 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing End-to-End Pixel Space Generative Modeling via Self-supervised Pre-training
Oct 14, 2025Pixel-space generative models are often more difficult to train and generally underperform compared to their latent-space counterparts, leaving a persistent performance and efficiency gap. In this paper, we introduce a novel two-stage training framework that closes this gap for pixel-space diffusion and consistency models. In the first stage, we pre-train encoders to capture meaningful semantics from clean images while aligning them with points along the same deterministic sampling trajectory, which evolves points from the prior to the data distribution. In the second stage, we integrate the encoder with a randomly initialized decoder and fine-tune the complete model end-to-end for both diffusion and consistency models. Our training framework demonstrates strong empirical performance on ImageNet dataset. Specifically, our diffusion model reaches an FID of 2.04 on ImageNet-256 and 2.35 on ImageNet-512 with 75 number of function evaluations (NFE), surpassing prior pixel-space methods by a large margin in both generation quality and efficiency while rivaling leading VAE-based models at comparable training cost. Furthermore, on ImageNet-256, our consistency model achieves an impressive FID of 8.82 in a single sampling step, significantly surpassing its latent-space counterpart. To the best of our knowledge, this marks the first successful training of a consistency model directly on high-resolution images without relying on pre-trained VAEs or diffusion models.
Migrating Face Swap to Mobile Devices: A lightweight Framework and A Supervised Training Solution
Apr 13, 2022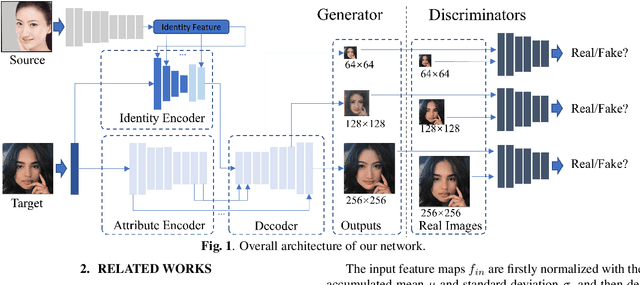
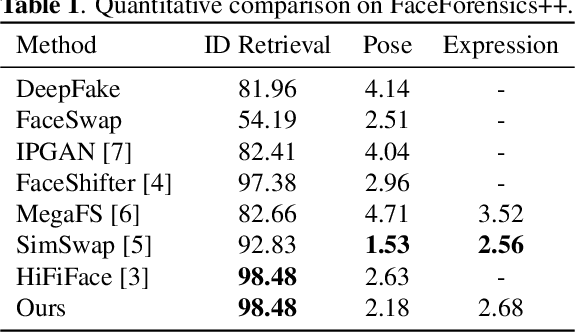
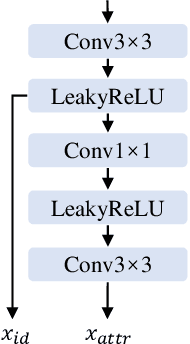
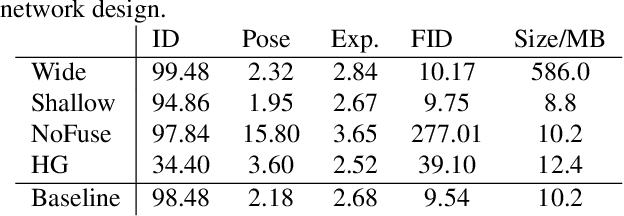
Existing face swap methods rely heavily on large-scale networks for adequate capacity to generate visually plausible results, which inhibits its applications on resource-constraint platforms. In this work, we propose MobileFSGAN, a novel lightweight GAN for face swap that can run on mobile devices with much fewer parameters while achieving competitive performance. A lightweight encoder-decoder structure is designed especially for image synthesis tasks, which is only 10.2MB and can run on mobile devices at a real-time speed. To tackle the unstability of training such a small network, we construct the FSTriplets dataset utilizing facial attribute editing techniques. FSTriplets provides source-target-result training triplets, yielding pixel-level labels thus for the first time making the training process supervised. We also designed multi-scale gradient losses for efficient back-propagation, resulting in faster and better convergence. Experimental results show that our model reaches comparable performance towards state-of-the-art methods, while significantly reducing the number of network parameters. Codes and the dataset have been released.
