 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Efficient GPU-based Implementation for Noise Robust Sound Source Localization
Apr 04, 2025



Robot audition, encompassing Sound Source Localization (SSL), Sound Source Separation (SSS), and Automatic Speech Recognition (ASR), enables robots and smart devices to acquire auditory capabilities similar to human hearing. Despite their wide applicability, processing multi-channel audio signals from microphone arrays in SSL involves computationally intensive matrix operations, which can hinder efficient deployment on Central Processing Units (CPUs), particularly in embedded systems with limited CPU resources. This paper introduces a GPU-based implementation of SSL for robot audition, utilizing the Generalized Singular Value Decomposition-based Multiple Signal Classification (GSVD-MUSIC), a noise-robust algorithm, within the HARK platform, an open-source software suite. For a 60-channel microphone array, the proposed implementation achieves significant performance improvements. On the Jetson AGX Orin, an embedded device powered by an NVIDIA GPU and ARM Cortex-A78AE v8.2 64-bit CPUs, we observe speedups of 4645.1x for GSVD calculations and 8.8x for the SSL module, while speedups of 2223.4x for GSVD calculation and 8.95x for the entire SSL module on a server configured with an NVIDIA A100 GPU and AMD EPYC 7352 CPUs, making real-time processing feasible for large-scale microphone arrays and providing ample capacity for real-time processing of potential subsequent machine learning or deep learning tasks.
Bird Vocalization Embedding Extraction Using Self-Supervised Disentangled Representation Learning
Dec 28, 2024



This paper addresses the extraction of the bird vocalization embedding from the whole song level using disentangled representation learning (DRL). Bird vocalization embeddings are necessary for large-scale bioacoustic tasks, and self-supervised methods such as Variational Autoencoder (VAE) have shown their performance in extracting such low-dimensional embeddings from vocalization segments on the note or syllable level. To extend the processing level to the entire song instead of cutting into segments, this paper regards each vocalization as the generalized and discriminative part and uses two encoders to learn these two parts. The proposed method is evaluated on the Great Tits dataset according to the clustering performance, and the results outperform the compared pre-trained models and vanilla VAE. Finally, this paper analyzes the informative part of the embedding, further compresses its dimension, and explains the disentangled performance of bird vocalizations.
UAV-Enhanced Combination to Application: Comprehensive Analysis and Benchmarking of a Human Detection Dataset for Disaster Scenarios
Aug 09, 2024



Unmanned aerial vehicles (UAVs) have revolutionized search and rescue (SAR) operations, but the lack of specialized human detection datasets for training machine learning models poses a significant challenge.To address this gap, this paper introduces the Combination to Application (C2A) dataset, synthesized by overlaying human poses onto UAV-captured disaster scenes. Through extensive experimentation with state-of-the-art detection models, we demonstrate that models fine-tuned on the C2A dataset exhibit substantial performance improvements compared to those pre-trained on generic aerial datasets. Furthermore, we highlight the importance of combining the C2A dataset with general human datasets to achieve optimal performance and generalization across various scenarios. This points out the crucial need for a tailored dataset to enhance the effectiveness of SAR operations. Our contributions also include developing dataset creation pipeline and integrating diverse human poses and disaster scenes information to assess the severity of disaster scenarios. Our findings advocate for future developments, to ensure that SAR operations benefit from the most realistic and effective AI-assisted interventions possible.
Can all variations within the unified mask-based beamformer framework achieve identical peak extraction performance?
Jul 22, 2024This study investigates mask-based beamformers (BFs), which estimate filters for target sound extraction (TSE) using time-frequency masks. Although multiple mask-based BFs have been proposed, no consensus has been established on the best one for target-extracting performance. Previously, we found that maximum signal-to-noise ratio and minimum mean square error (MSE) BFs can achieve the same extraction performance as the theoretical upper-bound performance, with each BF containing a different optimal mask. However, these remarkable findings left two issues unsolved: only two BFs were covered, excluding the minimum variance distortionless response BF; and ideal scaling (IS) was employed to ideally adjust the output scale, which is not applicable to realistic scenarios. To address these coverage and scaling issues, this study proposes a unified framework for mask-based BFs comprising two processes: filter estimation that can cover all BFs and scaling applicable to realistic scenarios by employing a mask to generate a scaling reference. We also propose a methodology to enumerate all possible BFs and derive 12 variations. Optimal masks for both processes are obtained by minimizing the MSE between the target and BF output. The experimental results using the CHiME-4 dataset suggested that 1) all 12 variations can achieve the theoretical upper-bound performance, and 2) mask-based scaling can behave as IS. These results can be explained by considering the practical parameter count of the masks. These findings contribute to 1) designing a TSE system, 2) estimating the extraction performance of a BF, and 3) improving scaling accuracy combined with mask-based scaling. The contributions also apply to TSE methods based on independent component analysis, as the unified framework covers them too.
SLAM-based Joint Calibration of Multiple Asynchronous Microphone Arrays and Sound Source Localization
May 30, 2024



