 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMiLorE-SSL: Scaling Multilingual Capabilities in Self-Supervised Models without Forgetting
Jan 28, 2026Self-supervised learning (SSL) has greatly advanced speech representation learning, but multilingual SSL models remain constrained to languages encountered during pretraining. Retraining from scratch to incorporate new languages is computationally expensive, while sequential training without migitation strategies often leads to catastrophic forgetting. To address this, we propose MiLorE-SSL, a lightweight framework that combines LoRA modules with a soft mixture-of-experts (MoE) mechanism for efficient continual multilingual training. LoRA provides efficient low-rank adaptation, while soft MoE promotes flexible expert sharing across languages, reducing cross-lingual interference. To further mitigate forgetting, we introduce limited replay data from existing languages, avoiding reliance on large historical corpora. Experiments on ML-SUPERB demonstrate that MiLorE-SSL achieves strong performance in new languages and improves the ability in existing ones with only 2.14% trainable parameters.
TreePS-RAG: Tree-based Process Supervision for Reinforcement Learning in Agentic RAG
Jan 11, 2026Agentic retrieval-augmented generation (RAG) formulates question answering as a multi-step interaction between reasoning and information retrieval, and has recently been advanced by reinforcement learning (RL) with outcome-based supervision. While effective, relying solely on sparse final rewards limits step-wise credit assignment and provides weak guidance for intermediate reasoning and actions. Recent efforts explore process-level supervision, but typically depend on offline constructed training data, which risks distribution shift, or require costly intermediate annotations. We present TreePS-RAG, an online, tree-based RL framework for agentic RAG that enables step-wise credit assignment while retaining standard outcome-only rewards. Our key insight is to model agentic RAG reasoning as a rollout tree, where each reasoning step naturally maps to a node. This tree structure allows step utility to be estimated via Monte Carlo estimation over its descendant outcomes, yielding fine-grained process advantages without requiring intermediate labels. To make this paradigm practical, we introduce an efficient online tree construction strategy that preserves exploration diversity under a constrained computational budget. With a rollout cost comparable to strong baselines like Search-R1, experiments on seven multi-hop and general QA benchmarks across multiple model scales show that TreePS-RAG consistently and significantly outperforms both outcome-supervised and leading process-supervised RL methods.
ELEGANCE: Efficient LLM Guidance for Audio-Visual Target Speech Extraction
Nov 09, 2025Audio-visual target speaker extraction (AV-TSE) models primarily rely on visual cues from the target speaker. However, humans also leverage linguistic knowledge, such as syntactic constraints, next word prediction, and prior knowledge of conversation, to extract target speech. Inspired by this observation, we propose ELEGANCE, a novel framework that incorporates linguistic knowledge from large language models (LLMs) into AV-TSE models through three distinct guidance strategies: output linguistic constraints, intermediate linguistic prediction, and input linguistic prior. Comprehensive experiments with RoBERTa, Qwen3-0.6B, and Qwen3-4B on two AV-TSE backbones demonstrate the effectiveness of our approach. Significant improvements are observed in challenging scenarios, including visual cue impaired, unseen languages, target speaker switches, increased interfering speakers, and out-of-domain test set. Demo page: https://alexwxwu.github.io/ELEGANCE/.
Speech Discrete Tokens or Continuous Features? A Comparative Analysis for Spoken Language Understanding in SpeechLLMs
Aug 25, 2025With the rise of Speech Large Language Models (SpeechLLMs), two dominant approaches have emerged for speech processing: discrete tokens and continuous features. Each approach has demonstrated strong capabilities in audio-related processing tasks. However, the performance gap between these two paradigms has not been thoroughly explored. To address this gap, we present a fair comparison of self-supervised learning (SSL)-based discrete and continuous features under the same experimental settings. We evaluate their performance across six spoken language understanding-related tasks using both small and large-scale LLMs (Qwen1.5-0.5B and Llama3.1-8B). We further conduct in-depth analyses, including efficient comparison, SSL layer analysis, LLM layer analysis, and robustness comparison. Our findings reveal that continuous features generally outperform discrete tokens in various tasks. Each speech processing method exhibits distinct characteristics and patterns in how it learns and processes speech information. We hope our results will provide valuable insights to advance spoken language understanding in SpeechLLMs.
