systems in high dynamic environments.
Enhancing Semantic Code Search with Multimodal Contrastive Learning and Soft Data Augmentation
Apr 08, 2022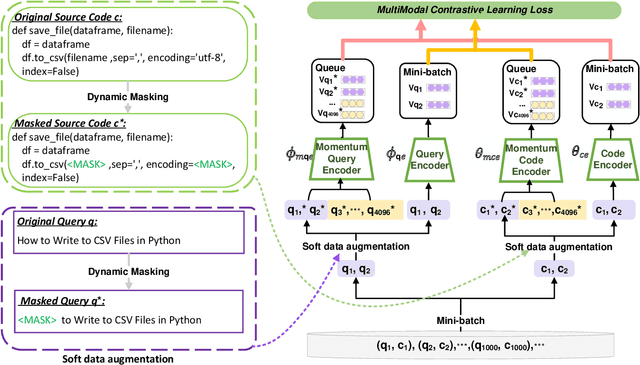
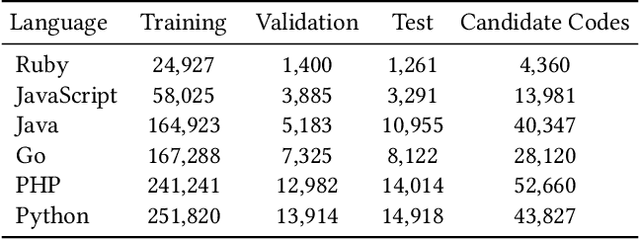
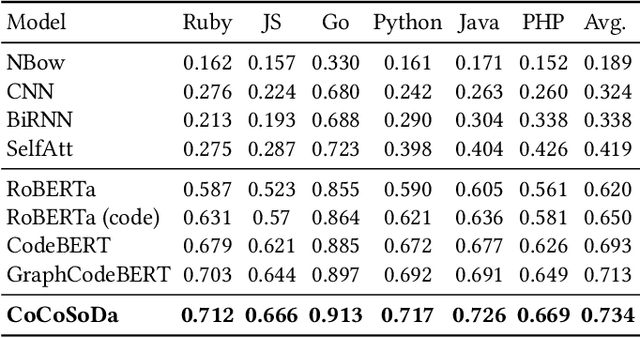
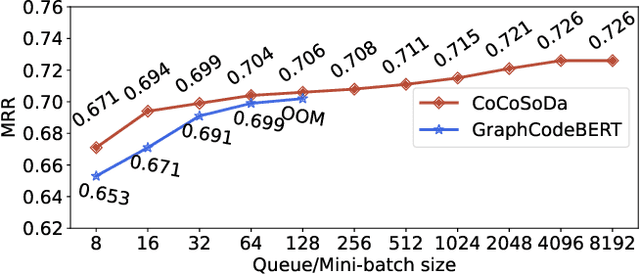
Code search aims to retrieve the most semantically relevant code snippet for a given natural language query. Recently, large-scale code pre-trained models such as CodeBERT and GraphCodeBERT learn generic representations of source code and have achieved substantial improvement on code search task. However, the high-quality sequence-level representations of code snippets have not been sufficiently explored. In this paper, we propose a new approach with multimodal contrastive learning and soft data augmentation for code search. Multimodal contrastive learning is used to pull together the representations of code-query pairs and push apart the unpaired code snippets and queries. Moreover, data augmentation is critical in contrastive learning for learning high-quality representations. However, only semantic-preserving augmentations for source code are considered in existing work. In this work, we propose to do soft data augmentation by dynamically masking and replacing some tokens in code sequences to generate code snippets that are similar but not necessarily semantic-preserving as positive samples for paired queries. We conduct extensive experiments to evaluate the effectiveness of our approach on a large-scale dataset with six programming languages. The experimental results show that our approach significantly outperforms the state-of-the-art methods. We also adapt our techniques to several pre-trained models such as RoBERTa and CodeBERT, and significantly boost their performance on the code search task.
ECMG: Exemplar-based Commit Message Generation
Apr 07, 2022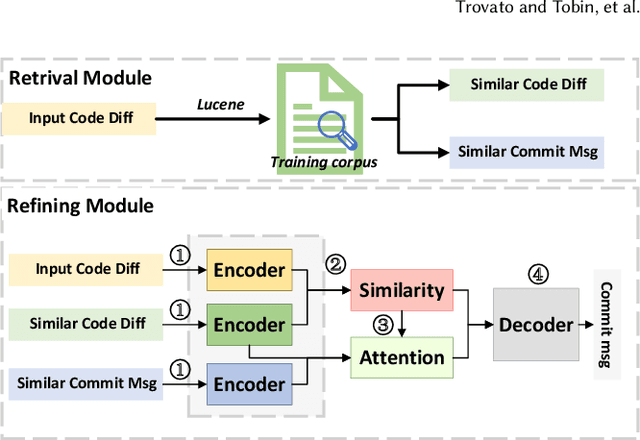

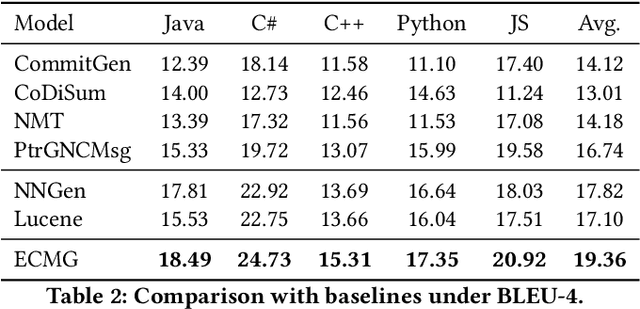
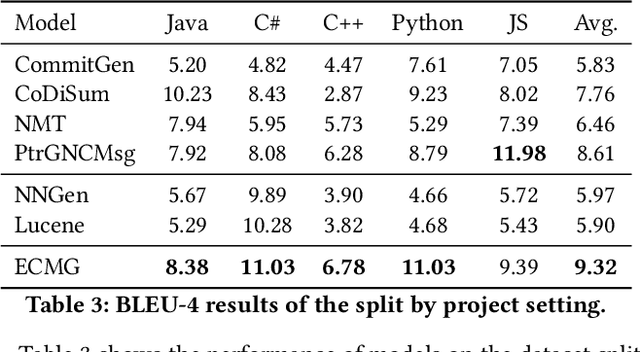
Commit messages concisely describe the content of code diffs (i.e., code changes) and the intent behind them. Recently, many approaches have been proposed to generate commit messages automatically. The information retrieval-based methods reuse the commit messages of similar code diffs, while the neural-based methods learn the semantic connection between code diffs and commit messages. However, the reused commit messages might not accurately describe the content/intent of code diffs and neural-based methods tend to generate high-frequent and repetitive tokens in the corpus. In this paper, we combine the advantages of the two technical routes and propose a novel exemplar-based neural commit message generation model, which treats the similar commit message as an exemplar and leverages it to guide the neural network model to generate an accurate commit message. We perform extensive experiments and the results confirm the effectiveness of our model.