Unknown Identity Rejection Loss: Utilizing Unlabeled Data for Face Recognition
Oct 24, 2019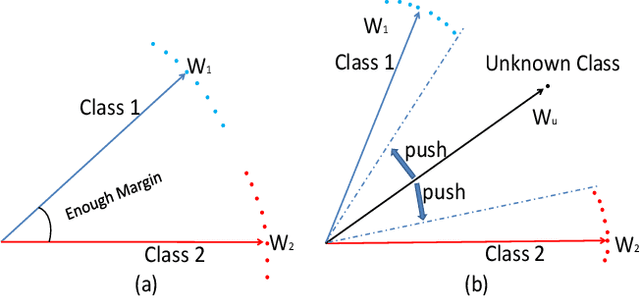
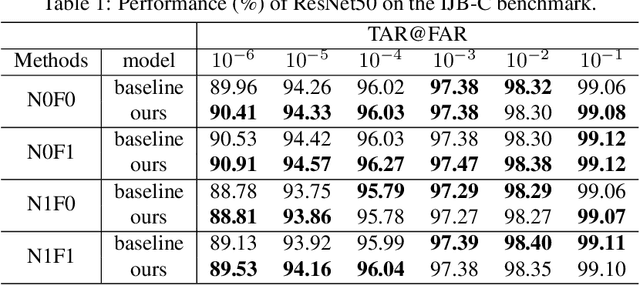
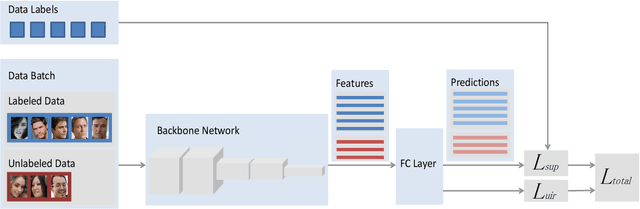
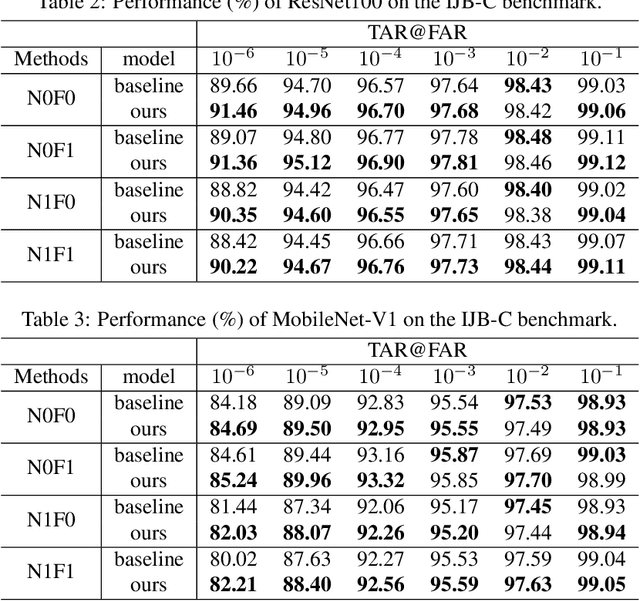
Face recognition has advanced considerably with the availability of large-scale labeled datasets. However, how to further improve the performance with the easily accessible unlabeled dataset remains a challenge. In this paper, we propose the novel Unknown Identity Rejection (UIR) loss to utilize the unlabeled data. We categorize identities in unconstrained environment into the known set and the unknown set. The former corresponds to the identities that appear in the labeled training dataset while the latter is its complementary set. Besides training the model to accurately classify the known identities, we also force the model to reject unknown identities provided by the unlabeled dataset via our proposed UIR loss. In order to 'reject' faces of unknown identities, centers of the known identities are forced to keep enough margin from centers of unknown identities which are assumed to be approximated by the features of their samples. By this means, the discriminativeness of the face representations can be enhanced. Experimental results demonstrate that our approach can provide obvious performance improvement by utilizing the unlabeled data.