DualSpeechLM: Towards Unified Speech Understanding and Generation via Dual Speech Token Modeling with Large Language Models
Aug 12, 2025Extending pre-trained Large Language Models (LLMs)'s speech understanding or generation abilities by introducing various effective speech tokens has attracted great attention in the speech community. However, building a unified speech understanding and generation model still faces the following challenges: (1) Due to the huge modality gap between speech tokens and text tokens, extending text LLMs to unified speech LLMs relies on large-scale paired data for fine-tuning, and (2) Generation and understanding tasks prefer information at different levels, e.g., generation benefits from detailed acoustic features, while understanding favors high-level semantics. This divergence leads to difficult performance optimization in one unified model. To solve these challenges, in this paper, we present two key insights in speech tokenization and speech language modeling. Specifically, we first propose an Understanding-driven Speech Tokenizer (USTokenizer), which extracts high-level semantic information essential for accomplishing understanding tasks using text LLMs. In this way, USToken enjoys better modality commonality with text, which reduces the difficulty of modality alignment in adapting text LLMs to speech LLMs. Secondly, we present DualSpeechLM, a dual-token modeling framework that concurrently models USToken as input and acoustic token as output within a unified, end-to-end framework, seamlessly integrating speech understanding and generation capabilities. Furthermore, we propose a novel semantic supervision loss and a Chain-of-Condition (CoC) strategy to stabilize model training and enhance speech generation performance. Experimental results demonstrate that our proposed approach effectively fosters a complementary relationship between understanding and generation tasks, highlighting the promising strategy of mutually enhancing both tasks in one unified model.
Incorporating Linguistic Constraints from External Knowledge Source for Audio-Visual Target Speech Extraction
Jun 11, 2025Audio-visual target speaker extraction (AV-TSE) models primarily rely on target visual cues to isolate the target speaker's voice from others. We know that humans leverage linguistic knowledge, such as syntax and semantics, to support speech perception. Inspired by this, we explore the potential of pre-trained speech-language models (PSLMs) and pre-trained language models (PLMs) as auxiliary knowledge sources for AV-TSE. In this study, we propose incorporating the linguistic constraints from PSLMs or PLMs for the AV-TSE model as additional supervision signals. Without introducing any extra computational cost during inference, the proposed approach consistently improves speech quality and intelligibility. Furthermore, we evaluate our method in multi-language settings and visual cue-impaired scenarios and show robust performance gains.
Naturalistic Language-related Movie-Watching fMRI Task for Detecting Neurocognitive Decline and Disorder
Jun 10, 2025Early detection is crucial for timely intervention aimed at preventing and slowing the progression of neurocognitive disorder (NCD), a common and significant health problem among the aging population. Recent evidence has suggested that language-related functional magnetic resonance imaging (fMRI) may be a promising approach for detecting cognitive decline and early NCD. In this paper, we proposed a novel, naturalistic language-related fMRI task for this purpose. We examined the effectiveness of this task among 97 non-demented Chinese older adults from Hong Kong. The results showed that machine-learning classification models based on fMRI features extracted from the task and demographics (age, gender, and education year) achieved an average area under the curve of 0.86 when classifying participants' cognitive status (labeled as NORMAL vs DECLINE based on their scores on a standard neurcognitive test). Feature localization revealed that the fMRI features most frequently selected by the data-driven approach came primarily from brain regions associated with language processing, such as the superior temporal gyrus, middle temporal gyrus, and right cerebellum. The study demonstrated the potential of the naturalistic language-related fMRI task for early detection of aging-related cognitive decline and NCD.
MMSU: A Massive Multi-task Spoken Language Understanding and Reasoning Benchmark
Jun 05, 2025Speech inherently contains rich acoustic information that extends far beyond the textual language. In real-world spoken language understanding, effective interpretation often requires integrating semantic meaning (e.g., content), paralinguistic features (e.g., emotions, speed, pitch) and phonological characteristics (e.g., prosody, intonation, rhythm), which are embedded in speech. While recent multimodal Speech Large Language Models (SpeechLLMs) have demonstrated remarkable capabilities in processing audio information, their ability to perform fine-grained perception and complex reasoning in natural speech remains largely unexplored. To address this gap, we introduce MMSU, a comprehensive benchmark designed specifically for understanding and reasoning in spoken language. MMSU comprises 5,000 meticulously curated audio-question-answer triplets across 47 distinct tasks. To ground our benchmark in linguistic theory, we systematically incorporate a wide range of linguistic phenomena, including phonetics, prosody, rhetoric, syntactics, semantics, and paralinguistics. Through a rigorous evaluation of 14 advanced SpeechLLMs, we identify substantial room for improvement in existing models, highlighting meaningful directions for future optimization. MMSU establishes a new standard for comprehensive assessment of spoken language understanding, providing valuable insights for developing more sophisticated human-AI speech interaction systems. MMSU benchmark is available at https://huggingface.co/datasets/ddwang2000/MMSU. Evaluation Code is available at https://github.com/dingdongwang/MMSU_Bench.