Robot audition systems with multiple microphone arrays have many applications in practice. However, accurate calibration of multiple microphone arrays remains challenging because there are many unknown parameters to be identified, including the relative transforms (i.e., orientation, translation) and asynchronous factors (i.e., initial time offset and sampling clock difference) between microphone arrays. To tackle these challenges, in this paper, we adopt batch simultaneous localization and mapping (SLAM) for joint calibration of multiple asynchronous microphone arrays and sound source localization. Using the Fisher information matrix (FIM) approach, we first conduct the observability analysis (i.e., parameter identifiability) of the above-mentioned calibration problem and establish necessary/sufficient conditions under which the FIM and the Jacobian matrix have full column rank, which implies the identifiability of the unknown parameters. We also discover several scenarios where the unknown parameters are not uniquely identifiable. Subsequently, we propose an effective framework to initialize the unknown parameters, which is used as the initial guess in batch SLAM for multiple microphone arrays calibration, aiming to further enhance optimization accuracy and convergence. Extensive numerical simulations and real experiments have been conducted to verify the performance of the proposed method. The experiment results show that the proposed pipeline achieves higher accuracy with fast convergence in comparison to methods that use the noise-corrupted ground truth of the unknown parameters as the initial guess in the optimization and other existing frameworks.
From Blurry to Brilliant Detection: YOLOv5-Based Aerial Object Detection with Super Resolution
Jan 26, 2024The demand for accurate object detection in aerial imagery has surged with the widespread use of drones and satellite technology. Traditional object detection models, trained on datasets biased towards large objects, struggle to perform optimally in aerial scenarios where small, densely clustered objects are prevalent. To address this challenge, we present an innovative approach that combines super-resolution and an adapted lightweight YOLOv5 architecture. We employ a range of datasets, including VisDrone-2023, SeaDroneSee, VEDAI, and NWPU VHR-10, to evaluate our model's performance. Our Super Resolved YOLOv5 architecture features Transformer encoder blocks, allowing the model to capture global context and context information, leading to improved detection results, especially in high-density, occluded conditions. This lightweight model not only delivers improved accuracy but also ensures efficient resource utilization, making it well-suited for real-time applications. Our experimental results demonstrate the model's superior performance in detecting small and densely clustered objects, underlining the significance of dataset choice and architectural adaptation for this specific task. In particular, the method achieves 52.5% mAP on VisDrone, exceeding top prior works. This approach promises to significantly advance object detection in aerial imagery, contributing to more accurate and reliable results in a variety of real-world applications.
Is the Ideal Ratio Mask Really the Best? -- Exploring the Best Extraction Performance and Optimal Mask of Mask-based Beamformers
Sep 21, 2023This study investigates mask-based beamformers (BFs), which estimate filters to extract target speech using time-frequency masks. Although several BF methods have been proposed, the following aspects are yet to be comprehensively investigated. 1) Which BF can provide the best extraction performance in terms of the closeness of the BF output to the target speech? 2) Is the optimal mask for the best performance common for all BFs? 3) Is the ideal ratio mask (IRM) identical to the optimal mask? Accordingly, we investigate these issues considering four mask-based BFs: the maximum signal-to-noise ratio BF, two variants of this, and the multichannel Wiener filter (MWF) BF. To obtain the optimal mask corresponding to the peak performance for each BF, we employ an approach that minimizes the mean square error between the BF output and target speech for each utterance. Via the experiments with the CHiME-3 dataset, we verify that the four BFs have the same peak performance as the upper bound provided by the ideal MWF BF, whereas the optimal mask depends on the adopted BF and differs from the IRM. These observations differ from the conventional idea that the optimal mask is common for all BFs and that peak performance differs for each BF. Hence, this study contributes to the design of mask-based BFs.
Metric-based multimodal meta-learning for human movement identification via footstep recognition
Nov 15, 2021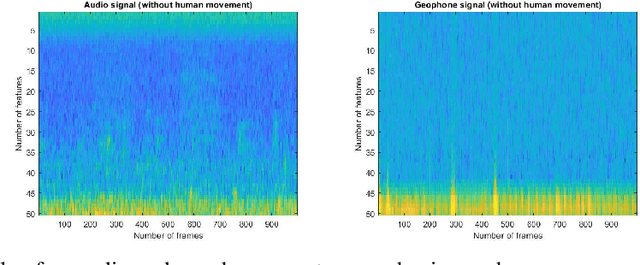