RAG-Zeval: Towards Robust and Interpretable Evaluation on RAG Responses through End-to-End Rule-Guided Reasoning
May 28, 2025



Robust evaluation is critical for deploying trustworthy retrieval-augmented generation (RAG) systems. However, current LLM-based evaluation frameworks predominantly rely on directly prompting resource-intensive models with complex multi-stage prompts, underutilizing models' reasoning capabilities and introducing significant computational cost. In this paper, we present RAG-Zeval (RAG-Zero Evaluator), a novel end-to-end framework that formulates faithfulness and correctness evaluation as a rule-guided reasoning task. Our approach trains evaluators with reinforcement learning, facilitating compact models to generate comprehensive and sound assessments with detailed explanation in one-pass. We introduce a ranking-based outcome reward mechanism, using preference judgments rather than absolute scores, to address the challenge of obtaining precise pointwise reward signals. To this end, we synthesize the ranking references by generating quality-controlled responses with zero human annotation. Experiments demonstrate RAG-Zeval's superior performance, achieving the strongest correlation with human judgments and outperforming baselines that rely on LLMs with 10-100 times more parameters. Our approach also exhibits superior interpretability in response evaluation.
On-the-fly Routing for Zero-shot MoE Speaker Adaptation of Speech Foundation Models for Dysarthric Speech Recognition
May 28, 2025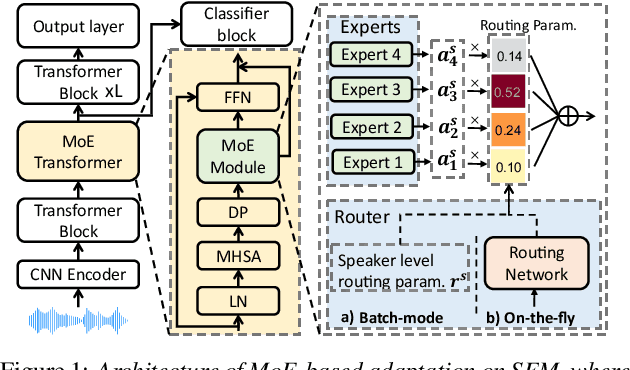
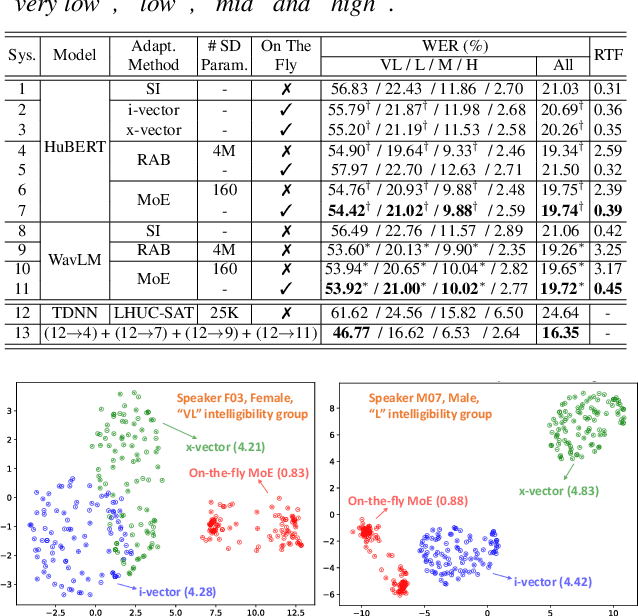
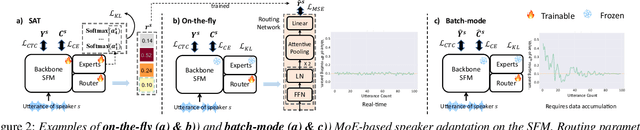

This paper proposes a novel MoE-based speaker adaptation framework for foundation models based dysarthric speech recognition. This approach enables zero-shot adaptation and real-time processing while incorporating domain knowledge. Speech impairment severity and gender conditioned adapter experts are dynamically combined using on-the-fly predicted speaker-dependent routing parameters. KL-divergence is used to further enforce diversity among experts and their generalization to unseen speakers. Experimental results on the UASpeech corpus suggest that on-the-fly MoE-based adaptation produces statistically significant WER reductions of up to 1.34% absolute (6.36% relative) over the unadapted baseline HuBERT/WavLM models. Consistent WER reductions of up to 2.55% absolute (11.44% relative) and RTF speedups of up to 7 times are obtained over batch-mode adaptation across varying speaker-level data quantities. The lowest published WER of 16.35% (46.77% on very low intelligibility) is obtained.