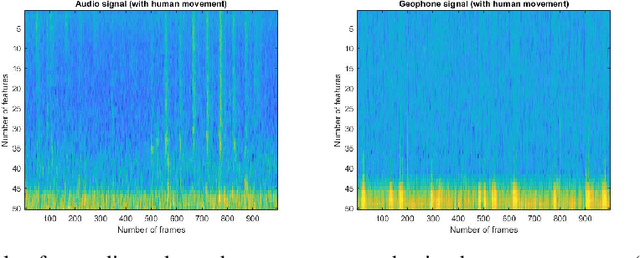
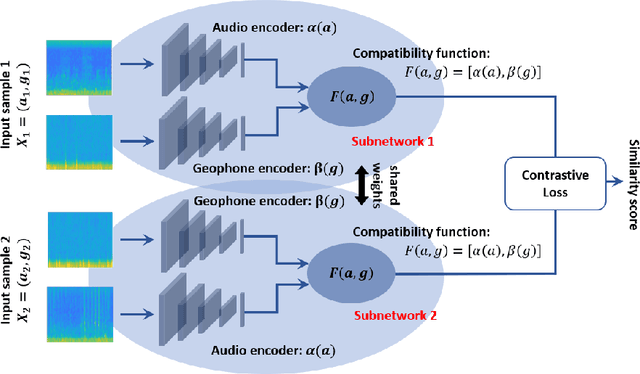
We describe a novel metric-based learning approach that introduces a multimodal framework and uses deep audio and geophone encoders in siamese configuration to design an adaptable and lightweight supervised model. This framework eliminates the need for expensive data labeling procedures and learns general-purpose representations from low multisensory data obtained from omnipresent sensing systems. These sensing systems provide numerous applications and various use cases in activity recognition tasks. Here, we intend to explore the human footstep movements from indoor environments and analyze representations from a small self-collected dataset of acoustic and vibration-based sensors. The core idea is to learn plausible similarities between two sensory traits and combining representations from audio and geophone signals. We present a generalized framework to learn embeddings from temporal and spatial features extracted from audio and geophone signals. We then extract the representations in a shared space to maximize the learning of a compatibility function between acoustic and geophone features. This, in turn, can be used effectively to carry out a classification task from the learned model, as demonstrated by assigning high similarity to the pairs with a human footstep movement and lower similarity to pairs containing no footstep movement. Performance analyses show that our proposed multimodal framework achieves a 19.99\% accuracy increase (in absolute terms) and avoided overfitting on the evaluation set when the training samples were increased from 200 pairs to just 500 pairs while satisfactorily learning the audio and geophone representations. Our results employ a metric-based contrastive learning approach for multi-sensor data to mitigate the impact of data scarcity and perform human movement identification with limited data size.
Unsupervised Speech Enhancement Based on Multichannel NMF-Informed Beamforming for Noise-Robust Automatic Speech Recognition
Mar 31, 2019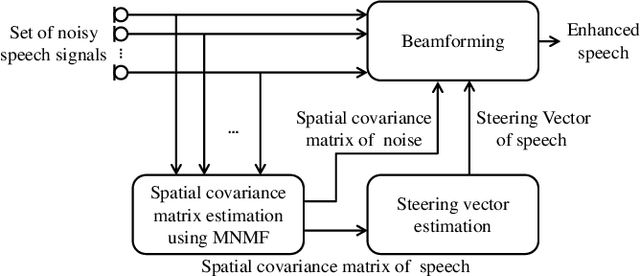
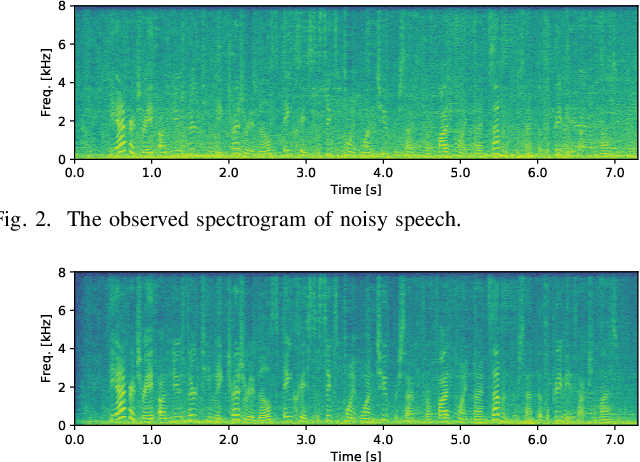
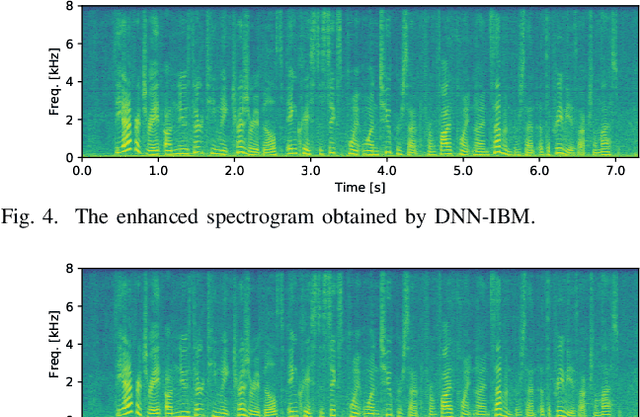

This paper describes multichannel speech enhancement for improving automatic speech recognition (ASR) in noisy environments. Recently, the minimum variance distortionless response (MVDR) beamforming has widely been used because it works well if the steering vector of speech and the spatial covariance matrix (SCM) of noise are given. To estimating such spatial information, conventional studies take a supervised approach that classifies each time-frequency (TF) bin into noise or speech by training a deep neural network (DNN). The performance of ASR, however, is degraded in an unknown noisy environment. To solve this problem, we take an unsupervised approach that decomposes each TF bin into the sum of speech and noise by using multichannel nonnegative matrix factorization (MNMF). This enables us to accurately estimate the SCMs of speech and noise not from observed noisy mixtures but from separated speech and noise components. In this paper we propose online MVDR beamforming by effectively initializing and incrementally updating the parameters of MNMF. Another main contribution is to comprehensively investigate the performances of ASR obtained by various types of spatial filters, i.e., time-invariant and variant versions of MVDR beamformers and those of rank-1 and full-rank multichannel Wiener filters, in combination with MNMF. The experimental results showed that the proposed method outperformed the state-of-the-art DNN-based beamforming method in unknown environments that did not match training data.
Statistical Speech Enhancement Based on Probabilistic Integration of Variational Autoencoder and Non-Negative Matrix Factorization
Mar 19, 2018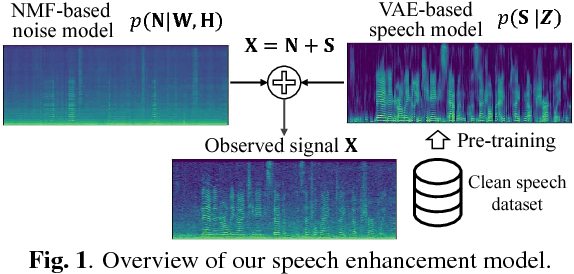
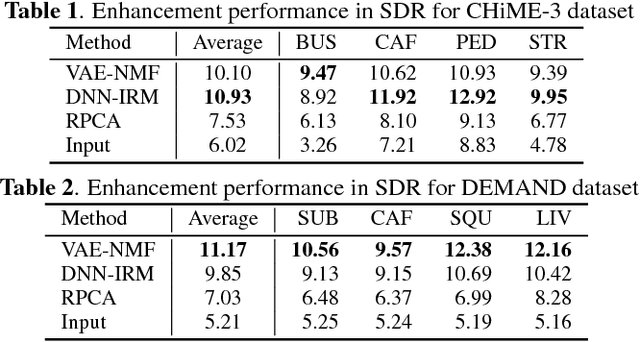
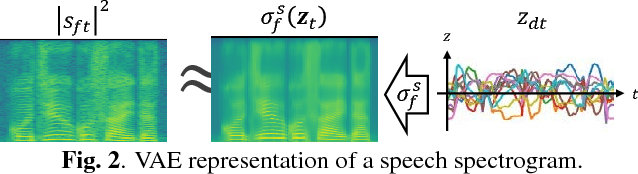

This paper presents a statistical method of single-channel speech enhancement that uses a variational autoencoder (VAE) as a prior distribution on clean speech. A standard approach to speech enhancement is to train a deep neural network (DNN) to take noisy speech as input and output clean speech. Although this supervised approach requires a very large amount of pair data for training, it is not robust against unknown environments. Another approach is to use non-negative matrix factorization (NMF) based on basis spectra trained on clean speech in advance and those adapted to noise on the fly. This semi-supervised approach, however, causes considerable signal distortion in enhanced speech due to the unrealistic assumption that speech spectrograms are linear combinations of the basis spectra. Replacing the poor linear generative model of clean speech in NMF with a VAE---a powerful nonlinear deep generative model---trained on clean speech, we formulate a unified probabilistic generative model of noisy speech. Given noisy speech as observed data, we can sample clean speech from its posterior distribution. The proposed method outperformed the conventional DNN-based method in unseen noisy environments.